Навигация
Алгоритм нисходящего разбора. Нисходящие распознаватели
22327
знаков
0
таблиц
0
изображений
1. Задача разбора
Разбор сентенциальной формы означает построение вывода и, возможно
синтаксического дерева для нее. Программу разбора называют также рас-
познавателем, так как она распознает только предложения рассматривае-
мой грамматики. Именно это и является нашей задачей в данный момент.
Все алгоритмы разбора, которые бутут здесь описаны называются алгори-
тмами слева направо ввиду того, что они обрабатывают сначала самые ле-
вые символы обрабатываемой цепочки и продвигаются по цепочке только
тогда, когда это необходимо. Можно подобным способом определить разбор
справа налево, но он менее естественен. Инструкции в программе выполня-
ются слева направо, да и мы читаем слева направо.
Различают две категории алгоритмов разбора: нисходящий (сверху вниз)
и восходящий (снизу вверх). Их называют также разверткой и сверткой.
( В данном реферате будет рассмотрен процесс только нисходящего раз-
бора. ) Соотетственно, эти термины соответствуют и способу построения
синтаксического дерева. При нисходящем разборе дерево строится от корня
( начального символа ) вниз к концевым узлам. Метод восходящего разбора
состоит в том, что отправляясь от заданной цепочки, пытаются привести ее
к начальному символу. В качестве примера нисходящего разбора рассмотрим
предложение (1) в следующей грамматике целых чисел ( последовательностей,
состоящих из одной и более цифр ):
N ::= D | ND
D ::= 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 (1)
На первом шаге непосредственный вывод N => ND будет строиться так,
как показано в первом дереве на рис. 1. На каждом последующем шаге
самый левый нетерминал V текущей сентенциальной формы xVy заменяется
на правую часть u правила V ::= u, в результате чего получается сле-
дующая сентенциальная форма. Этот процесс для предложения (1) предс-
тавлен на рис. 1. в виде пяти деревьев. Фокус в том, конечно, что
надо получить ту сентенциальную форму, которая сопадает с заданной
цепочкой.
N N N N N
| | | |
*-------* *-------* *-------* *-------*
| | | | | | | |
N D N D N D N D
| | | |
D D D 5
| |
3 3
N => N D => D D => 3 D => 3 5
Рис. 1. Нисходящий разбор и построение
вывода
2. Нисходящие разбор с возвратами
Алгоритм нисходящего разбора строит синтаксическое дерево, как уже
было сказано, начиная с корня, постепенно опускаясь до уровня предло-
жения, как было показано ранее. Описание усложняется главным образом
из-за необходимости вспомогательных операций, которые необходимы гла-
вным образом для того, чтобы выполнять возвраты с твердой уверенностью,
что все возможные попытки построения дерева были предприняты.
Чтобы свести осложнеия к минимуму, давайте опишем этот алгоритм раз-
бора образно. Вообразим, что на любом этапе разбора, в каждом узле уже
построенной части дерева находится по одному человеку. Люди, которые
находятся в терминальных узлах, занимают места соответственно символам
предложения.
Некоему человеку надлежит провести разбор предложения x. Прежде все-
го ему необходимо отыскать вывод Z => +x, где Z - начальный символ; сле-
довательно первым непосредственным выводом должен будет быть вывод
Z => y где Z ::= y - правило. Пусть для Z существуют правила
Z ::= X X .. X | Y Y .. Y | Z Z .. Z
1 2 n 1 2 m 1 2 1
Сначала человек пытается определить правило Z ::= X X .. X . Если
1 2 n
нельзя построить дерево, используя это правило, он делает попытку приме-
нить второе правило Z ::= Y Y ... Y . В случае неудачи он переходит к
1 2 m
следующему правилу и т.д.
Как ему определить, правильно он выбрал непосредственный вывод
Z => X X .. X ? Заметим, что если вывод правилен, то для некоторых
1 2 n
цепочек x будет иметь место x=x x .. x , где X => *x для i=1,...,n.
i 1 2 n i i
Прежде всего человек, выполняющий разбор, возьмет себе приемного сына
M , который должен будет найти вывод X =>*x для любого x , такого,
1 1 1 1
что x = x ... Если сыну M удастся найти такой вывод, он (и любой из
1 1
сыновей, внуков и т.д.) закрывает цепочку x в предложении x и сообща-
1
ет своему отцу об успехе. Тогда его отец усыновит M , чтобы тот нашел
2
вывод X => *x , где x = x x ... и ждет ответа от него и т.д. Как толь-
2 2 1 2
ко сообщил об успехе сын M ,он усыновит еще и M , чтобы тот нашел
i-1 i
вывод X => *x . Сообщение об успехе, пришедшее от сына M , означает
i i n
что разбор предложения закончен.
Как быть, если сыну M не удается найти вывод X =>*x ? В этом
i i i
случае M сообщает о неудаче своему отцу; тот от него отрекается и
i
дает старшему брату M ,M такое распоряжение: "Ты уже нашел вывод,
i i-1
но этот вывод неверен. Найди-ка мне другой". Если M сумеет найти
i-1
другой вывод, он вновь сообщит об успехе, и все продолжится по-пре-
жнему. Если же M сообщит о неудаче, отец отречется и от него, и
i-1
тогда уже старшего брата M , попросят предпринять еще одну попыт-
i-2
ку. Если придется отречься даже от M , значит, непосредственный вы-
1
вод Z => X X .. X был неверен, и человек, начинавший разбор, попы-
1 2 n
тается воспользоваться другим выводом Z => Y .. Y .
1 m
Как же действует каждый из M ? Положим, его целью является тер-
1
минал X . Входная цепочка имеет вид x=x x ..x T.. ,где символы в
1 2 i-1
x ,x ,...,x уже закрыты другими людьми. M проверяет, совпадает
1 2 i-1 i
ли очередной незакрытый символ T с его целью X . Если это так, он
i
закрывает этот символ и сообщает об успехе. Если нет, сообщает об
неудаче.
Если цель M - нетерминал X , то M поступает точно так же, как
1 1
и его отец. Он начинает проверять правые части правил, относящихся к
нетерминалу, и, если необходимо, тоже усыновляет или отрекается от
сыновей. Есливсе его сыновья сообщают об успехе то M в свою очередь
i
сообщает об успехе отцу. Если отец просит M найти другой вывод, а це-
i
лью является нетерминальный символ, то M сообщает о неудаче, так как
i
другого такого вывода не существует. В противном случае M просит своего
i
младшего сына найти другой вывод и реагирует на его ответ также, как и
раньше. Если все сыновья сообщат о неудаче, он сообщит о неудаче свое-
му отцу.
Теперь, наверное, понятно, почему этот метод называется прогнозиру-
ющим или целенаправленным. Используется и название "нисходящий" из-за
способа построения синтаксического дерева. При разборе отправляются от
начального символа и нисходят к предложению (см рис. 2)
Z
|
*---*-------*
| | |
F | T
| | |
T |
| |
F |
| |
i + i * i
Рис. 2. Частичный нисходящий разбор предложения i+i*i.
Привлекательность этого метода (и его представления) в том и сос-
тоит, что каждый человек должен помнить лишь о своей цели, о своем от-
це, о своих сыновьях, а также о своем месте в грамматике и выходной це-
почке. И никому не нужны точные сведения о том, что происходит в других
местах. Это как раз и есть то, к чему мы вообще стремимся в программиро-
вании: в каждом сегменте программы или в подпрограмме необходимо забо-
титься о собственной входной и выходной информации и ни о чем более.
Для имитации усыновления и отречения сыновей в программах использу-
ют стек типа LIFO (последний вошел - первый вышел), или, как его иногда
называют, "магазин".
Опишем алгоритм в более явном виде:
Положим, во-первых, что грамматика задана списком в одномерном мас-
сиве GRAMMAR таким образом, что каждое множество правил
U ::= x|y|...|z
представлено, как Ux|y|...|z|$. То есть каждый символ занимает одну
ячейку, за каждой правой частью следует вертикальная черта "|", а за
последним символом следует "|$". Таким образом, грамматика
Z ::= E#
E ::= T+E|T
T ::= F*T|F
F ::= (E)|i
будет выглядеть как
ZE#|$ET+E|T|$TF*T|F|$F(E)|i|$
Каждый элемент стека соответствует человеку и состоит из пяти
компонент
(GOAL,i,FAT,SON,BRO)
которые означают следующее:
1. GOAL - цель, т.е. символ, который человек ищет. Таким обра-
зом, в незакрытой в данный момент части предложения ему предстоит
найти такую голову, которая приводится к GOAL, и закрыть ее. GOAL
передается ему отцом.
2. i - индекс в массиве GRAMMAR, указывающий на тот символ в
правой части для GOAL, с которым человек работает в данный момент.
3. FAT - имя отца (номер элемента стека, соответствующего от-
цу).
4. SON - имя самого последнего (младшего) из сыновей.
5. BRO - имя его старшего брата.
Нуль в любом из полей означает, что данная величина отсутствует.
В программе значение переменной v равно количеству участвующих в
разборе людей (количеству элементов в стеке в текущий момент), c -
имя (номер элемента в стеке) человека, работающего в данный момент.
Остальные ожидают конца его работы. Индекс j относитстя к самому ле-
вому (незакрытому) символу входной цепочки INPUT(1),...,INPUT(n).
а) Z б) СТЕК ЦЕЛЬ i FAT SON BRO
|
*---------*------* 1 Z 4 0 15 0
| | 2 E 10 1 7 0
E # 3 T 20 2 4 0
| 4 F 28 3 5 0
*--*------* 5 i 0 4 0 0
| | | 6 + 0 2 0 3
T | E 7 E 12 2 8 6
| + | 8 T 18 7 12 0
F T 9 F 28 8 10 0
| | 10 i 0 9 0 0
i *---*---* 11 * 0 8 0 9
| | | 12 T 20 8 13 11
F * T 13 F 28 12 14 0
| | 14 i 0 13 0 0
i F 15 # 0 1 0 2
|
i
Рис 3. Стек после нисходящего разбора i+i*i
а) - синтаксическое дерево б) - стек после разбора
Поле SON используется для хранения ссылки на последнего (младше-
го) сына. Тогда поле BRO элемента, соответствующего этому сыну, укажет
на старшего брата. В качестве иллюстрации расмотрим изображенное на
рис .3 а) синтаксическое дерево для предложения i+i*i вышеописанной
грамматики. Состояние стека после окончания работы показано на рис.3 б).
Теперь у человека 2(S (2)) есть цель E; предполагается, что он в соотве-
тствии с синтаксическим деревом использует правило E ::= T+E. Таким
образом, ему для того, чтобы найти символы T,+,E потребуется три сына.
Значение поля S(2).SON=7, так что младшим сыном является человек, c
номером 7, цель которого E. Имя среднего сына - число 6, определяется
значением поля S(7).BRO; - цель этого сына - символ +. Имя старшего
сына находится в поле BRO человека 6 и равно 3.
Очевидно, что у нас имеется список сыновей каждого человека и
элементы этого списка связаны в стеке между собой. То есть стек в его
окончательном виде представляет собой внутреннюю форму синтаксического
дерева.
Рассмотрим теперь сам алгоритм нисходящего разбора. Для удобства
чтения разделим его на шесть поименованных частей.
1. НАЧАЛЬНАЯ УСТАНОВКА
S(1) := (Z,0,0,0,0); c:=1; v:=1; j:=1; переход на НОВЫЙ ЧЕЛОВЕК
(первое усыновление. Цель усыновления - начальный символ Z.)
2. НОВЫЙ ЧЕЛОВЕК
IF GOAL терминал THEN Новый человек изучает свою цель.
IF INPUT (j)=GOAL THEN Цель - терминал.
BEGIN j:=j+1; Если GOAL совпадает с символом из
GO TO УСПЕХ; предложения, человек закрывает этот
ELSE GO TO НЕУДАЧА символ и сообщает об успехе.
i:= индекс в GRAMMAR правой Не совпадает - сообщает об неудаче.
части для GOAL; Цель нового человека - нетерминал.
GO TO ЦИКЛ Подготовка к просмотру правых частей
в правилах для GOAL
Похожие работы

... Министерство образования Российской Федерации Саратовский государственный технический университет Формульный компилятор методические указания к выполнению лабораторной работы по курсу «Теория вычислительных процессов и структур для студентов специальности ПВС Составил доцент кафедры ПВС Сайкин А.И. ...
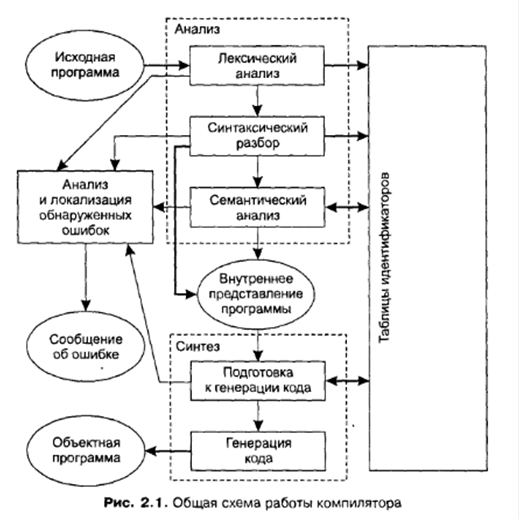
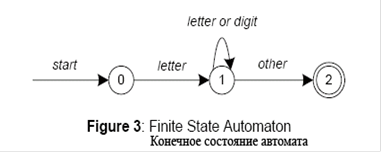
... , в данном каталоге в каждый момент времени может быть активным только один процесс yacc Постановка задачи Реализовать: – транслятор с языка математических выражений на язык деревьев вывода – интерпретатор языка деревьев вывода К разрабатываемым программам предъявляются следующие требования: – реализация осуществляется на языке C++. – функциональность транслятора и интерпретатора должна ...

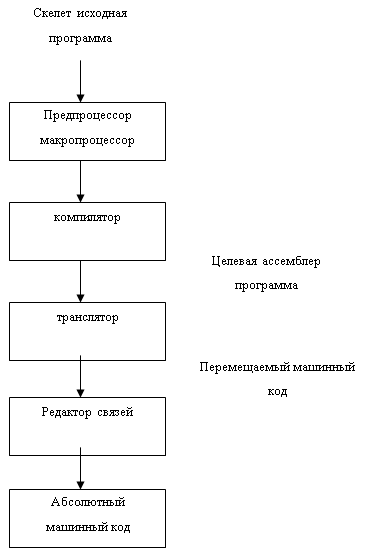
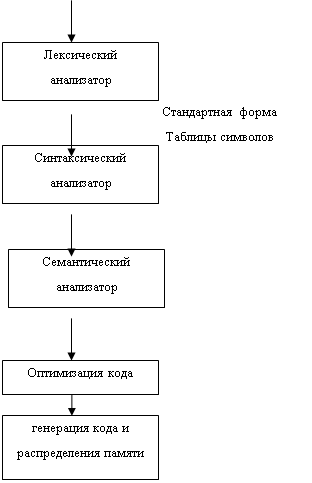
... , которая хранится в ПЗУ и к ней имеется постоянная доступ. Кросс ассемблер – выполняется на ЭВМ общего назначения, и написана на языке программирования этого ЭВМ. Достоинства – разработка программы предшествует технической реализации. Используется мощная программное обеспечение ЭМВ. Выразительность языка и диагностика, обеспечивается преимущества машины выразительности языка и диагностики. ...
... и определяю- щем вхождении идентификатора. КОНТЕКСТНЫЕ УСЛОВИЯ ЧЕТВЕРТОГО ТИПА Некоторые логические ограничения, которые относятся к реа- лизации той или иной версии транслятора. Массив может быть с неограниченным размером. ЛЕКЦИЯ 17 ПРОГРАММНЫЕ ГРАММАТИКИ Правила вывода этих грамматик имеют тот же вид, что и у классических, однако в ...
0 комментариев