Блок автоматического управления
Микропроцессорная система управления и диагностики (МСУД) электровозом ЭП1
Объект модернизации
Шунтирующие устройства ШУ-001, ШУ-003
Ячейка МК3.1
Ячейка аналого-цифрового преобразователя АЦ2
Ячейка входных формирователей ВФЗ
Устройство блока БИ1.6 ТЯБК.469136.113-04
Чтобы загрузить БИ1
Четырехступенчатый конвейер команд
Система прерываний
Генерация системного такта
Периферия микроконтроллера 80С166
Аналого-цифровой преобразователь (АЦП)
Навигация
Четырехступенчатый конвейер команд
Мехатронная система обеспечения заданной скорости электровоза на различных участках пути
82531
знак
7
таблиц
17
изображений
3.2 Четырехступенчатый конвейер команд
§ Для увеличения скорости выполнения команд контроллеры семейства С166 содержат 4-х ступенчатый конвейер команд (рисунок 3.3). За один машинный цикл C166 на различных ступенях конвейера выполняет одновременно до 4 команд. Это означает, что обработка каждой команды по времени длится четыре машинных цикла, хотя выполнение команды происходит в течение одного цикла. Таким образом, конвейеризация имеет существенные преимущества для ускорения выполнения последовательности команд при достаточной пропускной способности шины. Время исполнения большинства команд составляет 100 нс при тактовой частоте 20МГц.
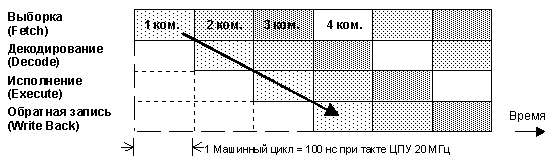
Рисунок 3.3 – Конвейер команд
§ Оптимизированная обработка команд перехода и вызова (Branch Instruction).
В то время как при выполнении обычных команд конвейер не вызывают проблем, команды перехода и вызова требуют выполнения специальных мероприятий. Ко времени достижения командой перехода или вызова фазы Execute следующая по адресу перехода команда только начинает исполнение фазы Fetch. Следовательно, команда, проходящая в конвейере на фазе Decode сразу вслед за командой перехода, должна игнорироваться. В данном случае вместо полного очищения конвейера используется переход с задержкой ("delayed branch"). Ситуация с условным переходом более сложная, т.к. неясно, будет ли следующая команда соответствовать результату проверки условия или нет. Поэтому при выполнении условия перехода вставляется холостая команда на фазе Decode и требуется дополнительный машинный цикл. Для ситуаций без перехода холостая команда не вставляется и один машинный цикл экономится. Таким образом, для команд Jump, Cond. Jump, Call, Return,... обычно требуется только один дополнительный машинный цикл для выборки команды из новой области памяти.
§ Обработка меток (Loop Control). Обычная задача в управляющих приложениях - просмотр таблиц, который состоит в повторном переходе по одному и тому же фиксированному адресу. Если в данном случае не предпринять специальных шагов, то при обработке каждой метки возникает бесполезный машинный цикл. Поэтому здесь осуществлен механизм кэширования (Jump Cache). При первичной обработке метки вставляется пустая команда и, как и раньше вхолостую тратится один машинный цикл. Однако адрес таблицы запоминается в кэш-памяти и при дальнейшем прохождении через метку адрес извлекается из кэш и вставляется непосредственно в фазу Decode. Таким образом, в данном случае переход осуществляется за один машинный цикл.
§ Краевые эффекты конвейера. В фазах Fetch и Decode может одновременно осуществляться запрос шины, если на завершающей фазе текущей команды осуществляется чтение. Предупреждение конфликтов осуществляет контроллер внешней шины External Bus Controller,
§ управляя приоритетами записи, выборки и чтения. Следует упомянуть также о краевых эффектах конвейера, которые могут возникнуть на фазе Write Back при использовании адреса, уже измененного на фазе Fetch. Хотя специальное аппаратное устройство искусственно передвигает вперед операнды чтения и записи, необходимо постоянно об этом помнить. Команды умножения и деления занимают 5 и 10 машинных циклов соответственно и имеют сложный операционный код. Поскольку эти команды длятся больше одного цикла, в конвейер на стадии Decode вставляются холостые команды.
3.3 Конфигурирование внешней шины
§ Одним из наиболее полезных свойств C166 является поддержка нескольких режимов конфигурации, когда, например, выборка кода и данных из внешней памяти осуществляется по 16-разрядной демультиплексной шине с нулевым ожиданием, а доступ к медленной периферии (часы RTC) из соображений экономии может происходить по 8-разрядной шине с 3 состояниями ожидания. В первом случае шина управляется регистром конфигурации BUSCON0, а во втором случае - регистрами конфигурации BUSCON1 и ADDRESEL1, которые определяют режим шины и адресный диапазон соответственно.
§ В ряде микроконтроллеров (C165 и C167) присутствует до четырех независимых дополнительных регистров конфигурации BUSCON1-BUSCON4, каждому из которых соответствует свой внешний вывод CS для соединения с входом разрешения выборки кристалла. Размер и начальный адрес диапазона для каждого сигнала CS1-CS4 задается в регистрах ADDRSEL1-ADDRSEL4. При задании областей действия сигналов CS необходимо помнить, что начальный адрес должен быть кратен размеру блока. Например, для блока размером 64 Кбайт, начальный адрес должен быть равен 0x00000 или 0x10000 или 0x20000 и т.д.
§ Характеристики системной шины для областей памяти, не перекрываемых данными четырьмя адресными диапазонами, задаются в регистре BUSCON0 и устанавливаются аппаратно при считывании линий порта 0 во время сброса, т.е. сигнал CS0 используется для адресации всех областей не определенных сигналами CS1-CS4.Кроме того, для экономии внешней логики присутствуют программируемые сигналы управления шиной. Это означает, что при более чем 20-кратном выигрыше в производительности проект с С166 получается проще, чем для 8031. С166 содержит также программируемые функции арбитража шины HOLD/HOLDA/BREQ для операций межпроцессорного обмена.
§ Непосредственное управление внешней шиной в соответствии с содержимым регистров конфигурации осуществляет контроллер внешней шины. В каждом диапазоне временные параметры циклов чтения-записи и режим работы системной шины задаются специальными битами в регистрах конфигурации. Ширина адресной шины может составлять в зависимости от кристалла 16 (для несегментированного режима), 18 (80C166), 22 (C164) и 24 (C165 и С167) разряда. Ширина шины данных может быть 8 или 16 разрядов, и работа может вестись в мультиплексном и демультиплексном (MUX и NMUX) режимах (у C161 и C164 предусмотрена только мультиплексная внешняя шина). Демультиплексный шинный интерфейс оптимален при высоких требованиях к времени обращения к внешним ОЗУ и ПЗУ. Как уже отмечалось, режимы работы шины могут динамически меняться в процессе выполнения программы. Сравнение скорости работы для различных конфигураций шины при частоте ЦПУ 20 МГц приведено в таблице
0 комментариев