Навигация
Возможность перескочить через этот сегмент
35323
знака
3
таблицы
7
изображений
1. Возможность перескочить через этот сегмент
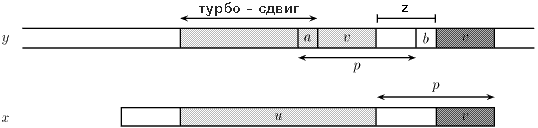
2. Возможность применения «турбо – сдвига»
«Турбо – сдвиг» может произойти, если мы обнаружим, что суффикс образца, который сходится с текстом, короче, чем тот, который был запомнен ранее.
Пусть u - запомненный сегмент, а v - cуффикс, совпавший во время текущей попытки, такой что uzv - суффикс x. Тогда av - суффикс x, два символа а и b встречаются на расстоянии p в тексте, и суффикс x длины |uzv| имеет период длины p, а значит не может перекрыть оба появления символов а и b в тексте. Наименьший возможный сдвиг имеет длину |u| - |v| ( его мы и называем «турбо – сдвигом» ).
По определению, конечный автомат представляет собой пятерку М = (Q, q0, A, ![]() ,
, ![]() ), где:
), где:
Q — конечное множество состояний;
q0![]() Q — начальное состояние;
Q — начальное состояние;
А![]() Q — конечное множество допускающих состояний;
Q — конечное множество допускающих состояний;
![]() — конечный входной алфавит;
— конечный входной алфавит;
![]() — функция Q х
— функция Q х ![]()
![]() Q, называемая функцией переходов автомата.
Q, называемая функцией переходов автомата.
Первоначально конечный автомат находится в состоянии q0. Затем он по очереди читает символы из входной строки. Находясь в состоянии q и читая символ а, автомат переходит в состояние ![]() (q,a). Если автомат находится в состоянии q
(q,a). Если автомат находится в состоянии q ![]() A говорят, что он допускает прочитанную часть входной строки. Если q
A говорят, что он допускает прочитанную часть входной строки. Если q ![]() А, то прочитанная часть строки отвергнута.
А, то прочитанная часть строки отвергнута.
С конечным состоянием М связана функция ![]() , называемая функцией конечного состояния, определяемая следующим образом:
, называемая функцией конечного состояния, определяемая следующим образом: ![]() есть состояние, в которое придет автомат (из начального состояния), прочитав строку w. Автомат допускает строку w тогда и только тогда, когда
есть состояние, в которое придет автомат (из начального состояния), прочитав строку w. Автомат допускает строку w тогда и только тогда, когда ![]()
![]() А
А
Для каждого образца Р можно построить конечный автомат, ищущий этот образец в тексте. Первым шагом в построении автомата, соответствующего строке-образцу Р[1..m], является построение по Р вспомогательной суффикс-функциии (как в алгоритме КМП). Теперь определим конечный автомат, соответствующий образцу Р[1..m], следующим образом:
· Его множество состояний Q = {0,1,..., m}. Начальное состояние q0 = 0. Единственное допускающее состояние m;
· Функция переходов ![]() определена соотношением (q — состояние,
определена соотношением (q — состояние, ![]() — символ):
— символ): ![]() (q,a) =
(q,a) = ![]() (Pqa). (1)
(Pqa). (1)
Поясним это соотношение. Требуется сконструировать автомат таким образом, чтобы при его действии на строку Т соотношение
![]() (Тi) =
(Тi) = ![]() (Тi)
(Тi)
являлось инвариантом (тогда равенство ![]() (Тi) = m будет равносильно тому, что Р входит в Т со сдвигом i — m, и автомат тем самым найдет все допустимые сдвиги). Однако в этом случае вычисление перехода по формуле (1) необходимо для поддержания истинности инварианта, что следует из теорем, приведенных ниже.[3]
(Тi) = m будет равносильно тому, что Р входит в Т со сдвигом i — m, и автомат тем самым найдет все допустимые сдвиги). Однако в этом случае вычисление перехода по формуле (1) необходимо для поддержания истинности инварианта, что следует из теорем, приведенных ниже.[3]
Теорема. Пусть q = ![]() (х), где х — строка. Тогда для любого символа а имеет место
(х), где х — строка. Тогда для любого символа а имеет место ![]() (ха) =
(ха) = ![]() (Pqa).
(Pqa).
Теорема. Пусть ![]() — функция конечного состояния автомата для поиска подстроки Р[1.. m]. Если Т[1.. n] — произвольный текст, то
— функция конечного состояния автомата для поиска подстроки Р[1.. m]. Если Т[1.. n] — произвольный текст, то ![]() (Тi) =
(Тi) = ![]() (Тi) для i=0,1,..., n. [14]
(Тi) для i=0,1,..., n. [14]
Из изложенного следует, что задача поиска подстроки состоит из двух частей:
построение автомата по образцу (определение функции переходов для заданного образца);
применение этого автомата для поиска вхождений образца в заданный текст.
1.5.2. Пример построения конечного автоматаПостроим конечный автомат, допускающий строку ababaca. Поскольку длина образца m = 7 символов, то в автомате будет m + 1 = 8 состояний.
Найдем функцию переходов ![]() . В соответствии с определением (1),
. В соответствии с определением (1), ![]() (q, a) =
(q, a) =![]() (Рqа), где
(Рqа), где ![]() — префикс-функция, а — произвольный символ из алфавита
— префикс-функция, а — произвольный символ из алфавита ![]() , q — номер состояния. Таким образом, необходимо для каждого префикса Pq = P[0..q], q = 0 .. m образца Р и для всех символов а входного алфавита
, q — номер состояния. Таким образом, необходимо для каждого префикса Pq = P[0..q], q = 0 .. m образца Р и для всех символов а входного алфавита ![]() найти длину максимального префикса Р, который будет являться суффиксом строки Рqа. Длина этого префикса и будет значением функции переходов
найти длину максимального префикса Р, который будет являться суффиксом строки Рqа. Длина этого префикса и будет значением функции переходов ![]() (q,a). Если а = P[q + 1] (очередной символ текста совпал со следующим символом образца), то Рqа = Рq+1 и
(q,a). Если а = P[q + 1] (очередной символ текста совпал со следующим символом образца), то Рqа = Рq+1 и ![]() (q, a) = q+1.
(q, a) = q+1.
Такой случай соответствует успешным этапам поиска. Иначе, ![]() (q,a)
(q,a)![]() q. Например, для префикса Р[0..5] = ababa и символа b максимальным суффиксом строки Р[0..5]b=ababab, который одновременно является префиксом Р, будет abab. Его длина равна 4, поэтому значение функции переходов
q. Например, для префикса Р[0..5] = ababa и символа b максимальным суффиксом строки Р[0..5]b=ababab, который одновременно является префиксом Р, будет abab. Его длина равна 4, поэтому значение функции переходов ![]() (5, b) = 4.
(5, b) = 4.
Запишем построенную таким образом функцию переходов в виде таблицы (Табл. 1):
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | |
| a | 1 | 1 | 3 | 1 | 5 | 1 | 7 | 1 |
| b | 0 | 2 | 0 | 4 | 0 | 4 | 0 | 2 |
| c | 0 | 0 | 0 | 0 | 0 | 6 | 0 | 0 |
Строки соответствуют входным символам, столбцы — состояниям автомата. Ячейки, соответствующие успешным этапам поиска (входной символ совпадает со следующим символом образца), выделены серым цветом.
Построим по таблице граф переходов автомата (Рис. 1), распознающего образец ababaca. Находясь в состоянии q и прочитав очередной символ а, автомат переходит в состояние ![]() (q,a). Обратим внимание, что его остов помечен символами образца (эти переходы выделены жирными стрелками).
(q,a). Обратим внимание, что его остов помечен символами образца (эти переходы выделены жирными стрелками).
|
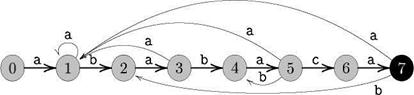
Здесь 0 — исходное состояние, 7 — единственное допускающее состояние (зачернено). Если из вершины i в вершину j ведет стрелка, помеченная буквой а, то это означает, что ![]() (i,a) = j. Отметим, что переходы, для которых
(i,a) = j. Отметим, что переходы, для которых ![]() (i,a) = 0, на графе переходов для его упрощения не обозначены. Жирные стрелки, идущие слева направо, соответствуют успешным этапам поиска подстроки Р — следующий входной символ совпадает с очередным символом образца. Стрелки, идущие справа налево, соответствуют неудачам — следующий входной символ отличается от очередного символа образца.
(i,a) = 0, на графе переходов для его упрощения не обозначены. Жирные стрелки, идущие слева направо, соответствуют успешным этапам поиска подстроки Р — следующий входной символ совпадает с очередным символом образца. Стрелки, идущие справа налево, соответствуют неудачам — следующий входной символ отличается от очередного символа образца.
Ниже приведен результат применения автомата к тексту Т = abababacaba. Под каждым символом Т[г] записано состояние автомата после прочтения этого символа (иными словами, значение ![]() (Тi)) (Табл. 2).
(Тi)) (Табл. 2).

Найдено одно вхождение образца (начиная с позиции 3). Найденный образец в тексте помечен серым цветом. Черным цветом помечено допускающее состояние автомата (состояние с номером 7).
Часть 2. Экспериментальный анализ алгоритмов. 2.1. Суть эксперимента.
Мы рассмотрели несколько алгоритмов, провели оценку их временной и емкостной сложности. Однако, как уже говорилось, данные критерии оценки не позволяют нам наверняка сказать, какой из алгоритмов будет быстрее работать. Поэтому, для дополнительной оценки проведем их экспериментальный анализ, т.е. измерим время, за которое алгоритм выполняет конкретно поставленную задачу.
Имеется несколько текстовых файлов, содержащих 10000 записей вида:
строка
подстрока (имеющаяся в данной строке)
место вхождения
длина подстроки
с разными максимальными длинами строк и подстрок.
Алфавитом является 66 русских заглавных и строчных букв.
Пусть это будут строки длиной не более 10, 100, 250 символов.
Проведем поиск подстрок в строках для каждого из алгоритмов и измерим время работы программы. При этом будем учитывать следующее:
· Строки предварительно загружаем в оперативную память (в виде массива), причем время считывания в массив не учитывается. Предобработка (создание таблиц перехода) входит в общее время.
· Каждый алгоритм запускается 5 раз, время выбирается наименьшее.
Стенд для эксперимента.
Процессор Intel Pentium IV 2,66Ггц
Похожие работы
... - код не совпадает, сравнение не проводим. QWERYTEWEQWERTY FS = 25 - [E] + [Y] = 25 - 3 + 6 = 28 - код совпадает, полное сравнение совпадает. Ура! Текст программы: Program FSISHF; {поиск подстроки в строке} Const NStr = 30000; NSub = 3000; Var FStr : array[1..NStr] of char; FSub : array[1..NSub] of char; {substring} FSum, NSum : longint; {Контрольная сумма} Spec, Work : word; ...
... (Robert S. Boyer) и Муром (J. Strother Moore), считается наиболее быстрым среди алгоритмов общего назначения, предназначенных для поиска подстроки в строке. Прежде чем рассмотреть работу этого алгоритма, уточним некоторые термины. Под строкой мы будем понимать всю последовательность символов текста. Собственно говоря, речь не обязательно должна идти именно о тексте. В общем случае строка – это ...
... какой либо ситуации - Определить результат действия программы. На основании сделанных выводов решено создать дополнительное обучающее средство в виде обучающей программы, поддерживающей индивидуальное изучение всех вопросов темы, а также, дополнительные сведения о типах данных. Кроме того, в программу будет встроен блок самоконтроля, поддерживающий проверку усвоения каждой изучаемой ...

... шкалы оценка пертинентности // НТИ. Сер. 2.- 1992.-№5.-С.19-27 Кноп К. Поиск в Интернете как хроническое заболевание // Мир Internet. - 2002. - N 10. - С. 33-35 Конжаев А. Стратегия информационного поиска // http://www.msiu.ru. Попов С. Поиск информации и принятие решения // НТИ. Сер.2.-2001.-№1.-С.1-4 Степанов В.К Русскоязычные поисковые механизмы в Интернет // ComputerWorld Россия.-1997.-N11 ...
0 комментариев