Навигация
5. Память для структур
Существует несколько альтернатив для определения новых
типов данных как структур, составленных из типов данных,
определенных ранее. Величины такого типа мы называем
структурными величинами. Существуют различные подходы к
реализации этих конструкций. Отличия обычно касаются следующих
вопросов:
Как выделять память для структурных величин?
Как строить структурные величины?
Как ссылаться на компоненту структурной величины?
Как освобождать память?
Записи по Хоору
Определение нового типа данных имеет вид
RECORD <идентификатор> ( <компонента>,
<компонента>, . . . , <компонента> )
где каждая компонента имеет вид
<простой тип> <идентификатор>
Причем <простой тип> является одним из основных типов языка -
REAL, INTEGER, POINTER и т.д. Здесь во время компиляции известны
все характеристики всех компонент, включая тип данных, на которые
могут ссылаться указатели. Во время счета не нужны описатели ни
для самой структуры, ни для ее компонент, причем может быть
сгенерирована эффективная программа.
Любая структурная величина с n компонентами может храниться в
памяти в виде:
┌──────────────┬──────────────┬─────────┬──────────────┐
│ Компонента 1 │ Компонента 2 │ ... │ Компонента n │
└──────────────┴──────────────┴─────────┴──────────────┘
Поскольку при компиляции известны все характеристики, то
известен также объем памяти, необходимый для каждой компоненты,
и, следовательно, компилятор знает смещение каждой компоненты
относительно начала структурной величины. Для упрощения сбора
мусора лучше всего присвоить номер каждому типу данных ( включая
типы, определенные программистом) и иметь описатель для каждого
указателя. Описатель будет содержать номер, описывающий тип
величины, на которую в данный момент ссылается указатель.
Память для указателей и их описателей может быть выделена
компилятором в области данных, с которой они связаны; это не
трудно, так как они имеют фиксированную длину. Для хранения
текущих значений структурных величин может быть использована
отдельная статическая область данных и специальная программа для
выделения памяти в этой области. В рассматриваемых языках нет
явного оператора для освобождения памяти, так что, когда память
исчерпана, система обращается к программе "сбора мусора".
Заметим, что для того, чтобы иметь возможность обнаружить мусор,
нужно знать, где расположены все указатели, включая те, которые
являются компонентами структурных величин.
Структуры PL/1
Более сложную конструкцию имеют структуры, в которых
компоненты могут сами иметь подкомпоненты. Пример таких
структур - структуры языка PL/1. Такая структура есть дерево,
узлы которого связаны с именами компонент, а концевые узлы
имеют значения данных.
Если бы возможность иметь подкомпоненты была бы
единственным различием между записями по Хоору и структурами
PL/1 не было бы существенной разницы во время выполнения
программы; можно было бы разместить все компоненты и
подкомпоненты так, чтобы каждая имела фиксированное смещение
относительно начала структуры и это смещение было бы известно во
время компиляции. Однако в языке PL/1 существует еще два
расширения. С целью экономии памяти атрибут CELL для компоненты
требует, чтобы все ее подкомпоненты непременно занимали одно и
тоже место в памяти. В любое заданное время только одна из
нескольких переменных может иметь значение. Присваивание значения
подкомпоненте приводит к тому, что подкомпонента, к которой
обращались ранее утрачивает свое значение.
Подобная возможность вызовет осложнения во время компиляции,
но в действительности не очень изменяет код готовой программы,
если только объектная программа не должна проверять при каждом
обращении к подкомпоненте, что значение подкомпоненты
действительно существует.
Для другого расширения требуются более сложные
административные функции во время выполнения программы. В PL/1
корневой узел структурного дерева или любая из подкомпонент могут
быть снабжены размерностями.
Так как выражения, которые определяют границы изменения
индексов, должны быть вычислены при выполнении программы, для
них, как и в случае массивов, следует употреблятъ опители, или
информационные векторы. Т.е. нам необходимы информационные
векторы для всех компонент имеющих размерность большую единицы.
Структуры данных по Стендишу
Следующий шаг в развитии - структуры данных, которые не
могут быть реализованы эффективно, но которые богаче и мощнее.
Структуры данных предложенные Стендишом изменяются во время
работы программы. Динамически могут изменяться не только
размерности компонент, но и число компопонент и их типы.
Обычно во время компиляции ничего не известно, а все делается
во время выполнения программы на основе описателей, которые
сами строятся в это же время.
Во время выполнения программы необходимо хранить описатель
для каждой структурной величины. Действительно, этот описатель
аналогичен набору элементов таблицы символов, используемому
компилятором при компиляции, скажем, структур PL/1. Такие
описания структур лучше всего реализуются в виде дерева, где
для каждого узла должно быть по крайней мере известно:
1) концевой ли это узел или нет;
2) если узел концевой, то каков его тип;
3) если узел концевой, то указатель на значение, если
таковое существует;
4) если узел не концевой, то указатели на узлы для
подкомпонент;
5) размерности подкомпонент.
Всякий раз при обращении к значению компоненты должен быть
проинтерпретирован описатель. Начиная с корневого узла, находится
путь к узлу, к которому обращаются, проверяется тип этого узла и,
наконец, используется или изменяется его значение.
Похожие работы
... 12 Библиографический список................................................................. 15 Введение Целью работы является демонстрация работы с динамической памятью на примере программ разработанных к заданиям 2, 6, 8, 10, 12, 14, 16 из методического указания [1]. Динамическое распределение памяти предоставляет программисту большие возможности при обращении к ресурсам памяти в ...
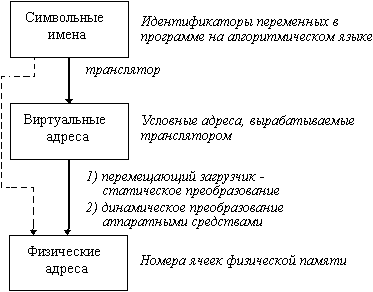
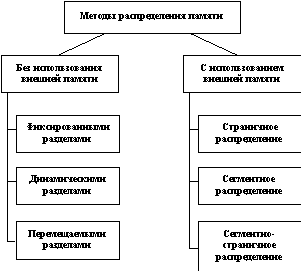
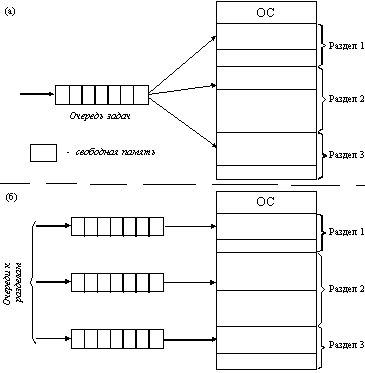
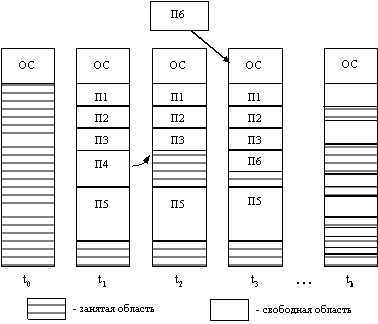
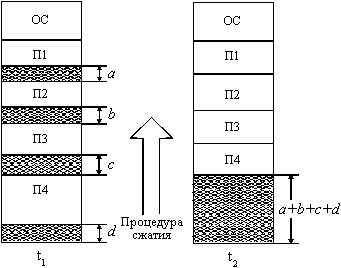
... задачи П4 место загружается задача П6, поступившая в момент t3. Рис. 2.10. Распределение памяти динамическими разделами Задачами операционной системы при реализации данного метода управления памятью является: ведение таблиц свободных и занятых областей, в которых указываются начальные адреса и размеры участков памяти, при поступлении новой задачи - анализ запроса, просмотр ...
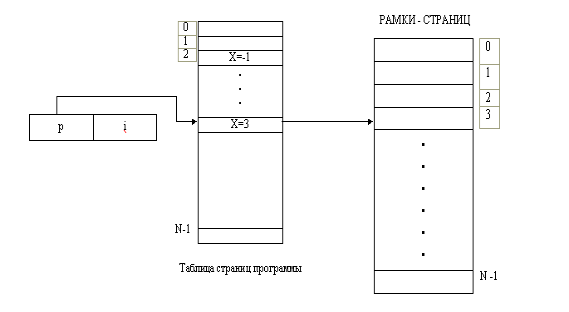
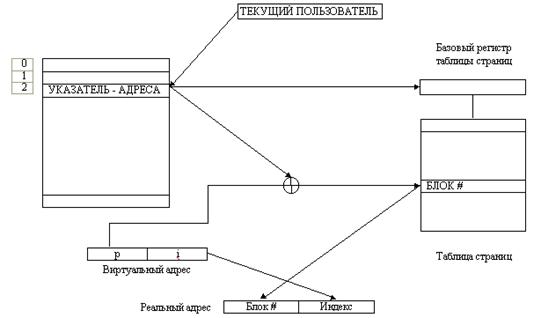
... .) В системах, в которых страницы инструкций (в противоположность страницам данных) являются реентерабельными, бит изменения никогда не устанавливается. 2. Разработка алгоритма управления оперативной памятью Ниже приведён алгоритм управления оперативной памятью в системе Linux. В основе всего лежат страницы памяти. В ядре они описываются структурой mem_map_t. typedef struct page { /* ...
... новые следы памяти могут поступать в активном или неактивном состоянии. Именно это свойство лежит в основе исключительно важного феномена — так называемого латентного обучения. Концепция состояний памяти свободна от условного деления на кратковременную и долговременную и потому может объяснять феномены, которые остаются непонятными с точки зрения временного подхода к организации памяти. То, что ...
0 комментариев