Навигация
Лабораторные работы по Теории вычислительных процессов и структур
42177
знаков
10
таблиц
1
изображение
Министерство образования Российской Федерации
Саратовский государственный технический университет
ЛАБОРАТОРНАЯ РАБОТА №1
Лексический анализ входного языка транслятора
лабораторная работа по курсу «Теория вычислите-
льных процессов и структур» для студентов
специальности 220400 (ПВС)
Составил доцент кафедры ПВС
Сайкин А.И.
Саратов, 2001 г.
Введение
Данная лабораторная работа предназначается для студентов специальности ПВС изучающих «Теорию вычислительных процессов и структур». Лабораторная работа рассчитана на 4 аудиторных часа и 6 часов самостоятельной работы по составлению
программы, изучение литературы и составление отчёта.
Объект исследования - трансляторы с алгоритмических языков программирования. Процесс трансляции с алгоритмического языка можно условно разбить на три этапа: лексический анализ, грамматический разбор и генерацию машинного кода. В данной работе рассматривается задача построения лексического анализатора
входного текста транслятора.
Цель работы состоит в составлении программы (сканера) производящей лексический анализ текста, соответствующего заданному алфавиту и грамматике алгоритмического языка.
Программа составляется на языках Паскаль и С++ по выбору студента в среде WINDOWS.
1. Содержание работы.
Этап лексического анализа текста исходной программы выделяется в самостоятельный этап работы транслятора, как с методической целью, так и с целью сокращения времени компиляции программы. Последнее достигается за счёт того, что
исходная программа в виде последовательности символов, преобразуется на этапе лексической обработки к некоторому стандартному виду, что облегчает дальнейший анализ.
Под лексическим анализом понимают процесс предварительной обработки исходной программы, на котором основные лексические единицы программы - лексемы: ключевые слова, идентификаторы, метки, константы приводятся к единому формату и заменяются условными кодами или ссылками на соответствующие таблицы, а коментарии исключаются из текста программы. Результатом лексического анализа является список лексем-дескрипторов и таблицы. В таблицах хранятся значения выделенных в программе лексем.
Дескриптор- это пара вида: ( . < указатель>),
где - это, как правило, числовой код класса лексемы, который означает, что лексема принадлежит одному из конечного множества классов слов, выделенных в языке программирования;
- это может быть либо начальный адрес области основной памяти, в которой хранится адрес этой лексемы, либо число, адресующее элемент таблицы, в которой хранится значение этой лексемы.
Количество классов лексем в языках программирования может быть различным. Наиболее распространёнными классами являются:
идентификаторы;
служебные (ключевые) слова;
разделители;
константы.
Могут вводиться и другие классы. Это обусловлено в первую очередь той ролью, которую играют различные виды слов при написании исходной программы и переводе её в машинную программу. При этом наиболее предпочтительным является разбиение всего множества слов, допускаемых в языке программирования, на такие классы, которые бы не пересекались между собой. В общем случае все выделяемые классы являются либо конечными (ключевые слова, разделители и др.) - классы фиксированных для данного языка программирования слов, либо
бесконечными или очень большими (идентификаторы, константы, метки)- классы переменных для данного языка программирования слов.
С этих позиций коды лексем (дескрипторы) из конечных классов всегда одни и те же в различных программах для данного компилятора. Коды же лексем из бесконечных классов различны для разных программ и формируются всякий раз на этапе лексического анализа.
В ходе лексического анализа значения лексем из бесконечных классов помещаются в таблицы соответствующих классов. Конечность таблиц объясняет ограничения, существующие в языках программирования на длины и соответственно число используемых в программе идентификаторов и констант.
Числовые константы перед помещением их в таблицу могут переводиться из внешнего символьного во внутреннее машинное представление. Содержимое таблиц, в особенности таблицы идентификаторов, в дальнейшем пополняется на этапе семантического анализа исходной программы и используется на этапе генерации объектной программы.
В работе требуется составить программу лексического анализатора (сканер) входного текста для транслятора, которая бы
составляла таблицы и производила бы кодирование идентификаторов, разделителей и констант. Производила бы проверку правильности написания ключевых слов операторов, стандартных функций и использование служебных символов.
Производила бы отображение теста программы с комментариями и исключала бы их из текста, подлежащего трансляции. Отображала
дескрипторный текст.
2. Задание по работе.2.1. Получить вариант задания у преподавателя.
2.2. В соответствии с выданным вариантом выполнить следующее:
2.2.1. Составит техническое задание (ТЗ) на разработку программы сканера, производящей лексический анализ произвольных текстов в пределах установленного алфавита.
2.2.2. Согласовать ТЗ с преподавателем.
2.2.3. Разработать программу-сканер на языках
Паскаль, С++ или в интегрированных средах по собственному усмотрению.
2.2.4. Провести тестирование программы, особенно для всех случаев выдачи пользователю сообщений об ошибках.
2.2.5. Составить отчёт по работе и приложить к нему ТЗ.
3. Варианты заданий.
Вариант задания включает номер, состоящий из трёх цифр.
Первая цифра означает выбор алфавита входного языка, вторая цифра означает выбор заданных ключевых слов входного языка и третья цифра означает выбор заданных библиотечных функций.
Таблица 1. Алфавит входного языка.
| № | Алфавит |
| 1 | Латинский, строчные буквы |
| 2 | Латинский, заглавные буквы |
| 3 | Кириллица, строчные буквы |
| 4 | Кириллица, заглавные буквы |
| 5 | Латинский, строчные + заглавные |
| 6 | Кириллица, строчные + заглавные |
Таблица 2. Ключевые слова.
| № | Дополнительные ключевые слова |
| 1 | Описание циклов, массивов |
| 2 | Описание операторов перехода, структуры типа switch |
| 3 | Описание безусловных переходов, описание функций |
Таблица 3. Библиотечные функции.
| № | Стандартные функции |
| 1 | sin, cos, tan, exp |
| 2 | sqrt, log, ln, nearby |
| 3 | abs, fact, code, sign |
Например, 1-2-3 означает, что из первой таблицы необходимо выбрать первую строку, из второй таблицы - вторую строку, из третьей таблицы - третью строку.
Для всех вариантов задаётся общая часть в которую входит следующее. Ключевые слова обозначающие начало и конец программы, описание типа, ввод и вывод, присваивание.
Разделители : +, -, *, :, _, /, (, ), {, }, =, , [, ], ;, “, ‘ , ‘,’ и про-
бел.
Идентификаторы должны начинаться с буквы, не включать в себя разделители, количество позиций не должно превышать 14.
Текст программы должен допускать использование комментариев.
4. Методические указания.
Рассмотрим основные идеи, которые лежат в основе построения
лексического анализатора, и проблемы, возникающие при его разра-
ботке.
Первоначально в тексте входной программы сканер выделяет последовательность символов, которая по его предположению должна быть словом в программе, т.е. лексемой. Может выделяться не вся последовательность, а только один символ, который считается началом лексемы. Это сделать просто, если слова в программе отделяются друг от друга специальными разделителями,
например, пробелами или запрещено использование служебных слов в качестве переменных, либо классы лексем распознаются по вхождению первых символов лексемы.
Затем, проводится идентификация лексемы. Она заключается
в сборке лексемы из символов, начиная с выделенного на предыдущем этапе, и проверки правильности записи лексемы данного класса.
Идентификация лексемы из конечного класса выполняется путём сравнения её с эталонным значением. Основная проблема здесь - минимизация времени поиска эталона. В общем случае может понадобиться полный перебор слов данного класса, особенно, если выделенное слово содержит ошибку. Уменьшить время поиска можно, используя различные методы ускоренного поиска: упорядоченный список, линейный список, метод расстановки и др.
Для идентификации из очень больших классов используются специальные методы сборки лексем с одновременной проверкой правильности написания. В этих методах применяется формальный математический аппарат- теория регулярных языков и конечных распознавателей.
При успешной идентификации значение лексемы из бесконечного класса помещается в таблицу идентификации лексем данного класса. При этом осуществляют проверку: не хранится ли уже там значение данной лексемы, т.е. необходимо проводить просмотр элементов таблицы. Таблица при этом должна допускать расширение. Опять же для уменьшения времени доступа к элементам таблицы она должна быть специальным образом организована, при этом должны использоваться специальные методы ускоренного поиска элементов.
После проведения успешной идентификации лексемы формируется её образ - дескриптор, он помещается в выходные данные лексического анализатора. В случае неуспешной идентификации формируется сообщение об ошибках в написании слов программы.
В ходе лексического анализа могут выполняться и другие виды лексического контроля, в частности, проверяться парность скобок и других парных символов, наличие метки у оператора, следующего за GOTO и т.д.
Результаты работы сканера передаются в последствии на вход синтаксического анлизатора. Имеется две возможности их связи:
раздельная связь и нераздельная связь.
При раздельной связи выходные данные сканера формируются полностью и затем передаются синтаксическому анализатору. При нераздельной связи, когда синтаксическому анализатору требуется очередной образ лексемы, он вызывает лексический анализатор, кото-
рый генерирует дескриптор и возвращает управление синтаксическому анализатору.
Второй вариант характерен для однопроходных трансляторов.
Таким образом, процесс лексического анализа достаточно прост, но может занимать значительное время трансляции.
Рассмотрим конкретный пример. Пусть нам дана программа на
некотором алгоритмическом азыке:
PROGRAM PRIMER;
VAR X,Y,Z : REAL;
BEGIN
X:=5;
Y:=6;
Z:=X+Y;
END;
Применим следующие коды для типов лексем:
К1- ключевое слово;
К2- разделитель;
К3- идентификатор;
К4- константа.
Лексический анализ можно производить, если нам задан алфавит,
список ключевых слов языка и служебных символов. Пусть всё это
имеется. Тогда внутренние таблицы сканера примут следующий вид.
Таблица 4. Ключевые слова.
| № | Ключевое слово |
| 1 | PROGRAM |
| 2 | BEGIN |
| 3 | END |
| 4 | FOR |
| 5 | REAL |
| 6 | VAR |
Таблица 5. Разделители.
| № | Разделители |
| 1 | ; |
| 2 | , |
| 3 | + |
| 4 | - |
| 5 | / |
| 6 | * |
| 7 | : |
| 8 | = |
| 9 | . |
Результат работы сканера таблица идентификаторов и таблица констант
Таблица 6. Идентификаторы.
| № | Идентификаторы |
| 1 | PRIMER |
| 2 | X |
| 3 | Y |
| 4 | Z |
Таблица 7. Константы.
| № | Знач. констант |
| 1 | 5 |
| 2 | 6 |
На основании составленных таблиц можно записать входной текст через введённые дескрипторы (дескрипторный текст):
( К1, 1) (К3, 1) (K2, 1)
( K1, 6) (K3, 2) (K2, 2) (k3, 3) ( K2, 2) (K3, 4) ( K2, 7) (K1, 5) (K2, 1)
( K1, 2)
( K3, 2) (K2, 7) (K2, 8) (K4, 1) (K2, 1)
( K3, 3) (K2, 7) (K2, 8) (K4, 2) (K2, 1)
( K3, 4) (K2, 7) (K2, 8) (K3, 2) (K2, 3) (K3, 3) (K2, 1)
( K1, 3) (K2, 9).
6. Содержание отчёта.
1. Титульный лист.
2. Вариант задания.
3. Полный список выбранных ключевых слов и стандартных функций.
4. Внутренние таблицы сканера.
5. Техническое задание на разработку сканера (по ЕСПД).
6. Отладочные примеры работы сканера с выходными таблицами и дескрипторным текстом.
7. Контрольные вопросы.
1. Дайте определение грамматики.
2. Назовите этапы трансляции программы.
3. Что такое лексема?
4. В чём состоят задачи лексического анализа?
5. Дайте определение метаязыка.
6. Исходные данные для сканера.
7. Результаты работы сканера.
8. Литература.
1. Бек Л. Введение в системное программирование. М,: Мир, 1988.
-448 с.
2. Компаниец Р.И. и др. Системное программирование.Основы
построения трансляторов.- СПб.: КОРОНА принт, 2000.-256 с.
6
Министерство образования Российской Федерации Саратовский государственный технический университет
Применение конечных автоматов в лексическом анализе
лабораторная работа для студентов
специальности ПВС по курсу « Теория
вычислительных процессов и структур»
Составил доцент кафедры ПВС
Сайкин А.И.
Саратов, 2001 г.
Введение.
Данная лабораторная работа рассчитана на четыре аудиторных часа и ещё четыре часа для изучения материала и оформление отчёта.
Объект исследования процесс трансляции заданного языка программирования в машинные коды. Цель изучения состоит в применении математического аппарата конечных автоматов при лексическом анализе. Лексический анализ это начальный этап трансляции, за которым следуют грамматический разбор и этап генерации машинного кода. Наиболее трудоёмким по затратам машинного времени является этап лексического анализа. Для сокращения общего времени трансляции и упрощения лексического анализа целесообразно использовать математический аппарат конечных автоматов. Метод исследований как раз и базируется на его применении.
Выполнение работы производится в дисплейном классе. Характер исследований состоит в сочетании результатов, полученных на ПЭВМ с их аналитической обработкой студентом.
1. Содержание работы.
Разработка лексического анализатора выполняется достаточно просто, если воспользоваться хорошо разработанным математическим аппаратом - теорией регулярных языков и конечных автоматов. В рамках этой теории классы однотипных лексем (идентификаторы, константы и т.д.) рассматриваются как формальные языки (язык идентификатороф, язык констант и т.д.), множество предложений которых описывается с помощью соответствующей порождающей грамматики. При этом языки эти настолько просты, что они порождаются простейшей из грамматик - регулярной грамматикой. Построенная регулярная грамматика является источником, по которому в дальнейшем конструируется вычислительное устройство, реализующее функцию распознаваний предложений языка, порождаемого данной грамматикой. Для регулярных языков таким устройством является конечный автомат.
Порождающая грамматика G(N,T,P,S), продукции которой имеют вид АаВ или Св, где А,В,С - нетерминальные символы; а,в- терминальные символы, называется регулярной или автоматной. Язык L(G), порождаемый регулярной грамматикой называется регулярным или автоматным или языком с конечным числом состояний. Основной задачей лексического анализа является распознавание лексических единиц. Математической моделью процесса распознавания регулярного языка является вычислительное устройство, которое называется конечным автоматом. Термин «конечный» подчёркивает то, что вычислительное устройство имеет фиксированный конечный объём памяти и обрабатывает последовательность входных символов, принадлежащих некоторому конечному множеству. Существуют различные типы конечных автоматов, если результатом работы является лишь указание на то, что входная последовательность символов допустима или нет, то такой конечный автомат называется конечным распознавателем.
В данной лабораторной работе необходимо построить конечные автоматы для каждого типа распознаваемых лексем. Проводя лексический анализ, конечные автоматы должны сообщать о допустимости или не допустимости конкретных лексем. Программа лексического анализатора должна распечатывать входной текст и выдавать сообщения обо всех недопустимых лексемах. Hеобходимо также составить техническое задание на разрабатываемую программу лексического анализатора.
2. Варианты заданий.
Вариант задания по второй лабораторной работе совпадает с вариантом задания по первой лабораторной работе, т.е. входным для лексического анализатора будет текст программы, составленный из заданного алфавита и заданных ключевых слов в соответствие с вариантом задания первой лабораторной работы.
3. Методические указания.
Любая регулярная грамматика G=(N,T,P,S) может быть представлена направленным графом, с помеченными узлами и дугами. Каждый узел помечаем символом из N. Кроме одного конечного узла, который помечаем символом #. Согласно принятым соглашениям, узел, соответствующий начальному символу S помечаем стрелкой, а конечный изображаем в виде прямоугольника. Каждая дуга графа соответствует только одной продукции заданной грамматики G.
Например, пусть регулярная грамматика G имеет следующие продукции:
SaA|bB
AaA|a
BbB|b,
тогда граф, отображающий данную грамматику G, будет иметь вид, представленный на рис.1. Путь на графе всегда соединяет начальную вершину с конечной вершиной графа. Метки, ассоциированные с дугами, составляющими этот путь, образуют некоторую строку. Множество таких строк совпадают с языком L(G). Конкретные пути на графе будут соответствовать некоторой схеме вывода. Например, SaAaaAaaaA
aaaa, т.е. от S к А, от А к А, от А к #. Конечный направленный граф, имеющий начальный узел и один или более конечных узлов сети - есть конечный автомат.
![]()
a



a
![]()
![]()
![]()
b
a
#
b

![]()

![]()
![]()
b
Рис.1. Граф конечного автомата.
Можно дать и второе определение конечного автомата. Конечным автоматом (КА) называется совокупность пяти множеств:
КА={N, T, t, S, F}
где : N-конечное множество состояний автомата, совпадающее с множеством нетерминальных символов грамматики;
T-множество терминальных символов автомата, совпадающее с множеством терминальных символов грамматики;
t-функция переходов, задаваемая таблицей;
S- начальное состояние автомата;
F-конечные состояния автомата.
Ф![]()
ункция
переходов может
быть представлена
различными
способами.
Основные из
них: списком
команд КА, диаграммой
состояний и
матрицей переходов.
Команда КА
представляет
собой следующую
запись:
(A i, a j)A k
которая представляет собой переход в автомате из вешины А i в вершину А k по дуге, отмеченной a j. Для КА необходимо составлять список таких команд, причём он должен обязательно содержать переходы в конечную вершину, для нормального завершения работы автомата.
Диаграмма состояний это по сути граф КА. И он содержит полную информацию об КА.
Матрица переходов может быть записана в двух видах. Во-первых, строки матрицы - это вершины КА (нетерминальные символы), столбцы матрицы - терминальные символы, приписываемые соответствующим дугам графа КА. Элементы матрицы - это состояния КА, в которые осуществляется переход. По второму способу матрица переходов записывается в три колонки, соответствующие командам КА. Естественно, что все три способа равнозначны.
КА могут быть детерминированными ДКА и недетерминированными НДКА. В детерминированном автомате из каждой вершины выходят дуги, отмеченные все различными метками. В НДКА имеется хотя бы одна вершина с одинаково отмеченными дугами. Для программирования ДКА гораздо проще. ДКА и НДКА по существу задают эквивалентные языки, но имеет место теорема, что ДКА может принять некоторый язык L, если этот язык принимает НДКА. Переход от НДКА к ДКА осуществляется тривиально, за счёт введения дополнительных фиктивных состояний. Если из одной вершины выходит две дуги, обозначенные одинаково (НДКА), то одну дугу обозначаем по другому, но замыкаем её на фиктивное состояние, из которого проводим ранее переобозначенную дугу к требуемому состоянию (ДКА).
Для практических целей необходимо, чтобы КА сам определял момент окончания входной цепочки символов с выдачей сообщения о правильности или неправильности входной цепочки символов. Для этих целей входная цепочка считается ограниченной справа концевым маркером, в качестве которого могут использоваться обычные разделители. И в диаграмму состояний КА водятся интерпретированные состояния: допустить входную цепочку как лексему, отвергнуть входную цепочку как лексему, запомнить ошибку во входной цепочке.
В общем случае может быть предложен следующий порядок конструирования лексического анализатора (ЛА).
1. Выделить во входном языке L(G) на основании описания его синтаксиса множество классов лексем.
2. Построить для каждого класса автоматную (регулярную) грамматику.
3. Для каждой автоматной грамматики построить КА.
4. Определить условия выхода из ЛА ( переход его в начальное состояние) при достижении конца произвольной лексемы из каждого класса лексем.
5. Разбить символы входного алфавита на непересекающиеся множества.
6. Построить матрицу переходов ЛА.
7. Выбрать формат и код образов лекскм-дескрипторов (см. первую лабораторную работу).
8. Запрограммировать ЛА.
4. Содержание отчёта.В соответствии с вариантом задания каждый студент сотавляет отчёт по работе, в который входят:
1. Титульный лист.
2. Вариант задания.
3. Техническое задание на разработку программы ЛА.
4. Описание программы ЛА.
5. Работающая программа ЛА (демонстрация работы при отчёте).
6. Выводы по работе.
5. Контрольные вопросы.
1. Как задаётся формальная грамматика?
2. Как определяется регулярная грамматика?
3. Чем отличаются сентенции и сентенциальные формы?
4. Что такое лексема?
5. В чём смысл работы ЛА?
6. Назовите основные этапы проектирования ЛА.
7. Как задаётся КА?
8. Как преобразовать НДКА в ДКА?
Литература.
1. Бек Л. Введение в системное программирование. М.: Мир, 1988.
-448 с.
2. Компаниец Р.И. и др. Системное программирование. Основы
построения трансляторов.- СПб.: КОРОНА принт 2000.-256 с.
Министерство образования Российской Федерации
Саратовский государственный технический университетФормульный компилятор
методические указания к выполнению лабораторной
работы по курсу «Теория вычислительных процессов
и структур для студентов специальности ПВС
Составил доцент кафедры ПВС
Сайкин А.И.
Саратов - 2001 г.
Введение
Данная лабораторная работа рассчитана на четыре аудиторных часа. Самостоятельная работа по изучению литературы, оформление отчёта ещё шесть часов.
Объект исследования формульный транслятор, Цель исследования состоит в изучении проблематики разработки трансляторов с алгоритмических языков. Метод предполагает использование алгоритма рекурсивного спуска и написание программы транслятора. Работа выполняется в дисплейном классе.
Похожие работы
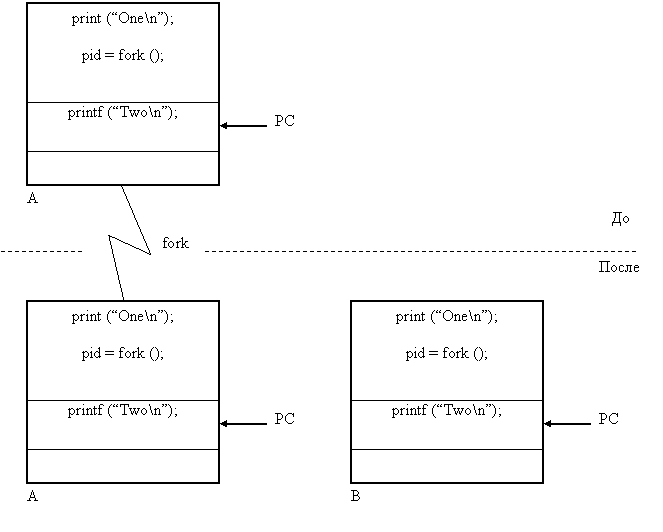
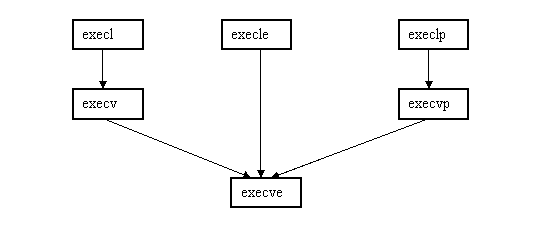
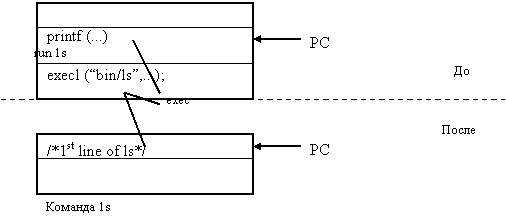
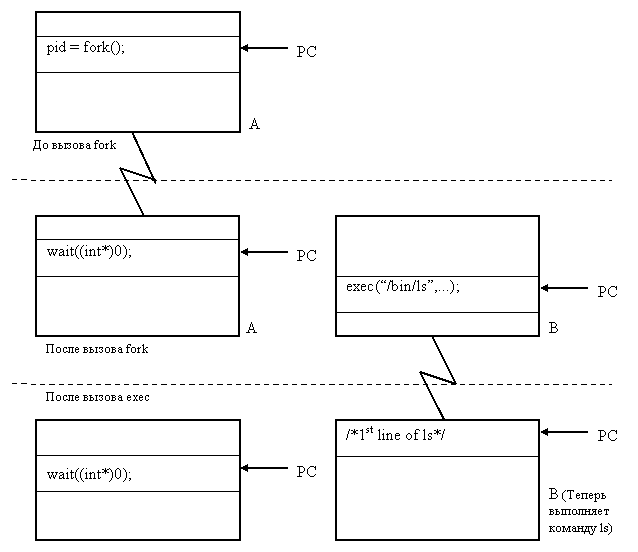
... процессом init (процесс, идентификатор которого pid = 1, становится их новым родителем). Порядок выполнения работы 1. Изучить теоретическую часть лабораторной работы. 2. Организовать функционирование процессов следующей структуры: 2.1. Отец формирует нумерованные сообщения вида: N pid time (N –текущий номер сообщения, pid – pid процесса, time – время записи в формате мм.сс (минуты. ...
... работы со справочной системой работа практикума приостанавливается. 3. Организационно-экономическое обоснование проекта В ходе дипломного проекта был разработан компьютерный лабораторный практикум по курсу «Теория оптимизации и численные методы». В данном разделе рассмотрена экономическая сторона проекта. Рассмотрены следующие вопросы: 1) сетевая модель 2) расчёт ...
... концентрических окружностей с уменьшающимся радиусом по мере затухания колебаний скорости и момента. Аналогичная картина наблюдается при ступенчатом набросе нагрузки. 5. РАЗРАБОТКА ВИРТУАЛЬНОЙ ЛАБОРАТОРНОЙ РАБОТЫ НА БАЗЕ ВИРТУАЛЬНОЙ АСИНХРОННОЙ МАШИНЫ Иную возможность анализа АД представляет специализированный раздел по электротехнике Toolbox Power System Block. В его библиотеке имеются блоки ...
... гистерезисная диаграмма поляризации сегнетоэлектрика. Подобрать масштаб по вертикальной оси осциллографа так, чтобы изображение занимало весь экран. Внимание: в процессе выполнения последующих пунктов лабораторной работы не допускается изменять положение масштабного переключателя осциллографа. Измерить и записать в табл. 6.2 координаты вершины гистерезисного цикла: xm, ym (координаты вершины ...
0 комментариев