Навигация
Динамическое распределение памяти
46448
знаков
0
таблиц
0
изображений
7. Динамическое распределение памяти
Для некоторых языков требуется схема динамического
распределения памяти во время выполнения программы, когда блоки
внутренней памяти выделяются, используются и затем освобождаются
для последующего использования.
Существуют два основных метода общего распределения памяти.
В обоих методах вызывается некоторая программа GETAREA(ADDRESS,
SIZE) для того, чтобы выделить область из SIZE ячеек; программа
записывает в ячейку ADDRESS, адрес этой области. В первом методе
память должна освобождаться "явно" посредством вызова программы
FREEAREA(ADDRESS,SIZE). Во втором методе память "явно" не
освобождается. Вместо этого в тех случаях, когда GETAREA не
может найти область необходимого размера, она вызывает программу
FREEGARBAGE для того, чтобы найти те области во внутренней
памяти, которые не используются программой, и вернуть их системе.
Кроме того она может уплотнить используемые области - сдвинуть
их вместе, чтобы все свободные ячейки были в одном блоке.
Опишем один из способов реализации первого метода.
Метод помеченных границ для распределения памяти
Распределение памяти происходит следующим образом. Когда
начинает выполняться программа, в качестве свободной памяти
используется один большой блок ячеек. При выполнении программы
может несколько раз вызываться GETAREA. Каждый раз она выделяет
необходимые ячейки, начиная от начала свободного блока памяти, и
блок приобретает следующий вид:
┌────────┬────────┬─────────┬────────┬──────────────────────┐
│ Занято │ Занято │ ... │ Занято │ Свободно │
└────────┴────────┴─────────┴────────┴──────────────────────┘
Заметим, что размеры занятых областей могут быть
разными. В некоторый момент будет вызвана FREEAREA, чтобы
освободить одну из использованных областей, вообще говоря, не
последнюю. После нескольких вызовов GETAREA и FREEAREA блок
может выглядеть так:
┌────────┬────────┬──────────┬─────────┬────────┬──────────┐
│ Занято │ Занято │ Свободно │ ... │ Занято │ Свободно │
└────────┴────────┴──────────┴─────────┴────────┴──────────┘
где по-прежнему размеры областей различны. Система должна
помнить расположение всех свободных областей, с тем чтобы они
могли быть снова использованы. Более того, смежные свободные
области следует сливать в одну свободную область так, чтобы
память не оказалась разбитой на области, слишком малые для
использования.
Описываемый нами метод помеченных границ принадлежит
Кнуту. Метод требует резервирования для системных нужд 2-х
ячеек на границах каждой области ( одной в начале и одной в
конце ). Это приемлемая плата, так как в случаях, в которых
применяется этот метод, требуются довольно большие области,
например области данных процедур и память для массивов.
Преимущество этого метода в том, что необходимо по существу
фиксированное время, чтобы освободить область и объединить ее
со смежными свободными областями, если это возможно. В других
методах для этой цели требуется просмотр некоторого списка.
Ниже приводится формат каждой занятой и свободной области.
Первое слово содержит поле TAG, которое указывает, свободна ли
область или нет; в поле SIZE содержится число слов области.
Свободные области связываются вместе в двусвязанный список. Поле
FLINK (ссылка вперед) указывает на следующую область списка, в
то время как поле BLINK (ссылка назад) указывает на предыдущую
область.
┌─────┬──────┬───────┬───────┐ первое ┌─────┬──────┬───────────────┐
│ TAG │ SIZE │ BLINK │ FLINK │ слово │ TAG │ SIZE │ │
├─────┴──────┴───────┴───────┤ ├─────┴──────┴───────────────┤
│ │ SIZE-2 │ │
│ │ слов │ │
│ │ │ │
├─────┬──────┬───────────────┤ послед- ├─────┬──────────────────────┤
│ TAG │ SIZE │ │ нее │ TAG │ │
└─────┴──────┴───────────────┘ слово └─────┴──────────────────────┘
Свободная область Резервированная область
Кроме того, существует одна переменная FREE следующего вида:
TAG SIZE BLINK FLINK
┌───┬──────┬──────────────────┬──────────────────┐
FREE │ + │ 0 │ на последнюю │ на первую │
│ │ │ область в списке │ область в списке │
└───┴──────┴──────────────────┴──────────────────┘
Поле BLINK первой области в списке указывает на ячейку FREE, так
же, как и поле FLINK последней области. Наконец, мы предположим,
что блоку, используемому для распределения памяти, предшествует
слово, а за блоком следует слово, содержащее '+' в поле TAG для
указания о том, что "окружающие" области заняты. Такое соглашение
упрощает процесс объединения смежных областей.
Алгоритм работы программы GETAREA основан на методе "первый
подходящий"; просматривается список свободпых областей и
выбирается первая из них, которая является достаточно большой.
Несморя на то, что выбор "наиболее подходящей" области кажется на
первый взгляд лучше, на самом деле это не так, и кроме того, на
это затрачивается, очевидно, больше времени.
Сборка мусора
При втором методе распределения памяти, когда GETAREA не
может найти подходящую область, вызывается программа FREEGARBAGE,
цель которой - найти неиспользуемые области и занести их в
некоторый список свободных областей. Для этого FREEGARBAGE должна
быть в состоянии определить следующее:
1) расположение в памяти каждого описанного указателя;
2) точные сведения о величине, на которую ссылается каждый
указатель, - длина величины и содержит ли она какие-нибудь
указатели;
3) для каждого указателя, содержащегося в величине, на
которую ссылается другой указатель, длину указателя и его
расположение в величине.
Как легко видеть, это довольно сильное требование, и
поэтому, используя указатели, нужно придерживаться строгих правил
Поэтому обычно "сбор мусора" используется в тех случаях, когда
система имеет определенную уверенность в том, что указатели
употребляются правильно, и когда число различных форматов для
величин невелико. Хорошим примером такой системы является LISP.
Другой пример - это система обработки строк, преимущество которой
состоитв том, что величины, па которые ссылаются указатели строк,
являются только строками литер, так что величина, на которую
ссылается указатель, никогда не содержит других указателей.
Другая проблема состоит в трудности точного определения
какие области на любом этапе свободны.
Обычно сбор мусора проходит в две фазы. Во время первой
фазы некоторым образом маркируются все используемые величины.
Общепринятый метод состоит в том, чтобы иметь в каждой
величине дополнительный бит специально для маркировки, хотя в
некоторых случаях это неудобно. Другой метод заключается в
том, что биты маркировки собираются в отдельную таблицу с
определенным соответствием между ячейками и битами маркировки.
Однако при этом требуется специальная таблица для битов
маркировки, а по-видимому, когда вызывается сборщик мусора,
объем свободной памяти очень мал!
Во второй фазе мы просматриваем последовательно всю память,
занося непомеченные области в список свободных областей и
гася биты маркировки. Последнее делается для того, чтобы
при следующем вызове сборщика мусора можно было бы правильно
сформировать биты маркировки.
Иногда используется третья фаза, которая собирает
свободные области вместе, так чтобы они образовывали один
большой блок. Для этого требуется, чтобы программа сбора
мусора изменяла значения указателей при перемещении данных.
Для рассмотрения существующих алгоритмов сбора мусора
отсылаем читателя к гл. 2 книги Кнута "Искусство программирования
на ЭВМ " т.1.
Системы с двухуровневым распределением памяти
В некоторых системах имеются два уровня распределения
памяти; большие блоки внутренней памяти резервируются и
освобождаются согласно одному методу, в то время как
каждый большой блок может быть подразделен с помощью
другого метода.
8. Объектно-ориентированные языки. Новые информационные
структуры и память для них
Одной из существенных причин, приводящих к появлению
новых языков программирования, является ограниченность
предопределенных типов данных. Их ограниченность в сложности
адаптации под конкретную задачу.
Для формализации некоторой концепции, или, другими словами,
создания нового абстрактного типа, необходимо определить как
представление объекта этого типа, так и операции над этим
объектом.
Удобным аппаратом для описания объектов нового типа обладают
объектно-ориентированные языки. Базовым понятием объектно -
ориентированного языка является класс.
Класс является типом, созданным программистом. Внешне
описание простейшего класса схоже со структурой данных. В отличие
от структур рассматриваемых ранее, в объектно-ориентированном
языке класс может включать в себя не только переменные,
определяющие новый тип данных, но и функции, реализующие операции
над этим типом данных. И данные, и функции, составляющие
класс, называются членами класса. Среди функций-членов класса
могут присутсвовать специальные функции, управляющие
инициализацией объектов такого типа - конструкторы и функции,
управляющие уничтожением обьектов - деструкторы. Они и занимаются
распределением памяти для экземпляров класса, кроме этого ими
может быть выполнена инициализация этой памяти заданными
значениями.
Мы будем рассматривать новые объекты в аспекте распределения
памяти под них. Идеология и механизмы использования классов
исчерпывающе описаны, например, в литературе [3], [4], [5].
Итак, когда в программе объявляется объект какого-либо
класса, или инициализируется указатель на объект этого типа,
вызывается конструктор класса. Его задачей является
распределить необходимую память. Память выделяется под
данные-члены класса. Коды функций-членов хранятся отдельно от
данных, а именно, в сегменте кода программы, и непосредственно
не присутствуют в реальном объекте; при этом хранится только
одна копия каждой функции, хотя объектов в программе может быть
несколько. Но, с другой стороны, поскольку эти функции
являются членами класса, они могут вызываться только после
того, как в программе созданы объекты абстрактного типа; более
того, они вызываются только для данного конкретного объекта, и
выполняемые ими действия никак не могут влиять на состояние
других объектов этого типа.
Память для данных-членов распределяется аналогично
методам, котрые описаны выше для структур ( см. Структуры PL/1
и Структуры данных по Стендишу ).
После того, как объект выполнил свою миссию в программе
он уничтожается деструктором класса: память занимаемая
данными-членами этого экземпляра класса освобождается. Причем
важно заметить, что если объект содержал какие-либо указатели на
занятую память - эта память не освобождается. Поэтому
ответственность за возможное таким образом возникновение
потерянной для системы памяти несет программист, а не компилятор.
СПИСОК ЛИТЕРАТУРЫ
1. ГРИС Д. Конструирование компиляторов для цифровых
вычислительных машин. -М.: МИР, 1975.
2. КАСЬЯНОВ В.Н., ПОТТОСИН И.В. Методы построения
трансляторов. -Н.: НАУКА, 1986.
3. РОМАНОВ В.Ю. Программирование на языке С++. -М.:
КОМПЬЮТЕР, 1993.
4. ЦИМБАЛ А.А., МАЙОРОВ А.Г., КОЗОДАЕВ М.А. Turbo C++: язык
и его применение. -М.: Джен Ай Лтд., 1993.
5. ЭЛЛИС М., СТРОУСТРУП Б. Справочное руководство по языку
программирования С++ с комментариями. -М.: МИР, 1992.
Похожие работы
... 12 Библиографический список................................................................. 15 Введение Целью работы является демонстрация работы с динамической памятью на примере программ разработанных к заданиям 2, 6, 8, 10, 12, 14, 16 из методического указания [1]. Динамическое распределение памяти предоставляет программисту большие возможности при обращении к ресурсам памяти в ...
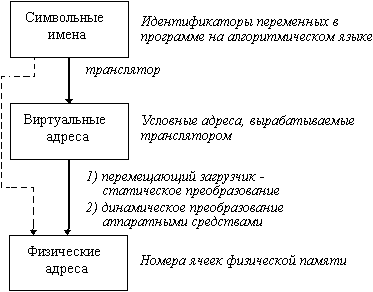
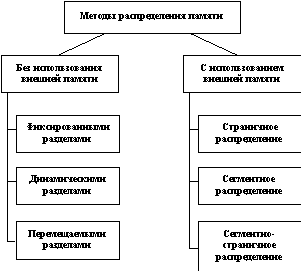
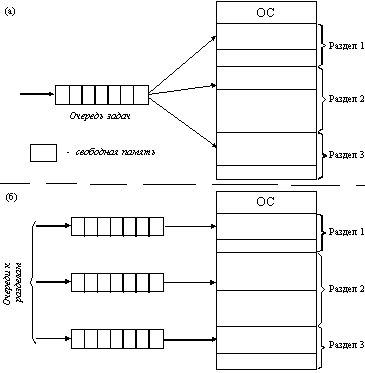
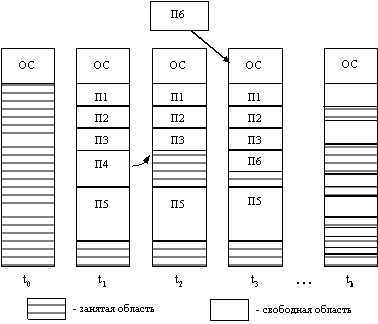
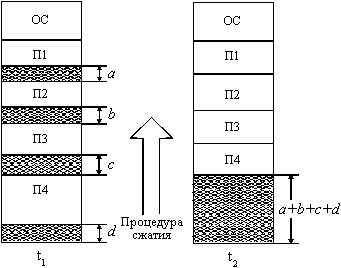
... задачи П4 место загружается задача П6, поступившая в момент t3. Рис. 2.10. Распределение памяти динамическими разделами Задачами операционной системы при реализации данного метода управления памятью является: ведение таблиц свободных и занятых областей, в которых указываются начальные адреса и размеры участков памяти, при поступлении новой задачи - анализ запроса, просмотр ...
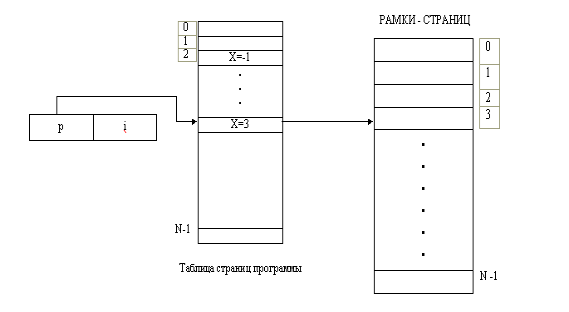
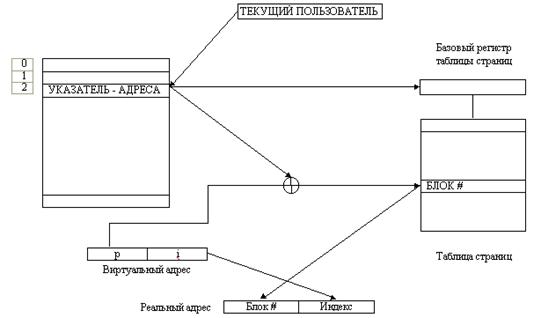
... .) В системах, в которых страницы инструкций (в противоположность страницам данных) являются реентерабельными, бит изменения никогда не устанавливается. 2. Разработка алгоритма управления оперативной памятью Ниже приведён алгоритм управления оперативной памятью в системе Linux. В основе всего лежат страницы памяти. В ядре они описываются структурой mem_map_t. typedef struct page { /* ...
... новые следы памяти могут поступать в активном или неактивном состоянии. Именно это свойство лежит в основе исключительно важного феномена — так называемого латентного обучения. Концепция состояний памяти свободна от условного деления на кратковременную и долговременную и потому может объяснять феномены, которые остаются непонятными с точки зрения временного подхода к организации памяти. То, что ...
0 комментариев