Навигация
МИНИСТЕРСТВО СЕЛЬСКОГО ХОЗЯЙСТВА И ПРОДОВОЛЬСТВИЯ РЕСПУБЛИКИ БЕЛАРУСЬ
БЕЛОРУССКИЙ ГОСУДАРСТВЕННЫЙ АГРАРНЫЙ ТЕХНИЧЕСКИЙ УНИВЕРСИТЕТ
Контрольная работа по предмету
Статистика
Подготовила студентка
3-го курса ФПУ 71зэи
№ зачетной книжки 507039
Боровик Марина Александровна
Проверил______________________
Отметка о зачете________________
«___»__________2008г.__________
Минск 2009
Задание 1. Статистические гипотезы и методы их проверки
Статистическая гипотеза представляет собой некоторое предположение о законе распределения случайной величины или о параметрах этого закона, формулируемое на основе выборки [3, 5, 11]. Примерами статистических гипотез являются предположения: генеральная совокупность распределена по экспоненциальному закону; математические ожидания двух экспоненциально распределенных выборок равны друг другу. В первой из них высказано предположение о виде закона распределения, а во второй – о параметрах двух распределений. Гипотезы, в основе которых нет никаких допущений о конкретном виде закона распределения, называют непараметрическими, в противном случае – параметрическими.
Гипотезу, утверждающую, что различие между сравниваемыми характеристиками отсутствует, а наблюдаемые отклонения объясняются лишь случайными колебаниями в выборках, на основании которых производится сравнение, называют нулевой (основной) гипотезой и обозначают Н0. Наряду с основной гипотезой рассматривают и альтернативную (конкурирующую, противоречащую) ей гипотезу Н1. И если нулевая гипотеза будет отвергнута, то будет иметь место альтернативная гипотеза.
Различают простые и сложные гипотезы. Гипотезу называют простой, если она однозначно характеризует параметр распределения случайной величины. Например, если l является параметром экспоненциального распределения, то гипотеза Н0 о равенстве l=10 – простая гипотеза. Сложной называют гипотезу, которая состоит из конечного или бесконечного множества простых гипотез. Сложная гипотеза Н0 о неравенстве l>10 состоит из бесконечного множества простых гипотез Н0 о равенстве l=bi, где bi – любое число, большее 10. Гипотеза Н0 о том, что математическое ожидание нормального распределения равно двум при неизвестной дисперсии, тоже является сложной. Сложной гипотезой будет предположение о распределении случайной величины Х по нормальному закону, если не фиксируются конкретные значения математического ожидания и дисперсии.
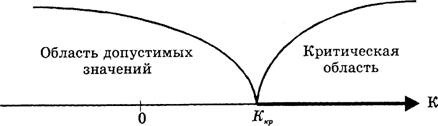
Проверка гипотезы основывается на вычислении некоторой случайной величины – критерия, точное или приближенное распределение которого известно. Обозначим эту величину через z, ее значение является функцией от элементов выборки z=z(x1, x2, …, xn). Процедура проверки гипотезы предписывает каждому значению критерия одно из двух решений – принять или отвергнуть гипотезу. Тем самым все выборочное пространство и соответственно множество значений критерия делятся на два непересекающихся подмножества S0 и S1. Если значение критерия z попадает в область S0, то гипотеза принимается, а если в область S1, то гипотеза отклоняется. Множество S0 называется областью принятия гипотезы или областью допустимых значений, а множество S1 – областью отклонения гипотезы или критической областью. Выбор одной области однозначно определяет и другую область.
Принятие или отклонение гипотезы Н0 по случайной выборке соответствует истине с некоторой вероятностью и, соответственно, возможны два рода ошибок. Ошибка первого рода возникает с вероятностью a тогда, когда отвергается верная гипотеза Н0 и принимается конкурирующая гипотеза Н1. Ошибка второго рода возникает с вероятностью b в том случае, когда принимается неверная гипотеза Н0, в то время как справедлива конкурирующая гипотеза Н1. Доверительная вероятность – это вероятность не совершить ошибку первого рода и принять верную гипотезу Н0. Вероятность отвергнуть ложную гипотезу Н0 называется мощностью критерия. Следовательно, при проверке гипотезы возможны четыре варианта исходов, табл. 1.1.
Таблица 1.1.
| Гипотеза Н0 | Решение | Вероятность | Примечание |
| Верна | Принимается | 1 - a | Доверительная вероятность |
| Отвергается | a | Вероятность ошибки первого рода | |
| Неверна | Принимается | b | Вероятность ошибки второго рода |
| Отвергается | 1 - b | Мощность критерия |
Например, когда некоторая несмещенная оценка параметра q вычислена по выборке объема n, и эта оценка имеет плотность распределения f(q), рис. 1.1.

Рис. 1.1. Области принятия и отклонения гипотезы
Предположим, что истинное значение оцениваемого параметра равно Т. Если рассматривать гипотезу Н0 о равенстве q=Т, то насколько велико должно быть различие между q и Т, чтобы эту гипотезу отвергнуть. Ответить на данный вопрос можно в статистическом смысле, рассматривая вероятность достижения некоторой заданной разности между q и Т на основе выборочного распределения параметра q.
Целесообразно полагать одинаковыми значения вероятности выхода параметра q за нижний и верхний пределы интервала. Такое допущение во многих случаях позволяет минимизировать доверительный интервал, т.е. повысить мощность критерия проверки. Суммарная вероятность выхода параметра q за пределы интервала с границами q1–a/2 и qa/2, составляет величину a. Эту величину следует выбрать настолько малой, чтобы выход за пределы интервала был маловероятен. Если оценка параметра попала в заданный интервал, то в таком случае нет оснований подвергать сомнению проверяемую гипотезу, следовательно, гипотезу равенства q=Т можно принять. Но если после получения выборки окажется, что оценка выходит за установленные пределы, то в этом случае есть серьезные основания отвергнуть гипотезу Н0. Отсюда следует, что вероятность допустить ошибку первого рода равна a (равна уровню значимости критерия).
Если предположить, например, что истинное значение параметра в действительности равно Т+d , то согласно гипотезе Н0 о равенстве q=Т – вероятность того, что оценка параметра q попадет в область принятия гипотезы, составит b, рис. 1.2.
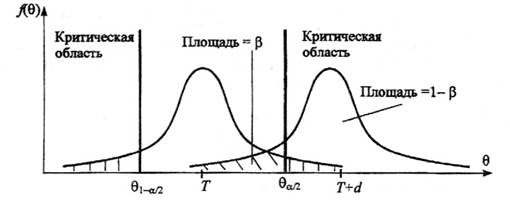
Рис.1.2. Области принятия и отклонения гипотезы
При заданном объеме выборки вероятность совершения ошибки первого рода можно уменьшить, снижая уровень значимости a. Однако при этом увеличивается вероятность ошибки второго рода b (снижается мощность критерия). Аналогичные рассуждения можно провести для случая, когда истинное значение параметра равно Т–d.
Единственный способ уменьшить обе вероятности состоит в увеличении объема выборки (плотность распределения оценки параметра при этом становится более "узкой"). При выборе критической области руководствуются правилом Неймана – Пирсона: следует так выбирать критическую область, чтобы вероятность a была мала, если гипотеза верна, и велика в противном случае. Однако выбор конкретного значения a относительно произволен. Употребительные значения лежат в пределах от 0,001 до 0,2. В целях упрощения ручных расчетов составлены таблицы интервалов с границами q1–a/2 и qa/2 для типовых значений a и различных способов построения критерия.
При выборе уровня значимости необходимо учитывать мощность критерия при альтернативной гипотезе. Иногда большая мощность критерия оказывается существеннее малого уровня значимости, и его значение выбирают относительно большим, например 0,2. Такой выбор оправдан, если последствия ошибок второго рода более существенны, чем ошибок первого рода. Например, если отвергнуто правильное решение "продолжить работу пользователей с текущими паролями", то ошибка первого рода приведет к некоторой задержке в нормальном функционировании системы, связанной со сменой паролей. Если же принято решения не менять пароли, несмотря на опасность несанкционированного доступа посторонних лиц к информации, то эта ошибка повлечет более серьезные последствия.
В зависимости от сущности проверяемой гипотезы и используемых мер расхождения оценки характеристики от ее теоретического значения применяют различные критерии. К числу наиболее часто применяемых критериев для проверки гипотез о законах распределения относят критерии хи-квадрат Пирсона, Колмогорова, Мизеса, Вилкоксона, о значениях параметров – критерии Фишера, Стьюдента.
При проверке гипотез широкое применение находит ряд теоретических законов распределения. Наиболее важным из них является нормальное распределение. С ним связаны распределения хи-квадрат, Стьюдента, Фишера, а также интеграл вероятностей. Для указанных законов функции распределения аналитически не представимы. Значения функций определяются по таблицам или с использованием стандартных процедур пакетов прикладных программ. Указанные таблицы обычно построены в целях удобства проверки статистических гипотез в ущерб теории распределений – они содержат не значения функций распределения, а критические значения аргумента z(a).
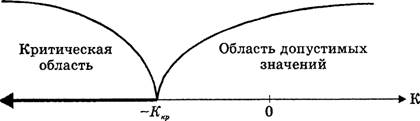
Для односторонней критической области z(a)=z1–a, т.е. критическое значение аргумента z(a) соответствует квантили z1–a уровня 1–a, рис 1.3, так как
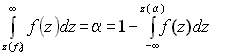 .
.
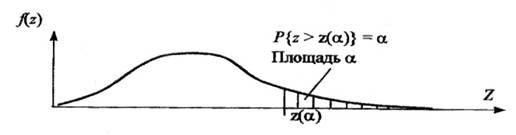
Рис. 1.3. Односторонняя критическая область
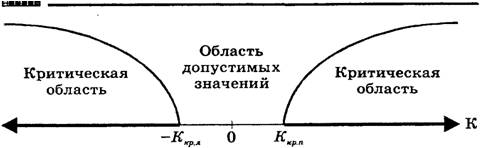
Для двусторонней критической области, с уровнем значимости a, размер левой области a2, правой a1 (a1+a2=a), рис. 1.4. Значения z(a2) и z(a1) связаны с квантилями распределения соотношениями
z(a1)= z1–a1, z(a2)= za2,
так как
 ,
,
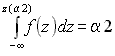
Для симметричной функции плотности распределения f(z) критическую область выбирают из условия a1=a2=a/2 (обеспечивается наибольшая мощность критерия). В таком случае левая и правая границы будут равны |z(a/2)|.
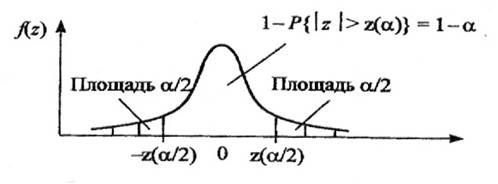
Рис. 1.4. Двусторонняя критическая область
Нормальное распределение
Этот вид распределения является наиболее важным в связи с центральной предельной теоремой теории вероятностей: распределение суммы независимых случайных величин стремится к нормальному с увеличением их количества при произвольном законе распределения отдельных слагаемых, если слагаемые обладают конечной дисперсией. Кроме того, А.М. Ляпунов доказал, что распределение параметра стремится к нормальному, если на параметр оказывает влияние большое количество факторов и ни один из них не является превалирующим. Функция плотности нормального распределения
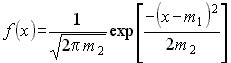
– унимодальная, симметричная, аргумент х может принимать любые действительные значения, рис. 1.5.

Рис. 1.5. Плотность нормального распределения
Функция плотности нормального распределения стандартизованной величины u имеет вид
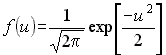 .
.
Вычисление значений функции распределения Ф(u) для стандартизованного неотрицательного аргумента u (u>=0) можно произвести с помощью полинома наилучшего приближения [9, стр. 694]
Ф(u)= 1– 0,5(1 + 0,196854u + 0,115194u2 + 0,000344u3 + 0,019527u4) – 4
Такая аппроксимация обеспечивает абсолютную ошибку не более 0,00025. Для вычисления Ф(u) в области отрицательных значений стандартизованного аргумента u (u<0) следует воспользоваться свойством симметрии нормального распределения
Ф(u) = 1 – Ф(– u).
Иногда в справочниках вместо значений функции Ф(u) приводят значения интеграла вероятностей (для u>0)
![]() , u > 0
, u > 0
Интеграл вероятностей связан с функцией нормального распределения стандартизованной величины u соотношением
Ф(u) = 0,5 + F(u).
Распределение хи-квадрат
Распределению хи-квадрат (c2-распределению) с k степенями свободы соответствует распределение суммы
![]()
квадратов n стандартизованных случайных величин ui, каждая из которых распределена по нормальному закону, причем k из них независимы, n>=k. Функция плотности распределения хи-квадрат с k степенями свободы
![]() , x >= 0,
, x >= 0,
где х=c2, Г(k/2) – гамма-функция.
Число степеней свободы k определяет количество независимых слагаемых в выражении для c2. Функция плотности при k, равном одному или двум, – монотонная, а при k>2 – унимодальная, несимметричная, рис. 1.6.
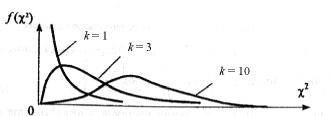
Рис. 1.6. Плотность распределения хи-квадрат
Математическое ожидание и дисперсия величины c2 равны соответственно k и 2k . Распределение хи-квадрат является частным случаем более общего гамма-распределения, а величина, равная корню квадратному из хи-квадрат с двумя степенями свободы, подчиняется распределению Рэлея.
С увеличением числа степеней свободы (k>30) распределение хи-квадрат приближается к нормальному распределению с математическим ожиданием k и дисперсией 2k. В таких случаях критическое значение
c2(k; a) » u1–a(k, 2k),
где u1–a(k, 2k) – квантиль нормального распределения. Погрешность аппроксимации не превышает нескольких процентов.
Распределение Стьюдента
Распределение Стьюдента (t-распределение, предложено в 1908 г. английским статистиком В. Госсетом, публиковавшим научные труды под псевдонимом Student) характеризует распределение случайной величины
![]()
где u0, u1, …, uk взаимно независимые нормально распределенные случайные величины с нулевым средним и конечной дисперсией. Аргумент t не зависит от дисперсии слагаемых. Функция плотности распределения Стьюдента
статистический гипотеза математический ожидание
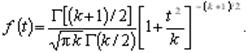
Величина k характеризует количество степеней свободы. Плотность распределения – унимодальная и симметричная функция, похожая на нормальное распределение, рис. 1.7.

Рис. 1.7. Плотность распределения Стьюдента
Область изменения аргумента t от минус до плюс бесконечности. Математическое ожидание и дисперсия равны 0 и k/(k–2) соответственно, при k>2. По сравнению с нормальным распределение Стьюдента более пологое, оно имеет меньшую дисперсию. Это отличие заметно при небольших значениях k, что следует учитывать при проверке статистических гипотез (критические значения аргумента распределения Стьюдента превышают аналогичные показатели нормального распределения). Таблицы распределения содержат значения для односторонней (пределы интегрирования от r(k; a ) до бесконечности)
![]()
или двусторонней (пределы интегрирования от – r(k; a) до r(k; a))
![]()
критической области.
Распределение Стьюдента применяется для описания ошибок выборки при k<30. При k, превышающем 100, данное распределение практически соответствует нормальному, для значений k из диапазона от 30 до 100 различия между распределением Стьюдента и нормальным распределением составляют несколько процентов. Поэтому относительно оценки ошибок малыми считаются выборки объемом не более 30 единиц, большими – объемом более 100 единиц. При аппроксимации распределения Стьюдента нормальным распределением для односторонней критической области вероятность
Р{t>t(k; a)} = u1–a(0, k /(k–2)),
где u1–a(0, k/(k–2)) – квантиль нормального распределения. Аналогичное соотношение можно составить и для двусторонней критической области.
Распределение Фишера
Распределению Р.А. Фишера (F-распределению Фишера – Снедекора) подчиняется случайная величина
х=[(y1/k1)/(y2/k2)],
равная отношению двух случайных величин у1 и у2, имеющих хи-квадрат распределение с k1 и k2 степенями свободы. Область изменения аргумента х от 0 до бесконечности. Плотность распределения
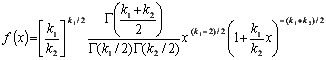 .
.
В этом выражении k1 обозначает число степеней свободы величины y1 с большей дисперсией, k2 – число степеней свободы величины y2 с меньшей дисперсией. Плотность распределения – унимодальная, несимметричная, рис. 1.8.
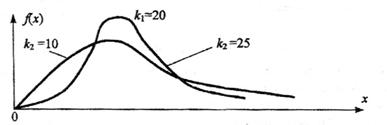
Рис. 1.8. Плотность распределения Фишера
Математическое ожидание случайной величины х
m1 = k2 /(k2–2) при k2>2,
дисперсия
т2 = [2k22(k1 + k2 –2)]/[k1(k2 –2)2(k2–4)] при k 2 > 4.
При k1>30 и k2>30 величина х распределена приближенно нормально:
с центром распределения (k1–k2)/(2k1k2) и дисперсией (k1+k2)/(2k1k2).
Проверка гипотез о законе распределения
Обычно сущность проверки гипотезы о законе распределения ЭД заключается в следующем. Имеется выборка ЭД фиксированного объема, выбран или известен вид закона распределения генеральной совокупности. Необходимо оценить по этой выборке параметры закона, определить степень согласованности ЭД и выбранного закона распределения, в котором параметры заменены их оценками. Пока не будем касаться способов нахождения оценок параметров распределения, а рассмотрим только вопрос проверки согласованности распределений с использованием наиболее употребительных критериев.
Критерий хи-квадрат К. Пирсона
Использование этого критерия основано на применении такой меры (статистики) расхождения между теоретическим F(x) и эмпирическим распределением Fп(x), которая приближенно подчиняется закону распределения c2. Гипотеза Н0 о согласованности распределений проверяется путем анализа распределения этой статистики. Применение критерия требует построения статистического ряда.
Итак, пусть выборка представлена статистическим рядом с количеством разрядов y. Наблюдаемая частота попаданий в i-й разряд ni. В соответствии с теоретическим законом распределения ожидаемая частота попаданий в i-й разряд составляет Fi. Разность между наблюдаемой и ожидаемой частотой составит величину (ni–Fi). Для нахождения общей степени расхождения между F(x) и Fп(x) необходимо подсчитать взвешенную сумму квадратов разностей по всем разрядам статистического ряда
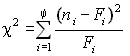 .
.
Величина c2 при неограниченном увеличении n имеет распределение хи-квадрат (асимптотически распределена как хи-квадрат). Это распределение зависит от числа степеней свободы k, т.е. количества независимых значений слагаемых в выражении (3.7). Число степеней свободы равно числу y минус число линейных связей, наложенных на выборку. Одна связь существует в силу того, что любая частота может быть вычислена по совокупности частот в оставшихся y–1 разрядах. Кроме того, если параметры распределения неизвестны заранее, то имеется еще одно ограничение, обусловленное подгонкой распределения к выборке. Если по выборке определяются f параметров распределения, то число степеней свободы составит k=y–f–1.
Очевидно, что чем меньше расхождение между теоретическими и эмпирическими частотами, тем меньше величина критерия. Область принятия гипотезы Н0 определяется условием c2<c2(k; a), где c2(k; a) – критическая точка распределения хи-квадрат с уровнем значимости a. Вероятность ошибки первого рода равна a, вероятность ошибки второго рода четко определить нельзя, потому что существует бесконечно большое множество различных способов несовпадения распределений. Мощность критерия зависит от количества разрядов и объема выборки. Критерий рекомендуется применять при n>200, допускается применение при n>40, именно при таких условиях критерий состоятелен (как правило, отвергает неверную нулевую гипотезу).
Для нормального закона возможные значения случайной величины лежат в диапазоне от минус до плюс бесконечности, поэтому при расчетах оценок вероятностей крайний левый и крайний правый интервалы расширяются до минус и плюс бесконечности соответственно. Вычислить значения функции нормального распределения можно, воспользовавшись стандартными функциями табличного процессора или полиномом наилучшего приближения.
Сумма взвешенных квадратов отклонения c2=1,32. Число степеней свободы
k = 6–1–2=3,
так как уклонения связаны линейным соотношением
![]() ,
,
кроме того, на уклонения наложены еще две связи, ибо по выборке были определены два параметра распределения. Критическое значение c2(3; 0,05)=7,815 определяется по табл. П.3 приложения. Поскольку соблюдается условие c2<c2(3; 0,05), то полученный результат нельзя считать значимым и гипотеза о нормальном распределении генеральной совокупности не противоречит ЭД.
Критерий А.Н. Колмогорова
Для применения критерия А.Н. Колмогорова ЭД требуется представить в виде вариационного ряда (ЭД недопустимо объединять в разряды). В качестве меры расхождения между теоретической F(x) и эмпирической Fn(x) функциями распределения непрерывной случайной величины Х используется модуль максимальной разности
![]()
А.Н. Колмогоров доказал, что какова бы ни была функция распределения F(x) величины Х при неограниченном увеличении количества наблюдений n функция распределения случайной величины
![]()
асимптотически приближается к функции распределения
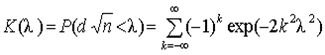 .
.
Иначе говоря, критерий А.Н. Колмогорова характеризует вероятность того, что величина
![]()
не будет превосходить параметр l для любой теоретической функции распределения. Уровень значимости a выбирается из условия
![]() ,
,
в силу предположения, что почти невозможно получить это равенство, когда существует соответствие между функциями F(x) и Fn(x). Критерий А.Н. Колмогорова позволяет проверить согласованность распределений по малым выборкам, он проще критерия хи-квадрат, поэтому его часто применяют на практике. Но требуется учитывать два обстоятельства.
Похожие работы
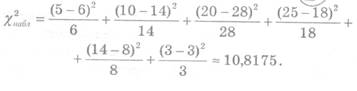
... ошибки первого рода; 3) определить область допустимых значений и так называемую критическую область; 4) принять то или иное решение на основе сравнения фактического и критического значений критерия. Проверка статистических гипотез складывается из следующих этапов: - формулируется в виде статистической гипотезы задача исследования; - выбирается статистическая характеристика гипотезы; - ...
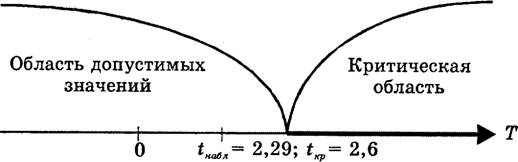
... критических точек распределения ([1], стр. 465), по уровню значимости =0,05 и числу степеней свободы 8-3=5 находим Т.к. , экспериментальные данные не противоречат гипотезе и о нормальном распределении случайной величины . Для случайной величины : Используя предполагаемый закон распределения, вычислим теоретические частоты по формуле , где - объем выборки, - шаг (разность между ...

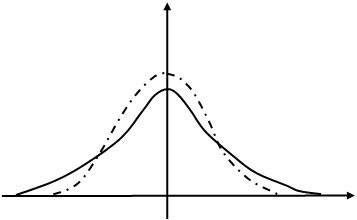
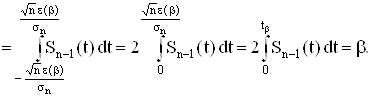
... mx , соответствующий доверительной вероятности b. Действительно, так как то Пользуясь таблицей значений интеграла по значению b найдем величину а следовательно, и сам доверительный интервал le = 2. Проверка статистических гипотез Принятие решения о параметрах генеральной совокупности играет исключительно важную роль на практике. Рассмотрим вопрос о принятии решения на примере ...
... вида выборочного наблюдения; 6) установление сроков проведения наблюдения; 7) определение потребности в кадрах для проведения выборочного наблюдения, их подготовка; 8) оценка точности и достоверности данных выборки, определение порядка их распространения на генеральную совокупность. Представление о статистических данных, как о выборочных, может относиться не только к собственно выборке, но и ...
0 комментариев