Навигация
Програмна реалізація завдання, виконаного у курсовій роботі
35454
знака
5
таблиц
4
изображения
7. Програмна реалізація завдання, виконаного у курсовій роботі
7.1 Алгоритм ELVIRS для окремо вимовлених слів
Архітектура
Архітектура системи розпізнавання ELVIRS (Extra Large Vocabulary Speech recognition based on the Information Retrieval) показана на мал. 4. Такі блоки з базової системи як обчислення ознак і акустичних моделей використовуються перед першим проходом алгоритму.
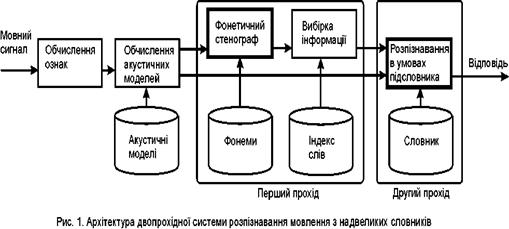
Також на другому проході використовується звичайне порівняння образів в умовах обмеженого словника
Зміни торкаються введення першого проходу алгоритму, де фонетичний стенограф використовується для отримання послідовності фонем. Потім процедура вибірки інформації створює обмежений словник (підсловник) для другого проходу алгоритму.
Фонетичний стенограф
Алгоритм фонетичного стенографа[2] створює фонетичну послідовність для мовного сигналу незалежно від словника. Для цього будується деякий автомат породження фонем, який може синтезувати всі можливі моделі мовних сигналів для послідовності фонем. Потім використовується пофонемне розпізнавання для невідомого мовного сигналу.
Використовуються ті ж контекстно-незалежні моделі фонем, що і в базовій системі розпізнавання.
Процедура отримання підсловника з бази даних
Заздалегідь в процесі навчання із словника транскрипцій створюється індекс від трійок фонем до транскрипцій. Ключем індексу є трійка фонем. Таким чином, таблиця індексу складається з M3 входжень, де M є число фонем в системі. Кожне входження в таблицю містить список транскрипцій, в які входить трійка фонем ключа входження.
Процес отримання підсловника ілюструється. Вихід фонетичного стенографа ділиться на трійки фонем із зрушенням на одну фонему. Трійка фонем стає запитом до бази даних. Зараз використовується простий запит, коли він в точності співпадає з трійкою фонем. В майбутньому пропонується використовувати відстань Levensteine для врахування вставок, видалень та замін в послідовності фонем. Таким чином, послідовність фонем продукує потік запитів до бази даних.
Відповідь на один запит складається із списку транскрипцій, в які дана трійка фонем входить. Цей список копіюється в підсловник для другого проходу алгоритму. Наступний запит з потоку додає нову порцію транскрипцій, при цьому підраховується кількість повторень для того, щоб можна було обчислити ранг слова в підсловнику.
Всі транскрипції в одержаному підсловнику упорядковуються згідно рангу слова (лічильнику повторень). Перші N транскрипцій заносяться в остаточний підсловник для другого проходу алгоритму. Таким чином, підсловник для розпізнавання містить транскрипції з найвищими рангами і число транскрипцій не перевищує фіксованого числа N.
Алгоритм ELVIRS
Алгоритм ELVIRS складається з двох частин. Підготовчий етап:
• Підготувати словник для розпізнавання.
• Вибрати множину фонем і створити транскрипції слів із словника за допомогою правил.
• Створити індекс бази даних від трійок фонем до транскрипцій.
• Навчити акустичні моделі по накопичених мовних сигналах.
Етап розпізнавання:
• Застосувати фонетичний стенограф до вхідного сигналу для отримання послідовності фонем.
• Поділити послідовність фонем на трійки фонем із зрушенням в одну фонему.
• Створити запити до БД з трійок фонем
• Одержати списки транскрипцій за допомогою запитів до індексу бази даних.
• Упорядкувати транскрипції до їх рангу.
• Вибрати перші N транскрипцій з найвищими рангами як підсловник для розпізнавання.
• Розпізнати вхідний мовний сигнал в умовах обмеженого підсловника.[5]
Інформаційна оцінка імовірності правильного формування підсловника
Відповідь розпізнавання фонетичного стенографа може розглядатися як правильна послідовність фонем, пропущена через канал з шумом. Позначимо у відповіді фонетичного стенографа правильну фонему як 1, а зіпсовану шумом як 0. Нехай імовірність появи 1 в двійковому наборі дорівнює u. Імовірність P знайти в двійковому наборі довжини n підряд k одиниць і більше можна обчислити за допомогою наступного рекурентного виразу:
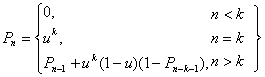 (12)
(12)
В таблиці показана імовірність P знайти в двійкових наборах підряд три і більше 1 при деяких довжинах n та імовірності u. Середня довжина транскрипцій дорівнює приблизно 8 і імовірність правильного знаходження фонеми у відомих реалізацій приблизно дорівнює 85%. При таких значеннях імовірність знайти правильне слово в підсловнику дорівнює 0.953.
Таблиця 3: Імовірність знайти підряд три і більше 1 в двійковому наборі довжини n
| 0.75 | 0.8 | 0.85 | 0.9 | |
| 6 | 0.738 | 0.819 | 0.890 | 0.948 |
| 7 | 0.799 | 0.869 | 0.926 | 0.967 |
| 8 | 0.849 | 0.908 | 0.953 | 0.982 |
| 9 | 0.887 | 0.937 | 0.971 | 0.991 |
| 10 | 0.915 | 0.956 | 0.981 | 0.995 |
Похожие работы
... культурною діяльністю для добра українського народу.[220,С.9] Значення постатей Митрополита А.Шептицького та Патріарха Й.Сліпого важко переоцінити. Яскравим свідченням цього є розпочатий Українською Греко-Католицькою Церквою процес беатифікації Митрополита Андрея Шептицького. Після розвалу тоталітарно-імперського СРСР Україна стала незалежною, самостійною державою, на території якої проживають ...

... депозитну угоду і документи з відкриття депозитного рахунку. 5.2. Самостійно повторити матеріал та розглянути інформаційні джерела, рекомендовані до тем 4, 6 з 1-го та 2-го модулів дисципліни „Банківські операції”. Практичне заняття-тренінг 6 Розрахунково-касове обслуговування фізичних осіб Питання для опрацювання 1. Правила надання консультацій клієнтам з питань оформлення розрахунково ...
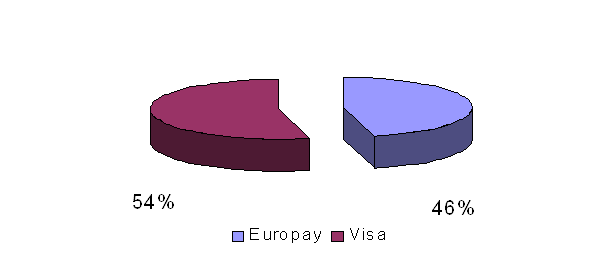
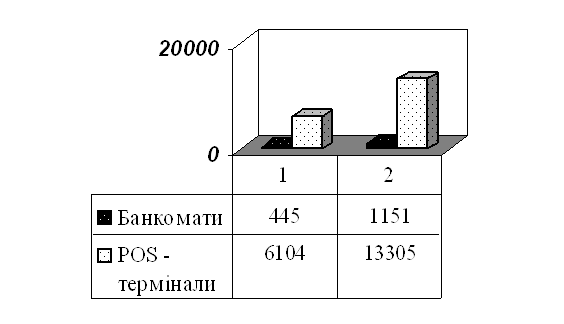
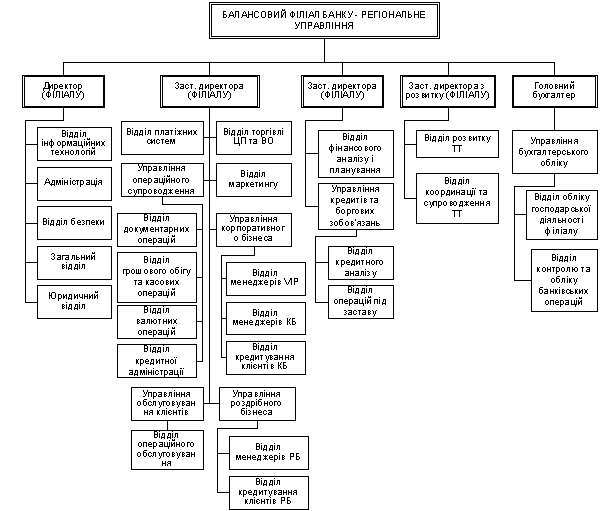
... будь-який громадянин в Україні, якщо в нього є стабільний дохід, може отримати “кредитку” без заставного майна та будь-яких гарантій, як це відбувається в розвинутих країнах світу. 3.3 Місце операцій з пластиковим картками в Інтернет-просторі України Лідери провідних держав та широкі кола ділового світу сприймають нову економіку не лише як сучасну модель ведення бізнесу, а й як стратегічну ...
... Дотримання цих умов обов’язкове для покупця жінки. Спробуємо тепер перевірити правильність наших висновків. Звернемося до історії, оскільки вона зберегла до нас дані щодо правового становища заміжньої жінки, заснованого в стародавності на викраденні, давнині, купівлі й інших способах. Найдавніша історія скупа у своїх свідченнях. Дещо зберегла вона для нас із глибокої давнини. Але і це дещо часто ...
0 комментариев