Производительность. СУБД должна выполнять свои функции с максимальной производительностью
Заголовок содержит фиксированное множество атрибутов или, точнее, пар <имя‑атрибута : имя‑домена>:
На практике большинство отношений имеют только один потенциальный ключ, хотя в общем случае их может быть несколько
Если каждое из них имеет одно и то же множество имен атрибутов (следовательно, заметьте, они заведомо должны иметь одну и ту же степень);
Следует заметить, что речь здесь пойдет о логическом, а не физическом макете
Правая часть (зависимая часть) каждой ФЗ множества S содержит только один атрибут (т.е. является одноэлементным множеством)
Диаграммы ER-экзрмпляров
Степени связи между сущностями (1:1, 1:М, М:1, М:М);
Булевы данные. Некоторые СУБД явным образом поддерживают логические значения (TRUE или FALSE)
Константа, показывающая, что в каждой строке результатов запроса должно содержаться одно и то же значение
Пользователь имеет доступ к объекту, только если его уровень допуска больше или равен уровню классификации объекта
ALTER – позволяет модифицировать структуру таблиц (DB2, Oracle);
Далее этот процесс следует повторить для вставки среднего значения W в родительский элемент Р на более высоком структурном уровне
В последовательности проекций данного отношения можно игнорировать все проекции, кроме последней. Таким образом, выражение
Долговечность. Когда транзакция выполнена, ее обновления сохраняются, даже если в следующий момент произойдет сбой системы
Транзакция, предназначенная для извлечения кортежа, прежде всего должна наложить S‑блокировку на этот кортеж
Перед выполнением каких-либо операций с некоторым объектом (например, с кортежем базы данных) транзакция должна заблокировать этот кортеж
Несколько клиентов могут использовать один и тот же сервер (действительно, это довольно обычная ситуация)
Навигация
Далее этот процесс следует повторить для вставки среднего значения W в родительский элемент Р на более высоком структурном уровне
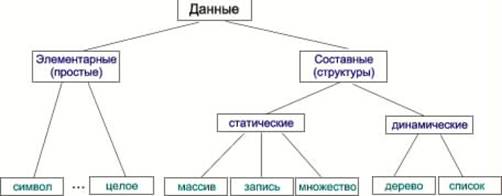
Организация баз данных
362757
знаков
48
таблиц
34
изображения
3. Далее этот процесс следует повторить для вставки среднего значения W в родительский элемент Р на более высоком структурном уровне.
В худшем случае процесс разделения элементов структуры может продлиться вплоть до корневого элемента всей структуры с образованием нового иерархического уровня.
Для удаления некоторого значения следует применить аналогичный алгоритм, но только в обратном порядке. А для изменения значения его можно удалить, а затем вставить новое.
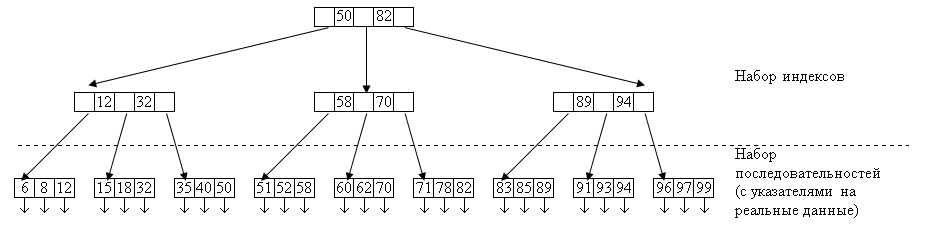 рис. 13.5 Пример структуры типа Б-дерева
рис. 13.5 Пример структуры типа Б-дерева
Хешированием, хеш-адресацией или хеш-индексированием называется технология быстрого прямого доступа к хранимой записи на основе заданного значения некоторого поля. При этом не обязательно, чтобы поле было ключевым.
Ниже перечислены основные черты этой технологии:
1. каждая хранимая запись базы данных размещается по адресу, который вычисляется с помощью специальной хеш-функции на основе значения некоторого поля данной записи, т.е. хеш-поля, или хеш-ключа. Вычисленный адрес называется хеш-адресом.
2. для сохранения записи в СУБД сначала вычисляется хеш-адрес новой записи, а затем диспетчер файлов помещает эту запись по вычисленному адресу.
3. Для извлечения нужной записи по заданному значению хеш-поля в СУБД сначала вычисляется хеш-адрес, а затем диспетчеру файлов посылается запрос для извлечения записи по вычисленному адресу.
В качестве простой иллюстрации предположим, что у нас есть записи с данными о студентах с кодами 100, 200, 300, 400, 500, а в качестве хеш-функции h используется следующая: h = StNo mod 13, где h – хеш-адрес, StNo – код студента.
Это простейший пример общего класса хеш-функций типа деление/остаток. (В качестве делителя следует выбирать простое натуральное число). В этом примере хеш-адресами для заданных записей будут 9, 5, 1, 10 и 6 соответственно. Схематически взаимное расположение записей на страницах показано на рис. 13.6.
| 0 | 1 | Иванов | … | … | 2 | 3 | 4 | ||||||||
| 300 | |||||||||||||||
| 5 | Петров | … | … | 6 | Сидоров | … | … | 7 | 8 | 9 | Стрельцов | … | … | ||
| 200 | 500 | 100 | |||||||||||||
| 10 | Кузнецов | … | … | 11 | 12 | ||||||||||
| 400 | |||||||||||||||
рис. 13.6 Пример использования хеширования.
Недостатком хеширования является возможность возникновения коллизий, т.е. ситуаций, когда две или более различных записи имеют одинаковые адреса. Допустим, что файл студентов из предыдущего примера (с записями 100, 200 и т.д.) содержит также запись с номером 1400. При использовании хеш-функции h = StNo mod 13 возникнет коллизия (по адресу 9) с записью 100.
Для разрешения таких коллизий можно использовать значения хеш-функции в качестве адреса не какой-либо записи с данными, а точки привязки. Точка привязки – это начальный адрес цепочки указателей (цепочки коллизий), связывающей вместе все записи или все страницы с записями, которые вызывают коллизии по адресу. Внутри цепочки коллизий записи также могут быть упорядочены согласно хеш-полю для упрощения последующего поиска.
Один из недостатков описанного выше способа хеширования – возрастание числа коллизий с увеличением размера хранимого файла. Это, в свою очередь, может привести к значительному увеличению среднего времени доступа, поскольку все больше и больше времени придется тратить на поиск записей в наборах конфликтующих записей. Однако этот недостаток можно устранить, если реорганизовать файл, т.е. выгрузить данный файл и загрузить его вновь, используя новую хеш-функцию.
Существует ряд модификаций алгоритма хеширования, например, расширяемое хеширование и др., применяемые для оптимизации операций обновления и поиска в БД.
Литература:
1. Дейт К.Дж. Введение в системы баз данных. –Пер. с англ. –6-е изд. –К. Диалектика, 1998. Стр. 674–696.
ЛЕКЦИЯ 14. Оптимизация запросов14.1 Оптимизация в реляционных СУБД.
14.2 Пример оптимизации реляционного выражения
14.3 Обзор процесса оптимизации
14.4 Преобразование выражений
14.1 Оптимизация в реляционных СУБД.Для реляционных систем оптимизация является как проблемой, так и возможностью повышения производительности. Проблема оптимизации состоит в том, что некоторые системы для достижения определенного уровня производительности требуют оптимизации. Оптимизация позволяет улучшить работу системы, так как одной из сильных сторон реляционного подхода является то, что первое применение оптимизации к реляционному выражению переводит это выражение на более эффективный семантический уровень. Общее назначение оптимизатора состоит в выборе эффективной стратегии для вычисления данного реляционного выражения.
Преимущество автоматической оптимизации заключается в том, что пользователь может не задумываться над наилучшим способом выражения своих запросов (т.е. над тем, как сформулировать запрос, чтобы система выполнила его с максимально возможной производительностью). Но это далеко не все. Существует реальная возможность, что оптимизатор сформулирует запрос лучше, чем программист-пользователь. Для подобного утверждения есть ряд причин. Ниже приведены только некоторые из них:
1. Хороший оптимизатор – обратите внимание на слово "хороший" – обладает достаточным количеством информации, которой пользователь может не иметь. Точнее, оптимизатор должен обладать некоторыми статистическими данными, такими как кардинальное число каждого базового отношения, количество различающихся значений для каждого атрибута в отношении, количество вхождений каждого значения в атрибутах и т.п. Благодаря наличию этих данных оптимизатор способен более точно оценивать эффективность любой стратегии реализации конкретного запроса. Поэтому оптимизатор сможет выбрать наилучшую стратегию реализации запроса.
2. Если с течением времени статистика базы данных значительно изменится (например, база данных будет физически реорганизована), то для реализации запроса может потребоваться совсем иная стратегия, чем до реорганизации. Другими словами, может понадобиться повторная оптимизация, или реоптимизация. В реляционных системах процесс реоптимизации достаточно тривиален – это просто повторная обработка исходного запроса системным оптимизатором. С другой стороны, в нереляционных системах реоптимизация требует переписывания программы, и, возможно, невыполнима вообще.
3. Оптимизатор – это программа, поэтому он более "настойчив" по сравнению с человеком. Оптимизатор вполне способен рассматривать буквально сотни различных стратегий реализации данного запроса, в то время как программист вряд ли изучает более трех-четырех стратегий (по крайней мере, достаточно глубоко).
4. В оптимизатор встроены знания и опыт "лучших из лучших" программистов, что делает эти знания и опыт доступными для всех. Естественно, в противном случае широкому кругу пользователей будет предоставлен явно недостаточный набор дешевых и неэффективных возможностей.
14.2 Пример оптимизации реляционного выраженияНачнем изложение с простого примера, дающего представление о результатах, которые можно получить с помощью оптимизации. Рассмотрим запрос "Получить список фамилий студентов, учащихся в группе А-98-51". Алгебраическая запись этого запроса такова:
((Students JOIN Groups) WHERE GrName = 'А-98-51') [StName]
Предположим, что база данных содержит информацию о 100 группах и 10000 студентов, только 30 из которых обучаются в группе А-98-51. В таком случае, если система будет вычислять выражение прямо (т.е. вообще без оптимизации), то последовательность выполняемых действий будет выглядеть так:
1. Соединение отношений Students и Groups (по атрибуту GrNo). На этом этапе считывается информация о 10000 студентов и 10000 раз считывается информация о 100 группах (один раз для каждого студента). После этого создается промежуточный результат, состоящий из 10000 соединенных кортежей.
2. Выборка кортежей с данными только о группе А-98-51 из результата, полученного на этапе 1. На этом этапе создается новое отношение, которое состоит из 30 кортежей.
3. Проекция результата, полученного на этапе 2, по атрибуту StName. На этом этапе создается требуемый результат, состоящий из 30 кортежей.
Показанная ниже процедура эквивалентна описанной в том смысле, что обязательно создаст тот же конечный результат, но более эффективным способом:
1. Выборка кортежей с данными только о группе А-98-51 из отношения Groups. На этом этапе выполняется чтение 100 кортежей и создается результат, состоящий только из 1 кортежа.
2. Соединение результата, полученного на этапе 1, с отношением Students (по атрибуту GrNo). На этом этапе выполняется считывание данных о 10000 студентов и 10000 раз считывается информация о группе А-98-51, полученная на 1 этапе. Результат содержит 30 кортежей.
3. Проецирование результата, полученного на этапе 2, по атрибуту StName (аналогично этапу 3 предыдущей последовательности действий). Требуемый результат содержит 30 кортежей.
Первая из показанных процедур выполняет в общем 1010000 операций ввода-вывода кортежа, в то время как вторая процедура выполняет только 20000 операции ввода-вывода. Следовательно, если принять "количество операции ввода-вывода кортежа" в качестве меры производительности, то вторая процедура в 50 раз эффективнее первой. (На практике мерой производительности служит количество операций ввода-вывода страницы, а не одного кортежа, но для данного примера эту поправку можно игнорировать.)
14.3 Обзор процесса оптимизации14.3.1 Стадия 1. Преобразование запроса во внутреннюю форму
На этой стадии выполняется преобразование запроса в некоторое внутреннее представление, более удобное для машинных манипуляций. Это полностью исключает из рассмотрения конструкции внешнего уровня (такие как "игра слов" конкретного синтаксиса рассматриваемого языка запросов) и готовит почву для последующих стадий оптимизации.
Обычно внутреннее представление запросов является определенной модификацией абстрактного синтаксического дерева, или дерева запроса.
Например, на рисунке показано дерево рассматриваемого выше в этой главе запроса ("Получить список фамилий студентов, учащихся в группе А-98-51").
 рис. 14.1. Дерево запроса "Получить список фамилий студентов, учащихся в группеА-98-51"
рис. 14.1. Дерево запроса "Получить список фамилий студентов, учащихся в группеА-98-51"
На этой стадии оптимизатор выполняет несколько операций оптимизации, которые "гарантированно являются хорошими" независимо от реальных данных, хранящихся в базе данных, и путей доступа к ним. Суть в том, что все запросы (за исключением простейших) реляционные языки обычно позволяют выразить несколькими разными (по крайней мере, внешне) способами.
Замечание о канонической форме. Понятие канонической формы употребляется, во многих разделах математики и связанных с ней дисциплин. Каноническая форма может быть определена следующим образом. Пусть Q – множество объектов (запросов), и пусть существует понятие об эквивалентности этих объектов (а именно: запросы q1 и q2 эквивалентны тогда и только тогда, когда дают идентичные результаты) Говорят, что подмножество C множества Q является подмножеством канонических форм для запросов из Q в смысле определенной выше эквивалентности тогда и только тогда, когда каждому объекту q из Q соответствует только один объект c из C. Тогда говорят, что объект с является канонической формой объекта q. Все "интересующие" свойства, которыми обладает объект q, также присущи и объекту с. Поэтому, чтобы доказать различные "интересующие" результаты, достаточно изучить менее мощное множество объектов C, а не более мощное множество Q.
Чтобы преобразовать результаты стадии 1 в некоторую эквивалентную, но более эффективную форму, оптимизатор использует определенные и хорошо известные правила преобразования, или законы.
14.3.3 Стадия 3. Выбор потенциальных низкоуровневых процедурПосле преобразования внутренней формы запроса в более подходящую (каноническую) форму оптимизатор должен решить, как выполнять запрос, представленный в канонической форме. На этой стадии принимается во внимание наличие индексов и других путей доступа, распределение хранимых значений данных, физическая кластеризация хранимых данных и т.п. Заметьте, что на стадиях 1 и 2 этим вопросам совсем не уделялось внимания
Для каждой низкоуровневой операции оптимизатор обладает набором низкоуровневых процедур реализации.
Замечание. С каждой процедурой также связана стоимостная формула, которая указывает "стоимость" выполнения процедуры (т.е. уровень требуемых затрат на ее выполнение). Обычно стоимость вычисляется в контексте операций ввода-вывода с диска, но некоторые системы учитывают также время использования процессора и другие факторы. Эти стоимостные формулы используются на стадии 4.
Следовательно, далее с помощью информации из каталога о состоянии базы данных (существующие индексы, кардинальные числа отношений и т.п.) и данных о зависимостях, описанных выше, оптимизатор выберет одну или несколько процедур-кандидатов для каждой низкоуровневой операции в запросе. Этот процесс обычно называют выбором пути доступа.
14.3.4 Стадия 4. Генерация планов вычисления запроса и выбор плана с наименьшей стоимостьюНа последней стадии процесса оптимизации конструируются потенциальные планы запросов, после чего следует выбор лучшего (т.е. наименее дорогого) плана выполнения запроса. Каждый план выполнения строится как комбинация набора процедур реализации, при этом каждой низкоуровневой операции в запросе соответствует одна процедура.
Для выбора плана с наименьшей стоимостью необходим метод привязки стоимости к данному плану. В основном стоимость плана – это просто сумма стоимостей отдельных процедур, которые использованы для его выполнения. Таким образом, работа оптимизатора сводится к вычислению стоимостных формул для каждой такой процедуры. Проблема состоит в том, что стоимость выполнения процедуры зависит от размера отношения (или отношений), которое выбранная процедура обрабатывает.
14.4 Преобразование выражений14.4.1 Выборки и проекции
1. Последовательность выборок данного отношения может быть преобразована в одну (объединенную операцией AND) выборку этого отношения. Например, выражение
(A WHERE выборка_1) WHERE выборка_2
эквивалентно выражению
A WHERE выборка_1 AND выборка_2
Похожие работы
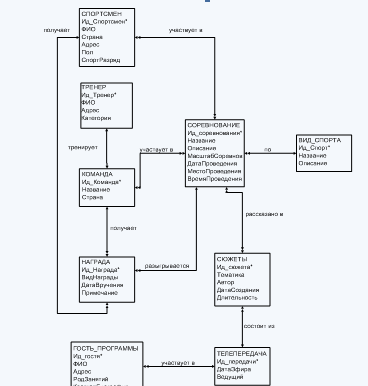
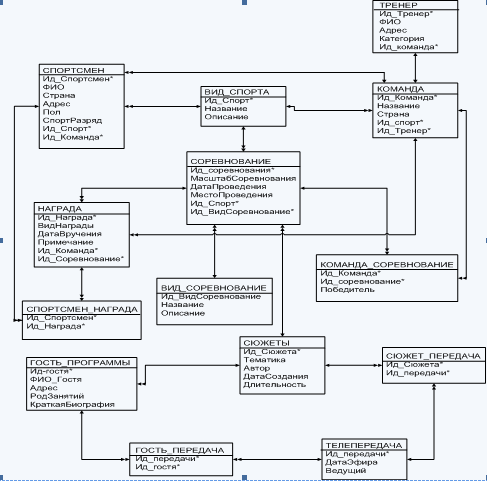
... для предметной области «Спортивная программа» показана на рис.1 Рис.1 – КМД для предметной области «Спортивная программа» Двойная стрелка означает «многие», одинарная стрелка означает «один» во взаимосвязи между объектами. Ключевые атрибуты обозначены *. Описание реляционной модели данных Реляционная модель данных (РМД) представляет БД в виде множества взаимосвязанных отношений, в том ...
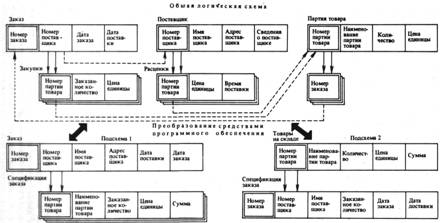
... и прикладных программ (логическая независимость данных) и возможность изменения физического расположения и организации данных без изменения общей логической структуры данных и структур данных прикладных программистов (физическая независимость). Рис. 1 2. Системы управления базами данных Использование систем управления базами данных (СУБД) позволяет исключить из прикладных программ ...
... (в виде связей). В последнее время все большее значение приобретает объектно-ориентированный подход к представлению данных. Физическая организация баз данных Физическая организация данных определяет собой способ непосредственного размещения данных на машинном носителе. В современных прикладных программных средствах этот уровень организации обеспечивается автоматически без вмешательства ...
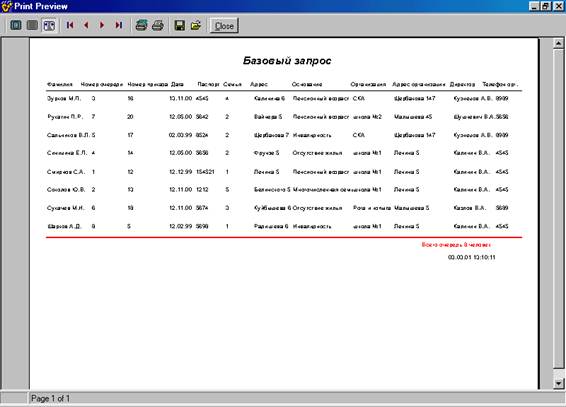
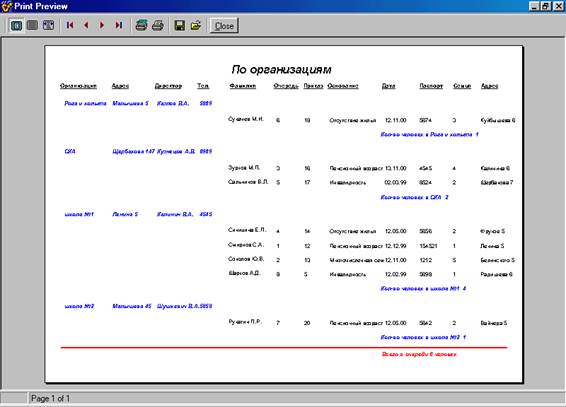
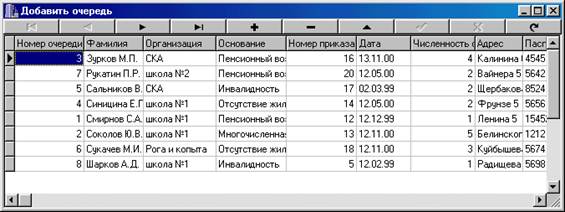
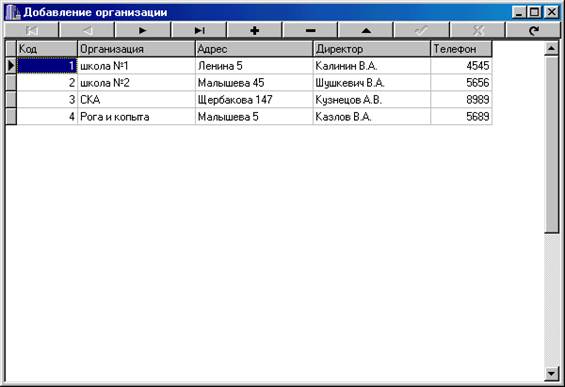
... отчет. Базовый отчет: Отчет по организациям: Программа предназначена для учёта очереди по организациям, а также для предоставления оперативной информации о очереди. К входящей информации относятся: номер очереди, фамилия, организация, основание, номер приказа, дата, численность семьи, адрес , паспорт. Т. е файл: Также Справочник 1 и 2: К выходящей информации в отчёте ...
0 комментариев