Имеются данные по предприятиям (Y1, Х5 и Х6 - см. таблицу).
Вычислить группировку, характеризующую зависимость между (Yi) и (Хi). Построить ряд распределения с равными интервалами по (Хi).
Определить обобщающие показатели ряда:
среднюю величину;
моду;
медиану;
квартили;
среднее квадратичное отклонение;
дисперсию;
коэффициент вариации;
скошенность.
Представить ряд на графике, отметить на нем средние величины и сделать выводы о характере распределения.
Построить кореляционное поле связи между (Yi) и (Xi). Сделать предварительный вывод о характере связи. Определить параметры уравнения парной регрессии и коэффициент кореляции.
Определить параметры уравления парной регрессии (Yi) от (Xi) и (Xj) и коэффициент частной и множественной кореляции.
Сделать выводы.
ИДЕНТИФИКАТОРЫ:
Y1 - средняя выработка на 1 рабочего (тыс. рублей);
X5 - коэффициент износа основных фондов %
X6 - удельный вес технически обоснованных норм выработки %.
Выделим сделующие неравные интервалы:
до 23 на 1 раб.
От 23 до 26
От 26 до 29
Свыше 29%.
Результаты группировки представим в таблице:
| X2 | f2 | X5 | Y1 |
| до 23 кВт | 8 | 21.7 | 8.3 |
| от 23 до 26 кВт | 19 | 24.4 | 7.8 |
| от 26 до 29 кВт | 8 | 27.1 | 7.8 |
| свыше 29 кВт | 5 | 29.6 | 7.7 |
| Всего: | 40 |
Таблица показывает что с увеличением (группировочный признак) возрастает среднее значение других исследуемых показателей, следовательно между этими показателями существует связь, которая требует специального исследования.
Поставим задачу:
Выполнить группировку и построить вариационный ряд, характеризующий распределение по (Х5).
Для этого необходимо найти величину интервала i, которая находится по формуле: i = Xmax – Xmin ;
n
Поскольку число n берется произвольно, примем его равным 5.
Отсюда i = 30 – 20 = 2
5
Теперь установим следующие группы ряда распределения:
| X5 | f2 | fн | a | af | af |
| 20,0—22,0 | 5 | 5 | -2 | -10 | 20 |
| 22,0—24,0 | 8 | 13 | -1 | -8 | 8 |
| 24,0—26,0 | 16 МАХ | 29 | 0 | 0 | 0 |
| 26,0—28,0 | 4 | 33 | 1 | 4 | 4 |
| 28,0-30,0 | 7 | 40 | 2 | 14 | 28 |
| | 40 | 0 | 60 |
На основе ряда распределения определим обобщающие показатели ряда.
Пусть условная величина А равна 25, тогда момент m1 находим по формуле:
m1 = af ; m1 = 0 = 0
f 40
отсюда средняя величина находится по формуле: Х = А + im1;
Х = 25+2 (0) = 25
2. Находим моду по формуле: Мо = Хо + i d1 ;
d1 + d2
где d1 = 8; d2 = 12; Xo = 24; i = 2.
Mo = 24 + 2 8 = 24,8;
8 + 12
3. Находим медиану по формуле: Ме = Хо + i Nме - S1 ;
fме
где Хо = 24; S1 = 13; fме = 16; i = 2
Nме = f + 1; Nме = 20.5
2
итак Ме = 24 + 2 20.5 – 13 = 24,9 ~25.
16
Рассчитываем квартели по формулам:
первая Q1 = ХQ1 + i NQ1 – SQ1-1;
fQ1
третья Q3 = XQ3 + i NQ3 – SQ3-1;
fQ3
NQ1=Ef+1 =40+1 =10.25
4
NQ3= 30.75
XQ1= 22 SQ-1=5
FQ1=8
Q1=22+2 10.25-5 = 23.31
8
Q3=XQ3+i NQ3-SQ3-1
FQ3
XQ3=26 SQ3-1 = 29
FQ3=4
Q3= 26+2 30.75-29 = 26.87
4
Показатели вариации.
Вариационный размах по коэффициенту износа основных фондов.
1.вариационный размах
R=X max -X min
R= 30.0-20.0=10.0
Рассчитаем квадратичное отклонение по способу моментов
= i m2- (m1)
m1 найдено ранее = 0
M2 вычислим по формуле m2 = Ea 2f
Ef
M2= 60 = 1.5
40
= 2 1.5-(0)2
Похожие работы
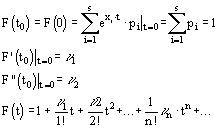
... Доказать: По определению второй смешанной производной. Найдем по двумерной плотности одномерные плотности случайных величин X и Y. Т.к. полученное равенство верно для всех х, то подинтегральные выражение аналогично В математической теории вероятности вводится как базовая формула (1) ибо предлагается, что плотность вероятности как аналитическая функция может не существовать. Но т.к. в нашем ...
... распределения генеральной совокупности F(x) и – эмпирической функция распределения Fn(x) , построенной по выборке х1,…,хn, называется функция. Теорема. Если F(x) непрерывна, то распределения статистики Колмогорова Dn не зависит от F(x). Условные математические ожидания и условные распределения. Св-ва условных мат. ожиданий. Аналоги формул полной вероятности и формулы Байеса для мат. ожиданий ГММЕ ...
... дает возможность статистического моделирования, происходящих в населении процессов. Потребность в моделировании возникает в случае невозможности исследования самого объекта. Наибольшее число моделей, применяемых в статистике населения, разработано для характеристики его динамики. Среди них выделяются экспоненциальные и логистические. Особое значение в прогнозе населения на будущие периоды имеют ...
... на задний план традиционными постановками. Несколько лет назад при описании современного этапа развития статистических методов нами были выделены [29] пять актуальных направлений, в которых развивается современная прикладная статистика, т.е. пять "точек роста": непараметрика, робастность, бутстреп, интервальная статистика, статистика объектов нечисловой природы. Обсудим их. 5. ...
0 комментариев