ЧУЗ-ИДА Кривой Рог PEI-IBM
Частное Учебное Заведение
Институт Делового Администрирования
Private Educational Institution
Institute of Business Managment
Основы теории систем и
системного анализа
Конспект лекций для специальности
УЧЕТ И АУДИТ· 95
сентябрь-декабрь 1996 г.
Особенности системного подхода к решению задач управления
Общие понятия теории систем и системного анализа
Термины теория систем и системный анализ или, более кратко — системный подход, несмотря на период более 25 лет их использования, все еще не нашли общепринятого, стандартного истолкования.
Причина этого факта заключается, скорее всего, в динамичности процессов в области человеческой деятельности и, кроме того, в принципиальной возможности использовать системный подход практически в любой решаемой человеком задаче.
Даже в определении самого понятия система можно обнаружить достаточно много вариантов, часть из которых базируется на глубоко философских подходах, а другая использует обыденные обстоятельства, побуждающие нас к решению практических задач системного плана.
Выберем золотую середину и будем далее понимать термин система как совокупность (множество) отдельных объектов с неизбежными связями между ними. Если мы обнаруживаем хотя бы два таких объекта: учитель и ученик в процессе обучения, продавец и покупатель в торговле, телевизор и передающая станция в телевидении и т. д. — то это уже система. Короче, с некоторой претензией на высокопарность, можно считать системы способом существования окружающего нас мира.
Более важно понять преимущество взгляда на этот мир с позиций системного подхода: возможность ставить и решать, по крайней мере, две задачи:
расширить и углубить собственные представления о “меха-низме” взаимодействий объектов в системе; изучить и, возможно, открыть новые её свойства;
повысить эффективность системы в том плане ее функционирования, который интересует нас больше всего.
Хотя хронология науки относит момент зарождения теории систем и системного анализа (далее ТССА) к средине текущего столетия, тем не менее, можно понять, что возраст ТССА составляет ровно столько, сколько существует Homo Sapiens.
Другое дело, что по мере развитие науки, прежде всего — кибернетики, эта отрасль прикладной науки сформировалась в самостоятельный раздел. Ветви ТССА прослеживаются во всех “ведомственных кибернетиках”: биологической, медицинской, технической и, конечно же, экономической. В каждом случае объекты, составляющие систему, могут быть самого широкого диапазона — от живых существ в биологии до механизмов, компьютеров или каналов связи в технике.
Но, несмотря на это, задачи и принципы системного подхода остаются неизменными, не зависящими от природы объектов в системе.
Для лиц вашей будущей профессии наибольший интерес представляют, естественно, экономические системы, а глобальной задачей системного подхода — совершенствование процесса управления экономикой.
Поэтому для нас с вами предметом системного анализа будут являться вопросы сбора, хранения и обработки информации об экономических объектах и, возможно, технологических процессах.
Используя классическое определение кибернетики как науки об общих законах получения, хранения, передачи и преобразования информации (кибернетика в дословном переводе — искусство управлять), можно считать ТССА фундаментальным разделом экономической кибернетики.
Сущность и принципы системного подхода
ТССА, как отрасль науки, может быть разделена на две, достаточно условные части:
· теоретическую: использующую такие отрасли как теория вероятностей, теория информации, теория игр, теория графов, теория расписаний, теория решений, топология, факторный анализ и др.;
· прикладную, основанную на прикладной математической статистике, методах исследовании операций, системотехнике и т. п. Таким образом, ТССА широко использует достижения многих отраслей науки и этот “захват” непрерывно расширяется.
Вместе с тем, в теории систем имеется свое “ядро”, свой особый метод — системный подход к возникающим задачам. Сущность этого метода достаточно проста: все элементы системы и все операции в ней должны рассматриваться только как одно целое, только в совокупности, только во взаимосвязи друг с другом.
Плачевный опыт попыток решения системных вопросов с игнорированием этого принципа, попыток использования "местечкового" подхода достаточно хорошо изучен. Локальные решения, учет недостаточного числа факторов, локальная оптимизация — на уровне отдельных элементов почти всегда приводили к неэффективному в целом, а иногда и опасному по последствиям, результату.
· Итак, первый принцип ТССА — это требование рассматривать совокупность элементов системы как одно целое или, более жестко, — запрет на рассмотрение системы как простого объединения элементов.
· Второй принцип заключается в признании того, что свойства системы не просто сумма свойств ее элементов. Тем самым постулируется возможность того, что система обладает особыми свойствами, которых может и не быть у отдельных элементов.
· Весьма важным атрибутом системы является ее эффективность. Теоретически доказано, что всегда существует функция ценности системы — в виде зависимости ее эффективности (почти всегда это экономический показатель) от условий построения и функционирования. Кроме того, эта функция ограничена, а значит можно и нужно искать ее максимум. Максимум эффективности системы может считаться третьим ее основным принципом.
· Четвертый принцип запрещает рассматривать данную систему в отрыве от окружающей ее среды — как автономную, обособленную. Это означает обязательность учета внешних связей или, в более общем виде, требование рассматривать анализируемую систему как часть (подсистему) некоторой более общей системы.
· Согласившись с необходимостью учета внешней среды, признавая логичность рассмотрения данной системы как части некоторой, большей ее, мы приходим к пятому принципу ТССА — возможности (а иногда и необходимости) деления данной системы на части, подсистемы. Если последние оказываются недостаточно просты для анализа, с ними поступают точно также. Но в процессе такого деления нельзя нарушать предыдущие принципы — пока они соблюдены, деление оправдано, разрешено в том смысле, что гарантирует применимость практических методов, приемов, алгоритмов решения задач системного анализа.
Все изложенное выше позволяет формализовать определение термина система в виде — многоуровневая конструкция из взаимо-действующих элементов, объединяемых в подсистемы нескольких уровней для достижения единой цели функционирования (целевой функции).
Проблемы согласования целей
Как уже отмечалось, в большинстве случаев (в экономических системах — повсеместно), показателем полноты достижения цели “жизни” системы служит стоимостной показатель. Разумеется, что выбор показателя — критерия эффективности системы, является заключитель-ным этапом формулировки целей и задач системы. Но нельзя упускать из виду, что от этого этапа будут зависеть наши представления о свойствах системы и результаты самого системного анализа.
Предположим, что по отношению к некоторой системе все формальные вопросы описания уже благополучно разрешены. Что же дальше?
А дальше надо системой управлять — точнее решать вопрос об алгоритме или тактике управления для достижения наибольшей эффективности. Скорее всего, именно в этой области и лежит поле профессиональной деятельности в вашей будущей профессии — делового администрирования, решения задач организационно-управленческого характера.
Вроде бы все очень просто — имеется предприятие, выделены его подсистемы (отделы), определены функции каждой подсистемы и каждого элемента в них, описаны связи внутри системы и по отношению к внешней среде. Так пусть каждый элемент функционирует оптимально — наиболее эффективно делает свое дело.
Но здесь почти всегда возникают противоречия, суть которых можно определить с помощью примера, ставшего классическим.
Рассмотрим деятельность некоторой фирмы, производящей определенные виды продукции и, естественно, стремящейся получить мак-симальную прибыль от ее продажи. Пусть решается простой вопрос — сколько готовой продукции хранить на складе предприятия и сколько разновидностей ее должно производиться? Посмотрим на “частные” интересы различных отделов фирмы и сразу же обнаружим их несовпадение.
Да, каждый из отделов заинтересован в достижении глобальной цели — максимуме прибыли фирмы (если это не так, то системный подход здесь бессилен). Но!
· Производственный отдел будет заинтересован в длительном и непрерывном производстве одного и того же вида продукции. Только в этом случае будут наименьшими расходы на наладку оборудования.
· Отдел сбыта, наоборот, будет отстаивать идею производства максимального числа видов продукции и больших запасов на складах.
· Финансовый отдел, конечно же, будет настаивать на минимуме складских запасов — то, что лежит на складе, не может приносить прибыли!
· Даже отдел кадров будет иметь свою локальную целевую функцию — производить продукцию всегда (даже в периоды делового спада) и в одном и том же ассортименте, так как в этом случае не будет проблем текучести кадров.
Вот и представьте себе сложность задачи управления такой большой системой с достижением глобальной цели — максимума прибыли.
Ясно, что придется ставить и решать задачи согласования целей отдельных подсистем и хорошо еще, если показатели эффективности подсистем имеют ту же размерность, что и показатель (критерий) эффективности системы в целом. Ведь вполне может оказаться, что эффективность работы некоторых подсистем приходится измерять не в денежном выражении, а с помощью других, не числовых, показателей.
Проблемы оценки связей в системе
Рассмотрим теперь вопрос о связях системы — между отдельными элементами подсистем, подсистемами разных уровней и связях с внешней средой. Хотя бы умозрительно можно полагать наличие каналов, по которым эти связи производятся. Но чем же “наполнены” такие каналы? Скорее всего, в экономических системах можно обнаружить и выделить только три типа наполнителей
продукция;
деньги;
информация.
Нет нужды объяснять принципиальные различия продукции и денег. Что же касается информации, то можно вспомнить ответ отца кибернетики Н.Винера на вопрос — так что же такое информация: это НЕ материя и НЕ энергия!
Возникает вопрос о том, как же согласовывать эти совершенно несопоставимые по размерностям показатели, как привести их к “общему знаменателю”? Ведь без такого согласования невозможно будет установить единый показатель эффективности системы в целом.
Вторая проблема оценки связей в системе станет понятной, если мы примем условное деление систем на естественные и искусственные. Никто не станет отрицать, что в природе все взаимосвязано — все “имеет свой конец, свое начало”. И, тем не менее, все согласятся с тем, что “поведение” природы (а тем более — человека) невозможно предсказать со 100% уверенностью.
Таким образом, вторая проблема оценки связей при системном анализе заключается в том, что количества продукции, суммы денег и показатели информационных потоков в каналах связи системы имеют стохастичную, вероятностную природу — их значения в данный момент времени нельзя предсказать абсолютно надежно.
Поэтому при системном анализе часто приходится иметь дело не с конкретными значениями величин, не с заранее определенными событиями, а с их оценками по прошлым наблюдениям или по прогнозам на будущее. Отсюда возникает необходимость использования специальных, большей частью прикладных, методов математической ста-тистики.
Если теперь вспомнить основное назначение системного анализа — получить рекомендации по вопросам управления системой или, по крайней мере, по совершенствованию этого управления, то возникает вопрос — а всегда ли оправдан системный подход? Ведь ясно, что для его реализации потребуются определенные и возможно немалые затраты времени и средств. Но, если выводы системного анализа, полу-ченные на его основе рекомендации, почти всегда не полностью достоверны, то выходит, что мы рискуем? Да, это так и есть.
Без риска ошибки в реальном, окружающем нас мире просто жить, а уж тем более действовать, — практически невозможно. Надо осознать, что даже самое точное следование рекомендациям науки не дает гарантии получить именно то, что мы задумали, проектировали, планировали. В утешение лишь скажем, что можно рисковать без попыток просчитать возможные последствия и можно рисковать в условиях, когда использованы все научные методы оценки этих последствий.
Это совершенно противоположные подходы, но нельзя считать ни один из них "юридически законным" или вытекающим из каких ни будь законов природы, нельзя считать стиль управления системой на основе системного анализа "правильным", "современным", "куль-турным". Другое дело — не знать о возможности применения системного подхода к вопросам управления — вот это неправильно, некультурно.
Пример системного подхода к задаче управления
Для закрепления темы введения в курс, с целью хотя бы частично осветить не затронутые еще вопросы системного анализа, рассмотрим конкретный пример из собственного практического опыта лектора.
В конце 70 г. г. украинский МинВуз принял решение глобального учета информации о текущей успеваемости студентов всех вузов Украины. Дело было поставлено с поистине советским размахом — каж-дые две недели семестра все студенты вуза проходили аттестацию по всем учебным дисциплинам. Вся эта лавина информации (конечно же, недостоверной — в виде прогноза будущей оценки на экзамене) передавалась в Киев. Сейчас дело не в том как она использовалась (в конце этой эпопеи оказалось — никак!).
Мы, в Криворожском горнорудном институте (теперь — технический университет) попытались использовать ситуацию для совершен-ствования управления учебным процессом, благо что процесс сбора информации был обусловлен приказом по министерству.
На первом этапе системного подхода к задаче был решен вопрос о выделении подсистем и их элементов. В качестве основных подсистем рассматривались всего три их разновидности:
подсистема “Студенты”;
подсистема “Кафедры”;
подсистема “Деканаты”.
Было понятно, что локальные цели каждой из подсистем отличались друг от друга (в первом случае это учеба, во втором — обучение, в третьем — управление обучением на уровне факультета).
Вместе с тем имелась и единая цель функционирования вуза — подготовка специалистов с высшим образованием по отдельным профи-лям. Была определена и мера оценки эффективности системы в целом, пусть даже в таком примитивном виде, как экзаменационные оценки знаний. Принималась во внимание иерархия подсистем в плане подчинения, направленность потоков знаний и информации о них в каналах связи между звеньями.
Были содержательно сформулированы две задачи:
· как по результатам текущего контроля знаний оценить эффективность процесса обучения на данном интервале семестра, обнаружить “узкие места” этого процесса;
· как оценить эффективность управляющих воздействий на систему обучения на конечном его этапе — после подведения итогов сессии.
При этом заранее предполагалось, что “виновниками” недостаточной эффективности обучения могут оказаться элементы любой из подсистем.
В самом деле, низкая успеваемость может быть обусловлена разными причинами:
слабой предварительной подготовкой студентов;
малоэффективными в данных условиях методами обучения;
промахами в организации обучения.
Заметим, что эти выводы пока никакого отношения к системному анализу не имеют, они сформулированы на основании понимания особенностей процесса обучения.
Здесь, на этом этапе системного подхода в любой сфере всегда необходимо обращаться к “технологии” процессов, происходящих в системе. А это означает, что в предварительной части системного анализа в равной степени должны участвовать как специалисты в области ТССА, так и знатоки процессов данной системы. Участие одного из них — лица, принимающего решения (далее — ЛПР) совершенно обязательно.
На следующем этапе в рассматриваемом примере были разработаны методы сбора, хранения и обработки информации. И здесь, как в любом случае системного подхода к задачам управления, пришлось решать проблему представительности собираемых данных.
Прежде всего, пришлось поставить и решить вопрос об оценках текущего контроля знаний, Поскольку это не метры, литры или килобайты, поскольку не существует шкалы знаний, то что должна означать оценка текущего контроля?
После обсуждения этих вопросов в среде специалистов (экспертов в области обучения в высшей школе) было принято решение — оценка текущего контроля знаний рассматривается как прогноз экзаменационной оценки.
И снова обратим внимание на тот факт, что такая договоренность между ЛПР и специалистами ТССА была бы необходима и в том случае, когда речь бы шла не о знаниях, а о будущих прибылях или надоях!
Здесь возможно различие в достоверности прогноза и то далеко не всегда, но со стохастичным характером данных системного анализа приходится мириться — такова природа явлений в реальной жизни.
Но и это еще не всё об информации, используемой при системном анализе. Далеко не всегда “измерения” чего-то можно производить без ощутимых последствий. И пусть даже сбор информации не приносит прямого морального или материального ущерба, что иногда вполне возможно, хотя и не всегда очевидно. Главное в другом — если мы хотим иметь информацию об элементе системы, то надо стремиться получить ее с наименьшими, информационными же, потерями.
В рассматриваемом примере не использовались никакие приборы, лишенные разума и эмоций, — источниками данных и “измерителями” являлись люди! В самом деле, необходимость предсказать свои собственные достижения в условиях, когда они не только от тебя зависят (прогнозировать итог экзамена студента), вне всяких сомнений, хоть чуть-чуть, но всё же меняет один из элементов, то есть преподавателя.
Моделирование как метод системного анализа
Одной из проблем, с которой сталкиваются почти всегда при проведении системного анализа, является проблема эксперимента в системе или над системой. Очень редко это разрешено моральными законами или законами безопасности, но сплошь и рядом связано с материальными затратами и (или) значительными потерями информации.
Опыт всей человеческой деятельности учит — в таких ситуациях надо экспериментировать не над объектом, интересующим нас предметом или системой, а над их моделями. Под этим термином надо понимать не обязательно модель физическую, т. е. копию объекта в уменьшенном или увеличенном виде. Физическое моделирование очень редко применимо в системах, хоть как то связанных с людьми. В частности в социальных системах (в том числе — экономических) приходится прибегать к математическому моделированию.
Буквально через минуту станет ясно, что математическим моделированием мы овладеваем еще на школьной скамье. В самом деле, пусть требуется найти площадь прямоугольника со сторонами 2 и 8 метров. Измерение сторон произведено приближенно — других измерений расстояний не бывает! Как решить эту задачу? Конечно же — не путем рисования прямоугольника (даже в уменьшенном масштабе) и последующем разбиении его на квадратики с окончательным подсчетом их числа. Да, безусловно, мы знаем формулу S = B· H и воспользуемся ею — применим математическую модель процесса определения площади.
Возвращаясь к начатому ранее примеру системного анализа обучения, можно заметить, что там собственно нечего вычислять по фор-мулам — где же их взять. Это так и есть, не существует методов расчета в такой сфере как “прием-передача” знаний и сомнительно, чтобы эти методы когда-либо появились.
Но ведь не существует формулы пищеварения, а люди все таки едят, планируют процесс питания, управляют им и иногда даже успешно.....
Так что же? Если нет математических моделей — не выдумывать же их самому? Ответ на этот вопрос самый простой: всем это уметь и делать — не обязательно, а вот тому, кто взялся решать задачи системного анализа — приходится и очень часто. Иногда здесь возможна подсказка природы, знание технологии системы; в ряде случаев может выручить эксперимент над реальной системой или ее элементами (т. н. методы планирования экспериментов) и, наконец, иногда приходится прибегать к методу “черного ящика”, предполагая некоторую статистическую связь между его входом и выходом.
Таким “ящиком” в рассматриваемом примере считался не только студент (с вероятностью такой-то получивший знания), но и все остальные элементы системы — преподаватели и лица, организующие обучение.
Конечно, возможны ситуации, когда все процессы в большой системе описываются известными законами природы и когда можно надеяться, что запись уравнений этих законов даст нам математическую модель хотя бы отдельных элементов или подсистем. Но и в этих, редких, случаях возникают проблемы не только в плане сложности урав-нений, невозможности их аналитического решения (расчета по формулам). Дело в том, что в природе трудно обнаружить примеры “чистого” проявления ее отдельных законов — чаще всего сопутствующие явление факторы “смазывают” теоретическую картину.
Еще одно важное обстоятельство приходится учитывать при математическом моделировании. Стремление к простым, элементарным моделям и вызванное этим игнорирование ряда факторов может сделать модель неадекватной реальному объекту, грубо говоря — сделать ее неправдивой. Снова таки, без активного взаимодействия с технологами, специалистами в области законов функционирования систем данного типа, при системном анализе не обойтись.
В системах экономических, представляющих для вас основной интерес, приходится прибегать большей частью к математическому моделированию, правда в специфическом виде — с использованием не только количественных, но и качественных, а также логических показателей.
Из хорошо себя зарекомендовавших на практике можно упомянуть модели: межотраслевого баланса; роста; планирования эко-номики; прогностические; равновесия и ряд других.
Завершая вопрос о моделировании при выполнении системного анализа, резонно поставить вопрос о соответствии используемых моделей реальности.
Это соответствие или адекватность могут быть очевидными или даже экспериментально проверенными для отдельных элементов системы. Но уже для подсистем, а тем более системы в целом существует возможность серьезной методической ошибки, связанная с объективной невозможность оценить адекватность модели большой системы на логическом уровне.
Иными словами — в реальных системах вполне возможно логическое обоснование моделей элементов. Эти модели мы как раз и стремимся строить минимально достаточными, простыми настолько, насколько это возможно без потери сущности процессов. Но логически осмыслить взаимодействие десятков, сотен элементов человек уже не в состоянии. И именно здесь может “сработать” известное в математике следствие из знаменитой теоремы Гёделя — в сложной системе, полностью изолированной от внешнего мира, могут существовать истины, положения, выводы вполне “допустимые” с позиций самой системы, но не имеющие никакого смысла вне этой системы.
То есть, можно построить логически безупречную модель реальной системы с использованием моделей элементов и производить анализ такой модели. Выводы этого анализа будут справедливы для каждого элемента, но ведь система — это не простая сумма элементов, и ее свойства не просто сумма свойств элементов.
Отсюда следует вывод — без учета внешней среды выводы о поведении системы, полученные на основе моделирования, могут быть вполне обоснованными при взгляде изнутри системы. Но не исключена и ситуация, когда эти выводы не имеют никакого отношения к системе — при взгляде на нее со стороны внешнего мира.
Для пояснения вернемся к рассмотренному ранее примеру. В нем почти все элементы были построены на вполне оправданных логических постулатах (допущениях) типа: если студент Иванов получил оценку “знает” по некоторому предмету, и посетил все занятия по этому предмету, и управление его обучением было на уровне “Да” — то вероятность получения им оценки “знает” будет выше, чем при отсутствии хотя бы одного из этих условий.
Но как на основании системного анализа такой модели ответить на простейший вопрос; каков вклад (хотя бы по шкале “больше-меньше”) каждой из подсистем в полученные фактические результаты сессии? А если есть числовые описания этих вкладов, то каково доверие к ним? Ведь управляющие воздействия на систему обучения часто можно производить только через семестр или год.
Здесь приходит на помощь особый способ моделирования — метод статистических испытаний (Монте Карло). Суть этого метода проста — имитируется достаточно долгая “жизнь” модели, несколько сотен семестров для нашего примера. При этом моделируются и регистрируются случайно меняющиеся внешние (входные) воздействия на систему. Для каждой из ситуации по уравнениям модели просчитываются выходные (системные) показатели. Затем производится обратный расчет — по заданным выходным показателям производится расчет входных. Конечно, никаких совпадений мы не должны ожидать — каждый элемент системы при входе “Да” вовсе не обязательно будет “Да” на выходе.
Но существующие современные методы математической статистики позволяют ответить на вопрос — а можно ли и, с каким доверием, использовать данные моделирования. Если эти показатели доверия для нас достаточны, мы можем использовать модель для ответа на поставленные выше вопросы.
Процессы принятия управляющих решений
Пусть построена модель системы с соблюдением всех принципов системного подхода, разработаны и “обкатаны” алгоритмы необходимых расчетов, приготовлены варианты управляющих воздействий на систему. Надо понять, что эти воздействия не всегда заключаются в изменениях уровня некоторых входных параметров — это могут быть варианты структурных перестроек системы.
Так вот — все это есть. И что же дальше? Пора и управлять, управлять с единой целью — повышения эффективности функционирования системы (однокритериальная задача) или с одновременным достижением нескольких целей (многокритериальная задача).
Естественно, мы ставим вопрос: “А что будет, если …?” и ожидаем ответа. Но здесь не следует ожидать чуда, нельзя надеяться на однозначный ответ. Если к примеру, мы интересуемся вопросом — “к чему приведет увеличение на 20% закупок цемента?”, то мы должны не удивляться, получив ответ — “Это приведет к увеличению рентабельности производства кирпича на величину, которая с вероятностью 95% не будет ниже 6% и не будет выше 14%”. И это еще очень содержательный ответ, могут быть и более “расплывчатые”!
Здесь уместно в последний раз обратиться к примеру с анализом системы обучения и ответить на возможный вопрос — а как же были использованы выводы системного анализа обучения в КГРИ? Ответ одного из соавторов системного анализа, пишущего эти строки, очень краткий — никак.
Можно теперь открыть еще одну (не последнюю) тайну ТССА. Дело в том, что судьбу разработок по управлению большими системами должно решать только ЛПР, и только этот человек (или коллективный орган) решает вопрос дальнейшей судьбы итогов системного анализа. Важно отметить, что это правило никак не связано ни с “важностью” конкретной отрасли промышленности, торговли или образования, ни с политическими обстоятельствами, ни с государственным строем. Все намного проще — мудрость отцов-основателей ТССА проявилась, прежде всего, в том, что неполнота достоверности выводов системного анализа была ими заранее оговорена.
Поэтому те, кто ведет системный анализ, не должны претендовать на обязательное использование своих разработок; факты отказа от их использования не есть показатель непригодности этих разработок.
С другой стороны, те, кто принимают решения, должны столь же четко понимать, что расплывчатость выводов ТССА есть неизбежность, она может быть обусловлена не промахами анализа, а самой природой или ошибкой постановки задачи, например, попытки управлять такой гигантской системой, как экономика бывшего СССР.
Основные понятия математической статистики
Случайные события и величины, их основные характеристики
Как уже говорилось, при анализе больших систем наполнителем каналов связи между элементами, подсистемами и системы в целом могут быть:
· продукция, т. е. реальные, физически ощутимые предметы с заранее заданным способом их количественного и качественного описания;
· деньги, с единственным способом описания — суммой;
· информация, в виде сообщений о событиях в системе и значениях описывающих ее поведение величин.
Начнем с того, что обратим внимание на тесную (системную!) связь показателей продукции и денег с информацией об этих показателях. Если рассматривать некоторую физическую величину, скажем — количество проданных за день образцов продукции, то сведения об этой величине после продажи могут быть получены без проблем и достаточно точно или достоверно. Но, уже должно быть ясно, что при системном анализе нас куда больше интересует будущее — а сколько этой продукции будет продано за день? Этот вопрос совсем не праздный — наша цель управлять, а по образному выражению “управлять — значит предвидеть”.
Итак, без предварительной информации, знаний о количественных показателях в системе нам не обойтись. Величины, которые могут принимать различные значения в зависимости от внешних по отношению к ним условий, принято называть случайными (стохастичными по природе). Так, например: пол встреченного нами человека может быть женским или мужским (дискретная случайная величина); его рост также может быть различным, но это уже непрерывная случайная величина — с тем или иным количеством возможных значений (в зависимости от единицы измерения).
Для случайных величин (далее — СВ) приходится использовать особые, статистические методы их описания. В зависимости от типа самой СВ — дискретная или непрерывная это делается по разному.
Дискретное описание заключается в том, что указываются все возможные значения данной величины (например - 7 цветов обычного спектра) и для каждой из них указывается вероятность или частота наблюдений именного этого значения при бесконечно большом числе всех наблюдений.
Можно доказать (и это давно сделано), что при увеличении числа наблюдений в определенных условиях за значениями некоторой дискретной величины частота повторений данного значения будет все больше приближаться к некоторому фиксированному значению — которое и есть вероятность этого значения.
К понятию вероятности значения дискретной СВ можно подойти и иным путем — через случайные события. Это наиболее простое понятие в теории вероятностей и математической статистике — событие с вероятностью 0.5 или 50% в 50 случаях из 100 может произойти или не произойти, если же его вероятность более 0.5 - оно чаще происходит, чем не происходит. События с вероятностью 1![]() называют достоверными, а с вероятностью 0 — невозможными.
называют достоверными, а с вероятностью 0 — невозможными.
Отсюда простое правило: для случайного события X вероятности P(X) (событие происходит) и P(X) (событие не происходит), в сумме для простого события дают 1.
Если мы наблюдаем за сложным событием — например, выпадением чисел 1..6 на верхней грани игральной кости, то можно считать, что такое событие имеет множество исходов и для каждого из них вероятность составляет 1/6 при симметрии кости.
Если же кость несимметрична, то вероятности отдельных чисел будут разными, но сумма их равна 1.
Стоит только рассматривать итог бросания кости как дискретную случайную величину и мы придем к понятию распределения вероятностей такой величины.
Пусть в результате достаточно большого числа наблюдений за игрой с помощью одной и той же кости мы получили следующие данные:
Таблица 2.1
| Грани | 1 | 2 | 3 | 4 | 5 | 6 | Итого |
| Наблюдения | 140 | 80 | 200 | 400 | 100 | 80 |
Подобную таблицу наблюдений за СВ часто называют выборочным распределением, а соответствующую ей картинку (диаграмму) — гистограммой.
Рис. 2.1
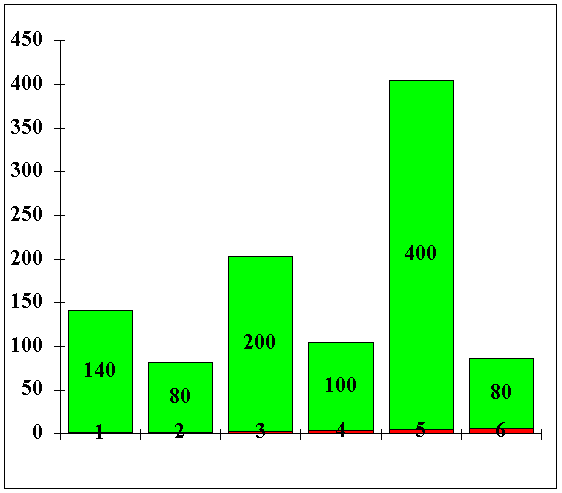
Какую же информацию несет такая табличка или соответствующая ей гистограмма?
Прежде всего, всю — так как иногда и таких данных о значениях случайной величины нет и их приходится либо добывать (эксперимент, моделирование), либо считать исходы такого сложного события равновероятными — по ![]() на любой из исходов.
на любой из исходов.
С другой стороны — очень мало, особенно в цифровом, численном описании СВ. Как, например, ответить на вопрос: — а сколько в среднем мы выигрываем за одно бросание кости, если выигрыш соответствует выпавшему числу на грани?
Нетрудно сосчитать:
1 0.140+2 0.080+3 0.200+4 0.400+5 0.100+6 0.080= 3.48
То, что мы вычислили, называется средним значением случайной величины, если нас интересует прошлое.
Если же мы поставим вопрос иначе — оценить по этим данным наш будущий выигрыш, то ответ 3.48 принято называть математическим ожиданием случайной величины, которое в общем случае определяется как
Mx = å Xi · P(Xi); {2 - 1}
где P(Xi) — вероятность того, что X примет свое i-е очередное значение.
Таким образом, математическое ожидание случайной величины (как дискретной, так и непрерывной)— это то, к чему стремится ее среднее значение при достаточно большом числе наблюдений.
Обращаясь к нашему примеру, можно заметить, что кость несимметрична, в противном случае вероятности составляли бы по 1/6 каждая, а среднее и математическое ожидание составило бы 3.5.
Поэтому уместен следующий вопрос - а какова степень асимметрии кости - как ее оценить по итогам наблюдений?
Для этой цели используется специальная величина — мера рассеяния — так же как мы "усредняли" допустимые значения СВ, можно усреднить ее отклонения от среднего. Но так как разности (Xi - Mx) всегда будут компенсировать друг друга, то приходится усреднять не отклонения от среднего, а квадраты этих отклонений. Величину
![]() {2 - 2}
{2 - 2}
принято называть дисперсией случайной величины X.
Вычисление дисперсии намного упрощается, если воспользоваться выражением
![]() {2 - 3}
{2 - 3}
т. е. вычислять дисперсию случайной величины через усредненную разность квадратов ее значений и квадрат ее среднего значения.
Выполним такое вычисление для случайной величины с распределением рис. 1.
Таблица 2.2
| Грани(X) | 1 | 2 | 3 | 4 | 5 | 6 | Итого |
| X2 | 1 | 4 | 9 | 16 | 25 | 36 | |
| Pi | 0.140 | 0.080 | 0.200 | 0.400 | 0.100 | 0.080 | 1.00 |
| Pi X2 1000 | 140 | 320 | 1800 | 6400 | 2500 | 2880 |
Таким образом, дисперсия составит 14.04 - (3.48)2 = 1.930.
Заметим, что размерность дисперсии не совпадает с размерностью самой СВ и это не позволяет оценить величину разброса. Поэтому чаще всего вместо дисперсии используется квадратный корень из ее значения — т. н. среднеквадратичное отклонение или отклонение от среднего значения:
![]() {2 - 4}
{2 - 4}
составляющее в нашем случае ![]() = 1.389. Много это или мало?
= 1.389. Много это или мало?
Сообразим, что в случае наблюдения только одного из возможных значений (разброса нет) среднее было бы равно именно этому значению, а дисперсия составила бы 0. И наоборот - если бы все значения наблюдались одинаково часто (были бы равновероятными), то среднее значение составило бы (1+2+3+4+5+6) / 6 = 3.500; усредненный квадрат отклонения — (1 + 4 + 9 + 16 + 25 + 36) / 6 =15.167; а дисперсия 15.167-12.25 = 2.917.
Таким образом, наибольшее рассеяние значений СВ имеет место при ее равновероятном или равномерном распределении.
Отметим, что значения Mx и SX являются размерными и их абсолютные значения мало что говорят. Поэтому часто для грубой оценки "случайности" данной СВ используют т. н. коэффициент вариации или отношение корня квадратного из дисперсии к величине математического ожидания:
Vx = SX/MX . {2 - 5}
В нашем примере эта величина составит 1.389/3.48=0.399.
Итак, запомним, что неслучайная, детерминированная величина имеет математическое ожидание равное ей самой, нулевую дисперсию и нулевой коэффициент вариации, в то время как равномерно распределенная СВ имеет максимальную дисперсию и максимальный коэффициент вариации.
В ряде ситуаций приходится иметь дело с непрерывно распределенными СВ - весами, расстояниями и т. п. Для них идея оценки среднего значения (математического ожидания) и меры рассеяния (дисперсии) остается той же, что и для дискретных СВ. Приходится только вместо соответствующих сумм вычислять интегралы. Второе отличие — для непрерывной СВ вопрос о том какова вероятность принятия нею конкретного значения обычно не имеет смысла — как проверить, что вес товара составляет точно 242 кг - не больше и не меньше?
Для всех СВ — дискретных и непрерывно распределенных, имеет очень большой смысл вопрос о диапазоне значений. В самом деле, иногда знание вероятности того события, что случайная величина не превзойдет заданный рубеж, является единственным способом использовать имеющуюся информацию для системного анализа и системного подхода к управлению. Правило определения вероятности попадания в диапазон очень просто — надо просуммировать вероятности отдельных дискретных значений диапазона или проинтегрировать кривую распределения на этом диапазоне.
Взаимосвязи случайных событий
Вернемся теперь к вопросу о случайных событиях. Здесь методически удобнее рассматривать вначале простые события (может произойти или не произойти). Вероятность события X будем обозначать P(X) и иметь ввиду, что вероятность того, что событие не произойдет, составляет
P(X) = 1 - P(X). {2 - 6}
Самое важное при рассмотрении нескольких случайных событий (тем более в сложных системах с развитыми связями между элементами и подсистемами) — это понимание способа определения вероятности одновременного наступления нескольких событий или, короче, — совмещения событий.
Рассмотрим простейший пример двух событий X и Y, вероятности которых составляют P(X) и P(Y). Здесь важен лишь один вопрос — это события независимые или, наоборот взаимозависимые и тогда какова мера связи между ними? Попробуем разобраться в этом вопросе на основании здравого смысла.
Оценим вначале вероятность одновременного наступления двух независимых событий. Элементарные рассуждения приведут нас к выводу: если события независимы, то при 80%-й вероятности X и 20%-й вероятности Y одновременное их наступление имеет вероятность всего лишь 0.8 0.2 = 0.16 или 16% .
Итак — вероятность наступления двух независимых событий определяется произведением их вероятностей:
P(XY) = P(X) ![]() P(Y). {2 - 7}
P(Y). {2 - 7}
Перейдем теперь к событиям зависимым. Будем называть вероятность события X при условии, что событие Y уже произошло условной вероятностью P(X/Y), считая при этом P(X) безусловной или полной вероятностью. Столь же простые рассуждения приводят к так называемой формуле Байеса
P(X/Y)![]() P(Y) = P(Y/X)
P(Y) = P(Y/X)![]() P(X) {2 - 8}
P(X) {2 - 8}
где слева и справа записано одно и то же — вероятности одновременного наступления двух "зависимых" или коррелированных событий.
Дополним эту формулу общим выражением безусловной вероятности события X:
P(X) = P(X/Y)![]() P(Y) + P(X/Y)
P(Y) + P(X/Y)![]() P(Y), {2 - 9}
P(Y), {2 - 9}
означающей, что данное событие X может произойти либо после того как событие Y произошло, либо после того, как оно не произошло (Y) — третьего не дано!
Формулы Байеса или т. н. байесовский подход к оценке вероятностных связей для простых событий и дискретно распределенных СВ играют решающую роль в теории принятия решений в условиях неопределенности последствий этих решений или в условиях противо-действия со стороны природы, или других больших систем (конкуренции). В этих условиях ключевой является стратегия управления, основанная на прогнозе т. н. апостериорной (послеопытной) вероятности события
P(X/Y) ![]()
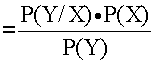 . {2 - 10}
. {2 - 10}
Прежде всего, еще раз отметим взаимную связь событий X и Y — если одно не зависит от другого, то данная формула обращается в тривиальное тождество. Кстати, это обстоятельство используется при решении задач оценки тесноты связей — корреляционном анализе. Если же взаимосвязь событий имеет место, то формула Байеса позволяет вести управление путем оценки вероятности достижения некоторой цели на основе наблюдений над процессом функционирования системы — путем перерасчета вариантов стратегий с учетом изменившихся представлений, т. е. новых значений вероятностей.
Дело в том, что любая стратегия управления будет строиться на базе определенных представлений о вероятности событий в системе — и на первых шагах эти вероятности будут взяты "из головы" или в лучшем случае из опыта управления другими системами. Но по мере "жизни" системы нельзя упускать из виду возможность "коррекции" управления - использования всего накапливаемого опыта.
Схемы случайных событий и законы распределений случайных величин
Большую роль в теории и практике системного анализа играют некоторые стандартные распределения непрерывных и дискретных СВ.
Эти распределения иногда называют "теоретическими", поскольку для них разработаны методы расчета всех показателей распределения, зафиксированы связи между ними, построены алгоритмы расчета и т. п.
Таких, классических законов распределений достаточно много, хотя "штат" их за последние 30..50 лет практически не пополнился. Необходимость знакомства с этими распределениями для специалистов вашего профиля объясняется тем, что все они соответствуют некоторым "теоретическим" схемам случайных (большей частью — элементарных) событий.
Как уже отмечалось, наличие больших массивов взаимосвязанных событий и обилие случайных величин в системах экономики приводит к трудностям априорной оценки законов распределений этих событий или величин. Пусть, к примеру, мы каким-то образом установили математическое ожидание спроса некоторого товара. Но этого мало - надо хотя бы оценить степень колебания этого спроса, ответить на вопрос — а какова вероятность того, что он будет лежать в таких-то пределах? Вот если бы установить факт принадлежности данной случайной величины к такому классическому распределению как т. н. нормальное, то тогда задача оценки диапазона, доверия к нему (доверительных интервалов) была бы решена безо всяких проблем.
Доказано, например, что с вероятностью более 95% случайная величина X с нормальным законом распределения лежит в диапазоне — математическое ожидание Mx плюс/минус три среднеквадратичных отклонения SX.
Так вот — все дело в том к какой из схем случайных событий классического образца ближе всего схема функционирования элементов вашей большой системы. Простой пример - надо оценить показатели оплаты за услуги предоставления времени на междугородние переговоры - например, найти вероятность того, что за 1 минуту осуществляется ровно N переговоров, если заранее известно среднее число поступающих в минуту заказов. Оказывается, что схема таких случайных событий прекрасно укладывается в т. н. распределение Пуассона для дискретных случайных величин. Этому распределению подчинены почти все дискретные величины, связанные с так называемыми "редкими" событиями.
Далеко не всегда математическая оболочка классического закона распределения достаточно проста. Напротив — чаще всего это сложный математический аппарат со своими, специфическими приемами. Но дело не в этом, тем более при "повальной" компьютеризации всех областей деятельности человека. Разумеется, нет необходимости знать в деталях свойства всех или хоть какой-то части классических распределений - достаточно иметь в виду саму возможность воспользоваться ими.
Из личного опыта - очень давно, в до_компьютерную эру автору этих строк удалось предложить метод оценки степени надежности энергоснабжения, найти по сути дела игровой метод принятия решения о необходимости затрат на резервирование линий электропередач в условиях неопределенности — игры с природой.
Таким образом, при системном подходе к решению той или иной задачи управления (в том числе и экономического) надо очень взвешено отнестись к выбору элементов системы или отдельных системных операций. Не всегда "укрупнение показателей" обеспечит логическую стройность структуры системы — надо понимать, что заметить близость схемы событий в данной системе к схеме классической чаще всего удается на самом "элементарном" уровне системного анализа.
Завершая вопрос о распределении случайных величин обратим внимание на еще одно важное обстоятельство: даже если нам достаточно одного единственного показателя — математического ожидания данной случайной величины, то и в этом случае возникает вопрос о надежности данных об этом показателя.
В самом деле, пусть нам дано т. н. выборочное распределение случайной величины X (например — ежедневной выручки в $) в виде 100 наблюдений за этой величиной. Пусть мы рассчитали среднее Mx и оно составило $125 при колебаниях от $50 до $200. Попутно мы нашли SX, равное $5. Теперь уместен вопрос: а насколько правдоподобным будет утверждение о том, что в последующие дни выручка составит точно $125? Или будет лежать в интервале $120..$130? Или окажется более некоторой суммы — например, $90?
Вопросы такого типа чрезвычайно остры - если это всего лишь элемент некоторой экономической системы (один из многих), то выводы на финише системного анализа, их достоверность, конечно же, зависят от ответов на такие вопросы.
Что же говорит теория, отвечая на эти вопросы? С одной стороны очень много, но в некоторых случаях — почти ничего. Так, если у вас есть уверенность в том, что "теоретическое" распределение данной случайной величины относится к некоторому классическому (т. е. полностью описанному в теории) типу, то можно получить достаточно много полезного.
· С помощью теории можно найти доверительные интервалы для данной случайной величины. Если, например, уже доказано (точнее — принята гипотеза) о нормальном распределении, то зная среднеквадратичное отклонение можно с уверенностью в 5% считать, что окажется вне диапазона (Mx - 3![]() Sx)......(Mx
Sx)......(Mx ![]() 3
3![]() Sx) или в нашем примере выручка с вероятностью 0.05 будет <$90 или >$140. Надо смириться со своеобразностью теоретического вывода — утверждается не тот факт, что выручка составит от 90 до 140 (с вероятностью 95%), а только то, что сказано выше.
Sx) или в нашем примере выручка с вероятностью 0.05 будет <$90 или >$140. Надо смириться со своеобразностью теоретического вывода — утверждается не тот факт, что выручка составит от 90 до 140 (с вероятностью 95%), а только то, что сказано выше.
· Если у нас нет теоретических оснований принять какое либо классическое распределение в качестве подходящего для нашей СВ, то и здесь теория окажет нам услугу — позволит проверить гипотезу о таком распределении на основании имеющихся у нас данных. Правда - исчерпывающего ответа "Да" или "Нет" ждать нечего. Можно лишь получить вероятность ошибиться, отбросив верную гипотезу (ошибка 1 рода) или вероятность ошибиться приняв ложную (ошибка 2 рода).
· Даже такие "обтекаемые" теоретические выводы в сильной степени зависят от объема выборки (количества наблюдений), а также от "чистоты эксперимента" — условий его проведения.
Методы непараметрической статистики
Использование классических распределений случайных величин обычно называют "параметрической статистикой" - мы делаем предположение о том, что интересующая нас СВ (дискретная или непрерывная) имеет вероятности, вычисляемые по некоторым формулам или алгоритмам. Однако не всегда у нас имеются основания для этого. Причин тому чаще всего две:
· некоторые случайные величины просто не имеют количественного описания, обоснованных единиц измерения (уровень знаний, качество продукции и т. п.);
· наблюдения над величинами возможны, но их количество слишком мало для проверки предположения (гипотезы) о типе распределения.
В настоящее время в прикладной статистике все большей популярностью пользуются методы т. н. непараметрической статистики — когда вопрос о принадлежности распределения вероятностей данной величины к тому или иному классу вообще не подымается, но конечно же — задача оценки самой СВ, получения информации о ней, остается.
Одним из основных понятий непараметрической статистики является понятие ШКАЛЫ или процедуры шкалирования значений СВ. По своему смыслу процедура шкалирования суть решение вопроса о "единицах измерения" СВ. Принято использовать четыре вида шкал.
Nom. Первой из них рассмотрим НОМИНАЛЬНУЮ шкалу — применяемую к тем величинам, которые не имеют природной единицы измерения. Если некоторая величина может принимать на своей номинальной шкале значения X, Y или Z, то справедливыми считаются только выражения типа: (X#Y), (X#Z), (X=Z), а выражения типа (X>Y), (X<Z), (X+Z) не имеют никакого смысла. Примеры СВ, к которым применимы только номинальные шкалы — пол, цвет, марка автомобиля и т. п.
Ord. Второй способ шкалирования - использование ПОРЯД-КОВЫХ шкал. Они незаменимы для СВ, не имеющих природных единиц измерения, но позволяющих применять понятия предпочтения одного значения другому. Типичный пример: оценки знаний (даже при нечисловом описании), служебные уровни и т. п.; для таких величин разрешены не только отношения равенства (= или #), но и знаки предпочтения (> или <). Иногда говорят о рангах значений таких величин.
Int & Rel. Еще два способа шкалирования используются для СВ, имеющих натуральные размерности — это ИНТЕРВАЛЬНАЯ и ОТНОСИТЕЛЬНАЯ шкала. Для таких величин, кроме отношений равенства и предпочтения, допустимы операции сравнения - т. е. все четыре действия арифметики. Главная особенность таких шкал заключается в том, что разность двух значений на шкале (36 и 12) имеет один смысл для любого места шкалы (28 и 4). Различие между интервальной шкалой и относительной — только в понятии нуля — на интервальной шкале 0 Кг веса означает отсутствие веса, а на относительной шкале температур 0 градусов не означает отсутствие теплоты — поскольку возможны температуры ниже 0 градусов (Цельсия).
Можно теперь заметить еще одно преимущество, которое мы получаем при использовании методов непараметрической статистики — если мы сталкиваемся со случайной величиной непрерывной природы, то использование интервальной или относительной шкалы позволит нам иметь дело не со случайными величинами, а со случайными событиями — типа "вероятность того, что вес продукции находится в интервале 17 Кг". Поэтому можно предложить единый подход к описанию всех показателей функционирования сложной системы — описание на уровне простых случайных событий (с вероятностью P(X) может произойти событие X). При том под событием придется понимать то, что случайная величина займет одно из допустимых для нее положений на шкале Nom, Ord, Int или Rel.
Конечно — такой, “микроскопический” подход резко увеличивает объем информации, необходимой для системного анализа. Частично этот недостаток смягчается при использовании компьютерных методов системного анализа, но более важно другое — преимущество на начальных этапах анализа, когда решаются вопросы дезинтеграции большой системы (выделение отдельных ее элементов) и последующей ее интеграции для разработки стратегии управления системой.
Не будет большим преувеличением считать, что методы непараметрической статистики - наиболее мощное средство для решения задач системного анализа во многих областях деятельности человека и, в частности, в экономике.
Корреляция случайных величин
Прямое токование термина корреляция — стохастическая, вероятная, возможная связь между двумя (парная) или несколькими (множественная) случайными величинами.
Выше говорилось о том, что если для двух СВ (X и Y) имеет место равенство P(XY) =P(X) ![]() P(Y), то величины X и Y считаются независимыми. Ну, а если это не так!?
P(Y), то величины X и Y считаются независимыми. Ну, а если это не так!?
Ведь всегда важен вопрос — а как сильно зависит одна СВ от другой? И дело в не присущем людям стремлении анализировать что-либо обязательно в числовом измерении. Уже понятно, что системный анализ означает непрерывные выЧИСЛения, что использование компьютера вынуждает нас работать с числами, а не понятиями.
Для числовой оценки возможной связи между двумя случайными величинами: Y(со средним My и среднеквадратичным отклонением Sy) и — X (со средним Mx и среднеквадратичным отклонением Sx) принято использовать так называемый коэффициент корреляции
Rxy=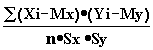 . {2 - 11}
. {2 - 11}
Этот коэффициент может принимать значения от -1 до +1 — в зависимости от тесноты связи между данными случайными величинами.
Если коэффициент корреляции равен нулю, то X и Y называют некоррелированными. Считать их независимыми обычно нет оснований — оказывается, что существуют такие, как правило — нелинейные связи величин, при которых Rxy = 0, хотя величины зависят друг от друга. Обратное всегда верно — если величины независимы, то Rxy = 0. Но, если модуль Rxy = 1, то есть все основания предполагать наличие линейной связи между Y и X. Именно поэтому часто говорят о линейной корреляции при использовании такого способа оценки связи между СВ.
Отметим еще один способ оценки корреляционной связи двух случайных величин — если просуммировать произведения отклонений каждой из них от своего среднего значения, то полученную величину —
Сxy= S (X - Mx)· (Y - My)
или ковариацию величин X и Y отличает от коэффициента корреляции два показателя: во-первых, усреднение (деление на число наблюдений или пар X, Y) и, во-вторых, нормирование путем деления на соответствующие среднеквадратичные отклонения.
Такая оценка связей между случайными величинами в сложной системе является одним из начальных этапов системного анализа, поэтому уже здесь во всей остроте встает вопрос о доверии к выводу о наличии или отсутствии связей между двумя СВ.
В современных методах системного анализа обычно поступают так. По найденному значению R вычисляют вспомогательную величину:
W = 0.5 Ln[(1 + R)/(1-R)] {2 - 12}
и вопрос о доверии к коэффициенту корреляции сводят к доверительным интервалам для случайной величины W, которые определяются стандартными таблицами или формулами.
В отдельных случаях системного анализа приходится решать вопрос о связях нескольких (более 2) случайных величин или вопрос о множественной корреляции.
Пусть X, Y и Z - случайные величины, по наблюдениям над которыми мы установили их средние Mx, My,Mz и среднеквадратичные отклонения Sx, Sy, Sz.
Тогда можно найти парные коэффициенты корреляции Rxy, Rxz, Ryz по приведенной выше формуле. Но этого явно недостаточно - ведь мы на каждом из трех этапов попросту забывали о наличии третьей случайной величины! Поэтому в случаях множественного корреляционного анализа иногда требуется отыскивать т. н. частные коэффициенты корреляции — например, оценка виляния Z на связь между X и Y производится с помощью коэффициента
Rxy.z = 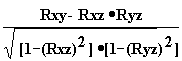 {2 - 13}
{2 - 13}
И, наконец, можно поставить вопрос — а какова связь между данной СВ и совокупностью остальных? Ответ на такие вопросы дают коэффициенты множественной корреляции Rx.yz, Ry.zx, Rz.xy, формулы для вычисления которых построены по тем же принципам — учету связи одной из величин со всеми остальными в совокупности.
На сложности вычислений всех описанных показателей корреляционных связей можно не обращать особого внимания - программы для их расчета достаточно просты и имеются в готовом виде во многих ППП современных компьютеров.
Достаточно понять главное — если при формальном описании элемента сложной системы, совокупности таких элементов в виде подсистемы или, наконец, системы в целом, мы рассматриваем связи между отдельными ее частями, — то степень тесноты этой связи в виде влияния одной СВ на другую можно и нужно оценивать на уровне корреляции.
В заключение заметим еще одно — во всех случаях системного анализа на корреляционном уровне обе случайные величины при парной корреляции или все при множественной считаются "равноправными" — т. е. речь идет о взаимном влиянии СВ друг на друга.
Так бывает далеко не всегда - очень часто вопрос о связях Y и X ставится в иной плоскости — одна из величин является зависимой (функцией) от другой (аргумента).
Линейная регрессия
В тех случаях, когда из природы процессов в системе или из данных наблюдений над ней следует вывод о нормальном законе распределения двух СВ - Y и X, из которых одна является независимой, т. е. Y является функцией X, то возникает соблазн определить такую зависимость “формульно”, аналитически.
В случае успеха нам будет намного проще вести системный анализ — особенно для элементов системы типа "вход-выход”. Конечно, наиболее заманчивой является перспектива линейной зависимости типа Y = a + b· X .
Подобная задача носит название задачи регрессионного анализа и предполагает следующий способ решения.
Выдвигается следующая гипотеза:
H0: случайная величина Y при фиксированном значении величины X распределена нормально с математическим ожиданием
My = a + b· X и дисперсией Dy, не зависящей от X. {2 - 14}
При наличии результатов наблюдений над парами Xi и Yi предварительно вычисляются средние значения My и Mx, а затем производится оценка коэффициента b в виде
b =![]()
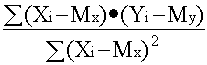 = Rxy
= Rxy ![]()
![]() {2 - 15}
{2 - 15}
что следует из определения коэффициента корреляции {2 - 11}.
После этого вычисляется оценка для a в виде
a = My - b![]() MX {2 - 16}
MX {2 - 16}
и производится проверка значимости полученных результатов. Таким образом, регрессионный анализ является мощным, хотя и далеко не всегда допустимым расширением корреляционного анализа, решая всё ту же задачу оценки связей в сложной системе.
Элементы теории статистических решений
Что такое - статистическое решение? В качестве простейшего примера рассмотрим ситуацию, в которой вам предлагают сыграть в такую игру:
· вам заплатят 2 доллара, если подброшенная монета упадет вверх гербом;
· вы заплатите 1 доллар, если она упадет гербом вниз.
Скорее всего, вы согласитесь сыграть, хотя понимаете степень риска. Вы сознаете, "знаете" о равновероятности появления герба и "вычисляете" свой выигрыш 0.5 · 1- 0.5 · 1= + $0.5.
Усложним игру — вы видите, что монета несколько изогнута и возможно будет падать чаще одной из сторон. Теперь решение играть или не играть по-прежнему зависит от вероятности выигрыша, которая не может быть заранее (по латыни — apriori) принята равной 0.5.
Человек, знакомый со статистикой, попытается оценить эту вероятность с помощью опытов, если конечно они возможны и стоят не очень дорого. Немедленно возникает вопрос - сколько таких бросаний вам будет достаточно?
Пусть с вас причитается 5 центов за одно экспериментальное бросание, а ставки в игре составляют $2000 против $1000. Скорее всего, вы согласитесь сыграть, заплатив сравнительно небольшую сумму за 100..200 экспериментальных бросков. Вы, наверное, будете вести подсчет удачных падений и, если их число составит 20 из 100, прекратите эксперимент и сыграете на ставку $2000 против $1000, так как ожидаемый выигрыш оценивается в 0.8· 2000 + 0.2· 1000 -100· 0.05=$1795.
В приведенных примерах главным для принятия решения была вероятность благоприятного исхода падения монетки. В первом случае — априорная вероятность, а во втором — апостериорная. Такую информацию принято называть данными о состоянии природы.
Приведенные примеры имеют самое непосредственное отношение к существу нашего предмета. В самом деле — при системном управлении приходится принимать решения в условиях, когда последствия таких решений заранее достоверно неизвестны. При этом вопрос: играть или не играть — не стоит! "Играть" надо, надо управлять системой. Вы спросите - а как же запрет на эксперименты? Ответ можно дать такой — само поведение системы в обычном ее состоянии может рассматриваться как эксперимент, из которого при правильной организации сбора и обработки информации о поведении системы можно ожидать получения данных для выяснения особенности системного подхода к решению задач управления.
Этапы системного анализа
Общие положения
В большинстве случаев практического применения системного анализа для исследования свойств и последующего оптимального управления системой можно выделить следующие основные этапы: · Содержательная постановка задачи
· Построение модели изучаемой системы
· Отыскание решения задачи с помощью модели
· Проверка решения с помощью модели
· Подстройка решения под внешние условия
· Осуществление решения
Остановимся вкратце на каждом из этих этапов. Будем выделять наиболее сложные в понимании этапы и пытаться усвоить методы их осуществления на конкретных примерах.
Но уже сейчас отметим, что в каждом конкретном случае этапы системного занимают различный “удельный вес” в общем объеме работ по временным, затратным и интеллектуальным показателям. Очень часто трудно провести четкие границы — указать, где оканчивается данный этап и начинается очередной.
Содержательная постановка задачи
Уже упоминалось, что в постановке задачи системного анализа обязательно участие двух сторон: заказчика (ЛПР) и исполнителя данного системного проекта. При этом участие заказчика не ограничивается финансированием работы - от него требуется (для пользы дела) произвести анализ системы, которой он управляет, сформулированы цели и оговорены возможные варианты действий. Так, — в упомянутом ранее примере системы управления учебным процессом одной из причин тихой кончины ее была та, что одна из подсистем руководство Вузом практически не обладала свободой действий по отношению к подсистеме обучаемых.
Конечно же, на этом этапе должны быть установлены и зафиксированы понятия эффективности деятельности системы. При этом в соответствии с принципами системного подхода необходимо учесть максимальное число связей как между элементами системы, так и по отношению к внешней среде. Ясно, что исполнитель-разработчик не всегда может, да и не должен иметь профессиональные знания именно тех процессов, которые имеют место в системе или, по крайней мере, являются главными. С другой стороны совершенно обязательно наличие таких знаний у заказчика — руководителя или администратора системы. Заказчик должен знать что надо сделать, а исполнитель — специалист в области системного анализа — как это сделать.
Обращаясь к будущей вашей профессии можно понять, что вам надо научиться и тому и другому. Если вы окажетесь в роли администратора, то к профессиональным знаниям по учету и аудиту весьма уместно иметь знания в области системного анализа — грамотная постановка задачи, с учетом технологии решения на современном уровне будет гарантией успеха. Если же вы окажетесь в другой категории — разработчиков, то вам не обойтись без “технологических" знаний в области учета и аудита. Работа по системному анализу в экономических системах вряд ли окажется эффективной без специальных знаний в области экономики. Разумеется, наш курс затронет только одну сторону — как использовать системный подход в управлении экономикой.
Построение модели изучаемой системы в общем случае
Модель изучаемой системы в самом лаконичном виде можно представить в виде зависимости
E = f(X,Y) {3 - 1}
где:
E — некоторый количественный показатель эффективности системы в плане достижения цели ее существования T, будем называть его — критерий эффективности.
X — управляемые переменные системы — те, на которые мы можем воздействовать или управляющие воздействия;
Y — неуправляемые, внешние по отношению к системе воздействия; их иногда называют состояниями природы.
Заметим, прежде всего, что возможны ситуации, в которых нет никакой необходимости учитывать состояния природы. Так, например, решается стандартная задача размещения запасов нескольких видов продукции и при этом можем найти E вполне однозначно, если известны значения Xi и, кроме того, некоторая информация о свойствах анализируемой системы.
В таком случае принято говорить о принятии управляющих решений или о стратегии управления в условиях определенности.
Если же с воздействиями окружающей среды, с состояниями природы мы вынуждены считаться, то приходится управлять системой в условиях неопределенности или, еще хуже — при наличии противодействия. Рассмотрим первую, на непросвещенный взгляд — самую простую, ситуацию.
Моделирование в условиях определенности
Классическим примером простейшей задачи системного анализа в условиях определенности может служить задача производства и поставок товара. Пусть некоторая фирма должна производить и поставлять продукцию клиентам равномерными партиями в количестве N =24000 единиц в год. Срыв поставок недопустим, так как штраф за это можно считать бесконечно большим.
Запускать в производство приходится сразу всю партию, таковы условия технологии. Стоимость хранения единицы продукции Cx=10 копеек в месяц, а стоимость запуска одной партии в производство (независимо от ее объема) составляет Cp =400 гривен.
Таким образом, запускать в год много партий явно невыгодно, но невыгодно и выпустить всего 2 партии в год — слишком велики затраты на хранение! Где же “золотая середина”, сколько партий в год лучше всего выпускать?
Будем строить модель такой системы. Обозначим через n размер партии и найдем количество партий за год — p = N / n ![]() 24000 / n.
24000 / n.
Получается, что интервал времени между партиями составляет
t = 12 / p (месяцев), а средний запас изделий на складе — n/2 штук.
Сколько же нам будет стоить выпуск партии в n штук за один раз?
Сосчитать нетрудно — 0.1 · 12 · n / 2 гривен на складские расходы в год и 400![]() p гривен за запуск партий по n штук изделий в каждой.
p гривен за запуск партий по n штук изделий в каждой.
В общем виде годовые затраты составляют
E = ![]()
![]() T
T![]() n / 2 +
n / 2 + ![]()
![]() N / n {3 - 2}
N / n {3 - 2}
где T = 12 — полное время наблюдения в месяцах.
Перед нами типичная вариационная задача: найти такое n0, при котором сумма E достигает минимума.
Решение этой задачи найти совсем просто — надо взять производную по n и приравнять эту производную нулю. Это дает
n0 = 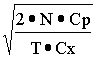 , {3 - 3}
, {3 - 3}
что для нашего примера составляет 4000 единиц в одной партии и соответствует интервалу выпуска партий величиной в 2 месяца.
Затраты при этом минимальны и определяются как
E0 = ![]() , {3 - 4}
, {3 - 4}
что для нашего примера составляет 4800 гривен в год.
Сопоставим эту сумму с затратами при выпуске 2000 изделий в партии или выпуске партии один раз в месяц (в духе недобрых традиций социалистического планового хозяйства):
E1 = 0.1· 12· 2000/2 + 400· 24000/ 2000 = 6000 гривен в год.
Комментарии, как говорится, — излишни!
Конечно, так просто решать задачи выработки оптимальных стратегий удается далеко не всегда, даже если речь идет о детерминированных данных для описания жизни системы — ее модели. Существует целый класс задач системного анализа и соответствующих им моделей систем, где речь идет о необходимости минимизировать одну функции многих переменных следующего типа:
E = a1![]() X1 + a2
X1 + a2![]() X2 + ..... an
X2 + ..... an![]() Xn {3 - 5}
Xn {3 - 5}
где Xi — искомые переменные, ai — соответствующие им коэффициенты или “веса переменных” и при этом имеют место ограничения как на переменные, так и на их веса.
Задачи такого класса достаточно хорошо исследованы в специальном разделе прикладной математики — линейном программировании. Еще в докомпьютерные времена были разработаны алгоритмы поиска экстремумов таких функций E = f(a,X), которые так и назвали — целевыми. Эти алгоритмы или приемы используются и сейчас — служат основой для разработки прикладных компьютерных программ системного анализа.
Системный подход к решению практических задач управления экономикой, особенно для задач со многими десятками сотен или даже тысячами переменных привел к появлению специализированных, типовых направлений как в области теории анализа, так и в практике.
Наиболее “старыми” и, следовательно, наиболее обкатанными являются методы решения специфичных задач, которые давно уже можно называть классическими.
Специалистам в области делового администрирования надо знать эти задачи хотя бы на уровне постановки и, главное, в плане моделирования соответствующих систем.
· Задачи управления запасами
Первые задачи управления запасами были рассмотрены еще в 1915 году — задолго не только до появления компьютеров, но и до употребления термина “кибернетика”. Был обоснован метод решения простейшей задачи — минимизация затрат на заказ и хранение запасов при заданном спросе на данную продукцию и фиксированном уровне цен. Решение — размер оптимальной партии обеспечивало наименьшие суммарные затраты за заданный период времени.
Несколько позже были построены алгоритмы решения задачи управления запасами при более сложных условиях — изменении уровня цен (наличие “скидок за качество” и / или “скидок за количество”); необходимости учета линейных ограничений на складские мощности и т. п.
· Задачи распределения ресурсов
В этих задачах объектом анализа являются системы, в которых приходится выполнять несколько операций с продукцией (при наличии нескольких способов выполнения этих операций) и, кроме того, не хватает ресурсов или оборудования для выполнения всех этих операций.
Цель системного анализа — найти способ наиболее эффективного выполнения операций с учетом ограничений на ресурсы.
Объединяет все такие задачи метод их решения — метод математического программирования, в частности, — линейного программирования. В самом общем виде задача линейного программирования формулируется так:
требуется обеспечить минимум выражения (целевой функции)
E(X) = C1![]() X1 + C2
X1 + C2![]() X2 + ......+ Ci
X2 + ......+ Ci![]() Xi + ... Cn
Xi + ... Cn![]() Xn {3 - 6} при следующих условиях:
Xn {3 - 6} при следующих условиях:
все Xi положительны и, кроме того, на все Xi налагаются m ограничений (m < n)
A11· X1 + A12· X2 + ......+ Aij· Xj + ... A1n· Xn = B1;
.....................................................................................
Ai1· X1 + Ai2· X2 + ......+ Aij· Xj + ... Ain· Xn = Bi; {3 - 7}
.....................................................................................
Am1· X1 + Am2· X2 + .....+ Amj· Xj+ ... Amn· Xn = Bm .
Начала теоретического обоснования и разработки практических методов решения задач линейного программирования были положены Д.Данцигом (по другой версии — Л.В.Канторовичем).
Для большинства конкретных приложений универсальным считается т. н. симплекс-метод поиска цели, для него и смежных методов разработаны специальные пакеты прикладных программ (ППП) для компьютеров.
Наличие нескольких целей — многокритериальность системы
Весьма часто этап содержательной постановки задачи системного анализа приводит нас к выводу о наличии нескольких целей функционирования системы. В самом деле, если некоторая экономическая система может иметь “главную цель” — достижение максимальной прибыли, то почти всегда можно наблюдать ситуацию наличия ограничений или условий. Нарушение этих условий либо невозможно (тогда не будет самой системы), либо заведомо приводит к недопустимым последствиям для внешней cреды. Короче говоря, ситуация, когда цель всего одна и достичь ее требуется любой ценой, практически невероятна.
Пусть имеется самая простая ситуация многокритериальности — существуют только две цели системы T1 и T2 и только две возможных стратегии S1, S2 .
Пусть мы как-то оценили эффективность E11 стратегии S1 по отношению к T1 и эффективность эта оказалась равной 0.4 (по некоторой шкале 0..1). Проделав такую же оценку для всех стратегий и всех целей, мы получили табличку (матрицу эффективностей):
Таблица 3.1
| E | T1 | T2 |
| S1 | 0.4 | 0.6 |
| S2 | 0.7 | 0.3 |
Какую же из стратегий считать наилучшей? Пока мы не оговорим значимость каждой из целей, не укажем их веса, — спорить бесполезно! Вот если бы нам было известно, что первая цель, к примеру, в 3 раза важнее второй, то тогда
можно учесть их относительные веса — скажем величинами 0.75 для первой и 0.25 для второй. При таких условиях суммарные эффективности стратегий (по отношению ко всем целям) составят:
для первой E1 = 0.4 · 0.70 + 0.6 · 0.30 = 0.28 + 0.18 = 0.46;
для второй E2 = 0.8 · 0.70 + 0.2 · 0.25 = 0.56 + 0.05 = 0.61;
так что ответ на вопрос о выборе стратегии далеко не очевиден.
Итак, критерий эффективности системы при наличии нескольких целей приходится выражать через эффективности отдельных стратегий виде: Es = S St · Ut {3 - 8}
т. е. учитывать веса отдельных целей Ut.
Если вы внимательно следили за рассуждениями при рассмотрении примера {3-2}, то сейчас можете сообразить, что по сути дела там речь шла о двух целях. С одной стороны, мы хотели бы иметь как можно меньшие партии — их дешевле хранить (мал срок хранения). с другой стороны, нам были желательны большие партии, поскольку при этом меньше затраты на запуск партий в производство. Если бы мы перебирали все 365 возможных стратегий (от смены партии каждый день до одной в год), то, конечно же, нашли бы оптимальную стратегию со сменой партий каждые два месяца. Другое дело, что в нашем распоряжении была аналитическая модель системы (формула суммарных затрат).
Так вот — весовые коэффициенты целей в той модели были равными и мы их могли не замечать при поиске минимума затрат. Ну, а что делать, если “важность” целей приходится измерять не по шкале Int или Rel, т. е. в числовом виде, а по шкале Ord? Иными словами — откуда берутся весовые коэффициенты целей?
Очень редко весовые коэффициенты определяются однозначно по “физическому смыслу” задачи системного анализа. Чаще же всего их отыскание можно называть “назначением”, “придумыванием”, “предсказанием” — т. е. никак не "научными" действиями.
Иногда, как ни странно это звучит, весовые коэффициенты назначаются путем голосования — явного или тайного. Дело в том, что в ситуациях, когда нет числового метода оценки веса цели, реальным выходом из положения является использование накопленного опыта.
Нередко задает весовые коэффициенты непосредственно ЛПР, но чаще его опыт управления подсказывает: одна голова — хорошо, а много умных голов
Похожие работы

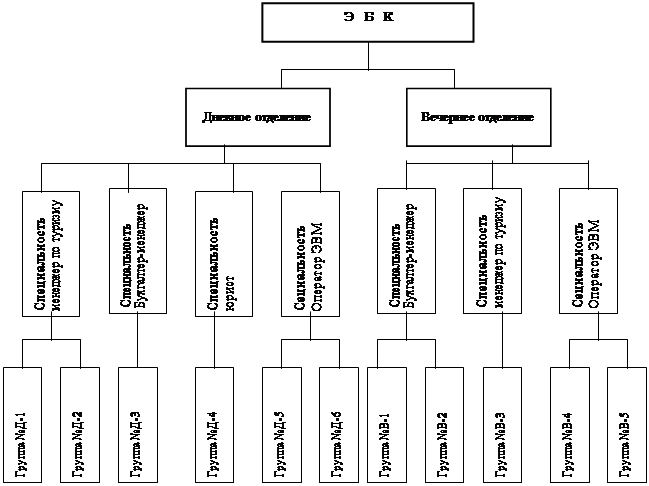
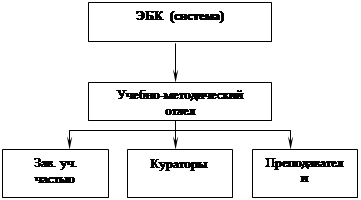
... Организация является одним из частных элементов системы. Суть данной контрольной работы представить организацию как систему, исследовать ее с помощью методов системного анализа, с применением соответствующих математических и эвристических (интуитивных) методов. В качестве математических методов используем методы теории графов. За систему я приняла Экономический бизнес колледж города Москвы ( ...
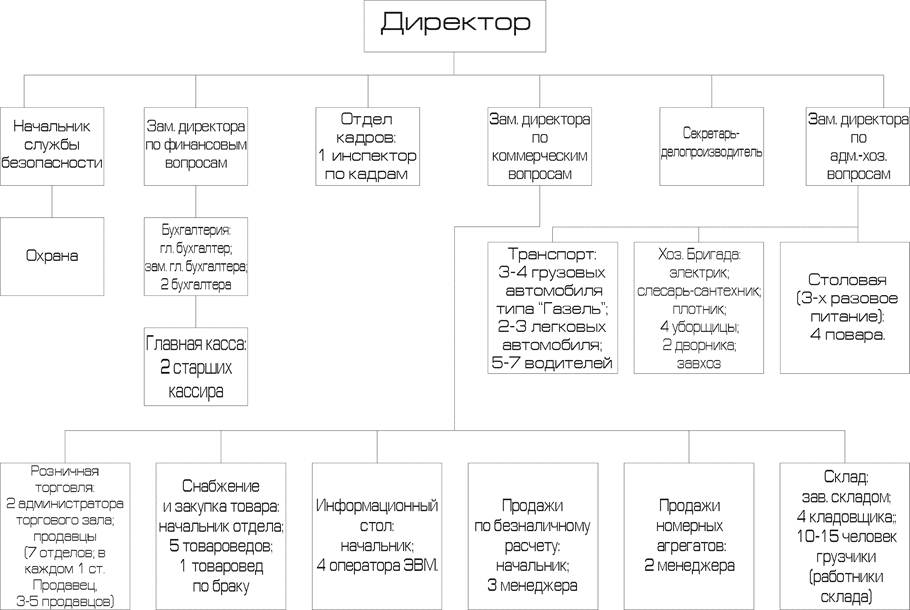
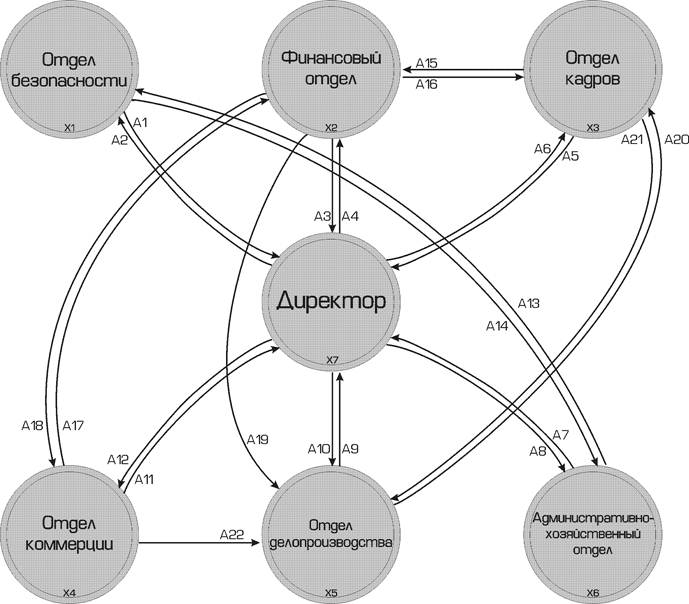
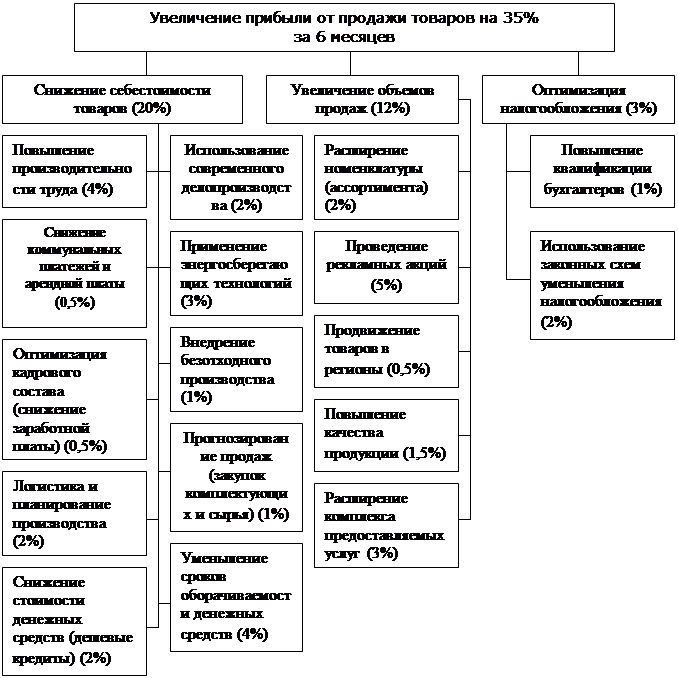
... Все можно вполне исправить и так. 6. Заключение. Проделанная работа показывает, что приведенная структура соответствует поставленным в дереве целей задачам. Это наглядно доказывает, что применение системного анализа вполне оправдано – он помогает решить на первый взгляд неразрешимые задачи, как, например, эта. Другие не менее важные проблемы также решаемы силами системного анализа. Руководителю ...
... колонок МФМИП представляют исходные данные. В колонке 1 показано количество услуг связи в натуральном выражении, предоставленных предприятием по видам в периоде 1, или базисном периоде. В данном примере периоду 1 соответствует год, а в общем случае базисный период, длительность которого зависит от необходимости анализа и планирования: неделя, декада, месяц, год. В колонке 2 в строках продукции ...

... затрат ресурсов по каждому из вариантов, степени чувствительности модели к различным нежелательным внешним воздействиям. 3. Практическая часть. Разработка управленческого решения создания службы управления персоналом в соответствии с технологией применения системного анализа к решению сложных задач I. Общая информация: 1. ООО "Компьюсервис" 2. Дата создания 01.07. 2005г 3. Московская ...
0 комментариев