Intranet-приложения
Традиционные средства и методологии разработки файл-серверных приложений
Новые средства разработки файл-серверных приложений
Серверы баз данных как базовая системная поддержка информационной системы в архитектуре "клиент-сервер"
Основные понятия Intranet
Серверы Intranet
Возможные архитектуры Intranet-приложений
Примеры реализации технологии складов данных у крупнейших компаний
Аналитический раздел
Архитектура задачи
Навигация
Возможные архитектуры Intranet-приложений
Проектирование корпоративных информационных систем и управление
102116
знаков
0
таблиц
9
изображений
5. Возможные архитектуры Intranet-приложений
Решения, ориентированные на клиентскую часть системы
Наиболее тривиальная архитектура. Аналогично тому, как в файл-серверных решениях, вся прикладная часть системы находится в клиенте, который взаимодействует с разнообразными серверами Internet (электронной почты, ftp и т.д.) и серверами, управляющими файлами и/или базами данных. Клиент должен быть достаточно "толстым", чтобы быть в состоянии уметь работать с разными видами серверов (для каждого из них требуется индивидуальная клиентская часть) и одновременно выполнять прикладную обработку данных. Серверы могут быть разной толщины в зависимости от своей функциональной ориентированности (сервер электронной почты нуждается в существенно меньшем числе ресурсов, чем мощный сервер баз данных).
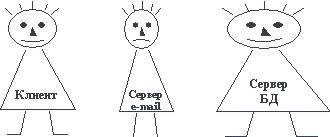 |
Рис. 5.9. "Толстый" клиент и серверы разной толщины в Intranet-системах, ориентированных на клиента
Трехзвенные архитектуры (Web-ориентированные)
Ориентация на использование Web-технологии позволяет одновременно добиться двух эффектов. Во-первых, за счет использования CGI или API можно перенести на сторону сервера часть логики приложения. Во-вторых, используя технику шлюзования Web-сервера (опять же применяя CGI-шлюзы или API) можно работать через Web-сервер (в стандартном интерфейсе) с другими серверами. Клиента можно сделать очень "тонким", Web-сервер будет достаточно "толстым", а остальные такими, как получится.
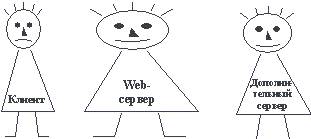 |
Рис. 5.10. "Тонкий" клиент, "толстый" Web-сервер и сравнительно "стройный" дополнительный сервер
Решения, основанные на использовании языка Java
Язык Java можно использовать для программирования Java-апплетов, которые выполняются на стороне клиента, и Java-приложений, выполняемых на стороне сервера. Естественно, клиент, приспособленный к выполнению Java-апплетов, становится несколько толще. Что же касается использования Java-программ на стороне сервера, то большее значение может иметь сравнительная надежность этого языка (в том смысле, что интерпретируемая Java-программа с меньшей вероятностью может нанести вред серверу).
Информационные приложения, основанные на использовании "складов данных" (DataWarehousing)
Здесь рассматриваются вопросы организации специального класса информационных приложений, ориентированных не на оперативную обработку транзакций (On-Line Transaction Processing - OLTP), а на оперативную аналитическую обработку (On-Line Analitical Processing - OLAP). У этих двух разновидностей систем принципиально разные задачи. Корпоративные информационные OLTP-системы создаются для того, чтобы способствовать повседневной деятельности корпорации, и опираются на актуальные для текущего момента данные. OLAP-системы служат для анализа деятельности корпорации или ее компонентов и прогнозирования будущего состояния. Для этого требуется использовать многочисленные накопленные данные о деятельности корпорации в прошлом, а также внешние источники данных, формирующие контекст, в котором работала корпорация.
Система оперативной аналитической обработки данных отличается от статической системы поддержки принятия решений (Decision Support System - DSS) тем, что OLAP-система позволяет аналитику динамически формировать класс вопросов, который требуется для решаемой им текущей аналитической задачи. DSS обеспечивает выдачу отчетов в соответствии с заранее сформулированными правилами. Для удовлетворения нового запроса нужно формально его описать, запрограммировать и только потом выполнить.
1. Проблема интеграции данных
Любая крупная и давно существующая корпорация обладает несколькими базами данных, относящимися к разным видам деятельности. Данные могут иметь разные представления, а иногда могут быть даже несогласованными (например, из-за ошибки ввода в одну из баз данных). Это нехорошо даже для OLTP-систем и в принципе непригодно для OLAP-систем, которые должны обрабатывать общие исторические согласованные корпоративные данные. Для оперативной аналитической обработки требуется привлечение внешних источников данных, которые тем более могут обладать разными форматами и требовать согласования.На подобных рассуждениях и возникла концепция склада данных как предметно-ориентированного, интегрированного, неизменчивого, поддерживающего хронологию набора данных, организованного для целей поддержки управления.
Подход построения склада данных для интеграции неоднородных источников данных принципиально отличается от подхода динамической интеграции разнородных баз данных. В случае склада данных реально строится новое крупномасштабное хранилище, управление данными в котором происходит, вообще говоря, по другим правилам, нежели в исходных оперативных базах данных.
В основе концепции склада данных лежат две основные идеи:
Интеграция разъединенных детализированных данных (детализированных в том смысле, что они описывают некоторые конкретные факты, свойства, события и т.д.) в едином хранилище. В процессе интеграции должно выполняться согласование рассогласованных детализированных данных и, возможно, их агрегация. Данные могут поступать из исторических архивов корпорации, оперативных баз данных, внешних источников.
Разделение наборов данных, используемых для оперативной обработки, и наборов данных, применяемых для решения задач анализа.
Некоторых проблемы реализации складов данных:
неоднородность программной среды;
распределенный характер организации;
повышенные требования к безопасности данных;
необходимость наличия многоуровневых справочников метаданных;
потребность в эффективном хранении и обработке очень больших объемов информации.
Склад данных практически никогда не создается на пустом месте. Почти всегда конечное решение будет разнородным, т.е. в нем будут использоваться автономно разработанные программные средства. Прежде всего это касается формирования интегрированного согласованного набора данных, которые могут поступать из разнородных баз данных, электронных архивов, публичных и коммерческих электронных каталогов, справочников, статистических сборников. При построении склада данных приходится решать задачу построения единой, согласованно функционирующей информационной системы на основе неоднородных программных средств и решений. При выборе средств реализации склада данных приходится учитывать множество факторов, включающих уровень совместимости различных программных компонентов, легкость их освоения и использования, эффективность функционирования и т.д.
В концепции склада данных предопределено то, что операционная аналитическая обработка может выполняться в любом узле сети независимо от места расположения основного хранилища. Хотя при аналитической обработке данные только читаются, и потребность в синхронизации отсутствует, для достижения эффективности необходимо поддерживать репликацию данных в разных узлах сети. (На самом деле, все не так просто. Одним из требований к складам данных является то, чтобы свежая информация поступала на склад как можно быстрее. Т.е. потенциально любая модификация оперативной базы данных может инициировать добавление данных к складу данных, а тогда потребуется обновить и все реплики, для чего синхронизация все-таки нужна.)
Собранная вместе согласованная информация об истории развития корпорации, ее успехах и неудачах, о взаимоотношениях с поставщиками и заказчиками, об истории и состоянии рынка дает возможность анализа прошлой и текущей деятельности корпорации и построения прогнозов для будущего. Эта информация настолько ценна для корпорации, что нельзя допустить возможности ее утечки . В системах, основанных на складах данных, оказывается недостаточной защита данных в стиле языка SQL, которую обеспечивают обычные коммерческие СУБД (этот уровень защиты соответствует классу C2 в соответствии с классификацией Оранжевой Книги Министерства обороны США). Для обеспечения должного уровня защиты доступ к данным должен контролироваться не только на уровне таблиц и их столбцов, но и на уровне отдельных строк (это уже соответствует классу B1 Оранжевой Книги). Приходится также решать вопросы аутентификации пользователей, защиты данных при их перемещении в склад данных из оперативных баз данных и внешних источников, защиты данных при их передаче по сети.
Если роль метаданных (обычно содержащихся в таблицах-каталогах) в оперативных информационных системах достаточно ограничена, то для OLAP-систем наличие развитых метаданных и средств их предоставления конечным пользователям является одним из основных условий успешной реализации. Например, прежде, чем менеджер корпорации задаст системе свой вопрос, он должен понять, какая информация имеется, насколько она актуальна, можно ли ей доверять, сколько времени может занять формирование ответа и т.д. Для пользователя OLAP-системы требуются метаданные, по крайней мере, следующих типов:
Описания структур данных, их взаимосвязей.
Информация о хранимых на складе данных и поддерживаемых им агрегатах данных.
Информация об источниках данных и о степени их достоверности. Одна и та же информация могла попасть в склад данных из разных источников. Пользователь должен иметь возможность узнать, какой источник был выбран основным, и каким образом производились согласование и очистка данных.
Информация о периодичности обновлений данных. Желательно знать не только то, какому моменту времени соответствуют интересующие его данные, но и когда они в следующий раз будут обновлены.
Информация о владельцах данных. Пользователю OLAP-системы может оказаться полезной информация о наличии в системе данных, к которым он не имеет доступа, о владельцах этих данных и о действиях, которые он должен предпринять, чтобы получить доступ к данным.
Статистические оценки времени выполнения запросов. До выполнения запроса полезно иметь хотя бы приблизительную оценку времени, которое потребуется для получения ответа, и объема этого ответа.
Уже сейчас известны примеры складов данных, содержащих терабайты информации. По данным консалтинговой компании Meta Group, около половины корпораций, использующих или планирующих использовать склады данных, предполагает довести их объем до сотен гигабайт. Проблемой таких больших хранилищ является то, что накладные расходы на внешнюю память возрастают нелинейно при возрастании объема хранилища. Исследования, проведенные на основе тестового набора TPC-D, показали, что для баз данных объемом в 100 гигабайт потребуется внешняя память объемом в 4.87 раза большая, чем нужно собственно для полезных данных. При дальнейшем росте баз данных этот коэффициент увеличивается.
В последнее время все более популярной становится идея совместить концепции склада и рынка данных в одной реализации и использовать склад данных в качестве единственного источника интегрированных данных для всех рынков данных. Тогда естественной становится такая трехуровневая организация OLAP-системы:
На первом уровне реализуется корпоративный склад данных на основе одной из развитых современных реляционных СУБД. Это хранилище интегрированных в основном детализированных данных. Реляционные СУБД обеспечивают эффективное хранение и управление данными очень большого объема, но не слишком хорошо соответствуют потребностям OLAP-систем, в частности, в связи с требованием многомерного представления данных.
На втором уровне поддерживаются рынки данных на основе многомерной системы управления базами данных (примером такой системы является Oracle Express Server). Он может содержать ссылки на склад данных и добирать оттуда информацию по мере поступления запросов. Конечно, это несколько увеличивает время отклика, но зато снимает проблему ограниченного объема многомерной базы данных.
Наконец, на третьем уровне находятся клиентские рабочие места конечных пользователей, на которых устанавливаются средства оперативного анализа данных.
Похожие работы
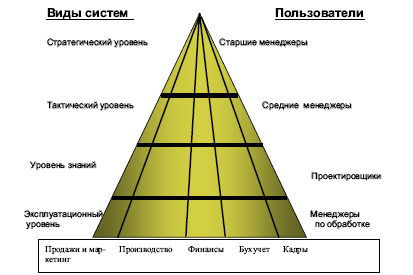
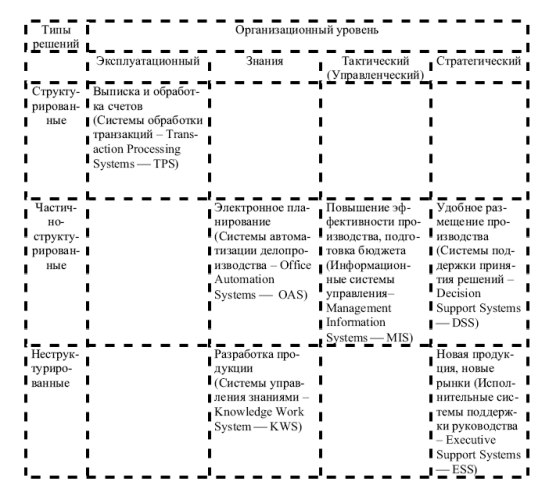
... функционирования. На данный момент существует достаточно большое количество разновидностей информационных систем. Классификация информационных систем обычно осуществляется на основе каких-либо выделенных признаков. Например, с точки зрения управленческого уровня, на котором осуществляется использование ИС, принято делить корпоративные ИС на следующие виды: 1. ИС для обеспечения текущих бизнес- ...
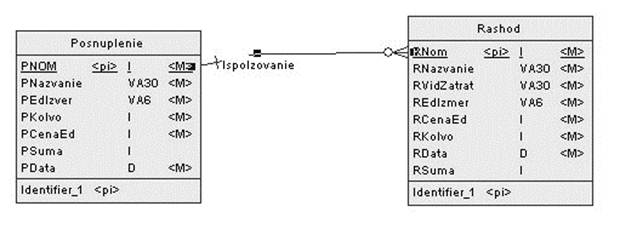
... null, constraint PK_RASHOD primary key (RNazvanie, RVidZatrat) ); Следующим шагом при создании курсовой является генерация базы данных. Для этого используется Interbase. 3. Проектирование базы данных по учету затрат в Delphi. Для подключения базы данных в Delphi используется компоненты IBDatabase, IBTransaction, IBUpdateSQL, IBQuery, DataSource. . Для активации компонента IBDatabase ...
... . Становление рыночной экономики в России породило ряд проблем. Одной из таких проблем является обеспечение безопасности бизнеса. На фоне высокого уровня криминализации общества, проблема безопасности любых видов экономической деятельности становится особенно актуальной. Информационная безопасность среди других составных частей экономической безопасности (финансовой, интеллектуальной, кадровой, ...
... которые отражают поведение системы, зависящее от времени; диаграммы жизненных циклов сущностей относятся именно к этому классу диаграмм. Методы проектирования информационных систем Индустрия разработки автоматизированных информационных систем управления родилась в 50-х - 60-х годах и к концу века приобрела вполне законченные формы. Материалы данного руководства являются обобщением цикла лекций ...
0 комментариев