Навигация
Модель «большого словаря со сложной структурой», которая заложена в большинство современных программ-переводчиков;
123813
знаков
0
таблиц
0
изображений
1. Модель «большого словаря со сложной структурой», которая заложена в большинство современных программ-переводчиков;
2. Модель «смысл-текст», впервые сформулированная А.А. Ляпуновым, но пока что не реализована ни в одном коммерческом продукте.
На сегодняшний день наиболее известны такие системы машинного перевода, как
- PROMT 2000/XT компании PROMT;
- Retrans Vista компаний Vista и Advantis;
- Сократ – набор программ компании Арсеналъ.
В настоящее время качество машинного перевода оставляет желать много лучшего, и само наличие таких систем пока правильнее воспринимать как предмет научных исследований. В большинстве случаев при работе над проектом применение систем МП не оправдано, поскольку:
- Системы МП не дают приемлемого качества выходного текста. Более высокого качества можно добиться с помощью предварительной настройки системы (продукты серии PROMT XT предоставляют пользователю множество возможностей для этого), что совершенно неприемлемо при небольших объемах переводимого текста, и/или путем последующего редактирования, а это только замедляет работу, если переводчик использует слепой метод печати.
- Системы МП не гарантируют соблюдения единства терминологии, особенно при работе коллектива переводчиков над большим проектом. Вернее, могут гарантировать при условии очень внимательного обращения с пользовательскими словарями, а на это не всегда стоит рассчитывать.
Однако в некоторых случаях использование систем МП все же помогает сократить временные затраты. Это происходит, если текст достаточно объемный и содержит однообразную терминологию, что позволяет сравнительно быстро настроить под него систему МП. Тогда редактирование текста не займет слишком много времени. Однако в этом случае следует особенно внимательно отнестись к стилю текста перевода. Машинный перевод формален, поэтому высока вероятность калькирования синтаксических структур языка оригинала, которое характерно для перевода вообще, а потому вполне может быть пропущено при редактировании.
Вообще говоря, системы МП вполне могут применяться там, где используется максимально стандартизованный язык с простой грамматикой и сравнительно небольшим запасом слов. Довольно успешным проектом системы МП считается немецкая программа Meteo, выполняющая перевод метеопрогнозов с французского языка на английский и обратно. Для облегчения работы переводчиков и технических писателей компанией Boeing в свое время был разработан стандарт языка для написания технической документации, который известен как Boeing English.
Система МП Retrans Vista. Системы машинного перевода текстов с одних естественных языков на другие моделируют работу человека-переводчика. Их эффективность зависит, прежде всего, от того, в какой степени в них учитываются объективные законы функционирования языка и мышления. К сожалению, эти законы пока еще недостаточно изучены. Решая проблему машинного перевода, необходимо учитывать богатый опыт межнационального общения и опыт переводческой деятельности, накопленный человечеством. А этот опыт свидетельствует о том, что в процессе перевода в качестве основных единиц смысла рассматриваются, прежде всего, фразеологические словосочетания, выражающие целостные понятия, а не отдельные слова. Именно понятия являются теми элементарными мыслительными образами, используя которые можно строить более сложные мыслительные образы, соответствующие переводимому тексту.
Условимся называть системы машинного перевода, в которых в качестве основных минимальных единиц смысла рассматриваются не отдельные слова, а фразеологические словосочетания, системами фразеологического машинного перевода. В этих системах отдельные слова также могут использоваться, но они рассматриваются как вспомогательные единицы смысла, к которым приходится прибегать за неимением лучших.
Система фразеологического машинного перевода должна включать в свой состав базу знаний, содержащую переводные эквиваленты для наиболее часто встречающихся фраз, фразеологических сочетаний и отдельных слов, и программные средства для морфологического и синтаксического анализа и синтеза текстов и для их редактирования человеком. В процессе перевода текстов система использует хранящиеся в ее базе знаний переводные эквиваленты в следующем порядке: сначала делается попытка перевести всю фразу как целостную единицу; далее, в случае неудачи, входящие в ее состав словосочетания; и, наконец, осуществляется пословный перевод тех фрагментов текста, которые не удалось перевести первыми двумя способами. Фрагменты выходного текста, полученные всеми тремя способами, должны грамматически согласовываться друг с другом (с помощью процедур морфологического и синтаксического синтеза).
Принципы построения систем фразеологического машинного перевода текстов были впервые сформулированы в 1975 году в предисловии к книге Д. Жукова "Мы переводчики". В более полном виде они были изложены в 1983 году в книге Г. Г. Белоногова и Б. А. Кузнецова "Языковые средства автоматизированных информационных систем". Наконец, в 1993 году были опубликованы две статьи, в которых были описаны система машинного перевода, построенная на этих принципах, и методы автоматизированного составления двуязычных словарей по параллельным (русских и английским) текстам. Важнейшими среди этих принципов являются следующие:
1. Основными единицами языка и речи, которые, прежде всего, следует включать в машинный словарь, должны быть фразеологические единицы (словосочетания, фразы). Отдельные слова также могут включаться в словарь, но они должны использоваться только в тех случаях, когда не удается осуществить перевод, опираясь только на фразеологические единицы.
2. Наряду с фразеологическими единицами, состоящими из непрерывных последовательностей слов, в системах машинного перевода следует использовать и так называемые "речевые модели" - фразеологические единицы с "пустыми местами", которые могут заполняться различными словами и словосочетаниями, порождая осмысленные отрезки речи.
3. Реальные тексты, независимо от их принадлежности к той или иной тематической области, обычно бывают политематическими, если они имеют достаточно большой объем. Поэтому машинный словарь, предназначенный для перевода текстов даже только из одной тематической области, должен быть политематическим, а для перевода текстов из различных предметных областей - тем более. Он должен создаваться, прежде всего, на основе автоматизированной обработки двуязычных текстов, являющихся переводами друг друга, и в процессе функционирования систем перевода.
4. Наряду с основным политематическим словарем большого объема, в системах фразеологического машинного перевода целесообразно использовать также набор небольших по объему дополнительных тематических словарей. Дополнительные словари должны содержать только ту информацию, которая отсутствует в основном словаре (например, информацию о приоритетных переводных эквивалентах словосочетаний и слов для различных предметных областей).
На основе описанных принципов в ВИНИТИ РАН (см. выше) были построены две системы фразеологического машинного перевода:
1) система русско-английского перевода (RETRANS)
2) система англо-русского перевода (ERTRANS).
Обе системы имеют одинаковую структуру и примерно одинаковые объемы машинных словарей. Поэтому мы рассмотрим только первую систему.
Система RETRANS имеет следующие характеристики:
1. Область применения, назначение, функциональные возможности. Система предназначена для автоматизированного перевода научно-технических текстов с русского языка на английский. Русско-английский политематический машинный словарь системы содержит терминологию по естественным и техническим наукам, экономике, бизнесу, политике, законодательству и военному делу. В частности, он содержит термины и фразеологические единицы по следующим тематическим областям: Машиностроение, Электротехника, Энергетика, Транспорт, Аэронавтика. Космонавтика, Робототехника, Автоматика и Радиоэлектроника, Вычислительная Техника, Связь, Математика, Физика, Химия, Биология, Медицина, Экология, Сельское Хозяйство, Строительство и Архитектура, Астрономия, География, Геология, Геофизика, Горное Дело, Металлургия и др.
Перевод текстов может осуществляться в автоматическом и в диалоговом режимах.
2. Объем политематического машинного словаря: более 1.300.000 словарных статей; 77 процентов из них составляют словосочетания длиной от двух до семнадцати слов. Объем дополнительных машинных словарей (для настройки системы на различные тематические области) - более 200.000 словарных статей.
Система МП PROMT XT. В основу программных продуктов компании PROMT поставлено решение следующих фундаментальных проблем:
Во-первых, всем ясно, что чем больше словарь, тем лучше перевод, значит, первая проблема - проблема создания больших словарей для систем.
Во-вторых, ясно, что система должна переводить такие предложения: ПРИВЕТ, КАК ДЕЛА? Значит, еще одна проблема - научить систему распознавать устойчивые обороты.
В-третьих, понятно, что предложение для перевода пишется по определенным правилам, по определенным правилам переводится, а значит есть еще одна проблема: записать все эти правила в виде программы. Вот, собственно, и все.
Самое интересное, что эти проблемы действительно являются основными при разработке систем машинного перевода, другое дело, что методы их решения известны далеко не всем и отнюдь не так просты, как может показаться.
Методы организации больших баз данных достаточно хорошо разработаны, но для перевода не менее, а может быть, и более важно правильно структурировать информацию, которая приписывается элементу базы, правильно выбрать этот самый элемент. Сколько, например, записей в словаре должно соответствовать обыкновенному русскому слову "программа"? И, вообще, большой словарь - это словарь, который содержит много словарных статей, или словарь, который позволяет распознать много слов из текста? Очевидно, более верно второе. Поэтому для описания и входного, и выходного языка в системе должен существовать некоторый формальный метод описания морфологии, на котором основывается выбор единицы словаря.
Практически во всех системах, которые претендуют на то, чтобы считаться системами перевода, проблема представления морфологических моделей так или иначе решается. Но одни системы могут распознать миллион словоформ при объеме словаря в пятьдесят тысяч словарных статей, а другие при объеме словаря в сто тысяч словарных статей могут распознать именно эти сто тысяч.
В системах семейства PROMT разработано практически уникальное по полноте морфологическое описание для всех языков, с которыми системы умеют обращаться. Оно содержит 800 типов словоизменений для русского языка, более 300 типов, как для немецкого, так и для французского языка, и даже для английского, который не принадлежит к флективным языкам, выделено более 250 типов словоизменений. Множество окончаний для каждого языка хранится в виде древесных структур, что обеспечивает не только эффективный способ хранения, но и эффективный алгоритм морфологического анализа.
Кроме того, используемая модель морфологии позволила разработать экспертную систему для пользователя - создателя словаря. Эта система фактически автоматизирует процедуру выделения основы и определения типа словоизменения при вводе новых словарных статей.
Такой возможности нет ни в одной из существующих систем машинного перевода, даже в таких распространенных системах как Power Translator (Globalink, США), Language Assistant (MicroTac, США), TRANSEND (Intergaph,США), где пользователям приходится вручную спрягать и склонять слова для задания морфологической модели.
Однако разработка описания морфологии позволяет решить только проблему того, что является заголовком словарной статьи, по которому происходит идентификация единицы текста и единицы словаря. Но ведь идентификация слова из текста со словарной статьей происходит не ради идентификации, как это требуется в спеллерах или электронных словарях, она необходима для выполнения программой собственно процедур перевода. Какая же нужна информация в словарной статье и как должны быть описаны правила перевода для того, чтобы программа переводила?
Во многих системах МП в прошлом (как, впрочем, и сейчас) словарное описание и описание алгоритмов рассматривались как стороны одной проблемы, но решение, как правило, искалось в ограничении рассматриваемого мира, либо грамматического, либо семантического. Например, на основе признака "принадлежность к части речи" описывалась грамматика такого типа:
именная группа - это существительное
именная группа - это прилагательное + именная группа
глагольная группа - это глагол + именная группа
предложение - это именная группа + глагольная группа
Понятно, что некоторая часть предложений естественного языка описывается такой грамматикой, но эта часть очень незначительна, и на ее основе нельзя правильно анализировать и переводить хоть сколько-нибудь реальный текст. Но зато можно использовать эффективные методы построения преобразователя по заданной грамматике или, на худой конец, написать программу, которая путем перебора построит древа зависимостей для ограниченного множества предложений. Такие системы точно так же получали определения "экспериментальные".
Так или иначе, но именно из таких проектов появились системы перевода, которые сейчас предлагаются конечному пользователю. Это и Power Translator (компания Globalink) и Language Assistant (компания MicroTac) и TRANSEND (компания Intergraph).
Системы семейств STYLUS и PROMT - не исключение, поскольку многие специалисты компании PROMT имели опыт работы в такого типа проектах. Однако при разработке систем PROMT впервые был применен фактически революционный подход, который и позволил получить впечатляющие результаты. Системы перевода семейства PROMT - это системы, спроектированные на основе не лингвистических, а кибернетических методов.
Оказалось, что очень продуктивно рассматривать систему перевода не как транслятор, задачей которого является перевод текста, допустимого с точки зрения входной грамматики, а как некоторую сложную систему, задачей которой является получение результата при произвольных входных данных, в том числе и для текстов, которые не являются правильными для грамматики, с которой работает система.
Вместо принятого лингвистического подхода, предполагающего выделение последовательных процессов анализа и синтеза предложения, в основу архитектуры систем было положено представление процесса перевода как процесса с "объектно-ориентированной" организацией, основанной на иерархии обрабатываемых компонентов предложения. Это позволило сделать системы PROMT устойчивыми и открытыми.
Кроме того, такой подход дал возможность применения различных формализмов для описания перевода разных уровней. В системах работают и сетевые грамматики, близкие по типу к расширенным сетям переходов, и процедурные алгоритмы заполнения и трансформаций фреймовых структур для анализа сложных предикатов.
Описание лексической единицы в словарной статье, которое фактически не ограничено по размерам и может содержать множество различных признаков, тесно взаимосвязано со структурой алгоритмов системы и структурировано не на основе извечной антитезы синтаксис - семантика, а на основе уровней компонентов текста.
При этом системы могут работать и с не полностью описанными словарными статьями, что является важным моментом при открытии словарей для пользователя, от которого нельзя требовать тонкого обращения с лингвистическим материалом.
Первая система машинного перевода, выпущенная компанией PROMT в 1991 году, переводила с английского языка на русский специализированные тексты по программному обеспечению. Она использовала небольшой словарь - около 17 тыс. слов и выражений, работала в среде ДОС и не имела средств настройки для пользователя. Но уже эта первая система была правильно устроена, и нынешняя технология разработки алгоритмов машинного перевода, применяемая в компании PROMT, не претерпела значительных изменений. Напротив, найденный тогда подход оказался очень плодотворным для самых разных языков.
Сначала поясним некоторые определения: вместе с развитием машинного перевода как области прикладной лингвистики появились и классификации систем, и стало принято делить системы перевода на системы типа TRANSFER и системы типа INTERLINGUA. Это разделение основано на особенностях архитектурных решений для лингвистических алгоритмов.
Алгоритмы перевода для систем типа TRANSFER строятся как композиция трех процессов: анализ входного предложения в терминах структур входного языка, преобразование этой структуры в аналогичную структуру выходного языка (TRANSFER) и затем синтез выходного предложения по полученной структуре.
Системы типа INTERLINGUA предполагают априори наличие некоторого метаязыка структур (INTERLINGUA), на котором можно описать все структуры как входного, так и выходного языков в общем случае; поэтому алгоритм перевода в системе типа INTERLINGUA предполагается как более простой: анализ входного предложения в терминах метаязыка и затем синтез из метаструктуры соответствующего предложения выходного языка. "Единственная" сложность в этом случае - разработать сам метаязык и описать естественный язык в соответствующих терминах.
Несмотря на то, что эта классификация существует, и в среде разработчиков машинного перевода считается хорошим тоном спросить, к какому типу относится система PROMT, не было разработано еще не одной реальной системы, основанной на принципе INTERLINGUA.
Система PROMT не является исключением, и на этот вопрос мы отвечаем: наша система выполняет перевод типа TRANSFER. Но это очень простой ответ, он практически не отражает особенностей архитектуры системы PROMT. А особенности состоят в том, что этот метод (TRANSFER) применен в системе не в соответствии с лингвистическим стандартным подходом.
Дело в том, что система перевода, как правило, работает в условиях не полностью описанных данных, ведь в язык - это живая система, которая развивается очень быстро: постоянно появляются новые слова, новые функции старых слов, и, вместе с новыми сущностями, новые значения. В этих условиях определяющим структурным свойством алгоритмов перевода становится их устойчивость к произвольным входным данным, и в основу алгоритмов, выполняющих перевод в системе PROMT, вместо последовательного TRANSFER'а был заложен иерархический подход, разделяющий процесс перевода на взаимосвязанные TRANSFER'ы для разных единиц анализа.
В системе выделяется уровень лексических единиц, уровень групп, уровень простых предложений и уровень сложных предложений. Все эти процессы связаны и взаимодействуют иерархически в соответствии с иерархией текстовых единиц, обмениваясь синтезируемыми и наследуемыми признаками. Такое устройство алгоритмов позволяет использовать разные формальные методы для описания алгоритмов разных уровней.
Рассмотрим уровень лексических единиц: лексическая единица - это слово или словосочетание, которое является единицей самого низкого уровня. И в случае входного, и в случае выходного языка слово описывается как совокупность основы и окончания. Это обеспечивает возможность, с одной стороны, распознавания входных слов и анализа входной морфологии и, с другой стороны, удобного синтеза выходных слов по их морфологической информации (основа, тип словоизменения и адрес окончания в массиве окончаний этого типа). Таким образом, если ввести правила преобразования входной морфологической информации в выходную морфологическую информацию, осуществляется TRANSFER на морфологическом уровне.
Уровень групп рассматривает структуры более сложные: группы существительных, прилагательных, наречий и сложные глагольные формы. Этот уровень при анализе, основываясь на формальных сетевых грамматиках, умеет соединять группы в синтаксические единицы, каждая из которых характеризуется синтезированной структурной информацией и главным элементом группы. По входной структуре, полученной в терминах непосредственных составляющих, вместе с синтезированными признаками формируется выходная группа как набор лексических единиц со значениями морфологических признаков, которые могут наследоваться исходя из результатов анализа группы. Таким образом, реализуется TRANSFER на уровне групп.
Анализ простых предложений как структур, состоящих из синтаксических единиц, выполняется на основе фреймовых предикатных структур, которые позволяют эффективно выполнять преобразования. Глагол считается для простых предложений главным элементом и его валентности определяют заполнение соответствующего фрейма. Для каждого типа фреймов существует некоторый закон преобразования в выходной фрейм и оформление актантов. Таким образом, осуществляется TRANSFER на уровне предложений. Анализ сложных предложений требуется в случае формирования согласования времен и правильного перевода союзов.
Глава IV. ПРАКТИЧЕСКАЯ ЧАСТЬ
Чтобы лучше понять принципы действия систем МП и их методы использования словарей и анализа грамматики, равно как и синтеза структур на выходном языке, следует на практике перевести несколько текстов (желательно различных по функциональному стилю и тематике), используя одну из вышеописанных систем машинного перевода. Наиболее целесообразным представляется использование системы МП PROMT XT, поскольку она является самой последней на данный момент версией ряда продуктов PROMT и объективно лучшей из доступных.
Возьмем в качестве первого примера следующую логическую задачку:
"You are given 12 identical-looking coins, one of which is counterfeit and weighs slightly more or less (you don't know which) than the others. You are given a beam balance which lets you put the same number of coins on each side and observe which side (if either) is heavier. How can you identify the counterfeit and tell whether it is heavy or light, in 3 weighings?"
Вот ее 'вольный' перевод на русский язык, который мог бы быть сделан человеком - переводчиком:
"У вас есть 12 одинаковых по виду монет, одна из которых - фальшивая и весит немного больше или меньше, чем остальные (вы не знаете, какая именно). Имеются рычажные весы, на чаши которых вы можете класть равное число монет и смотреть, какая из чаш перевесила (или весы остались в равновесии). Как за 3 взвешивания определить фальшивую монету и узнать, легче она или тяжелее остальных?"
При переводе переводчику пришлось поменять порядок слов в нескольких предложениях. А вот как переводит этот текст система автоматического перевода семейства PROMT (использовалась PROMT XT):
"Вам дают 12 идентично-выглядящих монет, одна из которых - подделка и весит немного более или менее (Вы не знаете который) чем другие. Вам дают баланс луча, который позволяет Вам помещать то же самое число {номер} монет на каждой стороне и наблюдать {соблюдать}, какая сторона (если любой) более тяжел. Как Вы можете идентифицировать подделку и сказать, тяжело ли это или легко, в 3 взвешиваниях?"
Обратим внимание на "баланс луча". Эта ошибка вызвана, как легко понять, отсутствием в словаре словосочетания "beam balance", означающего "рычажные весы". Очевидно, что варианты перевода слов (данные в фигурных скобках) - вторые значения соответственных слов во входном языке. Таким образом, отбирая, исходя из контекста, наиболее вероятные значения слов, программа PROMT иногда затрудняется выдать однозначный вариант, оставляя, таким образом, право выбора за редактором-переводчиком. Однако справедливости ради, нужно отметить, что в обоих случаях двоякого толкования слова программой в данном тексте, в качестве наиболее вероятных были выбраны именно правильные значения.
Немного смущает фраза "если любой", употребленная в тексте в скобках. Во-первых, очевидно, что грамматически текст данный в скобках никак программой не связывается с текстом за скобками - отсюда и разница в роде: сущ. сторона - ж.р. ед. ч.; и мест. любой - м.р. ед. ч. Во-вторых, вероятно фраза "if any" представляет собой одно единое семантическое целое - в своем роде клише официального стиля. Доказательством тому служит присутствие выражения "if any" в словаре ABBY Lingvo7.0 в качестве отдельной словарной статьи:
"if any - если это имеет место
At the start of every month I have to send him an account of my earnings, if any. — В начале каждого месяца я должен посылать ему отчет о моих заработках, если таковые имелись."
Поэтому упущением создателей системы PROMT является пословный перевод этой фразеологической единицы. Следующим существенным недостатком является очевидное 'нежелание' системы менять порядок слов в предложении - иногда это жизненно необходимо. То есть в выходном языке порядок слов почти всегда такой же, как и во входном.
Общеизвестно, что в английские существительные утратили грамматическую категорию рода. Поэтому почти все они согласуются с местоимением 3 лица ед. числа "it" - среднего рода. В русском же языке категория рода у существительных присутствует и в 3-м лице ед. числе они согласуются с тремя разными местоимениями в зависимости от грамматического рода. Так вот, система PROMT, синтезируя текст на выходном языке не учитывает возможность согласования существительного и местоимения, его заменяющего в роде. Примером может служить последнее предложение текста: "How can you identify the counterfeit and tell whether it is heavy or light, in 3 weighings?". Переведено оно следующим образом: "Как Вы можете идентифицировать подделку и сказать, тяжело ли это или легко, в 3 взвешиваниях?" Перевод слов "It" и "counterfeit" не согласуются в роде: подделка - женского рода, это - среднего рода; более того - не видя связи между двумя этими словами, программа-переводчик вместо личного местоимения подставляет указательное.
В качестве второго примера возьмем начало Декларации Независимости США. Здесь мы увидим перевод программой PROMT XT текста, написанного в официально-деловом стиле в конце XVIII века. Вот оригинал текста:
"When in the course of human events, it becomes necessary for one people to dissolve the political bands which have connected them with another, and to assume among the powers of the earth, the separate and equal station to which the laws of nature and of nature's God entitle them, a decent respect to the opinions of mankind requires that they should declare the causes which impel them to the separation. We hold these truths to be self-evident, that all men are created equal, that they are endowed by their creator with certain unalienable rights, that among these are life, liberty and the pursuit of happiness, that to secure these rights, governments are instituted among men, deriving their just powers from the consent of the governed..."
Как мы видим, этот текст далеко не прост с точки зрения восприятия: предложения длинные, много придаточных предложений и однородных членов. С другой стороны, несмотря на то, что тексту более 225 лет, в нем нет слов или грамматических конструкций, которые были бы непонятны человеку, знающему английский язык хотя бы на уровне носителя. В тесте не используются слова, значения, которых устарели бы и поэтому единственной сложностью является большой объем предложений и относительная сложность их конструкции. Далее следует перевод этого текста, сделанный человеком переводчиком:
"Когда в ходе человеческой истории для одного народа становится необходимым порвать политические узы, связывающие его с другим, и занять среди наций мира самостоятельное и равное положение, присвоенное ему в силу естественного права и законов Божественной Природы, — уважение к мнениям человечества требует декларации причин, вынуждающих его к отделению. Мы считаем самоочевидными следующие истины: что все люди созданы равными, что они наделены Создателем определенными неотъемлемыми правами, среди которых имеется право на жизнь, свободу и на стремление к счастью; что для обеспечения этих прав существуют среди людей правительства, осуществляющие свою власть с согласия тех, кем они управляют…"
А вот перевод этого текста, осуществленный системой PROMT XT:
"Когда в ходе человеческих событий, это становится необходимым для одного людей расторгнуть {распустить} политические полосы{оркестры}, которые соединили их с другим, и принимать среди полномочий земли, отдельная и равная станция, на которую законы характера{природы} и Бога характера{природы} дают право им, приличное уважение{отношение} к мнениям относительно человечества требует, чтобы они объявили причины, которые побуждают их к разделению. Мы считаем эти истины быть самоочевидными, что все мужчины созданы равными, что они обеспечены их создателем с некоторыми неотъемлемыми правами, которые среди них являются жизнью, свободой и преследованием счастья, что, чтобы обеспечить эти права, правительства назначены{установлены} среди мужчин, получая их справедливые полномочия от согласия управляемых..."
Как мы видим, с таким текстом у системы машинного перевода возникает больше проблем. Здесь можно даже не упоминать выбора неправильных значений слов, таких как People, bands, station. Основываясь на данном образце перевода текста, можно воочию, так сказать, увидеть все несовершенство механизмов грамматического анализа и синтеза.
В отношении грамматического синтеза, с другой стороны, сказать можно не так много. Ну, например, выходной вариант "дают право им" не соответствует норме языка с точки зрения порядка слов. Таким образом, при синтезе грамматических структур на выходном языке, мы опять-таки видим жесткую привязку к порядку слов в тексте на входном языке. Затем, такая фраза как "мы считаем эти истины быть самоочевидными…" сильно напоминает речь иностранца, 'изучившего' русский язык посредством разговорника. А ведь программа писалась русскими специалистами! Однако в данном случае, лингвистов, участвовавших в создании систем PROMT в незнании грамматики родного языка обвинить нельзя. Ведь проблема здесь не в синтезе грамматической структуры, а все в том же непонимании структуры входного языка - то есть в грамматическом анализе.
Грамматический анализ, как мы видим, находится на самом примитивном уровне. Да, простые предложения система переводит (да и то, как мы убедились - не все) почти без ошибок. Сложносочиненные, да и классические примеры сложноподчиненных предложений тоже даются системе с относительной легкостью. Однако как только возникает нестандартная ситуация (например, одно придаточное предложение усложняется другим (или даже элементарное вводной или пояснительной конструкцией) и, как следствие, разрывается) и программа не находит подходящего алгоритма грамматического анализа - она сразу забывает о синтаксисе и начинает элементарный пословный перевод, формально (посредством флексий) пытаясь связать хотя бы рядом стоящие слова. Эта попытка связать грамматически рядом стоящие слова вкупе неправильным выбором значений некоторых слов еще более запутывает выходной вариант.
Язык - это живая структура, которая не поддается полной алгоритмизации и, следовательно, посредством одних лишь алгоритмов проблему машинного перевода не решить. Машина не понимает текст, она лишь преобразовывает его посредством различных алгоритмов и правил. И не важно, сколько будет этих правил, без хотя бы общего понимания входного текста не может быть сколько-нибудь связного и стабильного процесса перевода. На уровне простых предложений и в рамках строго определенной тематики машинный перевод в принципе возможен, но не более.
Заключение.
До уровня полной автоматизации перевода человечество еще не дошло, да и дойдет, вероятно, не скоро. Причиной этому является, вероятно, недостаточный уровень развития наук, затронутых в создании подобных систем. Слишком сложно сказать, как человек переводит - а тем более сложно смоделировать этот процесс с помощью компьютерной программы. Тем более сложно сделать это, если учесть, что человек мыслит образами, а научить этому компьютер - невозможно в принципе (по крайней мере, на настоящем уровне развития ЭВМ).
Возьмем, к примеру, неопределенный артикль "a". Если человеку с определенным багажом лингвистических знаний сказать фразу "неопределенный артикль "а", в его сознании моментально возникает несколько образов - начиная от звуковой формы данного артикля и заканчивая образом неопределенности, каким бы у данного человека этот образ ни был. Однако даже для самой современной компьютерной системы фраза "неопределенный артикль "а" обозначает лишь последовательность из двухсот-восьми единиц и нулей, составляющих бинарный эквивалент литерной величины "неопределенный артикль "а". Поэтому-то научить ЭВМ самостоятельно осуществлять адекватный перевод текстов в принципе невозможно на данном этапе развития. Язык образен и не поддается полной алгоритмизации, а посему проблема полной автоматизации перевода сводится следующей проблеме: научить машину мыслить и оперировать образами - а эта проблема уже из области проблем искусственного интеллекта, создание которого все еще является чем-то из области фантастики.
Другое дело, что уже теперь мы можем использовать достижения науки и техники для облегчения работы человека во всех сферах его деятельности. Конечно, применимость ЭВМ может быть где-то более актуальна, а где-то - менее. Тем не менее, ЭВМ применимы везде, более того - уровень их применимости постоянно растет. Справедливо это и для автоматизации процесса перевода. Если машины и не могут пока осуществлять адекватный перевод самостоятельно, то служить серьезным подспорьем для переводчика они вполне в состоянии. При их грамотном использовании эффективность перевода может возрасти в несколько раз, причем качество перевода не снизится, а наоборот - повысится (взять, к примеру, те же системы Translation Memory).
Таким образом, говоря о наиболее перспективных путях развития систем автоматизации перевода, следует, вероятно, сосредоточиться на том, что выполнимо на данный момент, то есть на создании более эффективных электронных словарей с как можно более эффективным механизмом поиска и индексации, с как можно более интегрированной системой словарных статей. Если же брать во внимание развитие систем Машинного Перевода, то наиболее перспективным направлением здесь окажется совершенствование подсистем грамматического анализа и синтеза, а также увеличение объема контекстуального охвата текста и совершенствование семантических цепочек с целью более точного подбора значений слов.
Библиография
1) http://courier.com.ru/nauka/diction1.htm#up ("Что внутри электронного словаря?");
2) http://mcbsys.com/;
3) http://osp.admin.tomsk.ru/school/1999/2/06.htm;
4) http://school.ort.spb.ru/library/informatica/compmarket/internet/transl.htm ("Интернет: кое-что в помощь переводчику", Ильдар Кутыев);
5) http://www.a-z.ru/person/belonogov/index.htm#I0
6) http://www.computerra.ru/ ("Что могут словари?" Денис Зельцер);
7) http://www.krugosvet.ru/articles/82/1008256/1008256a1.htm;
8) http://www.lingvoda.ru/transforum/articles/pdf/selegey_a1.pdf ("Электронные словари и компьютерная лексикография", Владимир Селегей, компания ABBY);
9) http://www.mtoday.com/article_m.htm (Анна Марченко, центр переводов "Гильдия");
10) http://www.promt.ru/mtw/articles/article_Sokolova.phtml ("Как переводит компьютер", Автор:Соколова Светлана);
11) http://www.promt.ru:8000/mtw/class.phtml;
12) http://www.promt.ru:8000/mtw/developer.phtml;
13) http://www.svoboda.org/programs/sc/2001/sc.050101.asp (Александр Костинский);
14) www.multilex.ru;
15) А. САВИНА, Т. ТИПИКИНА («Наука и жизнь» 1999, N 9);
16) Владимир Самусенко, "Электронный словарь - друг человека" 24.02.1999, Компьютер в школе, #2/1999;
17) Г. Г. Белоногов, Ю. Г. Зеленков,"Б. А. Кузнецов, А. П. Новоселов, Александрдр А. Хорошилов, Алексей А. Хорошилов. Автоматизация составления и ведения словарей для систем фразеологического машинного перевода текстов с русского языка на английский и с английского на русский. Сб. "Научно-техническая информация", Сер. 2, | 12, ВИНИТИ, 1993;
18) Г. Г. Белоногов, Ю. Г. Зеленков,"Б. А. Кузнецов, А. П. Новоселов, Н. А. Пащенко, Александрдр А. Хорошилов, Алексей А. Хорошилов. Интерактивная система русско-английского и англо-русского машинного перевода политематических научно-технических текстов. Сб. "Научно-техническая информация", Серия 2, | 3, ВИНИТИ, 1993.
19) З.М.Шаляпина "АВТОМАТИЧЕСКИЙ ПЕРЕВОД: ЭВОЛЮЦИЯ И СОВРЕМЕННЫЕ ТЕНДЕНЦИИ" (Вопросы языкознания, 1996, №2, с.105-117);
20) Сергеев В.Н. Словари – наши друзья и помощники. – М.: Просвещение, 1984.
Похожие работы
... и наблюдателя (экперимент М. Стормса) Рисунок 4 3.3. Г.М. Андреева, Н.Н. Богомолова, Л.А. Петровская. Теории диадического взаимодействия (Андреева Г.М., Богомолова Н.Н., Петровская Л.А. Современная социальная психология на Западе (теоретические направления). М.: Изд-во Моск. ун-та, 1978. С. 70-83) Бихевиористская ориентация включает в качестве одного из методологических принципов ...
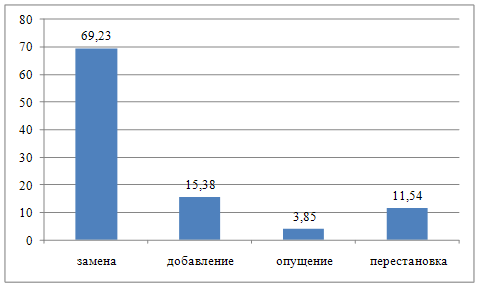
... в процессе перевода научно-технического стиля составляют замены и перестановки. Гораздо реже встречаются опущения и дополнения. В заключение можно сказать, что все рассмотренные особенности перевода научно–технических текстов свидетельствуют о важности изучения данной темы, и дальнейшего подробного изучения ее со всех сторон. Список использованных источников 1. Гореликова С. Н. Природа ...
В чем причина их успеха и для чего они нужны? Компьютер – это универсальное средство для хранения, обработки и передачи информации. Он способен делать массу полезного и тем самым облегчать жизнь пользователю – работающему за компьютером человеку. Мы живем в мире компьютеров. Они играют существенную роль в нашей работе, образовании, досуге и в средствах общения. Кассиры в банках, агенты бюро ...
... этих стран характерен высокий статус национальных профессиональных объединений управляющих документацией, а также общественный интерес к вопросам документационного обеспечения управления. 2.1 Управление электронными документами в Австралии Деятельность архивных органов в Австралии в области нормативно-методического регулирования вопросов управления документацией в настоящее время является ...
0 комментариев