Навигация
Отсеивание менее существенных факторов в процессе построения регрессионной модели;
80420
знаков
0
таблиц
2
изображения
1. отсеивание менее существенных факторов в процессе построения регрессионной модели;
2. замена исходного набора переменных меньшим числом эквивалентных факторов, полученных в результате преобразований исходного набора.
Процедура отсева несущественных факторов в процессе построения регрессионной модели и получила название многошагового регрессионного анализа.
Этот метод основан на вычислении нескольких промежуточных уравнений регрессии, в результате анализа которых получают конечную модель, включающую только факторы, оказывающие статистически существенное влияние на исследуемую зависимую переменную. Различные сочетания одних и тех же факторов оказывают разное влияние на зависимую переменную. Вследствие этого появляется необходимость выбора наилучшей модели, т.к. перебирать все возможные варианты сочетания факторов и строить множество уравнений регрессии (количество которых может быть очень велико) просто не имеет смысла.
Таким образом методы пошагового регрессионного анализа позволяют избежать столь громоздких расчетов и получить достаточно надежную и полную модель зависимости исследуемого признака от ряда объясняющих переменных.
Как было сказано выше, основой многошагового регрессионного анализа является построение уравнения регрессии. Рассмотрим более подробно его систему и основные понятия.
Многомерный регрессионный анализВ общем виде многомерная линейная регрессионная модель зависимости y от объясняющих переменных ![]() ,
, ![]() ,…,
,…,![]() имеет вид:
имеет вид:
![]() .
.
Для оценки неизвестных параметров ![]() взята случайная выборка объема n из (k+1)–мерной случайной величины (y,
взята случайная выборка объема n из (k+1)–мерной случайной величины (y, ![]() ,
,![]() ,…,
,…,![]() ).
).
В матричной форме модель имеет вид:
![]() ,
,
где  ,
, 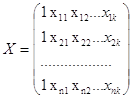 ,
,  , ε=
, ε=![]()
- вектор-столбец фактических значений зависимой переменной размерности n;
- матрица значений объясняющих переменных размерности n*(k+1);
- вектор-столбец неизвестных параметров, подлежащих оценке, размерности (k+1);
- вектор-столбец случайных ошибок размерности n с математическим ожиданием ME=0 и ковариационной матрицей ![]() соответственно, при этом
соответственно, при этом
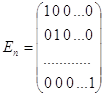 -единичная матрица размерности (nxn).
-единичная матрица размерности (nxn).
Оценки неизвестных параметров ![]() находятся методом наименьших квадратов, минимизируя скалярную сумму квадратов
находятся методом наименьших квадратов, минимизируя скалярную сумму квадратов ![]() по компонентам вектора β.
по компонентам вектора β.
Далее подставив выражение
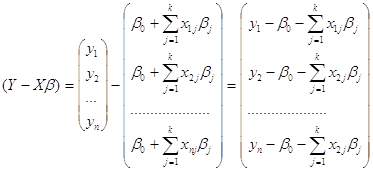 в
в ![]() ,
,
получаем скалярную сумму квадратов ![]()
Условием обращения полученной суммы в минимум является система нормальных уравнений:
![]() , (j=0,1,2,…,k) .
, (j=0,1,2,…,k) .
В результате дифференцирования получается:
![]() .
.
При замене вектора неизвестных параметров β на оценки, полученные методом наименьших квадратов, получаем следующее выражение:
![]() .
.
Далее умножив обе части уравнения слева на матрицу ![]() , получим
, получим
![]()
Так как ![]() , тогда
, тогда ![]() .
.
Полученные оценки вектора b являются не смещенными и эффективными.
Ковариационная матрица вектора b имеет вид:
![]() , где
, где ![]() - остаточная дисперсия.
- остаточная дисперсия.
Элементы главной диагонали этой матрицы представляют собой дисперсии вектора оценок b. Остальные элементы являются значениями коэффициентов ковариации:
![]() , где
, где ![]() ,
, ![]() .
.
Таким образом, оценка ![]() - это линейная функция от зависимой переменной. Она имеет нормальное распределение с математическим ожиданием
- это линейная функция от зависимой переменной. Она имеет нормальное распределение с математическим ожиданием ![]() и дисперсией
и дисперсией ![]() .
.
Несмещенная оценка остаточной дисперсии определяется по формуле:
![]() , где n – объем выборочной совокупности;
, где n – объем выборочной совокупности;
k – число объясняющих переменных.
Для проверки значимости уравнения регрессии используют F-критерий дисперсионного анализа, основанного на разложении общей суммы квадратов отклонений на составляющие части:
![]() , где
, где ![]() - сумма квадратов отклонений (от нуля), обусловленная регрессией;
- сумма квадратов отклонений (от нуля), обусловленная регрессией;
![]()
![]() - сумма квадратов отклонений
фактических значений зависимой переменной от расчетных
- сумма квадратов отклонений
фактических значений зависимой переменной от расчетных ![]() , т.е. сумма квадратов отклонений относительно плоскости регрессии, обусловленное воздействием случайных и неучтенных в модели факторов.
, т.е. сумма квадратов отклонений относительно плоскости регрессии, обусловленное воздействием случайных и неучтенных в модели факторов.
Для проверки гипотезы ![]() используется величина
используется величина  , которая имеет F-распределение Фишера-Снедекора с числом степеней свободы
, которая имеет F-распределение Фишера-Снедекора с числом степеней свободы ![]() и
и ![]() . Если
. Если ![]() , то уравнение регрессии значимо, т.е. в уравнении есть хотя бы один коэффициент регрессии, отличный от нуля.
, то уравнение регрессии значимо, т.е. в уравнении есть хотя бы один коэффициент регрессии, отличный от нуля.
В случае значимости уравнения регрессии проверяется значимость отдельных коэффициентов регрессии. Для проверки нулевой гипотезы ![]() используется величина
используется величина
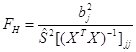 , которая имеет F-распределение Фишера-Снедекора с числом степеней свободы
, которая имеет F-распределение Фишера-Снедекора с числом степеней свободы ![]() и
и ![]() ;
; ![]() - соответствующий элемент главной диагонали ковариационной матрицы.
- соответствующий элемент главной диагонали ковариационной матрицы.
Коэффициент регрессии ![]() считается
значимым, если
считается
значимым, если ![]() . Для значимых коэффициентов регрессии можно построить доверительные интервалы, используя формулу
. Для значимых коэффициентов регрессии можно построить доверительные интервалы, используя формулу
![]() , где
, где ![]() находится по таблице распределения Стьюдента для уровня значимости
находится по таблице распределения Стьюдента для уровня значимости ![]() и числа степеней свободы
и числа степеней свободы ![]() .
.
В многошаговом регрессионном анализе наиболее известны три подхода:
1. Метод случайного поиска с адаптацией. Осуществляется путем построения нескольких уравнений регрессии на основе формально разработанного принципа включения факторов и последующего выбора лучшего уравнения с точки зрения определенного критерия.
2. Метод включения переменных, основанный на построении уравнения регрессии по одному значимому фактору и последовательном добавлении всех остальных статистически значимых переменных путем расчета частных коэффициентов корреляции и F-критерия при проверке значимости вводимого в модель фактора.
3. Метод отсева факторов по t-критерию. Данный метод заключается в построении уравнений регрессии по максимально возможному количеству объясняющих переменных и последующем исключении статистически не существенных факторов.
Метод отсева факторов по t-критериюНаиболее оправданным является использование многошагового регрессионного анализа, основанного на оценке значимости коэффициентов регрессии с помощью t-критерия Стьюдента. Данный метод и был использован при анализе продолжительности жизни населения стран Африки в данной курсовой работе, потому что его применение четко формализовано, и в то же время на различных стадиях построения модели можно производить качественный экономический анализ. Рассмотрим его более подробно.
Итак, на первом этапе строится уравнение регрессии по переменным, предположительно влияющим на исследуемую зависимую переменную. Затем с помощью определенных критериев исключаются те переменные, которые оказывают статистически несущественное влияние. На этом подходе основан метод отсева факторов по t-критерию в многошаговом регрессионном анализе.
Применение t-критерия при отборе существенных факторов основано на следующей предпосылке регрессионного анализа: если выполняется условие, что Ei распределены нормально, то величина 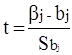 распределена по закону Стьюдента с n = n-k-1 степенями свободы. По этому критерию можно проверить гипотезу о существенном отличии от нуля коэффициента регрессии bj при некотором заданном уровне значимости и n-k-1 степенях, то коэффициент регрессии bj признается значимым.
распределена по закону Стьюдента с n = n-k-1 степенями свободы. По этому критерию можно проверить гипотезу о существенном отличии от нуля коэффициента регрессии bj при некотором заданном уровне значимости и n-k-1 степенях, то коэффициент регрессии bj признается значимым.
Простейшая схема проверки сводится к построению доверительного интервала для каждого коэффициента регрессии и проверке гипотезы о том, находится ли нуль внутри построенного интервала. Если это так, то данный коэффициент регрессии признается незначимым или же его значимость подвергается сомнению и выявляется на следующих этапах анализа.
Схема отбора значимых факторов в уравнение регрессии с помощью t-критерия выглядит следующим образом. Если все коэффициенты регрессии значимы, то уравнение регрессии признается окончательным и принимается в качестве модели исследуемого признака для последующего анализа. Если же среди коэффициентов регрессии имеются незначимые, то соответствующие объясняющие переменные следует исключить из уравнения.
Однако предварительно следует проранжировать коэффициенты регрессии по величине tH и в первую очередь отсеять тот фактор, для которого коэффициент регрессии незначим и tH имеет наименьшее значение. Затем уравнение регрессии пересчитывается снова (уже без исключенного фактора), и производится оценка коэффициентов регрессии по t-критерию. Такую процедуру повторяют до тех пор, пока все коэффициенты регрессии в уравнении не окажутся значимыми.
При этом на каждом шаге, кроме формальной статистической проверки значимости коэффициентов регрессии, проводится экономический анализ несущественных факторов и устанавливается порядок их исключения. В некоторых случаях значение tH находится вблизи tкр, и, с точки зрения содержательности модели, этот фактор можно оставить для последующей проверки его значимости в сочетании с другим набором факторов. Возможность такого экономического анализа при формальной статистической процедуре отсеивания незначимых факторов по t-критерию является большим преимуществом этого метода многошагового регрессионного анализа.
Вместе с тем следует отметить, что несущественность коэффициента регрессии по t-критерию не всегда является надежным основанием для исключения переменной из дальнейшего анализа. Поэтому в ряде случаев для проведения многошагового регрессионного анализа с помощью t-критерия предполагается использовать некоторые дополнительные эмпирические процедуры. Например, исключать переменную из уравнения регрессии лишь в том случае, когда средняя квадратическая ошибка коэффициента регрессии превышает абсолютный размер вычисленного коэффициента, то есть когда tH по абсолютной величине меньше единицы. При этом предполагается, что нет достаточных логических оснований для того, чтобы оставлять такую переменную в модели.
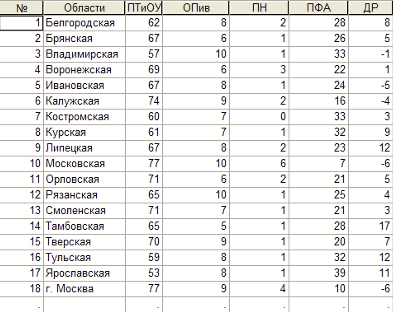
Практическая часть. Вариационные характеристики.Для изучения корреляционного и регрессионного анализа в более подробном разрезе была взята совокупность стран Африки.
Задачей проводимого исследования является выявление и изучение зависимости данных экономических явлений.
При проведении данного исследования была взята совокупность, состоящая из 25 стран Африки:
Алжир, Ангола, Генин, Ботсвана, Бурунди, Буркина Фасо, Габон, Гамбия, Гана, Гвинея, Гвинея-Бисау, Джибути, Египет, Заир, Замбия, Зимбабве, Кабо-Верде, Кения, Коморские острова, Конго, Кот-д’Ивуар, Лесото, Либерия, Ливия.
Характеризующими являются следующие признаки: средняя продолжительность жизни (лет), численность населения (тыс. человек), доля городского населения (%), число медицинских работников на 10 тысяч населения (чел.), доля неграмотных (%), среднегодовой индекс роста производства продовольствия (%).
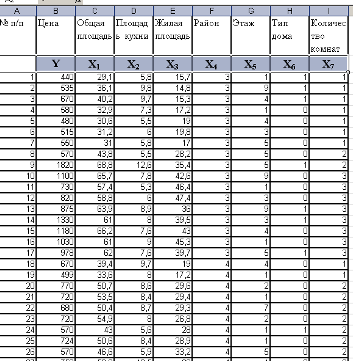
Но для упрощения проведения расчетов и всего исследования, а также выявления связи стоит разделить вышеописанные признаки на факторный и результативные и заменить их условными переменными (у, х1, х2, х3, х4, х5):
результативный признак (у) представляет собой среднюю продолжительность жизни (лет);
факторные признаки (х):
х1: численность населения (тыс. человек);
х2: доля городского населения (%);
х3: число медицинских работников на 10 тысяч населения (чел.);
х4: доля неграмотных (%);
х5: среднегодовой индекс роста производства продовольствия (%).
Начальные данные представлены в таблице:
┌────┬────────┬───────────┬────────┬────────┬────────┬─────────┐
│ N │ y │ x1 │ x2 │ x3 │ x4 │ x5 │
├────┼────────┼───────────┼────────┼────────┼────────┼─────────┤
│ 1 │ 63.00 │ 23102.00 │ 60.85 │ 32.70 │ 55.30 │ 87.00 │
│ 2 │ 44.50 │ 9226.00 │ 21.00 │ 12.70 │ 97.00 │ 58.00 │
│ 3 │ 46.00 │ 4304.00 │ 30.80 │ 7.50 │ 75.20 │ 108.00 │
│ 4 │ 56.50 │ 1169.00 │ 29.50 │ 35.80 │ 59.30 │ 71.00 │
│ 5 │ 48.50 │ 5001.00 │ 2.29 │ 3.80 │ 77.40 │ 101.00 │
│ 6 │ 47.20 │ 8305.00 │ 8.48 │ 8.10 │ 91.20 │ 92.00 │
│ 7 │ 51.00 │ 1058.00 │ 35.80 │ 22.30 │ 87.60 │ 98.00 │
│ 8 │ 37.00 │ 670.00 │ 18.50 │ 15.10 │ 85.20 │ 62.00 │
│ 9 │ 54.00 │ 13704.00 │ 35.86 │ 37.60 │ 69.80 │ 73.00 │
│ 10 │ 42.20 │ 6380.00 │ 19.07 │ 4.20 │ 80.00 │ 91.00 │
│ 11 │ 45.00 │ 925.00 │ 23.80 │ 38.60 │ 71.60 │ 83.00 │
│ 12 │ 64.50 │ 372.00 │ 73.95 │ 72.20 │ 80.00 │ 75.00 │
│ 13 │ 60.60 │ 50740.00 │ 45.37 │ 47.90 │ 56.50 │ 89.00 │
│ 14 │ 52.00 │ 32461.00 │ 39.50 │ 12.60 │ 42.10 │ 86.00 │
│ 15 │ 53.30 │ 7563.00 │ 40.40 │ 18.50 │ 56.00 │ 91.00 │
│ 16 │ 57.80 │ 8640.00 │ 19.60 │ 16.60 │ 29.20 │ 94.00 │
│ 17 │ 53.00 │ 10822.00 │ 34.60 │ 14.40 │ 59.50 │ 102.00 │
│ 18 │ 61.50 │ 348.00 │ 5.80 │ 18.80 │ 63.10 │ 83.00 │
│ 19 │ 53.30 │ 22936.00 │ 14.17 │ 11.20 │ 50.40 │ 93.00 │
│ 20 │ 52.00 │ 472.00 │ 11.53 │ 15.30 │ 41.60 │ 91.00 │
│ 21 │ 48.50 │ 1837.00 │ 37.27 │ 31.70 │ 84.40 │ 83.00 │
│ 22 │ 52.30 │ 11142.00 │ 37.62 │ 13.50 │ 58.80 │ 102.00 │
│ 23 │ 50.60 │ 1619.00 │ 4.52 │ 0.50 │ 48.00 │ 78.00 │
│ 24 │ 51.00 │ 2349.00 │ 32.94 │ 11.30 │ 74.60 │ 91.00 │
│ 25 │ 60.80 │ 4083.00 │ 52.40 │ 64.80 │ 49.90 │ 151.00 │
└────┴────────┴───────────┴────────┴────────┴────────┴─────────┘
Реализация алгоритма многомерного регрессионного анализа начинается с расчета важнейших статистических характеристик исходной информации и матрицы выборочных парных коэффициентов корреляции.
Рассмотрим более подробно вариационные характеристики переменной у:
. число наблюдений 25
. среднее значение 52.2440
. верхняя оценка среднего 54.5134
. нижняя оценка среднего 49.9746
. среднеквадратическое отклонение 6.6138
. дисперсия 43.7425
. дисперсия (несмещ. оценка) 45.5651
. среднекв. откл. (несмещ. оценка) 6.7502
. среднее линейное отклонение 5.0938
. моменты начальные
. 2-го поpядка 2773.1780
. 3-го поpядка 1.4943e+05
. 4-го поpядка 8.1668e+06
. моменты центpальные
. 3-го поpядка -2.1613e+01
. 4-го поpядка 5.1166e+03
. коэффициент асимметрии
. значение -0.0747
. несмещенная оценка -0.0796
. среднекв. отклонение 0.4637
. коэффициент эксцесса
. значение -0.0000
. несмещенная оценка 0.2846
. среднекв. отклонение 0.9017
. коэффициенты вариации
. по pазмаху 0.5264
. сpеднему линейному откл. 0.0975
. сpеднеквадp. откл. 0.1266
. медиана 52.0000
. мода 48.5000
. минимальное значение 37.0000
. максимальное значение 64.5000
. размах 27.5000
Проанализируем их.
Средняя продолжительность жизни в странах Африки – 52,244 года. Она вычисляется по формуле средней арифметической невзвешенной:
_
у = Σуi/n
где n – объем исследуемой совокупности.
Дисперсия в нашем случае равна 43,7425. Она представляет собой средний квадрат отклонений индивидуальных значений признака от их средней величины и вычисляется по формуле:
_
σ2 = Σ (у I – у )2 / n
Среднее квадратическое отклонение представляет собой корень второй степени из дисперсии, и в нашем случае σ = 6,6138, то есть значение продолжительности жизни в среднем отклоняется на 6,6138 лет.
А среднее линейное отклонение вычисляется по формуле:
_ _
d = Σ |уi -y| / n,
которое в нашем случае равно 5,0938 и представляет собой среднюю величину из отклонений вариантов признака от их средней.
Коэффициент вариации среднеквадратического отклонения в исследуемой нами совокупности равен Vσ = 0,1266 или 12,66%, который вычисляется по формуле:
_
Vσ = σ / у * 100%.
Коэффициент вариации характеризует не только сравнительную оценку вариации, но и дает характеристику однородности совокупности. Совокупность считается однородной, если коэффициент вариации не превышает 33%, то есть наша совокупность является однородной.
Мода – значение признака, наиболее часто встречающегося в совокупности. Она рассчитывается по формуле:
Мо = уМо + iМо * (fМо – fМо-1)/(fМо – fМо-1)*(fМо – fМо+1)
То есть по Африке наиболее часто встречающееся значение продолжительности жизни равно 48,5 лет.
Медиана – значение признака, приходящегося на середину ранжированной (упорядоченной) совокупности.
Ме = уМе + iМе * (0,5 Σf – SМе-1)/fМе.
Таким образом, в нашем случае в половине стран Африки население имеет среднюю продолжительность жизни менее 52 лет, а в другой половине – более 52 лет.
Начальным моментом порядка k случайной величины х называют математическое ожидание величины хк:
νк = М (хк),
в частности ν1 = М (х), ν2 = М (х2).
В нашем случае
начальные моменты равны:
. 2-го поpядка 2773.1780
. 3-го поpядка 1.4943e+05
. 4-го поpядка 8.1668e+06
Центральным моментом порядка k случайной величины х называют математическое ожидание величины (х – (М (х))к, в частности
μ1 = М[х – М (х)] = 0; μ2 = М[ ( х – М (х))2] = D (х).
В нашем случае центральные моменты равны:
. 3-го поpядка -2.1613e+01
. 4-го поpядка 5.1166e+03
Теперь рассмотрим нашу совокупность на предмет симметрии.
Симметричным называется распределение, в котором частоты любых двух вариантов, равностоящих в обе стороны от центра распределения, равны между собой. В статистике для характеристики асимметрии используют показатели асимметрии и эксцесса.
Так как видно, что наша совокупность асимметричная, найдем степень асимметрии. Сперва используем коэффициент асимметрии:
_
Аs = (у – Мо)/ σ = 0,4637,
что свидетельствует о наличии незначительной правосторонней асимметрии (Аs>0).
Теперь рассчитаем показатель эксцесса:
ЕК = μ4/ σ4 – 3, где μ4 – центральный момент четвертого порядка.
ЕК = 0,9017, следовательно, распределение стран Африки по продолжительности жизни является островершинным (ЕК>0).
Кроме того, взглянув на нашу совокупность, можно увидеть, что максимальная продолжительность жизни жителей стран Африки равна уmax=64,5 лет, а минимальная у min=37 лет.
Размах данной совокупности равен уmax - у min = 27,5 лет.
Многошаговый регрессионный анализ.Построим корреляционную модель из исследуемых шести переменных:![]() y,
y,![]() ,
, ![]() ,
,![]() ,
,![]() ,
,![]() .
.
Присвоим для облегчения обозначений всем переменным порядковые номера: у-1, х1-2, х2-3, x3-4,x4-5,x5-6.
Предварительно, с целью анализа взаимосвязи показателей построена таблица парных коэффициентов корреляции R.
┌─────┬───────┬───────┬───────┬───────┬───────┬───────┐
│ │ y │ x1 │ x2 │ x3 │ x4 │ x5 │
├─────┼───────┼───────┼───────┼───────┼───────┼───────┤
│ y │ 1.00 │ 0.30 │ 0.53 │ 0.60 │ -0.51 │ 0.26 │
│ x1 │ 0.30 │ 1.00 │ 0.27 │ 0.10 │ -0.33 │ 0.02 │
│ x2 │ 0.53 │ 0.27 │ 1.00 │ 0.74 │ -0.04 │ 0.17 │
│ x3 │ 0.60 │ 0.10 │ 0.74 │ 1.00 │ -0.03 │ 0.15 │
│ x4 │ -0.51 │ -0.33 │ -0.04 │ -0.03 │ 1.00 │ -0.31 │
│ x5 │ 0.26 │ 0.02 │ 0.17 │ 0.15 │ -0.31 │ 1.00 │
└─────┴───────┴───────┴───────┴───────┴───────┴───────┘
Анализ матрицы парных коэффициентов корреляции показывает, что результативный показатель наиболее тесно связан с показателем x3 – числом медицинских работников на 10 тысяч населения (ryx3=0.60).
Одним из основных препятствий эффективного применения регрессионного анализа, является мультиколлинеарность (наличие сильной корреляции между независимыми переменными, входящими в уравнение регрессии x1,x2,x3,x4,x5). Наиболее распространенный метод выявления коллинеарности основан на анализе парных коэффициентов корреляции. Он состоит в том, что две или несколько переменных признаются коллинеарными (мультиколлинеарными), если парные коэффициенты корреляции больше определенной величины. На практике наиболее часто считают, что два аргумента коллинеарны, если парный коэффициент корреляции между ними по абсолютной величине больше 0,8.
В данном примере ни один парный коэффициент корреляции не превышает величины 0,8, что говорит об отсутствии явления мультиколлинеарности.
Приступим непосредственно к регрессионному анализу.
Построим регрессионную модель по следующим факторам: х1, х2, х3, х4 и х5. Для расчета параметров уравнения регрессии используем стандартную программу многошагового регрессионного анализа с последовательным отсевом факторов.
На первом шаге построения модели в уравнение линейной регрессии вводятся все указанные выше переменные. В результате получена следующая модель:
ŷ= 57.700+0.000*x1+0.056*x2+0.173*x3-0.182*x4+0.007*x5.
Прежде чем осуществлять проверку значимости уравнения регрессии и коэффициентов регрессии, следует убедиться, что выполняется необходимое для этого условие, а именно следует проверить, является ли распределение остатков (т.е. отклонений эмпирических значений зависимой переменной от расчетных) нормальным. Для проверки данного условия используем критерий согласия Пирсона ![]() , рассчитанные значения которого приведены ниже:
, рассчитанные значения которого приведены ниже:
Проверка нормального закона распределения
критерий хи-квадpат
.число степеней свободы 3
.хи-квадpат pасчетное 1.571
веpоятн. хи-квадpат заключение
уpовень теоpетическое о гипотезе
0.900 6.226 не отвеpгается
0.950 7.795 не отвеpгается
0.990 11.387 не отвеpгается
Таким образом, можно сделать вывод, что гипотеза о нормальности распределения остатков не отвергается с доверительной вероятностью 0.95 (![]() =7.795).
=7.795).
Проверка значимости уравнения регрессии показала, что оно значимо на уровне доверительной вероятности 0,95. (см. приложение 3.1)
Уровень множественного коэффициента детерминации (0,625) свидетельствует о том, что воздействием включенных в модель факторов обусловлено 62,5% вариации средней продолжительности жизни в странах Африки.
Далее осуществляется проверка значимости отдельных коэффициентов регрессии на основе t-критерия Стьюдента. Для определения ![]() , используем таблицу распределения Стьюдента:
, используем таблицу распределения Стьюдента: ![]() =2,093 (α=0,05 и ν=n-k-1=25-5-1=19).
=2,093 (α=0,05 и ν=n-k-1=25-5-1=19).
По нижеприведенной таблице (гр.5 t-значения) статистически существенными оказались только два коэффициента регрессии при переменных ![]() и
и ![]() (|t|>
(|t|>![]() ).
).
Оценки коэффициентов линейной регрессии
┌───┬──────────┬───────────┬───────────────┬───────────┬────────┬─────────┐
│ N │ Значение │ Дисперсия │ Средне- │ t - │ Нижняя │ Верхняя │
│ │ │ │ квадатическое │ значение │ оценка │ оценка │
│ │ │ │ отклонение │ │ │ │
├───┼──────────┼───────────┼───────────────┼───────────┼────────┼─────────┤
│![]() │
57.70 │ 59.12 │ 7.69 │ 7.50 │ 44.37 │ 71.03 │
│
57.70 │ 59.12 │ 7.69 │ 7.50 │ 44.37 │ 71.03 │
│![]() │ 0.00 │ 0.00 │ 0.00 │ 0.36 │ -0.00 │
0.00 │
│ 0.00 │ 0.00 │ 0.00 │ 0.36 │ -0.00 │
0.00 │
│![]() │ 0.06 │ 0.01 │ 0.08 │ 0.66 │ -0.09 │
0.20 │
│ 0.06 │ 0.01 │ 0.08 │ 0.66 │ -0.09 │
0.20 │
│![]() │ 0.17 │ 0.01 │ 0.08 │ 2.21 │ 0.04 │
0.31 │
│ 0.17 │ 0.01 │ 0.08 │ 2.21 │ 0.04 │
0.31 │
│![]() │
-0.18 │ 0.00 │ 0.06 │ -2.96 │ -0.29 │ -0.08 │
│
-0.18 │ 0.00 │ 0.06 │ -2.96 │ -0.29 │ -0.08 │
│![]() │ 0.01 │ 0.00 │ 0.06 │ 0.12 │ -0.09 │
0.11 │
│ 0.01 │ 0.00 │ 0.06 │ 0.12 │ -0.09 │
0.11 │
└───┴──────────┴───────────┴───────────────┴───────────┴────────┴─────────┘
Среди незначимых коэффициентов регрессии наименее существенно по значению t-критерия является коэффициент регрессии при переменной ![]() (среднегодовой индекс роста производства продовольствия), t=0.12. Этот фактор и подлежит исключению из модели в первую очередь.
(среднегодовой индекс роста производства продовольствия), t=0.12. Этот фактор и подлежит исключению из модели в первую очередь. ![]()
Исключив указанный фактор, на втором шаге получаем уравнение регрессии следующего вида:
ŷ= 58.478+0.000*x1+0.057*x2+0.173*x3-0.184*x4 .
Величина коэффициента детерминации на этом шаге не изменилась и составляет 0,625, гипотеза о значимости уравнения также не отвергается с вероятностью 0,95 (см. приложение 3.2).
Т.к. значение степеней свободы на каждом этапе построения модели изменяется (в связи с уменьшением числа объясняющих переменных), то ![]() также меняется. Тогда при α=0,05 и
также меняется. Тогда при α=0,05 и
ν=n-k-1=25-4-1=20, ![]() =2,086. Таким образом, значимыми являются коэффициенты регрессии при факторах
=2,086. Таким образом, значимыми являются коэффициенты регрессии при факторах ![]() и
и ![]() , а среди оставшихся незначимых наименьшее значение t-критерия, которое равно 0,35, принадлежит коэффициенту регрессии при переменной
, а среди оставшихся незначимых наименьшее значение t-критерия, которое равно 0,35, принадлежит коэффициенту регрессии при переменной ![]() . Поэтому фактор
. Поэтому фактор ![]() (численность населения) из дальнейшего процесса исключается.
(численность населения) из дальнейшего процесса исключается.
На третьем шаге уравнение регрессии имеет следующий вид:
ŷ= 59.036+0.066*x2+0.168*x3-0.191*x4 .
Воздействием включенных в модель переменных объясняется 62,2% вариации средней продолжительности жизни. Проверка на значимость уравнения регрессии показала, что оно значимо (на уровне значимости α=0,05). На этом шаге ![]() =2,080 (α=0,05 и ν=n-k-1=25-3-1=21), таким образом, статистически существенными оказались все коэффициенты регрессии, кроме коэффициента при объясняющей переменной
=2,080 (α=0,05 и ν=n-k-1=25-3-1=21), таким образом, статистически существенными оказались все коэффициенты регрессии, кроме коэффициента при объясняющей переменной ![]() , который и подлежит исключению по t-критерию из уравнения регрессии (t=0,87).
, который и подлежит исключению по t-критерию из уравнения регрессии (t=0,87).
На последнем шаге регрессионного анализа получено значимое уравнение следующего вида:
Y=59.951+0.215x3-0.192x4.
Все коэффициенты регрессии значимы (см. приложение).
В результате моделирования зависимости средней продолжительности жизни в странах Африки можно сделать следующие выводы.
Уровень множественного коэффициента детерминации 0,609 свидетельствует о том, что 60,9% вариации зависимой переменной объясняется вариацией двух факторов:
x3 - число медицинских работников на 10 тыс. населения,
x4 - доля неграмотных.
Указанный уровень влияния достаточно высок, поэтому можно сделать вывод, что все факторы, оказывающие существенной влияние на среднюю продолжительность жизни, включены в модель, поскольку уровень остаточной вариации составляет 39.1%, объясняется воздействием случайных и неучтенных в модели факторов.
В рассматриваемом уравнении регрессии с изменением каждого фактора на одну единицу собственного измерения (при постоянном значении остальных факторов, вошедших в модель) зависимая переменная изменяется на соответствующий коэффициент регрессии βj отражает среднее приращение функции за счет единичного приращения j-го аргумента, независимое от изменения остальных учтенных в модели аргументов. Интерпретируемый таким образом коэффициент регрессии используется в экономико-статистическом анализе как средняя оценка эффективности влияния j-го аргумента на функцию.
Значение коэффициента регрессии βj зависит от принятых единиц измерения величин у и хj. Если единица измерения хj велика, то увеличение хj на единицу соответствует меньшее изменение среднего значения у, то есть βj мало. Если единица измерения у велика, то соответствующее изменение у выражается большим количеством единиц хj, следовательно, βj велико.
Анализируя полученную модель, можно сказать, что при увеличении числа медицинских работников на 1 человека средняя продолжительность жизни жителей стран Африки повышается в среднем на 0.215 лет; при увеличении доли неграмотных на 1% средняя продолжительность жизни уменьшится на 0.192 лет (обратная зависимость).
Однако с помощью коэффициентов регрессии нельзя сопоставить факторы по степени их влияния на зависимую переменную из-за различия единиц измерения и разной степени колеблемости. Поэтому для устранения таких различий при интерпретации применяется целая система показателей: средние частные коэффициенты эластичности, бета-коэффициенты или коэффициенты регрессии в стандартизированном масштабе и дельта-коэффициенты.
Средний частный коэффициенты эластичности рассчитывается по формуле:
_ _
Эj = bj*xj/ y.
_
В рассматриваемой модели при изменении на 1% числа медицинских работников на 10 тысяч населения и доли неграмотных среди жителей исследуемых стран Африки средняя продолжительность жизни изменяется следующим образом: увеличивается на 0.094% и уменьшается на 0.241% соответственно (частные коэффициенты эластичности). - см. приложение.
Однако средний частный коэффициент эластичности не учитывает степени колеблемости факторов, которая может значительно различаться у отдельных факторов. Поэтому для устранения различий в измерении и степени колеблемости факторов используется другой показатель - коэффициент регрессии в стандартизированном масштабе (бета-коэффициент). Он показывает, на какую часть величины среднего квадратического отклонения изменяется среднее значение зависимой переменной с изменением соответствующей независимой переменной на одно среднее квадратическое отклонение при фиксированном на постоянном уровне значении остальных независимых переменных.
Бета-коэффициенты, рассчитанные для нашей модели, показывают, что при увеличении на одно среднее квадратическое отклонение числа медработников на 10 тысяч населения и доли неграмотных, средняя продолжительность жизни в среднем увеличивается на 0.587 и уменьшается на 0.495 средних квадратических отклонений соответственно. - см. приложение.
С помощью частных коэффициентов эластичности и с помощью бета-коэффициентов можно проранжировать факторы по степени их влияния на зависимую переменную, то есть сопоставить их между собой по величине этого влияния. Но с помощью бета-коэффициентов нельзя непосредственно оценить долю влияния каждого фактора в суммарном влиянии всех факторов. Для этой цели используются дельта-кэффициенты.
В практических задачах при корректно проведенном анализе величины дельта-коэффициентов положительны, то есть все коэффициенты регрессии имеют тот же знак, что и соответствующие парные коэффициенты корреляции. В этих случаях сумма величин вкладов независимых переменных равна коэффициенту множественной детерминации. Вместе с тем, в некоторых исследованиях отдельные коэффициенты регрессии имеют знак, противоположный знаку соответствующего коэффициента парной корреляции, вследствие чего величина дельта-коэффициента будет отрицательной. Не менее важно, что случаи с отрицательными вкладами могут иметь место только при значительной коррелированности объясняющих переменных.
В нашей модели наибольшее влияние на среднюю продолжительность жизни оказывает число медработников на 10 тысяч населения - 58.2%, а доля неграмотных оказывает влияние в размере 41.8%.
В настоящей курсовой работе был рассмотрен один из наиболее популярных в настоящее время методов математико-статистического моделирования экономических процессов, который позволяет строить достаточно адекватные и легко экономически интерпретируемые модели. Но легко заметить, что все вышеприведенные вычисление очень трудоемки и занимают немало времени. Поэтому, кроме вычислений вручную, а также для упрощения исследования, была проведена работа в пакете прикладных программ «ОЛИМП» - совокупность программных средств, ориентированных на решение задач экономического анализа и прогнозирования с помощью различных методов математической статистики. Полученные результаты приведены в Приложении.
Приложение.Просмотр начальных данных
┌────┬────────┬───────────┬────────┬────────┬────────┬─────────┐
│ N │ y │ x1 │ x2 │ x3 │ x4 │ x5 │
├────┼────────┼───────────┼────────┼────────┼────────┼─────────┤
│ 1 │ 63.00 │ 23102.00 │ 60.85 │ 32.70 │ 55.30 │ 87.00 │
│ 2 │ 44.50 │ 9226.00 │ 21.00 │ 12.70 │ 97.00 │ 58.00 │
│ 3 │ 46.00 │ 4304.00 │ 30.80 │ 7.50 │ 75.20 │ 108.00 │
│ 4 │ 56.50 │ 1169.00 │ 29.50 │ 35.80 │ 59.30 │ 71.00 │
│ 5 │ 48.50 │ 5001.00 │ 2.29 │ 3.80 │ 77.40 │ 101.00 │
│ 6 │ 47.20 │ 8305.00 │ 8.48 │ 8.10 │ 91.20 │ 92.00 │
│ 7 │ 51.00 │ 1058.00 │ 35.80 │ 22.30 │ 87.60 │ 98.00 │
│ 8 │ 37.00 │ 670.00 │ 18.50 │ 15.10 │ 85.20 │ 62.00 │
│ 9 │ 54.00 │ 13704.00 │ 35.86 │ 37.60 │ 69.80 │ 73.00 │
│ 10 │ 42.20 │ 6380.00 │ 19.07 │ 4.20 │ 80.00 │ 91.00 │
│ 11 │ 45.00 │ 925.00 │ 23.80 │ 38.60 │ 71.60 │ 83.00 │
│ 12 │ 64.50 │ 372.00 │ 73.95 │ 72.20 │ 80.00 │ 75.00 │
│ 13 │ 60.60 │ 50740.00 │ 45.37 │ 47.90 │ 56.50 │ 89.00 │
│ 14 │ 52.00 │ 32461.00 │ 39.50 │ 12.60 │ 42.10 │ 86.00 │
│ 15 │ 53.30 │ 7563.00 │ 40.40 │ 18.50 │ 56.00 │ 91.00 │
│ 16 │ 57.80 │ 8640.00 │ 19.60 │ 16.60 │ 29.20 │ 94.00 │
│ 17 │ 53.00 │ 10822.00 │ 34.60 │ 14.40 │ 59.50 │ 102.00 │
│ 18 │ 61.50 │ 348.00 │ 5.80 │ 18.80 │ 63.10 │ 83.00 │
│ 19 │ 53.30 │ 22936.00 │ 14.17 │ 11.20 │ 50.40 │ 93.00 │
│ 20 │ 52.00 │ 472.00 │ 11.53 │ 15.30 │ 41.60 │ 91.00 │
│ 21 │ 48.50 │ 1837.00 │ 37.27 │ 31.70 │ 84.40 │ 83.00 │
│ 22 │ 52.30 │ 11142.00 │ 37.62 │ 13.50 │ 58.80 │ 102.00 │
│ 23 │ 50.60 │ 1619.00 │ 4.52 │ 0.50 │ 48.00 │ 78.00 │
│ 24 │ 51.00 │ 2349.00 │ 32.94 │ 11.30 │ 74.60 │ 91.00 │
│ 25 │ 60.80 │ 4083.00 │ 52.40 │ 64.80 │ 49.90 │ 151.00 │
└────┴────────┴───────────┴────────┴────────┴────────┴─────────┘
*** Вариационные характеристики переменной y ***
. число наблюдений 25
. среднее значение 52.2440
. верхняя оценка среднего 54.5134
. нижняя оценка среднего 49.9746
. среднеквадратическое отклонение 6.6138
. дисперсия 43.7425
. дисперсия (несмещ. оценка) 45.5651
. среднекв. откл. (несмещ. оценка) 6.7502
. среднее линейное отклонение 5.0938
. моменты начальные
. 2-го поpядка 2773.1780
. 3-го поpядка 1.4943e+05
. 4-го поpядка 8.1668e+06
. моменты центpальные
. 3-го поpядка -2.1613e+01
. 4-го поpядка 5.1166e+03
. коэффициент асимметрии
. значение -0.0747
. несмещенная оценка -0.0796
. среднекв. отклонение 0.4637
. коэффициент эксцесса
. значение -0.0000
. несмещенная оценка 0.2846
. среднекв. отклонение 0.9017
. коэффициенты вариации
. по pазмаху 0.5264
. сpеднему линейному откл. 0.0975
. сpеднеквадp. откл. 0.1266
. медиана 52.0000
. мода 48.5000
. минимальное значение 37.0000
. максимальное значение 64.5000
. размах 27.5000
**** Характеристики интеpвального pяда *****
. среднее значение 52.4000
. среднеквадратическое отклонение 6.5949
. дисперсия 43.4928
. коэффициент асимметpии -0.0815
. коэффициент эксцесса -0.2092
. медиана 51.5139
. мода 50.7500
N инт. Начало Сеpедина Конец Частота Частость
1 34.7083 37.0000 39.2917 1.0 0.0400
2 39.2917 41.5833 43.8750 1.0 0.0400
3 43.8750 46.1667 48.4583 4.0 0.1600
4 48.4583 50.7500 53.0417 9.0 0.3600
5 53.0417 55.3333 57.6250 4.0 0.1600
6 57.6250 59.9167 62.2083 4.0 0.1600
7 62.2083 64.5000 66.7917 2.0 0.0800
Пpовеpка ноpмального закона pаспpеделения
Кpитеpий хи-квадpат
.число степеней свободы 3
.хи-квадpат pасчетное 1.571
веpоятн. хи-квадpат заключение
уpовень теоpетическое о гипотезе
0.900 6.226 не отвеpгается
0.950 7.795 не отвеpгается
0.990 11.387 не отвеpгается
222222222222222 ОТЧЕТ 2222222222222222222222222222222222
0,990 11,387 не отвергается
или
не отвергается с вероятностью 0,950
32
Матpица
┌─────┬───────┬───────┬───────┬───────┬───────┬───────┐
│ N │ 1 │ 2 │ 3 │ 4 │ 5 │ 6 │
├─────┼───────┼───────┼───────┼───────┼───────┼───────┤
│ y │ 1.00 │ 0.30 │ 0.53 │ 0.60 │ -0.51 │ 0.26 │
│ x1 │ 0.30 │ 1.00 │ 0.27 │ 0.10 │ -0.33 │ 0.02 │
│ x2 │ 0.53 │ 0.27 │ 1.00 │ 0.74 │ -0.04 │ 0.17 │
│ x3 │ 0.60 │ 0.10 │ 0.74 │ 1.00 │ -0.03 │ 0.15 │
│ x4 │ -0.51 │ -0.33 │ -0.04 │ -0.03 │ 1.00 │ -0.31 │
│ x5 │ 0.26 │ 0.02 │ 0.17 │ 0.15 │ -0.31 │ 1.00 │
└─────┴───────┴───────┴───────┴───────┴───────┴───────┘
Похожие работы
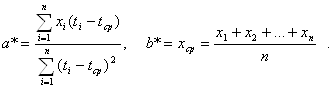
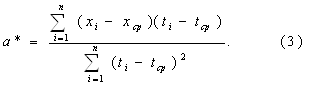

... исходить из вида обрабатываемых данных. В соответствии с современными воззрениями делим эконометрику и прикладную статистику на четыре области: - статистика случайных величин (одномерная статистика); - многомерный статистический анализ; - статистика временных рядов и случайных величин; - статистика объектов нечисловой природы. В первой области элемент выборки - число, во второй - вектор, в ...

... . При этом анализироваться могут как объекты (как точки, задаваемые в признаковом пространстве), так и признаки (как точки, задаваемые в объектном пространстве). Прикладное значение многомерного статистического анализа состоит в основном в решении следующих трех задач: · задача статистического исследования зависимостей между рассматриваемыми показателями; · задача классификации элементов ( ...
Использование корреляционно-регрессионного анализа для обработки экономических статистических данных
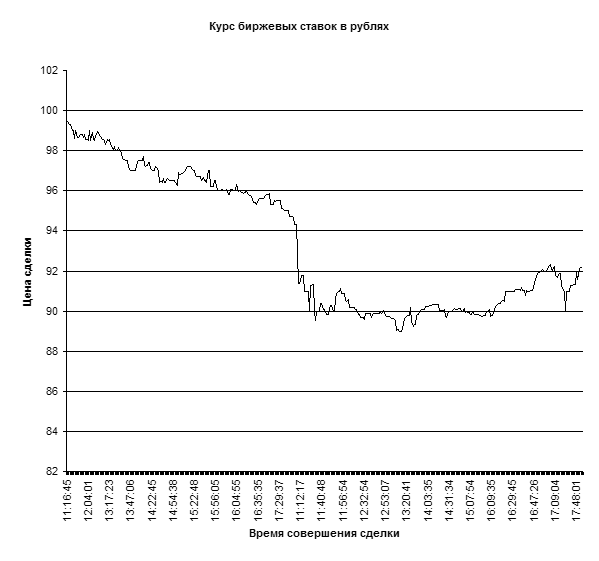
... быстро выполняемой счетной операцией. Данная работа посвящена изучению возможности обработки статистических данных биржевых ставок методами корреляционного и регрессионного анализа с использованием пакета прикладных программ Microsoft Excel. Роль корреляцонно-регрессионного анализа в обработке экономических данных Корреляционный анализ и регрессионный анализ являются смежными разделами ...
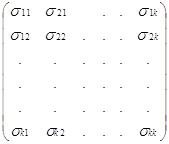

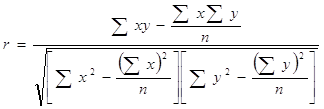
... ŷ = a0 + a1x , где ŷ - теоретические значения результативного признака, полученные по уравнению регрессии; a0 , a1 - коэффициенты (параметры) уравнения регрессии. Задача регрессионного анализа состоит в построении модели, позволяющей по значениям независимых показателей получать оценки значений зависимой переменной. Регрессионный анализ является основным средством исследования ...
0 комментариев