Навигация
Встановлюємо час t = t + 1 ; вертаємося до кроку 3, якщо t < T ; інакше — закінчуємо виконання
35454
знака
5
таблиц
4
изображения
5. Встановлюємо час t = t + 1 ; вертаємося до кроку 3, якщо t < T ; інакше — закінчуємо виконання.
Підбиваючи підсумок, можливо помітити, що повний опис ПММ складається із двох параметрів моделі ( N і M ), опису символів спостережуваної послідовності й трьох масивів ймовірностей — A , B , і π . Для зручності ми використаємо наступний запис
![]() (11)
(11)
для позначення достатнього опису параметрів моделі.
5. Основні результати, які отримані в результаті вирішення задачі
Відповідно до опису схованої марківської моделі, викладеному в попередньому розділі, існує три основних задачі, які повинні бути вирішені для того, щоб модель могла успішно вирішувати поставлені перед нею задачі.
Задача 1
Дано: спостережувана послідовність і модель λ = ( A , B ,π) . Необхідно обчислити ймовірність P ( O | λ) — імовірність того, що дана спостережувана послідовність побудована саме для даної моделі.
Задача 2
Дано: спостережувана послідовність і модель λ = ( A , B ,π) . Необхідно підібрати послідовність станів системи , що найкраще відповідає спостережуваній послідовності, тобто «пояснює» спостережувану послідовність.
Задача 3
Підібрати параметри моделі λ = ( A , B ,π) таким чином, щоб максимізувати P ( O | λ) .
Задача 1 - це задача оцінки моделі, що полягає в обчисленні ймовірності того, що модель відповідає заданій спостережуваній послідовності. До суті цієї задачі можна підійти й з іншої сторони: наскільки обрана ПММ відповідає заданій спостережуваній послідовності. Такий підхід має більшу практичну цінність. Наприклад, якщо в нас коштує питання вибору найкращої моделі з набору вже існуючих, то рішення першої задачі дає нам відповідь на це питання.
Задача 2 - це задача, у якій ми намагаємося зрозуміти, що ж відбувається в прихованій частині моделі, тобто знайти «правильну» послідовність, що проходить модель. Зовсім ясно, що абсолютно точно не можна визначити цю послідовність. Тут можна говорити лише про припущення з відповідним ступенем вірогідності. Проте для наближеного рішення цієї проблеми ми звичайно будемо користуватися деякими оптимальними показниками, критеріями. Далі ми побачимо, що, на жаль, не існує єдиного критерію оцінки для визначення послідовності станів. При рішенні другої задачі необхідно кожний раз ухвалювати рішення щодо того, які показники використати. Дані, отримані при рішенні цієї задачі використаються для вивчення поводження побудованої моделі, знаходження оптимальної послідовності її станів, для статистики й т.п. [6]
Рішення задачі 3 складається в оптимізації моделі таким чином, щоб вона якнайкраще описувала реальну спостережувану послідовність. Спостережувана послідовність, по якій оптимізується ПММ, прийнято називати навчальною послідовністю, оскільки за допомогою її ми «навчаємо» модель. Задача навчання ПММ - це найважливіша задача для більшості проектованих ПММ, оскільки вона полягає в оптимізації параметрів ПММ на основі навчальної спостережуваної послідовності, тобто створюється модель, що щонайкраще описує реальні процеси.
Для кращого розуміння розглянемо все вищесказане на прикладі системи, призначеної для розпізнавання мови. Для кожного слова зі словника W ми спроектуємо ПММ із N станами. Кожне слово зокрема ми представимо як послідовність спектральних векторів. Навчання ми будемо вважати завершеним, коли модель із високою точністю буде відтворювати ту саму послідовність спектральних векторів, що використалася для навчання моделі. У такий спосіб кожна окрема ПММ буде навчатися відтворювати яке-небудь одне слово, але навчати цю модель треба на декількох варіантах проголошення цього слова; тобто наприклад три чоловіки (кожний по-своєму) проговорюють слово «собака», а потім кожне сказане слово конвертується в упорядкований за часом набір спектральних векторів, і модель навчається на основі цих трьох наборів. Для кожного окремого слова проектуються відповідні моделі. Спершу вирішується 3-я задача ПММ: кожна модель настроюється на «проголошення» певного слова зі словника W , відповідно до заданої точності. Для того щоб інтерпретувати кожний стан спроектованих моделей ми вирішуємо 2-ую задачу, а потім виділяємо ті властивості спектральних векторів, які мають найбільша вага для певного стану. Це момент тонкого настроювання моделі. А вже після того, як набір моделей буде спроектований, оптимізований і навчений, варто оцінити модель на предмет її здатності розпізнавати слова в реальному житті. Тут ми вже вирішуємо 1-ую задачу ПММ. Нам дається тестове слово, представлене, зрозуміло, у вигляді спостережуваної послідовності спектральних векторів. Далі ми обчислюємо функцію відповідності цього тестового слова для кожної моделі. Модель, для якої ця функція буде мати найбільше значення, буде вважатися моделлю названого слова.
6. Місце і спосіб застосування отриманих результатів
Для розпізнавання мовлення із великих словників для ізольовано (або дискретно) вимовлених слів на початку 90-х років було розроблено декілька систем з достатньо гарними показниками. Потім увага дослідників перенеслася на розпізнавання злитого мовлення, де використовувалися статистичні залежності в порядку слів, що дозволяло передбачити поточне розпізнаване слово на основі кількох попередніх слів. Розроблені статистичні методи прогнозу дозволили значно зменшити кількість альтернатив при розпізнаванні, що у свою чергу дозволило розробляти системи розпізнавання з сумарним обсягом у десятки тисяч слів, хоча на кожному кроці розпізнавання розглядалося декілька сотень альтернатив.
Проте, існує необхідність побудови систем розпізнавання мови з великою кількістю альтернатив і за умови, що немає яких-небудь обмежень на порядок розпізнаваних слів.
Наприклад, при керуванні комп'ютера голосом неможливо передбачити наступне слово на основі декількох попередніх, оскільки це визначається логікою керування комп'ютера, а не властивостями тексту. З іншого боку існує необхідність значного збільшення обсягу словника для того, щоб охопити всі синоніми однієї і тієї ж команди, оскільки користувачу, звичайно, важко запам'ятати тільки один варіант назви команди.
Другий приклад пов'язаний з диктуванням текстів. Використання таких систем, звичайно, обмежено такими текстами, що аналогічні тим текстам, для яких накопичувалися статистики. Крім іншого, додаткове редагування набраного тексту вимагає наявності всіх слів в активному словнику.
Таким чином, існують додатки, де бажано мати словник максимально великого розміру, щоб у майбутньому охопити всі слова даної мови.
Додаткова інформація для обмеження числа альтернатив може бути одержана безпосередньо з мовного сигналу. Для цього пропонується виконати пробне розпізнавання за допомогою фонетичного стенографа. Одержана послідовність фонем формує потік запитів до бази даних для отримання невеликої кількості слів, які могли б входити в словник розпізнавання, що дозволяє значно скоротити кількість альтернатив для розпізнавання.[3]
Наступні розділи описують новий двопрохідний алгоритм. Спочатку представлена базова система для порівняння із запропонованою системою розпізнавання мови. Потім описані два варіанти алгоритму для ізольованих слів та злитого мовлення. Виконані експерименти показують ефективність запропонованих методів.
Запропонований метод можна застосувати в будь-якій системі розпізнавання мовлення, де представлені фонеми, і можна сформувати процедуру фонетичного стенографа. У даній роботі як базова система використовується інструментарій на основі прихованих Марківських моделей (Hidden Markov Model - HMM)
Попередня обробка мовленнєвого сигналу
Мовний сигнал перетвориться в послідовність векторів ознак з інтервалом аналізу 25 мс і кроком аналізу 10 мс. Спочатку мовний сигнал фільтрується фільтром високих частот з характеристикою P(z) =1-0.97z-1 та застосовується вікно Хемінга. Швидке перетворення Фурьє переводити часовий сигнал у спектральний вигляд. Спектральні коефіцієнти усереднюються з використанням 26 трикутних вікон, розташованими в мел-шкалі. 12 кепстральних коефіцієнтів обчислюються за допомогою зворотного косинусного перетворення.
Логарифм енергії додається як 13-й коефіцієнт. Ці 13 коефіцієнтів розширюються до 39-мірного вектора параметрів шляхом дописування першої та другої різниць від коефіцієнтів сусідніх за часом. Для обліку впливу каналу застосовується віднімання середнього кепстра.
Акустична модель
Акустичні моделі відображають характеристики основних одиниць розпізнавання. Для акустичних моделей використовуються приховані Марківські моделі з 64 сумішами Гауссівських функцій щільності імовірності. 47 російських контекстно-незалежних фонем моделюються трьома станами Марківського ланцюга з пропусками. Словник транскрипцій створюється автоматично з орфографічного словника з використанням множини контекстно-залежних правил.[3]
Показники базової системи
Акустичні моделі навчалися на вибірці з 12 тис. звукових записів із словника в 2037 слів, вимовлених одним диктором. Розпізнавання проводилося на комп'ютері P-IV 2.4 ГГц.
Для перевірки надійності розпізнавання мови було накопичено 1000 окремо вимовлених слів тим же диктором. Послівна надійність розпізнавання і середній час розпізнавання однієї секунди мови для різних розмірів словника приведені в таблиці 1. Оскільки час розпізнавання лінійно залежить від розміру словника, то для словника в 1987 тис. слів його можна оцінити приблизно в 2300 секунд.
Таблиця 1: Результати розпізнавання окремо вимовлених слів базовою системою
| Об'єм словника, тис. | 1 | 15 | 95 |
| Надійність, % | 99.9 | 97.9 | 94.7 |
| Час, сек. | 1 | 16 | 115 |
Для перевірки надійності розпізнавання злитого мовлення було додатково накопичено 1000 фраз з числами від 0 до 999. Послівна надійність розпізнавання і середній час розпізнавання однієї секунди мови для різних розмірів словника приведені в таблиці 2.
Таблиця 2: Результати розпізнавання злитого мовлення базовою системою
| Об'єм словника, тис. | 1 | 15 | 95 |
| Надійність, % | 98.0 | 96.5 | 92.6 |
| Час, сек. | 2.1 | 36 | 205 |
Похожие работы
... культурною діяльністю для добра українського народу.[220,С.9] Значення постатей Митрополита А.Шептицького та Патріарха Й.Сліпого важко переоцінити. Яскравим свідченням цього є розпочатий Українською Греко-Католицькою Церквою процес беатифікації Митрополита Андрея Шептицького. Після розвалу тоталітарно-імперського СРСР Україна стала незалежною, самостійною державою, на території якої проживають ...

... депозитну угоду і документи з відкриття депозитного рахунку. 5.2. Самостійно повторити матеріал та розглянути інформаційні джерела, рекомендовані до тем 4, 6 з 1-го та 2-го модулів дисципліни „Банківські операції”. Практичне заняття-тренінг 6 Розрахунково-касове обслуговування фізичних осіб Питання для опрацювання 1. Правила надання консультацій клієнтам з питань оформлення розрахунково ...
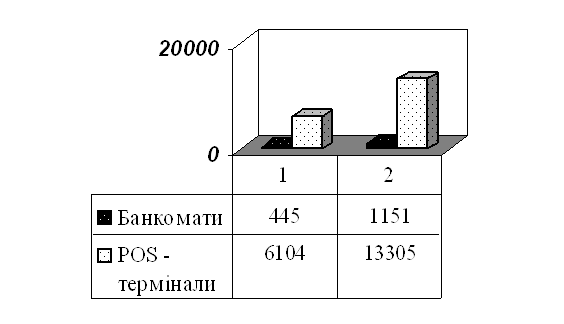
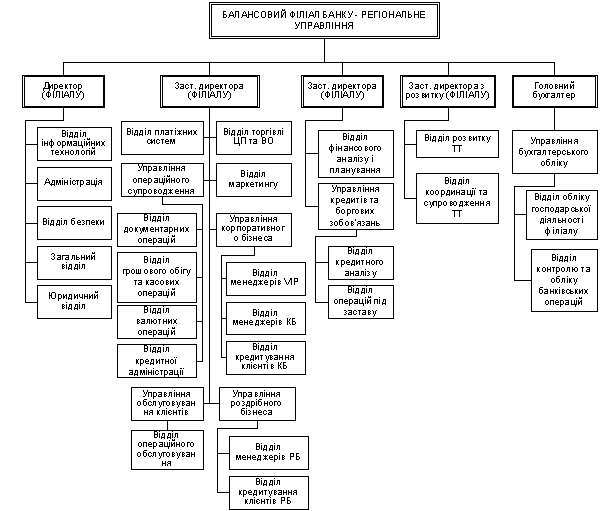
... будь-який громадянин в Україні, якщо в нього є стабільний дохід, може отримати “кредитку” без заставного майна та будь-яких гарантій, як це відбувається в розвинутих країнах світу. 3.3 Місце операцій з пластиковим картками в Інтернет-просторі України Лідери провідних держав та широкі кола ділового світу сприймають нову економіку не лише як сучасну модель ведення бізнесу, а й як стратегічну ...
... Дотримання цих умов обов’язкове для покупця жінки. Спробуємо тепер перевірити правильність наших висновків. Звернемося до історії, оскільки вона зберегла до нас дані щодо правового становища заміжньої жінки, заснованого в стародавності на викраденні, давнині, купівлі й інших способах. Найдавніша історія скупа у своїх свідченнях. Дещо зберегла вона для нас із глибокої давнини. Але і це дещо часто ...
0 комментариев