Производительность. СУБД должна выполнять свои функции с максимальной производительностью
Заголовок содержит фиксированное множество атрибутов или, точнее, пар <имя‑атрибута : имя‑домена>:
На практике большинство отношений имеют только один потенциальный ключ, хотя в общем случае их может быть несколько
Если каждое из них имеет одно и то же множество имен атрибутов (следовательно, заметьте, они заведомо должны иметь одну и ту же степень);
Следует заметить, что речь здесь пойдет о логическом, а не физическом макете
Правая часть (зависимая часть) каждой ФЗ множества S содержит только один атрибут (т.е. является одноэлементным множеством)
Диаграммы ER-экзрмпляров
Степени связи между сущностями (1:1, 1:М, М:1, М:М);
Булевы данные. Некоторые СУБД явным образом поддерживают логические значения (TRUE или FALSE)
Константа, показывающая, что в каждой строке результатов запроса должно содержаться одно и то же значение
Пользователь имеет доступ к объекту, только если его уровень допуска больше или равен уровню классификации объекта
ALTER – позволяет модифицировать структуру таблиц (DB2, Oracle);
Далее этот процесс следует повторить для вставки среднего значения W в родительский элемент Р на более высоком структурном уровне
В последовательности проекций данного отношения можно игнорировать все проекции, кроме последней. Таким образом, выражение
Долговечность. Когда транзакция выполнена, ее обновления сохраняются, даже если в следующий момент произойдет сбой системы
Транзакция, предназначенная для извлечения кортежа, прежде всего должна наложить S‑блокировку на этот кортеж
Перед выполнением каких-либо операций с некоторым объектом (например, с кортежем базы данных) транзакция должна заблокировать этот кортеж
Несколько клиентов могут использовать один и тот же сервер (действительно, это довольно обычная ситуация)
Навигация
Производительность. СУБД должна выполнять свои функции с максимальной производительностью
Организация баз данных
362757
знаков
48
таблиц
34
изображения
6. Производительность. СУБД должна выполнять свои функции с максимальной производительностью.
1.6 Экспертные системы и базы знанийВ последнее время появилась необходимость хранения и использования слабоструктурированных данных, каковыми являются, например, человеческие знания в экспертных системах.
Экспертная система – система искусственного интеллекта, включающая знания об определенной слабо структурированной и трудно формализуемой узкой предметной области и способная предлагать и объяснять пользователю разумные решения. Экспертная система состоит из базы знаний, механизма логического вывода и подсистемы объяснений.
База знаний – семантическая модель, описывающая предметную область и позволяющая отвечать на такие вопросы из этой предметной области, ответы на которые в явном виде не присутствуют в базе. База знаний является основным компонентом интеллектуальных и экспертных систем.
Для хранения баз знаний в современных экспертных системах используются либо промышленные СУБД и специализированное промежуточное ПО, либо специализированное ПО.
В настоящем курсе основное внимание уделяется проектированию БД и организации хранения в них структурированной информации. Проектирование и создание баз знаний будет подробно рассматриваться в других курсах, связанных с изучением интеллектуальных систем.
Литература:
1. Дейт К.Дж. Введение в системы баз данных. –Пер. с англ. –6-е изд. –К. Диалектика, 1998. Стр. 36–75.
ЛЕКЦИЯ 2. Модели БД2.1 Обзор ранних (дореляционных) СУБД
2.2 Системы, основанные на инвертированных списках
2.3 Иерархическая модель
2.4 Сетевая модель
2.5 Основные достоинства и недостатки ранних СУБД
2.1 Обзор ранних (дореляционных) СУБД
Рассмотрим системы, исторически предшествовавшие реляционным, что необходимо для правильного понимания причин повсеместного перехода к реляционным системам. Кроме того, внутренняя организация реляционных систем во многом основана на использовании методов ранних систем. И, наконец, некоторое знание в области ранних систем будет полезно для понимания путей развития постреляционных СУБД.
Ограничимся рассмотрением только общих подходов к организации трех типов ранних систем, а именно, систем, основанных на инвертированных списках, иерархических и сетевых систем управления базами данных. Не будем касаться особенностей каких-либо конкретных систем, поскольку это привело бы к изложению многих технических деталей. Детали можно найти в соответствующей литературе.
Рассмотрим некоторые наиболее общие характеристики ранних систем:
1. Эти системы активно использовались в течение многих лет, дольше, чем используется многие из реляционных СУБД. На самом деле некоторые из ранних систем используются даже в наше время, накоплены громадные базы данных, и одной из актуальных проблем информационных систем является использование этих систем совместно с современными системами.
2. Все ранние системы не основывались на каких-либо абстрактных моделях. Понятие модели данных фактически вошло в обиход специалистов в области БД только вместе с реляционным подходом. Абстрактные представления ранних систем появились позже на основе анализа и выявления общих признаков у различных конкретных систем.
3. В ранних системах доступ к БД производился на уровне записей. Пользователи этих систем осуществляли явную навигацию в БД, используя языки программирования, расширенные функциями СУБД. Интерактивный доступ к БД поддерживался только путем создания соответствующих прикладных программ с собственным интерфейсом.
4. Навигационная природа ранних систем и доступ к данным на уровне записей заставляли пользователя самого производить всю оптимизацию доступа к БД, без какой-либо поддержки системы.
5. После появления реляционных систем большинство ранних систем было оснащено "реляционными" интерфейсами. Однако в большинстве случаев это не сделало их по‑настоящему реляционными системами, поскольку оставалась возможность манипулировать данными в естественном для них режиме.
2.2 Системы, основанные на инвертированных спискахК числу наиболее известных и типичных представителей таких систем относятся Datacom/DB компании Applied Data Research, Inc. (ADR), ориентированная на использование на машинах основного класса фирмы IBM, и Adabas компании Software AG.
Организация доступа к данным на основе инвертированных списков используется практически во всех современных реляционных СУБД, но в этих системах пользователи не имеют непосредственного доступа к инвертированным спискам (индексам).
2.2.1 Структуры данныхВ базе данных, организованной с помощью инвертированных списков хранимые таблицы и пути доступа к ним видны пользователям. При этом:
1. Строки таблиц упорядочены системой в некоторой физической последовательности.
2. Физическая упорядоченность строк всех таблиц может определяться и для всей БД (так делается, например, в Datacom/DB).
3. Для каждой таблицы можно определить произвольное число ключей поиска, для которых строятся индексы. Эти индексы автоматически поддерживаются системой, но явно видны пользователям.
2.2.2 Манипулирование даннымиПоддерживаются два класса операторов:
1. Операторы, устанавливающие адрес записи, среди которых:
1.1. прямые поисковые операторы (например, найти первую запись таблицы по некоторому пути доступа);
1.2. операторы, находящие запись в терминах относительной позиции от предыдущей записи по некоторому пути доступа.
2. Операторы над адресуемыми записями
Типичный набор операторов:
1. Найти первую запись таблицы T в физическом порядке;
2. Найти первую запись таблицы T с заданным значением ключа поиска K;
3. Найти запись, следующую за записью с заданным адресом в заданном пути доступа;
4. Найти следующую запись таблицы T в порядке пути поиска с заданным значением K;
5. Найти первую запись таблицы T в порядке ключа поиска K cо значением ключевого поля, большим заданного значения K;
6. Выбрать запись с указанным адресом;
7. Обновить запись с указанным адресом;
8. Удалить запись с указанным адресом;
9. Включить запись в указанную таблицу; операция генерирует адрес записи.
2.2.3 Ограничения целостностиОбщие правила определения целостности БД отсутствуют. В некоторых системах поддерживаются ограничения уникальности значений некоторых полей, но в основном все возлагается на прикладную программу.
2.3 Иерархическая модельТипичным представителем (наиболее известным и распространенным) является Information Management System (IMS) фирмы IBM. Первая версия появилась в 1968 г. До сих пор поддерживается много баз данных, что создает существенные проблемы с переходом как на новую технологию БД, так и на новую технику.
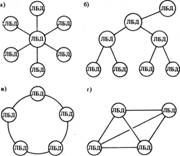
2.3.1 Иерархические структуры данныхИерархическая БД состоит из упорядоченного набора деревьев; более точно, из упорядоченного набора нескольких экземпляров одного типа дерева.
Тип дерева (рис. 2.1) состоит из одного "корневого" типа записи и упорядоченного набора из нуля или более типов поддеревьев (каждое из которых является некоторым типом дерева). Тип дерева в целом представляет собой иерархически организованный набор типов записи.
рис. 2.1 Пример типа дерева (схемы иерархической БД)
Пример типа дерева (схемы иерархической БД)
Здесь (рис. 2.1) Группа является предком для Куратора и Студенты, а Куратор и Студенты – потомки Группа. Между типами записи поддерживаются связи.
База данных с такой схемой могла бы выглядеть следующим образом (рис. 2.2):
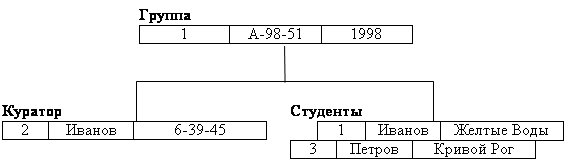 рис. 2.2 Один экземпляр дерева.
рис. 2.2 Один экземпляр дерева.
Все экземпляры данного типа потомка с общим экземпляром типа предка называются близнецами. Для БД определен полный порядок обхода – сверху-вниз, слева-направо.
В IMS использовалась оригинальная и нестандартная терминология: "сегмент" вместо "запись", а под "записью БД" понималось все дерево сегментов.
2.3.2 Манипулирование даннымиПримерами типичных операторов манипулирования иерархически организованными данными могут быть следующие:
1. Найти указанное дерево БД (например, отдел 310);
2. Перейти от одного дерева к другому;
3. Перейти от одной записи к другой внутри дерева (например, от отдела - к первому сотруднику);
4. Перейти от одной записи к другой в порядке обхода иерархии;
5. Вставить новую запись в указанную позицию;
6. Удалить текущую запись.
2.3.3 Ограничения целостностиАвтоматически поддерживается целостность ссылок между предками и потомками. Основное правило: никакой потомок не может существовать без своего родителя. Заметим, что аналогичное поддержание целостности по ссылкам между записями, не входящими в одну иерархию, не поддерживается (примером такой "внешней" ссылки может быть содержимое поля Каф_Номер в экземпляре типа записи Куратор).
В иерархических системах поддерживалась некоторая форма представлений БД на основе ограничения иерархии. Примером представления приведенной выше БД может быть иерархия, изображенная на рис. 2.3.
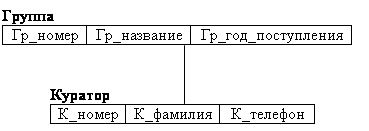 рис. 2.3 Пример представления иерархической БД.
рис. 2.3 Пример представления иерархической БД.
Типичным представителем является Integrated Database Management System (IDMS) компании Cullinet Software, Inc., предназначенная для использования на машинах основного класса фирмы IBM под управлением большинства операционных систем. Архитектура системы основана на предложениях Data Base Task Group (DBTG) Комитета по языкам программирования Conference on Data Systems Languages (CODASYL), организации, ответственной за определение языка программирования Кобол. Отчет DBTG был опубликован в 1971г., а в 70-х годах появилось несколько систем, среди которых IDMS.
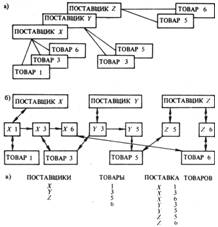
2.4.1 Сетевые структуры данныхСетевой подход к организации данных является расширением иерархического. В иерархических структурах запись-потомок должна иметь в точности одного предка; в сетевой структуре данных потомок может иметь любое число предков.
Сетевая БД состоит из набора экземпляров каждого типа записи и набора экземпляров каждого типа связи (рис. 2.4).
Тип связи определяется для двух типов записи: предка и потомка. Экземпляр типа связи состоит из одного экземпляра типа записи предка и упорядоченного набора экземпляров типа записи потомка. Для данного типа связи L с типом записи предка P и типом записи потомка C должны выполняться следующие два условия:
1. Каждый экземпляр типа P является предком только в одном экземпляре L;
2. Каждый экземпляр C является потомком не более, чем в одном экземпляре L.
На формирование типов связи не накладываются особые ограничения; возможны, например, следующие ситуации:
1. Тип записи потомка в одном типе связи L1 может быть типом записи предка в другом типе связи L2 (как в иерархии).
2. Данный тип записи P может быть типом записи предка в любом числе типов связи.
3. Данный тип записи P может быть типом записи потомка в любом числе типов связи.
4. Может существовать любое число типов связи с одним и тем же типом записи предка и одним и тем же типом записи потомка; и если L1 и L2 – два типа связи с одним и тем же типом записи предка P и одним и тем же типом записи потомка C, то правила, по которым образуется родство, в разных связях могут различаться.
5. Типы записи X и Y могут быть предком и потомком в одной связи и потомком и предком – в другой.
6. Предок и потомок могут быть одного типа записи.
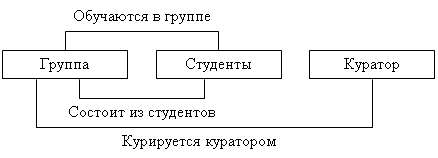 рис. 2.4 Простой пример сетевой схемы БД.
рис. 2.4 Простой пример сетевой схемы БД.
Примерный набор операций может быть следующим:
1. Найти конкретную запись в наборе однотипных записей (инженера Сидорова);
2. Перейти от предка к первому потомку по некоторой связи (к первому сотруднику отдела 310);
3. Перейти к следующему потомку в некоторой связи (от Сидорова к Иванову);
4. Перейти от потомка к предку по некоторой связи (найти отдел Сидорова);
5. Создать новую запись;
6. Уничтожить запись;
7. Модифицировать запись;
8. Включить в связь;
9. Исключить из связи;
10. Переставить в другую связь и т.д.
2.4.3 Ограничения целостностиВ принципе их поддержание не требуется, но иногда требуется целостности по ссылкам (как в иерархической модели).
2.5 Основные достоинства и недостатки ранних СУБДСильные места ранних СУБД:
1. Развитые средства управления данными во внешней памяти на низком уровне;
2. Возможность построения вручную эффективных прикладных систем;
3. Возможность экономии памяти за счет разделения подобъектов (в сетевых системах).
Недостатки:
1. Слишком сложно пользоваться;
2. Фактически необходимы знания о физической организации;
3. Прикладные системы зависят от этой организации;
4. Их логика перегружена деталями организации доступа к БД.
Литература:
1. Сергей Кузнецов, “Основы современных баз данных”. Центр Информационных Технологий, http://www.citforum.ru/database/osbd/contents.shtml
ЛЕКЦИЯ 3. Реляционная модель и ее характеристики. Целостность в реляционной модели3.1 Представление информации в реляционных БД
3.2 Домены
3.3 Отношения. Свойства и виды отношений
3.4 Целостность реляционных данных
3.5 Потенциальные и первичные ключи
3.6 Внешние ключи
3.7 Ссылочная целостность
3.8 Значения NULL и поддержка ссылочной целостности
3.1 Представление информации в реляционных БД
Реляционный подход является наиболее распространенным в настоящее время, хотя наряду с общепризнанными достоинствами обладает и рядом недостатков. К числу достоинств реляционного подхода можно отнести:
1. наличие небольшого набора абстракций, которые позволяют сравнительно просто моделировать большую часть распространенных предметных областей и допускают точные формальные определения, оставаясь интуитивно понятными;
2. наличие простого и в то же время мощного математического аппарата, опирающегося главным образом на теорию множеств и математическую логику и обеспечивающего теоретический базис реляционного подхода к организации баз данных;
3. возможность ненавигационного манипулирования данными без необходимости знания конкретной физической организации баз данных во внешней памяти.
Однако реляционные системы далеко не сразу получили широкое распространение. В то время, как основные теоретические результаты в этой области были получены еще в 70-х, и тогда же появились первые прототипы реляционных СУБД, долгое время считалось невозможным добиться эффективной реализации таких систем. Однако отмеченные выше преимущества и постепенное накопление методов и алгоритмов организации реляционных баз данных и управления ими привели к тому, что уже в середине 80-х годов реляционные системы практически вытеснили с мирового рынка ранние СУБД.
В настоящее время основным предметом критики реляционных СУБД является не их недостаточная эффективность, а следующие недостатки:
1. присущая этим системам некоторая ограниченность (прямое следствие простоты) при использовании в так называемых нетрадиционных областях (наиболее распространенными примерами являются системы автоматизации проектирования), в которых требуются предельно сложные структуры данных.
2. невозможность адекватного отражения семантики предметной области. Другими словами, возможности представления знаний о семантической специфике предметной области в реляционных системах очень ограничены. Современные исследования в области постреляционных систем главным образом посвящены именно устранению этих недостатков.
В реляционной модели рассматриваются три аспекта данных:
1. структура данных (объекты данных);
2. целостность данных;
3. обработка данных (операторы).
Рассмотрим специальную терминологию, применяемую в рамках аспекта "структура данных" (рис. 3.1).
 рис. 3.1 Отношение.
рис. 3.1 Отношение.
Домен является наименьшей семантической единицей данных, которая предполагается отдельным значением данных (таким как номер студента, фамилия студента и т.д.). Такие значения называют скалярами. Скалярные значения представляют собой наименьшую семантическую единицу данных в том смысле, что они являются атомарными: в реляционной модели у них отсутствует внутренняя структура. Следует обратить внимание, что отсутствие внутренней структуры при рассмотрении в реляционной модели вовсе не значит, что внутренняя структура отсутствует вообще. Например, название города имеет внутреннюю структуру (оно состоит из последовательности букв) однако, разложив название по буквам мы потеряем значение. Значение станет понятным лишь в том случае, если буквы сложены вместе и в правильной последовательности.
Таким образом, домен – именованное множество скалярных значений одного типа. Например, домен городов это множество всех возможных названий городов. Домены являются общими совокупностями значений из которых берутся реальные значения атрибутов.
Следует обратить внимание, что обычно в любой момент времени в домене будут значения, не являющиеся значением ни одного из атрибутов, соответствующих этому домену.
Основное значение доменов в том, что домены ограничивают сравнения. Сравнение будет иметь смысл для атрибутов, основанных на одном и том же домене. Например, можно сравнивать числовой код студента и оценку, полученную студентом на экзамене - и то и другое - целые числа, однако такое сравнение будет лишено смысла.
Домены, прежде всего, имеют концептуальную природу. Они могут быть или не быть явно сохранены в базе данных как реальные наборы значений (фактически, в большинстве случаев они не сохраняются), но они должны быть, по крайней мере, определены в рамках определений базы данных. Тогда каждое определение атрибута должно включать ссылку на соответствующий домен, таким образом, системе будет известно, какие атрибуты можно сравнивать, а какие - нет.
3.3 Отношения. Свойства и виды отношенийВокруг понятия "отношение" сложилась некоторая двусмысленность из-за отсутствия четкого разграничения между переменными отношений и значениями отношений. Переменная отношения – это обычная переменная, такая же, как и в языках программирования, т.е. именованный объект, значение которого может изменяться со временем. А значение этой переменной в любой момент будет значением отношения.
Отношение R, определенное на множестве доменов D1, D2, …, Dn (не обязательно различных), содержит две части – заголовок и тело:
Похожие работы
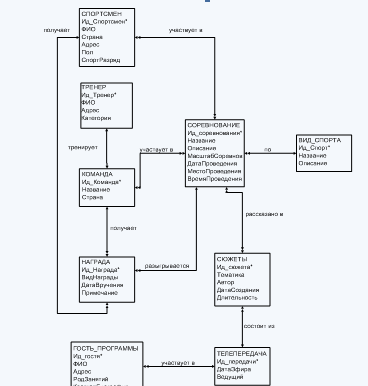
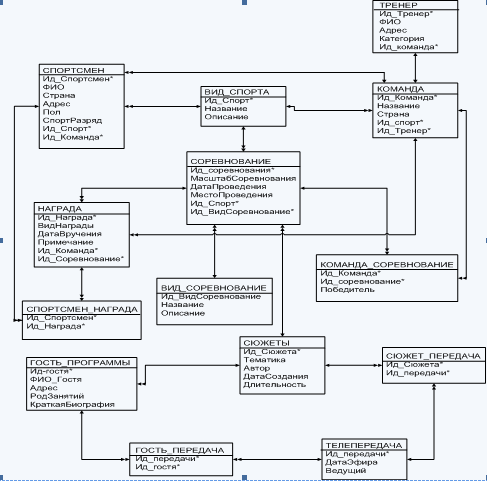
... для предметной области «Спортивная программа» показана на рис.1 Рис.1 – КМД для предметной области «Спортивная программа» Двойная стрелка означает «многие», одинарная стрелка означает «один» во взаимосвязи между объектами. Ключевые атрибуты обозначены *. Описание реляционной модели данных Реляционная модель данных (РМД) представляет БД в виде множества взаимосвязанных отношений, в том ...
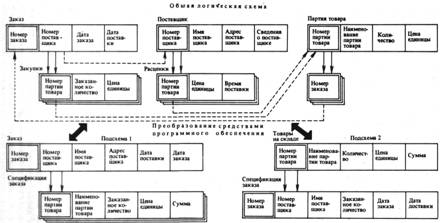
... и прикладных программ (логическая независимость данных) и возможность изменения физического расположения и организации данных без изменения общей логической структуры данных и структур данных прикладных программистов (физическая независимость). Рис. 1 2. Системы управления базами данных Использование систем управления базами данных (СУБД) позволяет исключить из прикладных программ ...
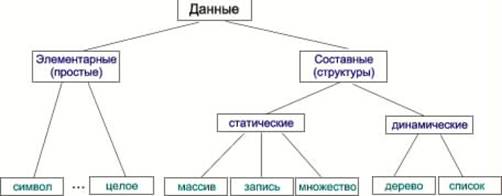
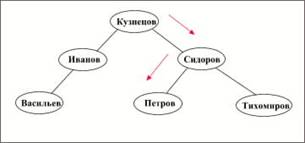
... (в виде связей). В последнее время все большее значение приобретает объектно-ориентированный подход к представлению данных. Физическая организация баз данных Физическая организация данных определяет собой способ непосредственного размещения данных на машинном носителе. В современных прикладных программных средствах этот уровень организации обеспечивается автоматически без вмешательства ...
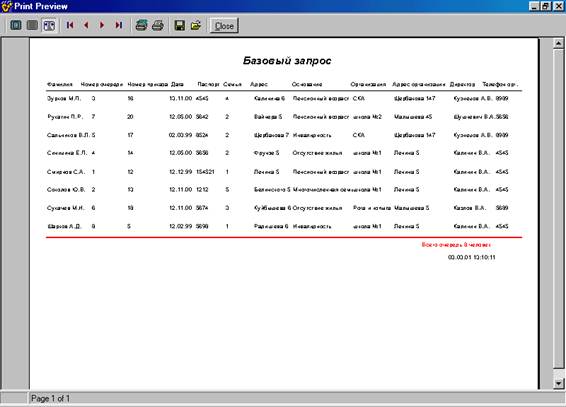
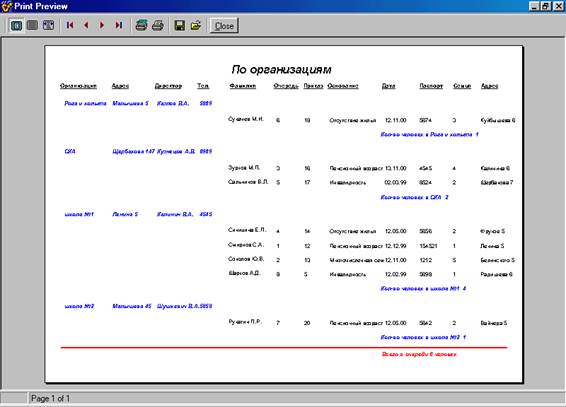
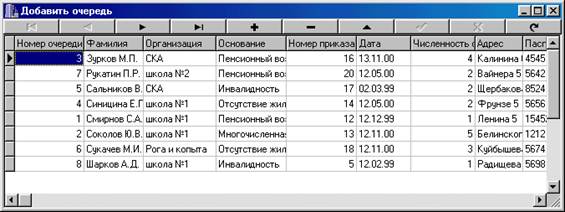
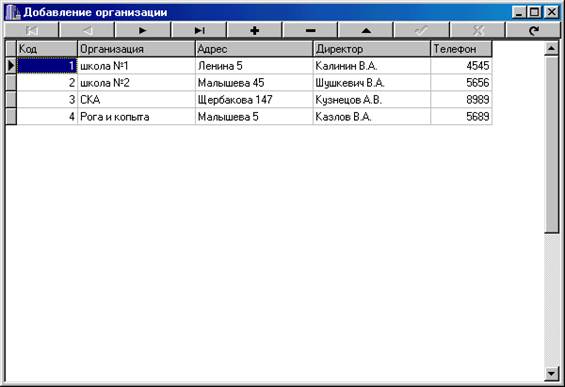
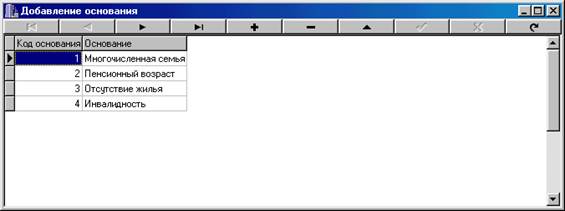
... отчет. Базовый отчет: Отчет по организациям: Программа предназначена для учёта очереди по организациям, а также для предоставления оперативной информации о очереди. К входящей информации относятся: номер очереди, фамилия, организация, основание, номер приказа, дата, численность семьи, адрес , паспорт. Т. е файл: Также Справочник 1 и 2: К выходящей информации в отчёте ...
0 комментариев