Генетический алгоритм (ГА) разработан Джоном Голландом (John Holland) в 1975 году в Мичиганском университете. В дальнейшем Д. Голдберг (D. Goldberg) выдвинул ряд гипотез и теорий, помогающих глубже понять природу генетических алгоритмов. К.ДеДжонг (K. DeJong) первым обратил внимание на важность настройки параметров ГА для общей эффективности работы и предложил свой оптимальный вариант подбора параметров, который послужил основой для всех дальнейших исследований. Существенный вклад в эти исследования внесли Дж. Грефенстетт (J. Greffenstett) и Г. Сесверда (G. Syswerda).
Генетический алгоритм был получен в процессе обобщения и имитации в искусственных системах таких свойств живой природы, как естественный отбор, приспособляемость к изменяющимся условиям среды, наследование потомками жизненно важных свойств от родителей и т.д. Так как алгоритм в процессе поиска использует некоторую кодировку множества параметров вместо самих параметров, то он может эффективно применяться для решения задач дискретной оптимизации, определённых как на числовых множествах, так и на конечных множествах произвольной природы. Поскольку для работы алгоритма в качестве информации об оптимизируемой функции используются лишь её значения в рассматриваемых точках пространства поиска и не требуется вычислений ни производных, ни каких-либо иных характеристик, то данный алгоритм применим к широкому классу функций, в частности, не имеющих аналитического описания. Использование набора начальных точек позволяет применять для их формирования различные способы, зависящие от специфики решаемой задачи, в том числе возможно задание такого набора непосредственно человеком.
Сила генетических алгоритмов в том, что этот метод очень гибок, и, будучи построенным в предположении, что об окружающей среде нам известен лишь минимум информации (как это часто бывает для сложных технических систем), алгоритм успешно справляется с широким кругом проблем, особенно в тех задачах, где не существует общеизвестных алгоритмов решения или высока степень априорной неопределенности.
Генетический алгоритм: описаниеГенетический алгоритм работает с представленными в конечном алфавите строками S конечной длины l, которые используются для кодировки исходного множества альтернатив W. Строки представляют собой упорядоченные наборы из l элементов: S=(s1,s2,..., sl), каждый из которых может быть задан в своём собственном алфавите Vi, ![]() , т.е. siО Vi,
, т.е. siО Vi, ![]() , где алфавит Vi является множеством из ri символов:
, где алфавит Vi является множеством из ri символов:![]() . Для решения конкретной задачи требуется однозначно отобразить конечное множество альтернатив W на множество строк подходящей длины (очевидно, что длина строк зависит от алфавитов, используемых для их задания).
. Для решения конкретной задачи требуется однозначно отобразить конечное множество альтернатив W на множество строк подходящей длины (очевидно, что длина строк зависит от алфавитов, используемых для их задания).
Для работы алгоритма необходимо на множестве строк ![]() задать неотрицательную функцию F(S), определяющую показатель качества, “ценность” строки SО
задать неотрицательную функцию F(S), определяющую показатель качества, “ценность” строки SО![]() . Алгоритм производит поиск строки, для которой
. Алгоритм производит поиск строки, для которой 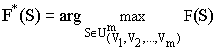
Если на множестве W задана целевая функция f(w), то функцию F(S) на множестве строк ![]() можем определить следующим образом: F(S)=f(w), если элемент w при отображении исходного множества W на множество строк был сопоставлен строке S.
можем определить следующим образом: F(S)=f(w), если элемент w при отображении исходного множества W на множество строк был сопоставлен строке S.
Генетический алгоритм за один шаг производит обработку некоторой популяции строк. Популяция G(t) на шаге t представляет собой конечный набор строк:![]() ,
, ![]() ,
, ![]() , где N -- размер популяции, причём строки в популяции могут повторяться.
, где N -- размер популяции, причём строки в популяции могут повторяться.
Анализ работы алгоритма удобно производить, используя аппарат схем. Схемой в генетическом алгоритме называют описание некоторого подмножества строк. Схема H=(h1,h2,...,hm ) может рассматриваться как строка, алфавиты для элементов которой дополнены специальным символом “#”:![]() ,
,![]() . Если в некоторой позиции r схемы H присутствует символ “#”, то такая позиция называется свободной, а сам символ “#” интерпретируется как произвольный символ из алфавита Vr. Позиция q схемы H называется фиксированной, если в этой позиции присутствует один из символов алфавита Vq. Схема H, в которой определены фиксированные и свободные позиции, описывает подмножество
. Если в некоторой позиции r схемы H присутствует символ “#”, то такая позиция называется свободной, а сам символ “#” интерпретируется как произвольный символ из алфавита Vr. Позиция q схемы H называется фиксированной, если в этой позиции присутствует один из символов алфавита Vq. Схема H, в которой определены фиксированные и свободные позиции, описывает подмножество![]() , содержащее такие строки, у которых элементы, соответствующие фиксированным позициям схемы, совпадают с символами схемы, а элементы, соответствующие свободным позициям схемы, являются произвольно заданными в соответствующих алфавитах:
, содержащее такие строки, у которых элементы, соответствующие фиксированным позициям схемы, совпадают с символами схемы, а элементы, соответствующие свободным позициям схемы, являются произвольно заданными в соответствующих алфавитах: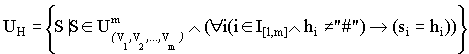 где I[1, m] - множество целых чисел отрезка [1,m].
где I[1, m] - множество целых чисел отрезка [1,m].
Например, для множества строк![]() , где Vi= {0,1},
, где Vi= {0,1},![]() , схема H1="1###0" задаёт такое множество строк, у которых первым элементом является символ "1", пятым - "0", а остальные - либо "0", либо "1". Строки "10010", "11110" являются примерами строк, принадлежащих множеству
, схема H1="1###0" задаёт такое множество строк, у которых первым элементом является символ "1", пятым - "0", а остальные - либо "0", либо "1". Строки "10010", "11110" являются примерами строк, принадлежащих множеству![]() .
.
Часть популяции![]() , строки которой удовлетворяют схеме H, обозначают
, строки которой удовлетворяют схеме H, обозначают![]() , где n(H,t) - число строк схемы H в популяции G(t) и называют подпопуляцией, соответствующей схеме H.
, где n(H,t) - число строк схемы H в популяции G(t) и называют подпопуляцией, соответствующей схеме H.
Суть генетического алгоритма заключается в следующем.
Пусть на шаге t имеется популяция G(t), состоящая из N строк. Для популяции вводится понятие средней ценности популяции Fср (G(t)): 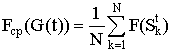
Аналогично для подпопуляции GH(t), удовлетворяющей схеме H, вводится понятие средней ценности подпопуляции Fср (GH(t)):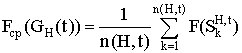 .
.
Генетический алгоритм осуществляет переход от популяции G(t) к популяции G(t+1) таким образом, чтобы средняя ценность составляющих её строк увеличивалась, причём количество новых строк в популяции равно KЧ N, где K - коэффициент новизны. Если K<1, то популяция будет перекрывающейся, т.е. в новой популяции сохраняются некоторые строки из старой, а если K=1, то она будет неперекрывающейся, т.е. подвергнется полному обновлению.
Генетический алгоритм включает три операции: воспроизводство, скрещивание, мутация.
Генетический алгоритм: блок-схема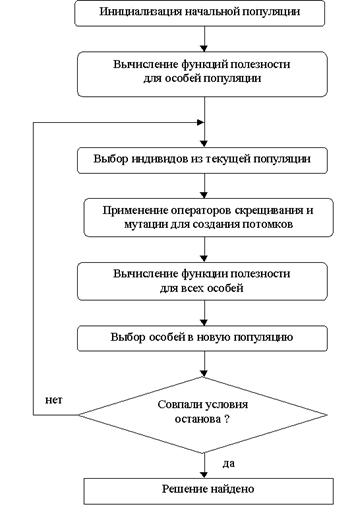
Генетический алгоритм включает три операции: воспроизводство, скрещивание, мутация.
Воспроизводство представляет собой процесс выбора K*N N строк популяции G(t) для дальнейших генетических операций. Выбор производится случайным образом, причём вероятность выбора строки Sit пропорциональна её ценности: 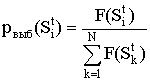
Процесс выбора повторяется K*N N раз. Предполагаемое количество экземпляров строки Sit в популяции G(t+1) равно ![]()
Операция воспроизводства увеличивает общую ценность последующей популяции путём увеличения числа наиболее ценных строк.
Пусть в популяции G(t) содержится n(H,t) строк, удовлетворяющих схеме H. Тогда в результате воспроизводства количество строк, удовлетворяющих схеме H в популяции G(t+1) будет равно n(H,t+1):
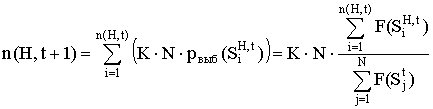 . (1)
. (1)
Используя выражения для средней ценности популяции Fср(G(t)) и подпопуляции Fср(GH(t)), можно записать формулу (1) в виде:
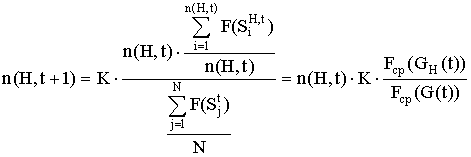 . (2)
. (2)
Средняя ценность подпопуляции, соответствующей схеме H, может быть представлена в следующем виде: ![]() , где c - некоторая величина. Тогда формула (2) примет вид:
, где c - некоторая величина. Тогда формула (2) примет вид:
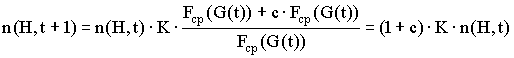 .
.
Предположим, что величина c при изменении t не изменяется; тогда, начиная с t=0, получим: ![]() , т.е. в этом случае число представителей схемы (строк популяции G(t), соответствующих схеме) изменяется в геометрической прогрессии. В общем случае можно сказать, что процесс изменения представителей схемы так же аппроксимируется геометрической прогрессией.
, т.е. в этом случае число представителей схемы (строк популяции G(t), соответствующих схеме) изменяется в геометрической прогрессии. В общем случае можно сказать, что процесс изменения представителей схемы так же аппроксимируется геометрической прогрессией.
Таким образом, в результате операции воспроизводства те схемы, для которых соответствующие подпопуляции имеют среднюю ценность выше средней в популяции, увеличивают количество своих представителей.
Воспроизводство оперирует со строками, уже присутствующими в рассматриваемой популяции, и само по себе не способно открывать новые области поиска. Для этой цели используется операция скрещивания.
Скрещивание представляет собой процесс случайного обмена значениями соответствующих элементов для произвольно сформированных пар строк. Для этого выбранные на этапе воспроизводства строки случайным образом группируются в пары. Далее каждая пара с заданной вероятностью pскр подвергается скрещиванию. При скрещивании происходит случайный выбор позиции разделителя d (d=1,2,...,l-1, где l-длина строки). Затем значения первых d элементов первой строки записываются в соответствующие элементы второй, а значения первых d элементов второй строки - в соответствующие элементы первой. В результате получаем две новых строки, каждая из которых является комбинацией частей двух родительских строк.
Операция скрещивания создаёт новые строки путём некоторой комбинации значений элементов наиболее ценных в популяции G(t) строк. Получившиеся в результате строки могут превосходить по ценности родительские строки.
Рассмотрим некоторую схему H, для которой определим порядок o(H) - число фиксированных позиций схемы и определяющую длину d (H) - расстояние (число позиций) между первой и последней фиксированными позициями. Допустим, что до операции скрещивания строка S была представителем схемы H, т.е. ![]() . Допустим, что строка S1 получена из строки S в результате скрещивания. Строка S1 будет представителем схемы H в том случае, если позиция разделителя при скрещивании не располагалась между фиксированными позициями схемы. Вероятность того, что позиция разделителя окажется между фиксированными позициями схемы, равна:
. Допустим, что строка S1 получена из строки S в результате скрещивания. Строка S1 будет представителем схемы H в том случае, если позиция разделителя при скрещивании не располагалась между фиксированными позициями схемы. Вероятность того, что позиция разделителя окажется между фиксированными позициями схемы, равна: ![]() .
.
Учтём, что скрещивание происходит с вероятностью pc, а также то, что даже если позиция разделителя окажется между фиксированными позициями схемы, строка S1 может являться представителем схемы H, если данная строка была получена скрещиванием двух представителей схемы H. Тогда вероятность ps,1 того, что строка S1 является представителем схемы H, определяется выражением: ![]() .
.
Полагая независимость операций воспроизводства и скрещивания, оценим совокупный эффект от этих операций, т.е. число представителей схемы H в популяции G(t+1):
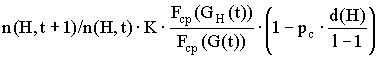 .
.
Так как открытие новых областей поиска в операции скрещивания происходит лишь путём перегруппирования имеющихся в популяции комбинаций символов, то при использовании только этой операции некоторые потенциально оптимальные области могут оставаться не рассмотренными. Для предотвращения подобных ситуаций применяется операция мутации.
Мутация представляет собой процесс случайного изменения значений элементов строки. Для этого строки, получившиеся на этапе скрещивания, просматриваются поэлементно, и каждый элемент с заданной вероятностью мутации pмут может мутировать, т.е. изменить значение на любой случайно выбранный символ, допустимый для данной позиции. Операция мутации позволяет находить новые комбинации признаков, увеличивающих ценность строк популяции.
Допустим, что до мутации строка S1 была представителем схемы H, т.е. ![]() . Допустим, что строка S2 получена из строки S1 в результате мутации. Строка S2 будет представителем схемы H в том случае, если ни один из элементов строки, соответствующий фиксированным позициям схемы, не был изменён.
. Допустим, что строка S2 получена из строки S1 в результате мутации. Строка S2 будет представителем схемы H в том случае, если ни один из элементов строки, соответствующий фиксированным позициям схемы, не был изменён.
Учитывая, что мутация происходит с вероятностью pмут, вероятность ps2 того, что строка S2 является представителем схемы H, определяется выражением: ![]() , где o(H) - число фиксированных позиций схемы H.
, где o(H) - число фиксированных позиций схемы H.
Полагая независимость операций воспроизводства, скрещивания и мутации оценим совокупный эффект от этих операций, т.е. число представителей схемы H в популяции G(t+1):
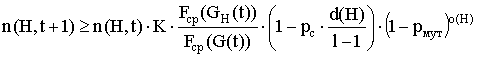 . (3)
. (3)
Так как, при малых значениях pm приближенно можно считать ![]() , то выражение (3) можно записать в виде:
, то выражение (3) можно записать в виде:
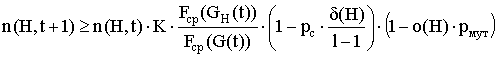
или
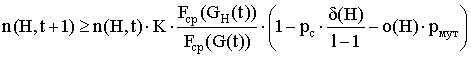 .
.
Таким образом, схемы, у которых малы определяющая длина и порядок, и для которых соответствующая подпопуляция имеет среднюю ценность, превышающую среднюю ценность популяции, экспоненциально увеличивают число представителей в последующих поколениях.
Очевидно, что эффективность описанной операции скрещивания значительно зависит от способа кодировки строк. Это свойство оказывается полезным для задач оптимизации функций, заданных на числовых множествах. Однако, если функция задана на произвольном множестве, например, на множестве комбинаций значений признаков объекта, где все признаки одинаковы по предпочтительности, то описанный выше способ скрещивания оказывается не вполне корректным, так как вероятность сохранения значений для групп признаков зависит от расстояния между элементами группы в кодовой строке, а это нарушает принцип равной предпочтительности признаков. Поэтому для таких задач операцию скрещивания предполагается производить путём обмена не частями строк, а отдельными элементами. При этом задаётся некоторое число позиций nП (nПО {1,2,…,l}), которое определяет количество элементов строк, для которых производится обмен значениями. Число позиций nП может быть задано непосредственно или определяться случайно для каждой пары строк. Далее для каждой пары строк (S1, S2)i, где i-номер пары, случайно выбираются nП номеров ni,j (ni,jО {1,2,…,l}; jО {1,2,…,nП}). Затем для строк пары (S1, S2)i производится обмен значениями элементов с номерами ni,j, т.е. каждому элементу с номером ni,j строки S1 присваивается значение элемента с номером ni,j строки S2 , а элементу с номером ni,j строки S2 присваивается значение элемента с номером ni,j строки S1.
Допустим, что до операции скрещивания строка S была представителем схемы H, т.е. ![]() , а строка S1 получена из строки S в результате поэлементного скрещивания. Вероятность p’s,1 того, что строка S1 будет представителем схемы H, равна:
, а строка S1 получена из строки S в результате поэлементного скрещивания. Вероятность p’s,1 того, что строка S1 будет представителем схемы H, равна:
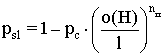 ,
,
где o(H) - число фиксированных позиций схемы H.
Совокупный эффект от операций воспроизводства и поэлементного скрещивания, и мутации, т.е. число представителей схемы H в популяции G(t+1) определяется выражением:
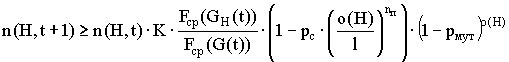 .
.
Таким образом, при поэлементном скрещивании скорость увеличения представителей схемы в последующих поколениях зависит от средней ценности схемы и количества фиксированных позиций и не зависит от расстояния между ними, а значит, не зависит от порядка расположения элементов в строке.
Итак, в результате описанных выше операций получаем K*N N новых строк, которые либо полностью формируют новую популяцию G(t+1) (при K=1), заменяя при этом все строки популяции G(t), либо составляют часть популяции G(t+1), заменяя собой K*N N наименее ценных строк предыдущей популяции.
Как видно из описания алгоритма, закон ![]() вероятности распределения значений целевой функции определяется и корректируется путём использования набора (популяции) строк, содержащих наилучшие в смысле значений целевой функции комбинации элемен
вероятности распределения значений целевой функции определяется и корректируется путём использования набора (популяции) строк, содержащих наилучшие в смысле значений целевой функции комбинации элемен
Похожие работы
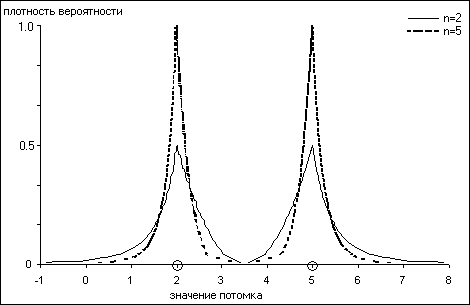
... число эпох функционирования алгоритма, или определение его сходимости, обычно путем сравнивания приспособленности популяции на нескольких эпохах и остановки при стабилизации этого параметра. 3. Непрерывные генетические алгоритмы. Фиксированная длина хромосомы и кодирование строк двоичным алфавитом преобладали в теории генетических алгоритмов с момента начала ее развития, когда были получены ...
... в популяциях, которые являются существенными для развития. Точный ответ на вопрос: какие биологические процессы существенны для развития, и какие нет? - все еще открыт для исследователей. Реализация генетических алгоритмов В природе особи в популяции конкурируют друг с другом за различные ресурсы, такие, например, как пища или вода. Кроме того, члены популяции одного вида часто конкурируют ...
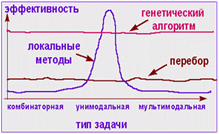
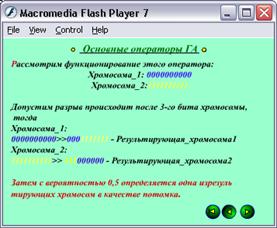
... : имеется пять городов, стоимость переезда между которыми представлена следующей матрицей: 1 2 3 4 5 1 0 4 6 2 9 2 4 0 3 2 9 3 6 3 0 5 9 4 2 2 5 0 8 5 9 9 9 8 0 Для решения задачи применим следующий генетический алгоритм. Решение представим в виде перестановки чисел от 1 до 5, отображающей последовательность посещения городов. А значение целевой функции ...
... решения Скрещивание, рекомбинация, кроссинговер Оператор рекомбинации мутация Оператор модификации При разработке генетических алгоритмов преследуется две главные цели: · Абстрактное и формальное объяснение процессов адаптации в естественных системах; · Проектирование искусственных программных систем, воспроизводящих механизмы функционирования естественных систем. Основные отличия ГА от ...
0 комментариев