Разработано техническое задание на новую версию программы-нейроимитатора, реализующую предложенные технологии
Метод потенциальных функций [14] для решения задач классификации объектов с учителем
Возможность параллельного выполнения наиболее трудоемких этапов алгоритма и желательно - нейронной сетью
Методы, выполняющие цикл "элементарное упрощение – дообучение нейросети" до тех пор, пока дообучение приводит к решению задачи с требуемой точностью
Методы, не позволяющие задавать число контрастируемых элементов сети (методы, основанные на модификации штрафной функции)
Если функция кусочно-линейна, то кусочно-постоянные участки будут описываться условными правилами (п.3), а кусочно-линейные – функциональными (п.2)
Разработано техническое задание на новую версию программы-нейроимитатора, реализующую предложенные технологии
Навигация
Если функция кусочно-линейна, то кусочно-постоянные участки будут описываться условными правилами (п.3), а кусочно-линейные – функциональными (п.2)
Технология извлечения знаний из нейронных сетей: апробация, проектирование ПО, использование в психолингвистике
176148
знаков
8
таблиц
14
изображений
4. Если функция кусочно-линейна, то кусочно-постоянные участки будут описываться условными правилами (п.3), а кусочно-линейные – функциональными (п.2).
Видно, что требования пользователя к виду извлекаемых правил приводят к необходимости выполнения той или иной модификации нелинейной функции нейрона. Задаваемое ограничение на число сущностей (входных сигналов нейрона), учитываемых в левой части правила, приводит к необходимости проведения операции равномерного упрощения сети по входам нейронов, и.т.д. В случае, когда упрощение нейросети не выполнено или все же оставило некоторые избыточные элементы, возможно огрубление извлеченных из сети правил с одновременным сокращением их числа по сравнению с исходным числом правил. Критерием возможности проведения огрубления выступает точность решения задачи набором правил – если точность при огрублении не опускается ниже требуемой пользователем точности, то огрубление можно производить. Вот варианты огрубляющих операций:
1. В случае использования сигмоидной нелинейной функции можно даже при непрерывнозначных входных сигналах нейрона перейти к описанию активации нейрона в терминах высокой (+1 или иное значение в зависимости от конкретной нелинейной функции) или низкой (-1 или иное значение) активации. Для этого взвешенная сумма входных сигналов нейрона W1X1+W2X2+…+WnXn сравнивается со значением неоднородного входа нейрона W0 и при превышении значения активация нейрона считается положительной, а иначе – отрицательной. Т.е. формируется единственное правило вида IF (W1X1+ …+WnXn)>W0 THEN Y=Yвысокая ELSE Y=Yнизкая.
2. В случае сигмоидной функции возможно исследование вида функции распределения выходного сигнала нейрона и при многомодальном распределении возможен переход к квантованию величин активации по центрам кластеров [61,62].
3. Для k выделенных кластеров активации с центрами кластеров в точках Ui и k-1 граничными значениями активации Zij между кластерами i и j формируется правило в виде цепочки
IF (W1X1+ …+WnXn)<Z12 THEN Y=U1 ELSE IF (W1X1+ …+WnXn)<Z23 THEN Y=U2 ELSE … ELSE IF (W1X1+ …+WnXn)<Zk-2,k-1 THEN Y=Uk-1 ELSE Y=Uk.
4. При многомодальном распределении значений величин активации нейрона с сигмоидной, пороговой или кусочно-линейной функцией возможна проверка различных гипотез касательно статистических характеристик величин входных и промежуточных сигналов нейронной сети при различных делениях обучающей выборки на фрагменты. Это делает возможным замену некоторого числа продукционных правил на более простые правила. В качестве начальной нелинейной функции нейрона может быть рассмотрена любая функция, имеющая непрерывную первую производную. Каждой конкретной функции сопоставляется набор ее негладких аппроксимаций в зависимости от последующих требований семантики. Так, гауссова функция ![]() может быть в дальнейшем интерпретируема как нечеткая функция принадлежности и аппроксимируема прямоугольной, трапецеидальной или треугольной негладкой функцией. Соответственно этому меняются описывающие нейрон правила и схемы огрубления. Здесь можно сделать следующие выводы:
может быть в дальнейшем интерпретируема как нечеткая функция принадлежности и аппроксимируема прямоугольной, трапецеидальной или треугольной негладкой функцией. Соответственно этому меняются описывающие нейрон правила и схемы огрубления. Здесь можно сделать следующие выводы:
- Существует номенклатура видов извлекаемых из сети элементарных правил.
- Каждому виду извлекаемых правил можно сопоставить некоторый набор операций по упрощению сети, если из исходной сети этот вид элементарных правил не извлекается.
- Набор извлеченных элементарных правил далее можно преобразовать в меньшее число более гибких и высокоуровневых правил, поэтому не следует стремиться к первоначальному извлечению высокоуровневых правил, тем более что сопоставленные с последними упрощающие операции либо будут полностью соответствовать упрощающим операциям для получения заданного вида элементарных правил, либо их будет трудно ввести.
4.4. Приемы повышения вербализуемости нейронной сетиПод вербализуемостью сети и извлеченного из нее набора правил понимается понятность этих правил пользователю, если все заданные критерии к виду правил уже удовлетворены на этапе извлечения правил.
Вербализацию можно проводить на основе визуального графического представления структуры сети и/или текстуального представления набора правил, путем последовательного построения симптом-синдромной структуры возникающих новых понятий предметной области [22,23,48,58]. Входные сигналы сети являются входными симптомами, выходные сигналы нейронов первого слоя – синдромами первого уровня и одновременно симптомами для нейронов второго слоя, генерирующих синдромы второго уровня, и т.д.
Рассмотрим идеи, которые могут помочь в процессе извлечения знаний.
4.4.1. Добавление синдрома в набор входных симптомовОтдельные фрагменты сети будут достаточно просто интерпретируемы и правдоподобны с точки зрения пользователя, тогда как другим фрагментам пользователь может и не дать правдоподобной интерпретации. Поэтому поскольку интерпретированные синдромы могут быть в дальнейшем полезны, с точки зрения пользователя, для решения других задач предсказания и классификации на данной обучающей выборке, то пользователь может добавить к выборке одну или несколько новых переменных - значений этих синдромов. Затем можно снова попытаться решить исходную задачу на основе нового, увеличенного набора входных признаков. Полученная новая нейронная сеть окажется меньше по размеру, чем исходная и может быть более просто интерпретируемой [58].
Утверждение о более простой интерпретации опирается на следующий факт: в слоистой нейросети синдром зависит только от синдромов (симптомов) предыдущего уровня. Поэтому, если для синдрома некоторого уровня требуется сигнал не с предыдущего уровня, то сеть должна включать в себя цепочку элементов для передачи требуемого сигнала к данному синдрому. Эта цепочка строится, как несколько соединенных последовательно нейронов, что затрудняет интерпретацию. Вдобавок, на протяжении цепочки к ней могут "подключаться" другие сигналы. Если же для порождения синдрома доступен не только предыдущий уровень иерархии симптомов, но и все ранее полученные симптомы, то таких цепочек передачи информации создавать не придется.
Нейронная сеть с таким набором синапсов, что каждый входной сигнал сети и сигнал любого нейрона может подаваться на все нейроны следующих слоев, не формирует цепочек элементов для передачи информации через слои – эти элементы уже присутствуют в сети. Вдобавок, линии передачи информации являются простыми линейными связями, а не суперпозицией функций, вычисляемых нейронами. Однако при такой архитектуре число синапсов в сети становится очень большим по сравнению с числом синапсов в исходной слоистой сети, что удлиняет время приведения такой сети к логически прозрачному виду.
4.4.2. Построение иерархии продукционных правилТочность решения задачи нейронной сетью регулируется целевой функцией, вычисляющей невязку между выходными сигналами сети и сигналами, которые требуется получить. Чем ниже требуемая точность, тем более простая и более логически прозрачная сеть может решить задачу. Поэтому для задачи приведения сети к логически прозрачному виду надо устанавливать минимально необходимые требования к точности.
Не все примеры сеть может решить с одинаковой точностью – в таблице данных могут присутствовать примеры, которые с трудом решаются сетью в то время как остальные примеры сеть решает хорошо. Причиной этого может быть некорректность поставленной задачи. Например, в таблицу данных входят примеры трех классов, а делается попытка обучить сеть классификации на два класса. Другой причиной может быть, например, ошибка измерений.
Для того, чтобы обнаружить некорректность в данных (либо в постановке задачи), предлагается исключать из таблицы данных наиболее “трудные” примеры (примеры с наибольшим значением функции оценки). Если сеть обучается правильно решать задачу и упрощается до довольно простой структуры, то исключение примеров производить не надо – задача корректна. В противном случае можно предложить следующие варианты.
Зададимся требованием к числу правильно решенных примеров. Допустим, что нас устроит правильность решения 95% от общего числа примеров, присутствующих в таблице данных. Тогда построим процесс обучения и упрощения сети так, чтобы сеть, правильно решающая 95% примеров, считалась правильно обученной решать задачу и, соответственно, упрощалась с сохранением навыка решения 95% примеров. При упрощении сети примеры, входящие в состав 5% наиболее трудных, могут меняться. После завершения процесса упрощения, если в итоге получилась сеть, гораздо более простая, чем полученная для всего набора примеров логически прозрачная сеть, необходимо проанализировать наиболее трудные примеры – там могут встретиться ошибки в данных (см., например, [17], стр. 14) либо эти примеры “нетипичны” по сравнению с остальными.
Если же сеть с самого начала не может обучиться правильно решать задачу, то будем исключать из таблицы данных наиболее трудные примеры до тех пор, пока сеть не сможет обучиться. Далее надо исследовать статистические различия между набором оставшихся и исключенных данных – может обнаружиться, что отброшенные примеры образуют отдельный кластер. Так было при решении задачи нейросетевой постановки диагноза вторичного иммунодефицита по иммунологическим и метаболическим параметрам лимфоцитов. Только коррекция классификационной модели (из отброшенных данных сформировали третий класс в дополнение к двум изначально имевшимся) позволила обучить сеть правильно решать теперь уже измененную задачу ([17], стр. 15-16). Далее это даст более простой набор решающих правил, т.к. ранее сеть была вынуждена фактически запоминать обучающую выборку, а теперь классификационная модель соответствует естественной внутренней кластерной структуре объектов проблемной области.
Еще одна трудность может существовать при попытке решения задачи, для которой обратная задача некорректно поставлена в некоторых точках области определения – например, из-за того, что в этих точках происходит смена описывающей данные зависимости. В зависимости от уровня некорректности, на некотором наборе обучающих точек сеть будет давать большую ошибку обучения по сравнению с ошибкой на других точках. Исследование поведения частной производной выходного сигнала сети по входному сигналу помогает определять области некорректности как границы смены вида решения. Если границы решения совпадают с примерами выборки с большой ошибкой обучения, то это говорит о том, что некорректность действительно существует и исходная нейросеть не может аппроксимировать поведение фукнции в области некорректности с требуемой точностью. Требуемую точность можно достичь увеличением размера сети (с соответствующим усложнением процесса ее интерпретации), но это нежелательно. Поэтому предпочтительнее подход [53], связанный с переходом от единственной сети к набору малых сетей, каждая из которых работает внутри своей области определения, а выбор той или иной сети осуществляется с помощью набора условных правил, сравнивающих значения признаков примера выборки с границами решения.
Гибкое управление требуемой точностью решения примеров обучающей выборки или требуемым числом правильно решенных примеров позволяет предложить следующий механизм построения иерархической структуры правил вывода, от наиболее важных правил до уточняющих и корректирующих, как циклическое выполнение следующих этапов:
- обучение сети до распознавания заданного числа примеров обучающей выборки (или до решения всех примеров выборки с заданной точностью),
- упрощение сети,
- извлечение правил,
- фиксирование полученной минимальной структуры сети,
- возвращение в сеть удаленных на этапе упрощения элементов,
- увеличение требуемого числа правильно распознанных примеров (или усиление требований к точности) – на следующей итерации цикла это добавит к полученной минимальной структуре некоторое число элементов, которые и сформируют правила следующего уровня детализации.
4.4.3. Ручное конструирование сети из фрагментов нескольких логически прозрачных сетейПринципиально, что для одной и той же таблицы данных и различных сетей (либо одной сети, но с разной начальной случайной генерацией исходных значений набора настраиваемых параметров) после обучения, упрощения по единой схеме и вербализации может получиться несколько различных логически прозрачных сетей и, соответственно, несколько алгоритмов решения задачи. По конечной таблице данных всегда строится несколько полуэмпирических теорий или алгоритмов решения. Далее теории начинают проверяться и конкурировать между собой. Комбинируя фрагменты нескольких теорий, можно сконструировать новую теорию. В силу этого неединственность получаемого знания не представляется недостатком.
При вербализации некоторые синдромы достаточно осмысленны и естественны, другие, напротив, непонятны. Из набора логически прозрачных нейросетей можно отсеять несколько наиболее осмысленных синдромов, объединить их в новую нейронную сеть, при этом введя, если необходимо, некоторые дополнительные нейроны или синапсы для связывания этих фрагментов между собой. Полученная нейросеть после адаптации и упрощения может быть более понятна, чем любой из ее предков. Таким образом, неединственность полуэмпирических теорий может стать ценным инструментом в руках исследователей-когнитологов.
В отдельные программы-нейроимитаторы встроены специальные средства визуального конструирования нейросетей. Однако ручное конструирование сети с целью заложения в нее эмпирических экспертных знаний достаточно сложно и часто практически неприменимо.
Вместо конструирования нейросети "с нуля" будем конструировать ее из фрагментов других сетей. Для реализации такой возможности программа-нейроимитатор должна включать в себя достаточно развитый визуальный редактор нейронных сетей, позволяющий вырезать из сетей отдельные блоки, объединять их в новую сеть и дополнять сеть новыми элементами. Это одна из возможностей нейроимитатора NeuroPro (идея предложена лично автором работы).
Если в результате дообучения и упрощения новой сети понимаемость использованных при конструировании фрагментов не потеряна, то новый набор правил потенциально более понятен пользователю, чем каждый из начальных.
Естественно, что возможны различные стратегии обучения и контрастирования сконструированной сети: можно запрещать обучение (изменение параметров) и контрастирование фрагментов, из которых составлена сеть, и разрешать обучение и контрастирование только добавленных элементов. Можно разрешать только дообучать фрагменты, можно разрешать и их контрастирование. Все зависит от предпочтений пользователя программы-нейроимитатора.
Глава 5. Нейросетевой анализ структуры индивидуального пространства смыслов
5.1. Семантический дифференциалСлова осмысляются человеком не через "толковый словарь", а через ощущения, переживания. За каждым словом у человека стоит несколько этих базовых переживаний: собака - это что-то маленькое, добродушненькое, пушистое, с мокрым язычком, …, но это и здоровенный, грозно рычащий зверь со злобными глазами, огромными клыками, … . Большинство слов кодирует некоторые группы переживаний, ощущений, и определить смысл слова, то есть эти самые переживания – довольно сложная задача.
Дж. Осгуд с соавторами в работе под названием “Измерение значений” ввели для решения этой задачи метод “семантического дифференциала” (обзор литературы дан в работе [86]). Они предложили искать координаты слова в пространстве свойств следующим образом. Был собран некоторый набор слов (например, "мама", "папа" и т.д.) и набор признаков к этим словам (таких, как близкий - далекий, хороший - плохой, и т.д.), и опрашиваемые люди оценивали слова по этим шкалам. Затем отыскивался минимальный набор координат смысла, по которому можно восстановить все остальные. Было выделено 3 базовых координаты смысла, по которым все остальные можно предсказать достаточно точно: сильный - слабый, активный - пассивный и хороший - плохой. С другой стороны, выявились огромные различия между культурами, например, у японцев и американцев очень многие вещи имеют существенно разные смысловые характеристики.
Существуют различные способы выделения основных признаков (базовых координат), например, метод главных компонент, факторный анализ и др. В данной работе используются нейросетевые методы. Разработка технологии сокращения описания и извлечения знаний из данных с помощью обучаемых и разреживаемых нейронных сетей началась в 90-е годы XX века и к настоящему времени созданы библиотеки нейросетевых программ даже для PC, позволяющие строить полуэмпирические теории в различных областях.
В данной работе с помощью нейроимитатора исследовались индивидуальные смысловые пространства. Был создан вопросник, в котором определяются координаты (от –10 до 10) 40 слов по 27 параметрам и были проведены эксперименты на нескольких людях.
Слова:
1. Папа
2. Мама
3. Болезнь
4. Детский сад
5. Школа
6. Собака
7. Кот
8. Воробей
9. Ворона
10.Апельсин
11.Яблоко
12.Дед Мороз
13.Дерево
14.Змея
15.Еда
16.Тортик
17.Горшок
18.Брат
19.Сестра
20.Работа
21.Деньги
22.Квартира
23.Муж (жена)
24.Дедушка
25.Бабушка
26.Музыка
27.Президент
28.Парламент
29.Политика
30.Наука
31.Политик
32.Ученый
33.Теорема
34.Выборы
35.Коммунизм
36.Доказательство
37.Россия
38.Америка
39.Китай
40.Израиль
41.Религия
42.Бог
1. Плотный – рыхлый
2. Молодой – старый
3. Светлый – темный
4. Разумный – неразумный
5. Холодный – горячий
6. Быстрый – медленный
7. Близкий – далекий
8. Пугливый – бесстрашный
9. Страшный – не страшный
10.Спокойный – беспокойный
11.Веселый – грустный
12.Удобный – неудобный
13.Красивый – некрасивый
14.Опасный – безопасный
15.Приятный – неприятный
16.Ручной – дикий
17.Утонченный – грубый
18.Умный – глупый
19.Шумный – тихий
20.Ласковый – грубый
21.Большой – маленький
22.Дружественный – враждебный
23.Мягкий – твердый
24.Добрый – злой
25.Активный – пассивный
26.Хороший – плохой
27.Сильный – слабый
В экспериментах отыскивался минимальный набор координат смысла, по которому можно восстановить все остальные с точностью до тенденции (т.е. с точностью до 3 баллов). Это делалось при помощи нейросетевого имитатора NeuroPro. Следует отметить, что предсказание с точностью до 3 баллов фактически соответствует переходу от 21-балльных шкал (от –10 до 10) к традиционным 7-балльным (от –3 до 3).
С помощью NeuroPro возможно получение показателей значимости входных сигналов для принятия нейросетью решения, показателей чувствительности выходного сигнала сети к изменению входных сигналов, показателей значимости и чувствительности по отдельным примерам выборки.
За начальную архитектуру была взята слоистая нейронная сеть, состоящая из трех слоев по 10 нейронов в каждом. Далее проводились последовательно следующие операции.
1) Обучение нейронной сети с максимальной допустимой ошибкой обучения 0.49 балла (такая ошибка приводит к тому, что после округления ошибка обучения фактически равна 0). Как показал опыт, такой ошибки обучения чаще всего достаточно для предсказаний с требуемой точностью, то есть для ошибки обобщения, меньшей 3 баллов.
2) Из входных сигналов выбирался наименее значимый и исключался, после чего проводилось повторное обучение нейросети с новыми входными сигналами и прежней ошибкой обучения.
Эта процедура проводилась до тех пор, пока нейросеть могла обучиться. В результате этих операций были получены минимальные определяющие наборы признаков (т.е. наборы входных сигналов, оставшиеся после сокращения их числа).
Для разных людей получены очень разные результаты (первые результаты представлены в [87]), совсем непохожие на результаты Осгуда. Вот типичные примеры:
Определяющий набор признаков 1-го человека (размерность 7):
Умный – глупый, шумный – тихий, разумный – неразумный, плотный – рыхлый, дружественный – враждебный, страшный – не страшный, опасный – безопасный.
2-го человека: сильный – слабый, приятный – неприятный, опасный – безопасный, страшный – не страшный, дружественный – враждебный, удобный – неудобный (размерность 6).
3-го человека: приятный – неприятный, опасный – безопасный (размерность 2). Представляет интерес, что Осгудовские признаки почти не представлены в большинстве наборов. В связи с этим было решено проверить, можно ли предсказать значения произвольно выбранных признаков при помощи набора Осгуда (ошибка обучения в экспериментах допускалась ±0.49 балла). Практически во всех случаях нейронные сети обучались с приемлемой ошибкой обучения, но ошибка обобщения в экспериментах со скользящим контролем (нейронные сети обучались по всем словам, кроме 2-х – 3-х, а потом тестировались на этих словах) часто была недопустимо велика (5-9 баллов). После этого проводились следующие эксперименты: нейронная сеть обучалась предсказывать значения параметров по уже определенному минимальному набору признаков на одной половине слов, далее она тестировалась на словах из другой половины.
При этом для большинства слов нейронные сети давали удовлетворительные прогнозы по всем параметрам (с точностью до 3 баллов), но почти во всех случаях обнаруживались одно - два слова, для которых сразу по нескольким признакам ошибка нейронных сетей была очень велика.
5.2. MAN-многообразияИтак, для каждого человека обнаруживается многообразие сравнительно малой размерности, в небольшой окрестности которого лежат почти все слова.
При осмыслении этого возникает гипотеза, связанная с тем, что отношение человека к большинству вещей, событий и т.д. не индивидуально, а сформировано культурой, в которой этот человек рос, его окружением и поэтому зависит от сравнительно небольшого числа признаков. В связи с этим и могли появиться многообразия малой размерности, в небольшой окрестности которых лежат почти все слова. Назовем их ман–многообразиями (от немецкого неопределенного местоимения man (некто)). Вероятно, для каждой определенной культуры имеется небольшое количество различных ман-многообразий, специфичных для нее. В ходе воспитания человек присваивает одно из типичных ман–многообразий. Например, определяющий набор признаков 3-го человека представляется основным набором признаков и для животных: опасность и приятность имеют прямой химический аналог и соответствуют уровню адреналина, эндорфинов и энкефалинов.
Обнаружено, что у большинства людей есть слова, которые неожиданно "выпадают" из ман-многообразий, ‑ отстоят от них довольно далеко. Вероятно, это слова, с которыми у человека связаны какие-либо сильные переживания, ощущения, что приводит к появлению "индивидуальности" оценки или же слова, свое истинное отношение к которым человек пытается скрыть. Есть еще один тип таких точек, специфичных для каждой отдельной культуры (или субкультуры), особое отношение к которым сформировано самой культурой (например, в России – Великая Отечественная, в мусульманских странах – бог). Интерпретация "индивидуальных точек" может дать полезную психодиагностическую информацию, а анализ особенных точек культуры - культурологическую. Возможно проведение культурологических исследований путем сравнения особенностей и закономерностей для различных культур.
Уже первые опыты показывают, что набор индивидуальных точек дает яркий и узнаваемый портрет личности, а общекультурные особенности пока не были изучены, так как требуют более масштабных исследований.
В перспективе результаты работы могут быть использованы во многих областях, где требуется информация о психологии и психическом здоровье человека, могут быть применены для создания компьютерных психодиагностических методик, выявляющих и анализирующих индивидуальные особенности и скрытые напряжения и т.п.
Литература
1. Лорьер Ж.-Л. Системы искусственного интеллекта. М.: Мир, 1991. - 568с.
2. Искусственный интеллект. В 3-х кн. Кн. 2. Модели и методы: Справочник / Под ред. Д.А.Поспелова. М.: Радио и связь, 1990. - 304с.
3. Хафман И. Активная память. М.: Прогресс. 1986. - 309с.
4. Бонгард М.М. Проблема узнавания. М.: Наука, 1967. - 320с.
5. Загоруйко Н.Г. Методы обнаружения закономерностей. М.: Наука, 1981. - 115с.
6. Гаек П., Гавранек Т. Автоматическое образование гипотез. М.: Наука, 1984. - 278с.
7. Гуревич Ю.В., Журавлев Ю.И. Минимизация булевых функций и и эффективные алгоритмы распознавания // Кибернетика. - 1974, №3. - с.16-20.
8. Искусственный интеллект. В 3-х кн. Кн. 1. Системы общения и экспертные системы: Справочник / Под ред. Э.В.Попова. М.: Радио и связь, 1990. - 464с.
9. Айвазян С.А., Енюков И.С., Мешалкин Л.Д. Прикладная статистика: Основы моделирования и первичная обработка данных. М.: Финансы и статистика, 1983. - 471с.
10.Загоруйко Н.Г. Гипотезы компактности и l-компактности в алгоритмах анализа данных // Сибирский журнал индустриальной математики. Январь-июнь, 1998. Т.1, №1. - с.114-126.
11.Браверман Э.М., Мучник И.Б. Структурные методы обработки эмпирических данных. М.: Наука, 1983. - 464с.
12.Дуда Р., Харт П. Распознавание образов и анализ сцен. М.: Мир, 1976. - 512с.
13.Цыпкин Я.З. Информационная теория идентификации. М.: Наука, 1995. - 336с.
14.Айзерман М.А., Браверман Э.М., Розоноер Л.И. Метод потенциальных функций в теории обучения машин. - М.: Наука, 1970. - 240с.
15.Россиев Д.А. Самообучающиеся нейросетевые экспертные системы в медицине: теория, методология, инструментарий, внедрение. Автореф. дисс. … доктора биол. наук. Красноярск, 1996.
16.Горбань А.Н. Обучение нейронных сетей. М.: изд. СССР-США СП "ParaGraph", 1990. - 160с. (English Translation: AMSE Transaction, Scientific Siberian, A, 1993, Vol. 6. Neurocomputing, рp.1-134).
17.Горбань А.Н., Россиев Д.А. Нейронные сети на персональном компьютере. Новосибирск: Наука, 1996. - 276с.
18.Нейроинформатика / А.Н. Горбань, В.Л. Дунин-Барковский, А.Н. Кирдин и др. Новосибирск: Наука, 1998. - 296с.
19.Ежов А.А., Шумский С.А. Нейрокомпьютинг и его применение в финансах и бизнесе. М.: МИФИ, 1998.
20.Миркес Е.М. Нейрокомпьютер: проект стандарта. Новосибирск, Наука, 1998.
21.Kwon O.J., Bang S.Y. A Design Method of Fault Tolerant Neural Networks / Proc. ICNN 1994, Seoul, Korea. - Vol.1. - pp. 396-400.
22.Горбань А.Н., Царегородцев В.Г. Методология производства явных знаний из таблиц данных при помощи обучаемых и упрощаемых искусственных нейронных сетей // Труды VI Международной конференции "Математика. Компьютер. Образование" / - М.: Прогресс-традиция, 1999. - Ч.I. - С.110-116.
23.Царегородцев В.Г. Извлечение явных знаний из таблиц данных при помощи обучаемых и упрощаемых искусственных нейронных сетей // Материалы XII Международной конференции по нейрокибернетике. - Ростов-на-Дону. Изд-во СКНЦ ВШ. 1999.- 323с. - С.245-249.
24.Reed R. Pruning Algorithms - a Survey / IEEE Trans. on Neural Networks, 1993, Vol.4, №5. - pp.740-747.
25.Depenau J., Moller M. Aspects of Generalization and Pruning / Proc. WCNN'94, 1994, Vol.3. - pp.504-509.
26.Гилев С.Е., Коченов Д.А., Миркес Е.М., Россиев Д.А. Контрастирование, оценка значимости параметров, оптимизация их значений и их интерпретация в нейронных сетях // Доклады III Всероссийского семинара “Нейроинформатика и ее приложения”. – Красноярск, 1995.- С.66-78.
27.Weigend A.S., Rumelhart D.E., Huberman B.A. Generalization by Weights-elimination with Application to Forecasting / Advances in Neural Information Processing Systems. Morgan Kaufmann, 1991. Vol.3. - pp. 875-882.
28.Yasui S. Convergence Suppression and Divergence Facilitation for Pruning Multi-Output Backpropagation Networks / Proc. 3rd Int. Conf. on Fuzzy Logic, Neural Nets and Soft Computing, Iizuka, Japan, 1994. - pp.137-139.
29.Yasui S. A New Method to Remove Redundant Connections in Backpropagation Neural Networks: Inproduction of 'Parametric Lateral Inhibition Fields' / Proc. IEEE INNS Int. Joint Conf. on Neural Networks, Beijing, Vol.2. - pp.360-367.
30.Yasui S., Malinowski A., Zurada J.M. Convergence Suppression and Divergence Facilitation: New Approach to Prune Hidden Layer and Weights in Feedforward Neural Networks / Proc. IEEE Int. Symposium on Circuits and Systems 1995, Seattle, WA, USA. Vol.1. - pp.121-124.
31.Malinowski A., Miller D.A., Zurada J.M. Reconciling Training and Weight Suppression: New Guidelines for Pruning-efficient Training / Proc. WCNN 1995, Washington, DC, USA. Vol.1. - pp.724-728.
32.Krogh A., Hertz J. A Simple Weight Decay can Improve Generalization / Advances in Neural Infromation Processing Systems 4, 1992. - pp. 950-957.
33.Kamimura R., Nakanishi S. Weight-decay as a Process of Redundancy Reduction / Proc. WCNN, 1994, Vol.3. - pp.486-489.
34.Karnin E.D. A Simple Procedure for Pruning Back-propagation Trained Network / IEEE Trans. on Neural Networks, June 1990. Vol. 1, No.2. - pp.239-242.
35.Le Cun Y., Denker J.S., Solla S.A. Optimal Brain Damage / Advances in Neural Information Processing Systems 2. - Morgan Kaufmann, 1990. - pp.598-605.
36.Hassibi B., Stork D.G., Wolff G. Optimal Brain Surgeon: Extensions and Performance Comparisions / Advances in Neural Information Processing Systems 6, 1994. – pp.263-270.
37.Гилев С.Е. Алгоритм сокращения нейронных сетей, основанный на разностной оценке вторых производных целевой функции // Нейроинформатика и ее приложения : Тезисы докладов V Всеросс. семинара, 1997. Красноярск. КГТУ. 1997. - 190с. - C.45-46.
38.Tanpraset C., Tanpraset T., Lursinsap C. Neuron and Dendrite Pruning by Synaptic Weight Shifting in Polynomial Time / Proc. IEEE ICNN 1996, Washington, DC, USA. Vol.2. - pp.822-827.
39.Kamimura R. Principal Hidden Unit Analysis: Generation of Simple Networks by Minimum Entropy Method / Proc. IJCNN 1993, Nagoya, Japan. - Vol.1. - pp.317-320.
40.Mozer M.C., Smolensky P. Using Relevance to Reduce Network Size Automatically / Connection Science. 1989. Vol.1. - pp.3-16.
41.Mozer M.C., Smolensky P. Skeletonization: A Technique for Trimming the Fat from a Network via Relevance Assessment / Advances in Neural Network Information Processing Systems 1, Morgan Kaufmann, 1989. - pp.107-115.
42.Watanabe E., Shimizu H. Algorithm for Pruning Hidden Units in Multi Layered Neural Network for Binary Pattern Classification Problem / Proc. IJCNN 1993, Nagoya, Japan. - Vol.1. - pp.327-330.
43.Yoshimura A., Nagano T. A New Measure for the Estimation of the Effectiveness of Hidden Units / Proc. Annual Conf. JNNS, 1992. - pp.82-83.
44.Murase K., Matsunaga Y., Nakade Y. A Back-propagation Algorithm which Automatically Determines the Number of Association Units / Proc. IJCNN, Singapore, 1991. - Vol.1. - pp.783-788.
45.Matsunaga Y., Nakade Y., Yamakawa O., Murase K, A Back-propagation Algorithm with Automatic Reduction of Association Units in Multi-layered Neural Network / Trans. on IEICE, 1991. Vol. J74-DII, №8. - pp.1118-1121.
46.Hagiwara M. Removal of Hidden Units and Weights for Back Propagation Networks / Proc. IJCNN 1993, Nagoya, Japan. - Vol.1. - pp.351-354.
47.Majima N., Watanabe A., Yoshimura A., Nagano T. A New Criterion "Effectiveness Factor" for Pruning Hidden Units / Proc. ICNN 1994, Seoul, Korea. - Vol.1. - pp. 382-385.
48.Царегородцев В.Г. Производство полуэмпирических знаний из таблиц данных с помощью обучаемых искусственных нейронных сетей // Методы нейроинформатики. – Красноярск: Изд-во КГТУ, 1998. - 205c. - C.176-198.
49.Sietsma J., Dow R.J.F. Neural Net Pruning - Why and How / Proc. IEEE IJCNN 1988, San Diego, CA. Vol.1. - pp. 325-333.
50.Sietsma J., Dow R.J.F. Creating Artificial Neural Network that Generalize / Neural Networks, 1991. Vol.4, No.1. - pp.67-79.
51.Yamamoto S., Oshino T., Mori T., Hashizume A., Motoike J. Gradual Reduction of Hidden Units in the Back Propagation Algorithm, and its Application to Blood Cell Classification / Proc. IJCNN 1993, Nagoya, Japan. - Vol.3. - pp.2085-2088.
52.Sarle W.S. How to measure importance of inputs? SAS Institute Inc., Cary, NC, USA, 1999. ftp://ftp.sas.com/pub/neural/importance.html
53.Goh T.-H. Semantic Extraction Using Neural Network Modelling and Sensitivity Analisys / Proc. IJCNN 1993, Nagoya, Japan. - Vol.1. - pp.1031-1034.
54.Howlan S.J., Hinton G.E. Simplifying Neural Network by Soft Weight Sharing / Neural Computations, 1992. Vol.4. №4. - pp.473-493.
55.Keegstra H., Jansen W.J., Nijhuis J.A.G., Spaanenburg L., Stevens H., Udding J.T. Exploiting Network Redundancy for Low-Cost Neural Network Realizations / Proc. IEEE ICNN 1996, Washington, DC, USA. Vol.2. - pp.951-955.
56.Chen A.M., Lu H.-M., Hecht-Nielsen R. On the Geometry of Feedforward Neural Network Error Surfaces // Neural Computations, 1993. - 5. pp. 910-927.
57.Гордиенко П. Стратегии контрастирования // Нейроинформатика и ее приложения : Тезисы докладов V Всероссийского семинара, 1997 / Под ред. А.Н.Горбаня. Красноярск. КГТУ. 1997. - 190с. - C.69.
58.Gorban A.N., Mirkes Ye.M., Tsaregorodtsev V.G. Generation of explicit knowledge from empirical data through pruning of trainable neural networks / Int. Joint Conf. on Neural Networks, Washington, DC, USA, 1999.
59.Ishibuchi H., Nii M. Generating Fuzzy If-Then Rules from Trained Neural Networks: Linguistic Analysis of Neural Networks / Proc. 1996 IEEE ICNN, Washington, DC, USA. Vol.2. - pp.1133-1138.
60.Lozowski A., Cholewo T.J., Zurada J.M. Crisp Rule Extraction from Perceptron Network Classifiers / Proc. 1996 IEEE ICNN, Washington, DC, USA. Plenary, Panel and Special Sessions Volume. - pp.94-99.
61.Lu H., Setiono R., Liu H. Effective Data Mining Using Neural Networks / IEEE Trans. on Knowledge and Data Engineering, 1996, Vol.8, №6. – pp.957-961.
62.Duch W., Adamczak R., Grabczewski K. Optimization of Logical Rules Derived by Neural Procedures / Proc. 1999 IJCNN, Washington, DC, USA, 1999.
63.Duch W., Adamczak R., Grabczewski K. Neural Optimization of Linguistic Variables and Membership Functions / Proc. 1999 ICONIP, Perth, Australia.
64.Ishikawa M. Rule Extraction by Successive Regularization / Proc. 1996 IEEE ICNN, Washington, DC, USA. Vol.2. - pp.1139-1143.
65.Sun R., Peterson T. Learning in Reactive Sequential Decision Tasks: the CLARION Model / Proc. 1996 IEEE ICNN, Washington, DC, USA. Plenary, Panel and Special Sessions Volume. - pp.70-75.
66.Gallant S.I. Connectionist Expert Systems / Communications of the ACM, 1988, №31. – pp.152-169.
67.Saito K., Nakano R. Medical Diagnostic Expert System Based on PDP Model / Proc. IEEE ICNN, 1988. – pp.255-262.
68.Fu L.M. Rule Learning by Searching on Adapted Nets / Proc. AAAI, 1991. - pp.590-595.
69.Towell G., Shavlik J.W. Interpretation of Artificial Neural Networks: Mapping Knowledge-based Neural Networks into Rules / Advances in Neural Information Processing Systems 4 (Moody J.E., Hanson S.J., Lippmann R.P. eds.). Morgan Kaufmann, 1992. - pp. 977-984.
70.Fu L.M. Rule Generation From Neural Networks / IEEE Trans. on Systems, Man. and Cybernetics, 1994. Vol.24, №8. - pp.1114-1124.
71.Yi L., Hongbao S. The N-R Method of Acquiring Multi-step Reasoning Production Rules Based on NN / Proc. 1996 IEEE ICNN, Washington, DC, USA. Vol.2. - pp.1150-1155.
72.Towell G., Shavlik J.W., Noodewier M.O. Refinement of Approximately Correct Domain Theories by Knowledge-based Neural Networks / Proc. AAAI'90, Boston, MA, USA, 1990. - pp.861-866.
73.Towell G., Shavlik J.W. Extracting Refined Rules from Knowledge-based Neural Networks / Machine Learning, 1993. Vol.13. - pp. 71-101.
74.Towell G., Shavlik J.W. Knowledge-based Artificial Neural Networks / Artificial Intelligence, 1994. Vol.70, №3. - pp.119-165.
75.Opitz D., Shavlik J. Heuristically Expanding Knowledge-based Neural Networks / Proc. 13 Int. Joint Conf. on Artificial Intelligence, Chambery, France. Morgan Kaufmann, 1993. - pp.1360-1365.
76.Opitz D., Shavlik J. Dynamically Adding Symbolically Meaningful Nodes to Knowledge-based Neural Networks / Knowledge-based Systems, 1995. - pp.301-311.
77.Craven M., Shavlik J. Learning Symbolic Rules Using Artificial Neural Networks / Proc. 10 Int. Conf. on Machine Learning, Amherst, MA, USA. Morgan Kaufmann, 1993. - pp.73-80.
78.Craven M., Shavlik J. Using Sampling and Queries to Extract Rules from Trained Neural Networks / Proc. 11 Int. Conf. on Machine Learning, New Brunswick, NJ, USA, 1994. - pp.37-45.
79.Medler D.A., McCaughan D.B., Dawson M.R.W., Willson L. When Local int't Enough: Extracting Distributed Rules from Networks / Proc. 1999 IJCNN, Washington, DC, USA, 1999.
80.Craven M.W., Shavlik J.W. Extracting Comprehensible Concept Representations from Trained Neural Networks / IJCAI Workshop on Comprehensibility in Machine Learning, Montreal, Quebec, Canada, 1995.
81.Andrews R., Diederich J., Tickle A.B. A Survey and Critique of Techniques for Extracting Rules from Trained Artificial Neural Networks / Knowledge Based Systems, 1995, №8. - pp.373-389.
82.Craven M.W., Shavlik J.W. Using Neural Networks for Data Mining / Future Generation Computer Systems, 1997.
83.Craven M.W., Shavlik J.W. Rule Extraction: Where Do We Go From Here? Department of Computer Sciences, University of Wisconsin, Machine Learning Research Group Working Paper 99-1. 1999.
84.Michalski R.S. A Theory and Methodology of Inductive Learning / Artificial Intelligence, 1983, Vol.20. – pp.111-161.
85.McMillan C., Mozer M.C., Smolensky P. The Connectionist Scientist Game: Rule Extraction and Refinement in a Neural Network / Proc. XIII Annual Conf. of the Cognitive Science Society, Hillsdale, NJ, USA, 1991. Erlbaum Press, 1991.
86.Language, meaning and culture: the selected papers of C. E. Osgood / ed. by Charles. E. Osgood and Oliver C. S. Tzeng. New York (etc.) : Praeger, 1990 XIII, 402 S.
87.Горбань П.А. Нейросетевая реализация метода семантического дифференциала и анализ выборов американских президентов, основанный на технологии производства явных знаний из данных // Материалы XXXVII Международной научной студенческой конференции "Cтудент и научно-технический прогресс": Информационные технологии. Новосибирск, НГУ, 1999
Публикации автора по теме диплома1. Горбань П.А. Нейросетевой анализ структуры индивидуального пространства смыслов. "Нейрокомпьютеры": разработка, применение. 2002, No 4. С. 14-19.
2. Горбань П.А., Царегородцев В.Г. Как определить одни признаки, существенные для исходов президентских выборов в США, через другие? (пример применения нейросетевой технологии анализа связей) // Тезисы VI международной конференции "Математика. Компьютер. Образование". (25-30 января 1999 г. в г.Пущино). (Электронная версия: http:// www.biophys.msu.ru/ scripts/ trans.pl/rus/ cyrillic/ awse/ CONFER/ MCE99/ 072.htm )
3. Gorban P.A. Relations between Social, Economic and Political Traits of USA Political Situation. Abstract: USA-NIS Neurocomputing Opportunities Workshop, Washington, DC, July 12-17, 1999. http:// phy025.lubb.ttuhsc.edu/ wldb/ Witali/ WWW/ P2_2.htm
4. Горбань П.А. Демонстрация возможностей нейроимитатора NeuroPro 1.0 на примере выборов американских президентов. Материалы 6 Всероссийского семинара "Нейроинформатика и ее приложения" (2-4 октября 1998 г., Красноярск). Красноярск, изд. КГТУ. С. 43.
5. Горбань П.А. Нейросетевой анализ структуры индивидуального пространства смыслов Материалы 7 Всероссийского семинара "Нейроинформатика и ее приложения" (1-3 октября 1999 г., Красноярск). Красноярск, изд. КГТУ. С. 34-36.
6. Горбань П.А. Нейросетевая реализация метода семантического дифференциала и анализ выборов американских президентов, основанный на технологии производства явных знаний из данных // Материалы 37 Международной конференции "Студент и научно-технический прогресс" (Новосибирск, апрель 1999). Новосибирск: изд. НГУ, 1999. С. 43.
Благодарности
Автор благодарен своему научному руководителю, всем сотрудника группы "Нейрокомп" и, в особенности, В.Г. Царегородцеву за внимание к работе, поддержку и разрешение использовать результаты совместных работ в дипломе. Я существенно использовал в дипломной работе описание программы «НейроПро» (В.Г. Царегородцев), технический отчет с обзором экспертных систем (А. Батуро), а также лекции проф. А.Н. Горбаня по нейронным сетям.
Приложение 1. Плакаты для защиты диплома.
ТЕХНОЛОГИЯ ИЗВЛЕЧЕНИЯ ЗНАНИЙ ИЗ НЕЙРОННЫХ СЕТЕЙ:
¨ АПРОБАЦИЯ,
¨ ПРОЕКТИРОВАНИЕ ПО,
¨ ИСПОЛЬЗОВАНИЕ В ПСИХОЛИНГВИСТИКЕ
ЦЕЛЬ РАБОТЫ¨ апробация гибкой технологии извлечения знаний из нейронных сетей, настраиваемой с учетом предпочтений пользователя;
¨ тестирование, пробная эксплуатация и разработка новой версии программных средств, реализующих данную технологию;
¨ проведение исследований индивидуальных пространств смыслов на основе данной технологии.
ОСНОВНЫЕ ЗАДАЧИ РАБОТЫ
¨ анализ разработанных методов извлечения явных знаний из нейронных сетей с указанием их ограничений и областей применимости;
¨ апробация гибкой настраиваемой на основе предпочтений пользователя технологии извлечения знаний, опирающейся на предварительное проведение комплексного упрощения нейронной сети, выполняющегося с учетом сформированных пользователем требований к результирующему виду извлекаемых знаний;
¨ тестирование, пробная эксплуатация и разработка новой версии программных средств, реализующих данную технологию;
¨ усовершенствование метода семантического дифференциала Осгуда при помощи технологии разреживания обучаемых нейронных сетей.
НЕЙРОНЫ, СЕТИ, ОБУЧЕНИЕ

Формальный нейрон
|
Слоистая сеть |
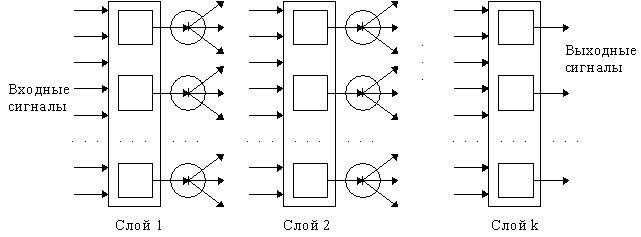
ОБУЧЕНИЕ – МИНИМИЗАЦИЯ ОШИБКИ НА ПРИМЕРАХ С ИЗВЕСТНЫМ ОТВЕТОМ
МЕТОДЫ (АЛГОРИТМЫ)
ОБРАТНОГО РАСПРОСТРАНЕНИЯ
Вычисление сложной функции многих переменных представим, как движение по графу: в каждой его вершине производится вычисление простой функции (рис. а).
Вычисление градиента (для оптимизации) представляется обратным движением (рис. б).
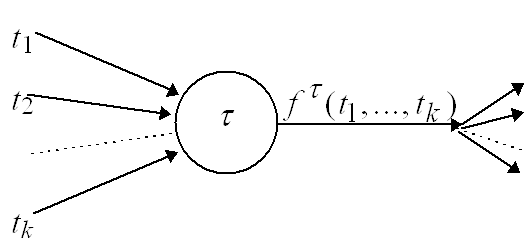
Рис. а. Прохождение вершины t в прямом направлении.

Рис. б. Прохождение вершины t в обратном направлении.
|
|

Схематическое представление вычисления сложной функции одного переменного и ее производных.
ЗАДАЧА ИЗВЛЕЧЕНИЯ ЗНАНИЙ ИЗ НЕЙРОННОЙ СЕТИвырезание "всего лишнего"
нейросеть логически прозрачная нейросеть
данные неявные знания явные знания
Нейросеть в ходе обучения формирует неявные знания, в ходе упрощения сети достигается логически прозрачная структура сети, удовлетворяющая некоторым заданным требованиям, и по ней сети возможно записать правила принятия решения в явном виде.
Результатом процесса извлечения знаний должен являться набор правил, который с заданной точностью решает заданное число примеров обучающей выборки
ЗНАЧИМОСТЬ И УПРОЩЕНИЕ
Показатели значимости – оценки изменения значения штрафной функции после некоторой модификации нейросети.
Показатели значимости нулевого порядка, основаны на рассмотрении абсолютной величины веса синапса.
Показатели значимости первого порядка оценивают по линейному приближению изменение значения штрафной функции после модификации.
Показатели значимости второго порядка используют второе тейлоровское приближение изменения штрафной функции после модификации.
КРИТЕРИИ ЛОГИЧЕСКОЙ ПРОЗРАЧНОСТИ
1. Чем меньше слоев нейронов в сети, тем сеть более логически прозрачна. В более сложных случаях: чем меньше нейронов в каждом из имеющихся путей прохождения сигналов в сети от входа к выходу, тем лучше.
2. Чем меньше число нейронов в каждом слое сети, тем лучше.
3. Чем меньше входных сигналов сети, тем лучше.
4. Чем меньше число приходящих на нейрон сигналов, тем лучше.
5. Чем меньше общее число синапсов в сети, тем лучше.
6. Необходимо приведение значений настраиваемых параметров сети к конечному набору выделенных значений.
Упрощение (контрастирование) нейронной сети строится как последовательный процесс исключения из сети наименее значимого элемента, уменьшающий нужный показатель, и дальнейшего подучивания сети. Если после шага упрощения невозможно доучивание сети до требуемой точности, то возвращаемся к сети, полученной на предыдущем шаге, и завершаем процесс упрощения.
МЕТОД СЕМАНТИЧЕСКОГО ДИФФЕРЕНЦИАЛА
Слова осмысляются человеком не через "толковый словарь", а через ощущения, переживания. Определить смысл слова – значит выделить этот комплекс переживаний. Путь к смыслу через качественные признаки понятия.
ГИПОТЕЗА ОСГУДА –
СУЩЕСТВУЮТ КООРДИНАТЫ СМЫСЛА:
все существенные свойства понятия определяются на основании небольшого числа базисных свойств
| ||||||||||
 | ||||||||||
|
Основной базис Осгуда:
Оценка («Хороший-Плохой»),
Сила («Сильный-Слабый»),
Активность («Активный-Пассивный»)
ОТЛИЧИЕ НАШЕЙ ПОСТАНОВКИ ОТ ЗАДАЧИ ОСГУДА
| У Осгуда | У нас |
| Ищется базис для всех носителей языка («Средний базис»). | Ищется базис для индивидуального носителя языка («Базис индивидуальных смыслов»). |
| Ищутся линейные связи. | Ищутся нелинейные связи (параметр, характеризующий регулярность связи – число нейронов). |
| У Осгуда признаки, не восстанавливаемые по базисным, выбрасываются, как незначимые. | У нас объекты, признаки которых не удается восстановить, рассматриваются как особые, характеризующие индивидуальные отклонения («психоаналитические»). |
| У Осгуда | У нас |
| Пространство смыслов трехмерно, ошибка предсказания свойств велика. | Размерность пространства смыслов индивидуальна, само пространство есть объединение типового MAN-многообразия с небольшим числом точек «психоаналитических» больших отклонений. Именно их наличие не позволяет дать точное «трехмерное» (среднекультурное) предсказание. |
КООРДИНАТЫ И ОСОБЫЕ ТОЧКИ ИНДИВИДУАЛЬНЫХ СМЫСЛОВЫХ ПРОСТРАНСТВ
Определяющий набор признаков 1-го человека (размерность 7):
Умный – глупый
Шумный – тихий
Разумный – неразумный
Плотный – рыхлый
Дружественный–враждебный
Страшный – не страшный
Опасный – безопасный.
Исключения: горшок, теорема, наука, деньги
2-го человека (размерность 6):
Сильный – слабый
Приятный – неприятный
Опасный – безопасный
Страшный – не страшный
Дружественный–враждебный
Удобный – неудобный.
Исключения: работа, жена, наука, деньги, тортик
3-го человека (размерность 2):
Приятный – неприятный
Опасный – безопасный.
Исключения: нет
ОСНОВНЫЕ РЕЗУЛЬТАТЫ РАБОТЫ, ПОЛУЧЕННЫЕ ЛИЧНО АВТОРОМ
1. Предложены следующие приемы, упрощающие и делающие более гибким процесс вербализации (семантического анализа – осмысления в терминах проблемной области) извлеченного из сети набора правил:
a) На основе гипотезы о неединственности извлекаемых правил и учитывая, что разные фрагменты сети (поднаборы правил) будут более или менее правдоподобны и интерпретируемы, предложено конструирование новой, более понятной пользователю нейронной сети из наиболее просто интерпретируемых фрагментов других сетей, решающих ту же задачу.
b) Предложено добавление выходного сигнала некоторого фрагмента сети (содержательно интерпретируемого и правдоподобного с точки зрения пользователя) в качестве нового интегрального признака в число независимых признаков таблицы данных, и решение задачи извлечения знаний на основе полученного расширенного набора признаков.
0 комментариев