Разработано техническое задание на новую версию программы-нейроимитатора, реализующую предложенные технологии
Метод потенциальных функций [14] для решения задач классификации объектов с учителем
Возможность параллельного выполнения наиболее трудоемких этапов алгоритма и желательно - нейронной сетью
Методы, выполняющие цикл "элементарное упрощение – дообучение нейросети" до тех пор, пока дообучение приводит к решению задачи с требуемой точностью
Методы, не позволяющие задавать число контрастируемых элементов сети (методы, основанные на модификации штрафной функции)
Если функция кусочно-линейна, то кусочно-постоянные участки будут описываться условными правилами (п.3), а кусочно-линейные – функциональными (п.2)
Разработано техническое задание на новую версию программы-нейроимитатора, реализующую предложенные технологии
Навигация
Метод потенциальных функций [14] для решения задач классификации объектов с учителем
Технология извлечения знаний из нейронных сетей: апробация, проектирование ПО, использование в психолингвистике
176148
знаков
8
таблиц
14
изображений
1. Метод потенциальных функций [14] для решения задач классификации объектов с учителем.
2. Методы непараметрической обработки данных:
- байесовские классификаторы на основе непараметрических оценок условных плотностей распределения вероятности [12];
- непараметрическая регрессия;
- непараметрические алгоритмы идентификации объектов;
Однако использование этих методов для приобретения знаний невозможно, поскольку при этом не возникает нового отдельного "объекта" (например, регрессионного уравнения, уравнения разделяющей поверхности,…), которым можно манипулировать и который можно пытаться интерпретировать – такой объект заменяется обучающей выборкой. Конечно, для каждого метода можно определить оптимальные значения некоторых параметров ("заряды" классов для метода потенциальных функций, параметры сглаживания и вид ядерных функций для непараметрических методов), минимизирующих ошибку классификации или предсказания, но нахождение оптимальных значений этих параметров трудно интерпретировать как прибавление новых знаний.
1.3. Требования к технологии извлечения знанийВозможности применения технологии извлечения знаний должны распространяться вплоть до индивидуального пользователя, имеющего возможность применять технологию извлечения знаний к доступных данных и конкретизирующего отдельные аспекты этой технологии в зависимости от своего собственного опыта и конкретной задачи. Это означает, что должно произойти коренное изменение технологии производства таких систем. Системы принятия решений, основанные на явных правилах вывода, создаются, как правило, группой специалистов, в числе которых – математики, программисты и предметные специалисты, ставящие задачи. Возможности настройки таких систем на конечного потребителя часто недостаточны. Приобретая такую систему, он часто сталкивается с ее неприменимостью к конкретным условиям работы (например, другой спектр лабораторных анализов или методов обследования, принятый в данной клинике). Выход – дать специалисту возможность самому конструировать ЭС исходя из конкретных условий, собственного опыта и опыта коллег. Такое конструирование должно производиться без знания предметным специалистом математического аппарата, требуя только обычных навыков работы на ЭВМ. В этой ситуации снимается психологическая проблема доверия к заключениям ЭС, которая работает, опираясь на опыт и знания того специалиста, который ее сконструировал, его коллег, которым он доверяет, и реальные данные, которые он сам получил в результате наблюдений [15].
Самообучающиеся ЭС принятия решений, диагностики и прогнозирования должны удовлетворять следующим требованиям [15]:
1. Индивидуализация (настройка на конкретные наборы экспериментальных данных, индивидуальный опыт и знания специалиста);
2. Динамическое развитие (накопление опыта системы в процессе функционирования, следуя изменениям в пунктах, перечисленных в предыдущем требовании);
3. Возможность перенастройки при резком изменении условий, например, при перенесении в другой регион;
4. Способность к экстраполяции результата. Требование, обратное индивидуальности. Система не должна резко терять качество работы при изменении условий;
5. Возможность конструирования с нуля конечным пользователем (специалист должен иметь возможность придумать совершенно новую ЭС и иметь возможность просто и быстро создать ее);
6. “Нечеткий” характер результата. Решение, выдаваемое системой, не должно быть окончательным. Оно может быть вероятностным или предлагать сразу несколько вариантов на выбор. Это дает возможность специалисту критически оценивать решение системы и не лишает его инициативы в принятии окончательного решения.
7. ЭС является только советчиком специалиста, не претендуя на абсолютную точность решения. Она должна накапливать опыт и знания и значительно ускорять доступ к ним, моделировать результат при изменении условий задачи. Ответственность за решение всегда лежит на специалисте.
8. Универсальность такой технологии означает, она не должна опираться на семантику проблемной области, предлагая унифицированный подход для решения типовых задач в любой проблемной области. Семантический аспект постановки задачи, осмысления процесса решения и анализа результатов лежит на конечном специалисте.
Анализ существующих методов обработки информации показал, что этим требованиям хорошо удовлетворяют нейроинформационные технологии, основанные на искусственных нейронных сетях [16-19]. В основе их функционирования лежат алгоритмы, моделирующие распространение сигналов по нейронам и синапсам нервной системы. Существует достаточно большой набор архитектур и метаалгоритмов функционирования нейронных сетей, при этом задачи, решаемые нейроинформатикой, в большинстве случаев требуют подгонки архитектуры и алгоритмов обучения нейросетей под определенный класс задач или даже конкретную задачу. Поэтому разработка теоретических и методологических основ и универсальной технологии создания ЭС, включающей оптимизацию архитектур и метаалгоритмов функционирования нейросетей при работе с информацией, и извлечение знаний из нейросетей является актуальной задачей.
Глава 2. Нейронные сети
2.1. КоннекционизмНейронные сети ‑ это сети, состоящие из связанных между собой простых элементов ‑ формальных нейронов. Нейроны моделируются довольно простыми автоматами, а вся сложность, гибкость функционирования и другие важнейшие качества определяются связями между нейронами. Каждая связь представляется как совсем простой элемент, служащий для передачи сигнала.
Научно-техническое направление, определяемое описанным представлением о нейронных сетях, называется коннекционизмом (по-ангийски connection – связь). С коннекционизмом тесно связан следующий блок идей:
1) однородность системы (элементы одинаковы и чрезвычайно просты, все определяется структурой связей);
2) надежные системы из ненадежных элементов и "аналоговый ренессанс" – использование простых аналоговых элементов;
3) "голографические" системы – при разрушении случайно выбранной части система сохраняет свои полезные свойства.
Существует большой класс задач: нейронные системы ассоциативной памяти, статистической обработки, фильтрации и др., для которых связи формируются по явным формулам. Но еще больше (по объему существующих приложений) задач требует неявного процесса. По аналогии с обучением животных или человека этот процесс также называют обучением.
Обучение обычно строится так: существует задачник – набор примеров с заданными ответами. Эти примеры предъявляются системе. Нейроны получают по входным связям сигналы – "условия примера", преобразуют их, несколько раз обмениваются преобразованными сигналами и, наконец, выдают ответ – также набор сигналов. Отклонение от правильного ответа штрафуется. Обучение состоит в минимизации штрафа как (неявной) функции связей.
Неявное обучение приводит к тому, что структура связей становится "непонятной" – не существует иного способа ее прочитать, кроме как запустить функционирование сети. Становится сложно ответить на вопрос: "Как нейронная сеть получает результат?" – то есть построить понятную человеку логическую конструкцию, воспроизводящую действия сети.
Это явление можно назвать "логической непрозрачностью" нейронных сетей, обученных по неявным правилам.
С другой стороны, при использовании нейронных сетей в экспертных системах возникает потребность прочитать и логически проинтерпретировать навыки, выработанные сетью. Для этого служат методы контрастирования – получения неявными методами логически прозрачных нейронных сетей.
2.2. Элементы нейронных сетейДля описания алгоритмов и устройств в нейроинформатике выработана специальная "схемотехника", в которой элементарные устройства – сумматоры, синапсы, нейроны и т.п. объединяются в сети, предназначенные для решения задач.
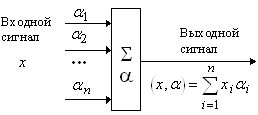
Адаптивный сумматор вычисляет скалярное произведение вектора входного сигнала x на вектор параметров a. На схемах он обозначается так, как показано на рис. 1. Адаптивным он называется из-за наличия вектора настраиваемых параметров a. Для многих задач полезно иметь линейную неоднородную функцию выходных сигналов. Ее вычисление также можно представить с помощью адаптивного сумматора, имеющего n+1 вход и получающего на 0-й вход постоянный единичный сигнал (рис. 2).
|
Рис. 2. Неоднородный адаптивный сумматор |

|
Рис. 1. Адаптивный сумматор. |
|
Рис. 5. Формальный нейрон |
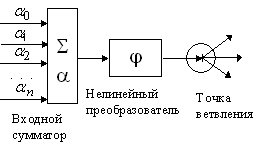
|
Рис. 3. Нелинейный преобразова-тель сигнала. |
|
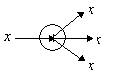
Рис. 4. Точка ветвления |
Нелинейный преобразователь сигнала изображен на рис. 3. Он получает скалярный входной сигнал x и переводит его в j(x).
Точка ветвления служит для рассылки одного сигнала по нескольким адресам (рис. 4). Она получает скалярный входной сигнал x и передает его всем своим выходам.
Стандартный формальный нейрон составлен из входного сумматора, нелинейного преобразователя и точки ветвления на выходе (рис. 5).
Линейная связь ‑ синапс ‑ отдельно от сумматоров не встречается, однако для некоторых рассуждений бывает удобно выделить этот элемент (рис. 6). Он умножает входной сигнал x на “вес синапса” a.
|
Рис. 6. Синапс. |
Итак, дано описание основных элементов, из которых составляются нейронные сети.
2.3. Основные архитектуры нейронных сетейКак можно составлять эти сети? Строго говоря, как угодно, лишь бы входы получали какие-нибудь сигналы. Используются несколько стандартных архитектур, из которых путем вырезания лишнего или (реже) добавления строятся большинство используемых сетей.
Здесь и далее рассматриваются только нейронные сети, синхронно функционирующие в дискретные моменты времени: все нейроны срабатывают “разом”.
В семействе нейронных сетей можно выделить две базовых архитектуры – слоистые и полносвязные сети.
|
Рис. 7. Слоистая сеть |
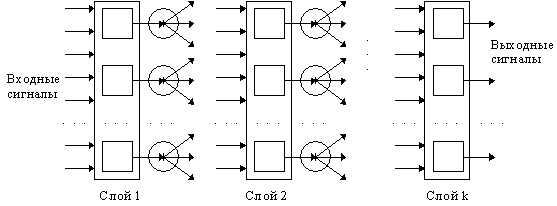
Слоистые сети: нейроны расположены в несколько слоев (рис. 7). Нейроны первого слоя получают входные сигналы, преобразуют их и через точки ветвления передают нейронам второго слоя. Далее срабатывает второй слой и т.д. до k-го слоя, который выдает выходные сигналы для интерпретатора и пользователя. Если не оговорено противное, то каждый выходной сигнал i-го слоя подается на вход всех нейронов i+1-го. Число нейронов в каждом слое может быть любым и никак заранее не связано с количеством нейронов в других слоях. Стандартный способ подачи входных сигналов: все нейроны первого слоя получают каждый входной сигнал. Особое распространение получили трехслойные сети, в которых каждый слой имеет свое наименование: первый – входной, второй – скрытый, третий – выходной.
Полносвязные сети: каждый нейрон передает свой выходной сигнал остальным нейронам, включая самого себя. Выходными сигналами сети могут быть все или некоторые выходные сигналы нейронов после нескольких тактов функционирования сети. Все входные сигналы подаются всем нейронам.
Элементы слоистых и полносвязных сетей могут выбираться по-разному. Существует, впрочем, стандартный выбор – нейрон с адаптивным неоднородным линейным сумматором на входе (рис. 5).
Для полносвязной сети входной сумматор нейрона фактически распадается на два: первый вычисляет линейную функцию от входных сигналов сети, второй – линейную функцию от выходных сигналов других нейронов, полученных на предыдущем шаге.
Функция активации нейронов (характеристическая функция) j – нелинейный преобразователь, преобразующий выходной сигнал сумматора (см. рис. 5) – может быть одной и той же для всех нейронов сети. В этом случае сеть называют однородной (гомогенной). Если же j зависит еще от одного или нескольких параметров, значения которых меняются от нейрона к нейрону, то сеть называют неоднородной (гетерогенной).
Если полносвязная сеть функционирует до получения ответа заданное число тактов k, то ее можно представить как частный случай k-слойной сети, все слои которой одинаковы и каждый из них соответствует такту функционирования полносвязной сети.
2.4. Обучение нейронных сетей как минимизация функции ошибкиПостроение обучения как оптимизации дает универсальный метод создания нейронных сетей для решения задач. Если сформулировать требования к нейронной сети, как задачу минимизации некоторой функции - оценки, зависящей от части сигналов (входных, выходных, ...) и от параметров сети, то обучение можно рассматривать как оптимизацию и строить соответствующие алгоритмы, программное обеспечение и, наконец, устройства. Функция оценки обычно довольно просто (явно) зависит от части сигналов - входных и выходных, но ее зависимость от настраиваемых параметров сети может быть сложнее и включать как явные компоненты (слагаемые, сомножители,...), так и неявные - через сигналы (сигналы, очевидно, зависят от параметров, а функция оценки - от сигналов).
За пределами задач, в которых нейронные сети формируются по явным правилам (сети Хопфилда, проективные сети, минимизация аналитически заданных функций и т.п.) требования к нейронной сети обычно можно представить в форме минимизации функции оценки. Не следует путать такую постановку задачи и ее весьма частный случай - "обучение с учителем".
Если для решения задачи не удается явным образом сформировать сеть, то проблему обучения можно, как правило, сформулировать как задачу минимизации оценки. Осторожность предыдущей фразы ("как правило") связана с тем, что на самом деле неизвестны и никогда не будут известны все возможные задачи для нейронных сетей, и, быть может, где-то в неизвестности есть задачи, которые несводимы к минимизации оценки.
Минимизация оценки - сложная проблема: параметров астрономически много (для стандартных примеров, реализуемых на РС - от 100 до 1000000), адаптивный рельеф (график оценки как функции от подстраиваемых параметров) сложен, может содержать много локальных минимумов, извилистых оврагов и т.п.
Наконец, даже для того, чтобы воспользоваться простейшими методами гладкой оптимизации, нужно вычислять градиент функции оценки. В данном разделе описывается связь двойственного функционирования сетей - автоматов с преобразованием Лежандра и неопределенными множителями Лагранжа.
Переменные обратного функционирования m появляются как вспомогательные при вычислении производных сложной функции. Переменные такого типа появляются не случайно. Они постоянно возникают в задачах оптимизации и являются множителями Лагранжа.
Для всех сетей автоматов, встречавшихся в предыдущих разделах, можно выделить три группы переменных:
внешние входные сигналы x...,
переменные функционирования - значения на выходах всех элементов сети f...,
переменные обучения a...(многоточиями заменяются различные наборы индексов).
Объединим их в две группы - вычисляемые величины y... - значения f... и задаваемые - b... (включая a... и x...). Упростим индексацию, перенумеровав f и b натуральными числами: f1,...,fN ; b1 ,...,bM .
Пусть функционирование системы задается набором из N уравнений
yi(y1 ,...,yN ,b1 ,...,bM)=0 (i=1,...,N). (1)
Для послойного вычисления сложных функций вычисляемые переменные - это значения вершин для всех слоев, кроме нулевого, задаваемые переменные - это значения вершин первого слоя (константы и значения переменных), а уравнения функционирования имеют простейший вид (4), для которого
![]()
Предполагается, что система уравнений (1) задает способ вычисления yi .
Пусть имеется функция (лагранжиан) H(y1 ,...,yN ,b1 ,...,bM). Эта функция зависит от b и явно, и неявно - через переменные функционирования y. Если представить, что уравнения (1) разрешены относительно всех y (y=y(b)), то H можно представить как функцию от b:
H=H1(b)=H(y1(b),...,yN(b),b). (2)
где b - вектор с компонентами bi .
Для задачи обучения требуется найти производные Di=¶H1(b)/¶bi . Непосредственно и явно это сделать трудно.
Поступим по-другому. Введем новые переменные m1,...,mN (множители Лагранжа) и производящую функцию W:
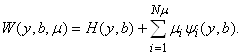
В функции W аргументы y, b и m - независимые переменные.
Уравнения (1) можно записать как
![]() (3)
(3)
Заметим, что для тех y, b, которые удовлетворяют уравнениям (13), при любых m
W(y,b,m)ºH(y,b). (4)
Это означает, что для истинных значений переменных функционирования y при данных b функция W(y,b,m) совпадает с исследуемой функцией H.
Попытаемся подобрать такую зависимость mi(b), чтобы, используя (4), получить для Di=¶H1(b)/¶bi наиболее простые выражения . На многообразии решений (15)
![]()
Поэтому
 (5)
(5)
Всюду различается функция H(y,b), где y и b - независимые переменные, и функция только от переменных b H(y(b),b), где y(b) определены из уравнений (13). Аналогичное различение принимается для функций W(y,b,m) и W(y(b),b,m (b)).
Произвол в определении m(b) надо использовать наилучшим образом - все равно от него придется избавляться, доопределяя зависимости. Если выбрать такие m, что слагаемые в первой сумме последней строки выражения (5) обратятся в нуль, то формула для Di резко упростится. Положим поэтому
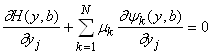 . (6)
. (6)
Это - система уравнений для определения mk (k=1,...,N). Если m определены согласно (6), то
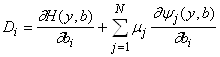
Основную идею двойственного функционирования можно понять уже на простейшем примере. Рассмотрим вычисление производной сложной функции одного переменного. Пусть заданы функции одного переменного f1(A) ,f2(A) ,...,fn(A) . Образуем из них сложную функцию
F(x)=fn (fn-1 (...(f1 (x))...)). (1)
Можно представить вычисление F(x) как результат работы n автоматов, каждый из которых имеет один вход и выдает на выходе значение fi (A), где A - входной сигнал (рис.8, а). Чтобы построить систему автоматов, вычисляющую F¢(x), надо дополнить исходные автоматы такими, которые вычисляют функции fi¢(A), где A - входной сигнал (важно различать производную fi по входному сигналу, то есть по аргументу функции fi, и производную сложной функции fi(A(x)) по x; fi¢(A) ‑ производные по A).
Для вычисления F¢(x) потребуется еще цепочка из n-1 одинаковых автоматов, имеющих по два входа, по одному выходу и подающих на выход произведение входов. Тогда формулу производной сложной функции
![]()
можно реализовать с помощью сети автоматов, изображенной на рис. 8, б. Сначала по этой схеме вычисления идут слева направо: на входы f1 и f1' подаются значения x, после вычислений f1(x) это число подается на входы f2 и f2' и т.д. В конце цепочки оказываются вычисленными все fi (fi-1 (...)) и fi'(fi-1 (...)).
|
Рис.8. Схематическое представление вычисления сложной функции одного переменного и ее производных. |

Можно представить вычисление любой сложной функции многих переменных, как движение по графу: в каждой его вершине производится вычисление простой функции (рис 9. а). Вычисление градиента представляется обратным движением (рис 9. б). Отсюда и термин: методы (алгоритмы) обратного распространения.
| а)
| б)
|
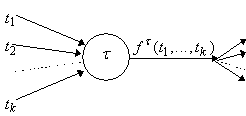

| Рис. 9. Прохождение вершины t в прямом (а) и обратном (б) направлении. |
Предлагается рассматривать обучение нейронных сетей как задачу оптимизации. Это означает, что весь арсенал методов оптимизации может быть испытан для обучения.
Существует, однако, ряд специфических ограничений. Они связаны с огромной размерностью задачи обучения. Число параметров может достигать 108 - и даже более. Уже в простейших программных имитаторах на персональных компьютерах подбирается 103 - 104 параметров.
Из-за высокой размерности возникает два требования к алгоритму:
1. Ограничение по памяти. Пусть n - число параметров. Если алгоритм требует затрат памяти порядка n2 ,то он вряд ли применим для обучения. Вообще говоря, желательно иметь алгоритмы, которые требуют затрат памяти порядка Kn, K=const.
0 комментариев