Навигация
Одновременный учет всех независимых переменных. Результаты представлены в таблице 8
51022
знака
14
таблиц
7
изображений
1. Одновременный учет всех независимых переменных. Результаты представлены в таблице 8
Таблица 8. Classification Results(a)
| Y | Predicted Group Membership | Total | |||
| 0 | 1 | |||||
| Original | Count | 0 | 218 | 82 | 300 |
| 1 | 188 | 512 | 700 | |||
| % | 0 | 72,7 | 27,3 | 100,0 | ||
| 1 | 26,9 | 73,1 | 100,0 | |||
a 73,0% of original grouped cases correctly classified.
В таблице 9 приведены коэффициенты дискриминантной функции
Таблица 9. Canonical Discriminant Function Coefficients
| Function | ||
| 1 | |
| Z1 | ,503 | |
| Z2 | -,127 | |
| Z3 | ,338 | |
| Z4 | ,024 | |
| Z5 | -,150 | |
| Z6 | ,174 | |
| Z7 | ,134 | |
| Z8 | -,242 | |
| Z9 | ,225 | |
| Z10 | ,314 | |
| Z11 | -,006 | |
| Z12 | -,172 | |
| Z13 | ,035 | |
| Z14 | ,242 | |
| Z15 | ,272 | |
| Z16 | -,210 | |
| Z17 | ,023 | |
| Z18 | -,135 | |
| Z19 | ,271 | |
| Z20 | ,611 | |
| (Constant) | -3,977 | |
Лямбда Уилкса показывает на значимое различие групп (p < 0,001).
Таблица 10. Wilks' Lambda
| Test of Function(s) | Wilks' Lambda | Chi-square | df | Sig. |
| 1 | ,760 | 271,399 | 20 | ,000 |
2. Пошаговый метод. При выполнении дискриминантного анализа можно применить пошаговый образ действий, который рекомендуется при наличии большого количества независимых переменных.
Таблица 11. Classification Results(a)
| Y | Predicted Group Membership | Total | |||
| 0 | 1 | ||||
| Original | Count | 0 | 219 | 81 | 300 |
| 1 | 203 | 497 | 700 | ||
| % | 0 | 73,0 | 27,0 | 100,0 | |
| 1 | 29,0 | 71,0 | 100,0 | ||
a 71,6% of original grouped cases correctly classified.
Лямбда Уилкса показывает на значимое различие групп (p < 0,001).
Таблица 12. Wilks' Lambda
| Test of Function(s) | Wilks' Lambda | Chi-square | df | Sig. |
| 1 | ,774 | 254,126 | 10 | ,000 |
В таблице 13 приведены коэффициенты дискриминантной функции
Таблица 13. Canonical Discriminant Function Coefficients
| Function | ||
| 1 | |
| SCHET | ,528 | |
| SROK | -,140 | |
| HISTOR | ,315 | |
| ZAIM | -,145 | |
| CHARES | ,186 | |
| TIMRAB | ,133 | |
| VZNOS | -,240 | |
| FAMIL | ,248 | |
| PORUCHIT | ,372 | |
| INIZAIMI | ,262 | |
| (Constant) | -3,288 | |
Точность распознавания дискриминантным анализом выше, чем кластерным. Но результаты по-прежнему остаются неудовлетворительными.
2.4. Дерево классификацийДерево классификаций является более общим алгоритмом сегментации обучающей выборки прецедентов. В методе дерева классификаций сегментация прецедентов задается не с помощью n-мерной сетки, а путем последовательного дробления факторного пространства на вложенные прямоугольные области (рис .1).
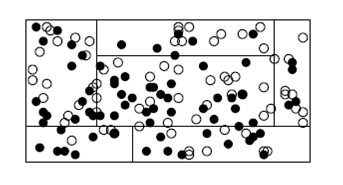
Рис.1. Дерево классификации
На первом шаге разделение выборки прецедентов на сегменты производится по самому значимому фактору. На втором и последующих шагах в отношении каждого из полученных ранее сегментов процедура повторяется до тех пор, пока никакой вариант последующего дробления не приводит к существенному различию между соотношением положительных и отрицательных прецедентов в новых сегментах. Количество ветвлений (сегментов) выбирается автоматически.
В рассмотренной методике также не дается ответ, насколько кредит хорош или плох. Метод не позволяют получить точную количественную оценку риска и установить допустимый риск.
2.5. Нейронные сетиНейронные сети NN используются при определении кредитоспособности юридических лиц, где анализируются выборки меньшего размера, чем в потребительском кредите. Наиболее успешной областью их применения стало выявление мошенничества с кредитными карточками. Нейронные сети выявляют нелинейные связи между переменными, которые могут привести к ошибке в линейных моделях. NN позволяют обрабатывать прецеденты обучающей выборки с более сложным (чем прямоугольники) видом сегментов (рис. 2). Форма сегментов зависит от внутренней структуры NN Формулы и коэффициенты модели риска на основе NN лишены физического и логического смысла.
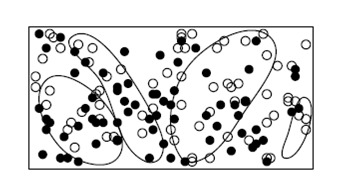
Рис.2. Сегменты разделения «хороших» и «плохих» объектов в NN
Нейросеть — это «черный ящик», внутреннее содержание которого (так называемые веса нейронов) не имеет смысла в терминах оценки риска. Такие методики не позволяют объяснить, почему данному заемщику следует отказать в кредите. NN-модели классификации обладают низкой стабильностью (робастностью).
2.6. Технологии Data miningВ основе технологии data mining лежат алгоритмы поиска закономерностей между различными факторами в больших объемах данных. При этом анализируются зависимости между всеми факторами; но, поскольку даже при небольшом числе факторов количество их всевозможных комбинаций растет экспоненциально, в data mining применяются алгоритмы априорного отсечения слабых зависимостей [1]. Говоря терминами анализа кредитоспособности, data mining на основе данных о выданных кредитах выявляет те факторы, которые существенно влияют на кредитоспособность заемщика, и вычисляет силу этого влияния. Соответственно, чем сильнее определенный фактор влияет на кредитоспособность, тем больший балл ему присваивается в методике скоринга. Чем больше данные держателя кредитной карты похожи на данные «кредитоспособного гражданина», тем больший лимит по кредиту он может получить, тем лучшие условия ему могут быть предоставлены
Главное преимущество методик на основе data mining заключается в том, что они могут работать на малых выборках. При больших выборках их точность, робастность и прозрачность недостаточны В них также не дается ответ, насколько кредит хорош или плох Метод не позволяет получить количественную оценку риска, установить допустимый риск, назначить цену за риск и выявить вклады факторов и их градаций в риск
2.7. Линейная вероятностная регрессионная модель
Задача регрессионного анализа состоит в построении модели, позволяющей по значениям независимых показателей получать оценки значений зависимой переменной. Линейная модель связывает значения зависимой переменной Y со значениями независимых показателей Xk (факторов) формулой:
Y=B0+B1X1+…+BpXp+e
где e - случайная ошибка. Здесь Xk означает не "икс в степени k", а переменная X с индексом k. Традиционные названия "зависимая" для Y и "независимые" для Xk отражают не столько статистический смысл зависимости, сколько их содержательную интерпретацию. Величина e называется ошибкой регрессии. Первые математические результаты, связанные с регрессионным анализом, сделаны в предположении, что регрессионная ошибка распределена нормально с параметрами N(0,σ2), ошибка для различных объектов считаются независимыми. Кроме того, в данной модели мы рассматриваем переменные X как неслучайные значения, Такое, на практике, получается, когда идет активный эксперимент, в котором задают значения X (например, назначили зарплату работнику), а затем измеряют Y (оценили, какой стала производительность труда). За это иногда зависимую переменную называют откликом. Для получения оценок ![]() коэффициентов
коэффициентов ![]() регрессии минимизируется сумма квадратов ошибок регрессии:
регрессии минимизируется сумма квадратов ошибок регрессии:
![]()
Решение задачи сводится к решению системы линейных уравнений относительно ![]() . На основании оценок регрессионных коэффициентов рассчитываются значения Y:
. На основании оценок регрессионных коэффициентов рассчитываются значения Y:
![]()
О качестве полученного уравнения регрессии можно судить, исследовав ![]() - оценки случайных ошибок уравнения. Оценка дисперсии случайной ошибки получается по формуле
- оценки случайных ошибок уравнения. Оценка дисперсии случайной ошибки получается по формуле
![]() .
.
Величина S называется стандартной ошибкой регрессии. Чем меньше величина S, тем лучше уравнение регрессии описывает независимую переменную Y.
Так как мы ищем оценки ![]() , используя случайные данные, то они, в свою очередь, будут представлять случайные величины. В связи с этим возникают вопросы:
, используя случайные данные, то они, в свою очередь, будут представлять случайные величины. В связи с этим возникают вопросы:
1. Существует ли регрессионная зависимость? Может быть, все коэффициенты регрессии в генеральной совокупности равны нулю, оцененные их значения ненулевые только благодаря случайным отклонениям данных?
2. Существенно ли влияние на зависимую отдельных независимых переменных?
В пакете SPSS вычисляются статистики, позволяющие решить эти задачи.
Для проверки одновременного отличия всех коэффициентов регрессии от нуля проведем анализ квадратичного разброса значений зависимой переменной относительно среднего. Его можно разложить на две суммы следующим образом:
![]()
В этом разложении обычно обозначают
![]() - общую сумму квадратов отклонений;
- общую сумму квадратов отклонений;
![]() - сумму квадратов регрессионных отклонений;
- сумму квадратов регрессионных отклонений;
![]() - разброс по линии регрессии.
- разброс по линии регрессии.
Статистика ![]() в условиях гипотезы равенства нулю регрессионных коэффициентов имеет распределение Фишера и, естественно, по этой статистике проверяют, являются ли коэффициенты B1,…,Bp одновременно нулевыми. Если наблюдаемая значимость статистики Фишера мала (например, sig F=0.003), то это означает, что данные распределены вдоль линии регрессии; если велика (например, Sign F=0.5), то, следовательно, данные не связаны такой линейной связью.
в условиях гипотезы равенства нулю регрессионных коэффициентов имеет распределение Фишера и, естественно, по этой статистике проверяют, являются ли коэффициенты B1,…,Bp одновременно нулевыми. Если наблюдаемая значимость статистики Фишера мала (например, sig F=0.003), то это означает, что данные распределены вдоль линии регрессии; если велика (например, Sign F=0.5), то, следовательно, данные не связаны такой линейной связью.
При сравнении качества регрессии, оцененной по различным зависимым переменным, полезно исследовать доли объясненной и необъясненной дисперсии. Отношение SSreg/SSt представляет собой оценку доли необъясненной дисперсии. Доля дисперсии зависимой переменной ![]() , объясненной уравнением регрессии, называется коэффициентом детерминации. В двумерном случае коэффициент детерминации совпадает с квадратом коэффициента корреляции.
, объясненной уравнением регрессии, называется коэффициентом детерминации. В двумерном случае коэффициент детерминации совпадает с квадратом коэффициента корреляции.
Корень из коэффициента детерминации называется КОЭФФИЦИЕНТОМ МНОЖЕСТВЕННОЙ КОРРЕЛЯЦИИ (он является коэффициентом корреляции между y и ![]() ). Оценкой коэффициента детерминации (
). Оценкой коэффициента детерминации (![]() ) является
) является ![]() . Соответственно, величина R является оценкой коэффициента множественной корреляции. Следует иметь в виду, что
. Соответственно, величина R является оценкой коэффициента множественной корреляции. Следует иметь в виду, что ![]() является смещенной оценкой. Корректированная оценка коэффициента детерминации получается по формуле:
является смещенной оценкой. Корректированная оценка коэффициента детерминации получается по формуле:
![]()
В этой формуле используются несмещенные оценки дисперсий регрессионного остатка и зависимой переменной.
Если переменные X независимы между собой, то величина коэффициента bi интерпретируется как прирост y, если Xi увеличить на единицу.
Можно ли по абсолютной величине коэффициента судить о роли соответствующего ему фактора в формировании зависимой переменной? То есть, если b1>b2, будет ли X1 важнее X2?
Абсолютные значения коэффициентов не позволяют сделать такой вывод. Однако при небольшой взаимосвязи между переменными X, если стандартизовать переменные и рассчитать уравнение регрессии для стандартизованных переменных, то оценки коэффициентов регрессии позволят по их абсолютной величине судить о том, какой аргумент в большей степени влияет на функцию.
Дисперсия коэффициента позволяет получить статистику для проверки его значимости ![]() . Эта статистика имеет распределение Стьюдента. В выдаче пакета печатается наблюдаемая ее двусторонняя значимость - вероятность случайно при нулевом регрессионном коэффициенте Bk получить значение статистики, большее по абсолютной величине, чем выборочное.
. Эта статистика имеет распределение Стьюдента. В выдаче пакета печатается наблюдаемая ее двусторонняя значимость - вероятность случайно при нулевом регрессионном коэффициенте Bk получить значение статистики, большее по абсолютной величине, чем выборочное.
Построим регрессию Y на факторы Z1-Z20 по методу линейной регрессии (табл.14.)
Таблица 14. Оценка линейной вероятностной модели
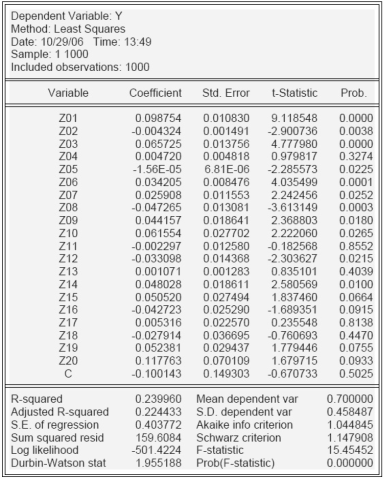
В нашем случае прогнозные значения Yf указывают на вероятность возврата (невозврата) кредита. Построим график прогнозных значений (рис.3.)
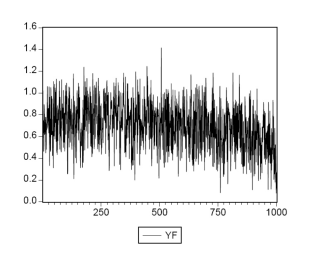
Рис.3. график прогнозных значений
Можно видеть, что прогнозные значения могут находиться вне интервала [0,1] – это главный недостаток LP модели. Поэтому приступим к построению моделей, лишенных этих недостатков.
2.8. Логистическая регрессияБудем считать, что событие в данных фиксируется дихотомической переменной (0 не произошло событие, 1 - произошло). Для построения модели предсказания можно было бы построить, к примеру, линейное регрессионное уравнение с зависимой дихотомической переменной Y, но оно будет не адекватно поставленной задаче, так как в классическом уравнении регрессии предполагается, что Y - непрерывная переменная. С этой целью рассматривается логистическая регрессия. Ее целью является построение модели прогноза вероятности события {Y=1} в зависимости от независимых переменных X1,…,Xp. Иначе эта связь может быть выражена в виде зависимости P{Y=1|X}=f(X)
Логистическая регрессия выражает эту связь в виде формулы
![]() , где Z=B0+B1X1+…+BpXp
, где Z=B0+B1X1+…+BpXp
Название "логистическая регрессия" происходит от названия логистического распределения, имеющего функцию распределения ![]() . Таким образом, модель, представленная этим видом регрессии, по сути, является функцией распределения этого закона, в которой в качестве аргумента используется линейная комбинация независимых переменных [3].
. Таким образом, модель, представленная этим видом регрессии, по сути, является функцией распределения этого закона, в которой в качестве аргумента используется линейная комбинация независимых переменных [3].
Отношение вероятности того, что событие произойдет к вероятности того, что оно не произойдет P/(1-P) называется отношением шансов.
С этим отношением связано еще одно представление логистической регрессии, получаемое за счет непосредственного задания зависимой переменной в виде Z=Ln(P/(1-P)), где P=P{Y=1|X1,…,Xp}. Переменная Z называется логитом. По сути дела, логистическая регрессия определяется уравнением регрессии Z=B0+B1X1+…+BpXp.
В связи с этим отношение шансов может быть записано в следующем виде
P/(1-P)= ![]() .
.
Отсюда получается, что, если модель верна, при независимых X1,…,Xp изменение Xk на единицу вызывает изменение отношения шансов в![]() раз.
раз.
Механизм решения такого уравнения можно представить следующим образом
1. Получаются агрегированные данные по переменным X, в которых для каждой группы, характеризуемой значениями Xj=![]() подсчитывается доля объектов, соответствующих событию {Y=1}. Эта доля является оценкой вероятности
подсчитывается доля объектов, соответствующих событию {Y=1}. Эта доля является оценкой вероятности ![]() . В соответствии с этим, для каждой группы получается значение логита Zj.
. В соответствии с этим, для каждой группы получается значение логита Zj.
2. На агрегированных данных оцениваются коэффициенты уравнения Z=B0+B1X1+…+BpXp. К сожалению, дисперсия Z здесь зависит от значений X, поэтому при использовании логита применяется специальная техника оценки коэффициентов - взвешенной регрессии.
Еще одна особенность состоит в том, что в реальных данных очень часто группы по X оказываются однородными по Y, поэтому оценки ![]() оказываются равными нулю или единице. Таким образом, оценка логита для них не определена (для этих значений
оказываются равными нулю или единице. Таким образом, оценка логита для них не определена (для этих значений ![]() ).
).
Построим модель пробит для наших данных. Оценивание в SPSS дает результаты (табл.15.), где приведены коэффициенты оценивания.
Таблица 15. Оценка логит-модели
| B | ||
| Step 1(a) | schet | ,585 |
| srok | -,139 | |
| histor | ,388 | |
| naznah | ,033 | |
| zaim | -,181 | |
| chares | ,239 | |
| timrab | ,161 | |
| vznos | -,299 | |
| famil | ,264 | |
| poruchit | ,360 | |
| timelive | -,005 | |
| garonti | -,191 | |
| vozras | ,068 | |
| inizaimi | ,315 | |
| kvartir | ,318 | |
| kolzaim | -,240 | |
| proff | ,021 | |
| rodstve | -,153 | |
| telefon | ,312 | |
| inosmest | 1,225 | |
| Constant | -4,227 | |
На основе модели логистической регрессии можно строить предсказание произойдет или не произойдет событие {Y=1}. Правило предсказания, по умолчанию заложенное в процедуру LOGISTIC REGRESSION устроено по следующему принципу: если ![]() >0.5 считаем, что событие произойдет;
>0.5 считаем, что событие произойдет; ![]() £0.5, считаем, что событие не произойдет (табл.16).
£0.5, считаем, что событие не произойдет (табл.16).
Таблица 16. Таблица прогнозов
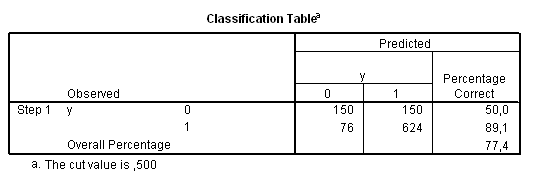
Так в нашем примере результаты прогноза можно оформить в виде таблицы 17.
Таблица 17. Прогнозное качество модели
| Логит модель | |||
| Y=0 | Y=1 | Всего | |
| всего по выборке | 300 | 700 | 1000 |
| прогноз | 226 | 774 | 1000 |
| правильно | 150 | 624 | 774 |
| неправильно | 150 | 76 | 226 |
| % правильно | 50,0% | 89,1% | 77,4% |
| % неправильно | 50,0% | 10,9% | 22,6% |
Результаты подобной классификации превосходят результаты кластерного и дискриминантного анализа.
Заключение
В результате анализа прозрачности методик для оценки кредитных рисков сделаны следующие выводы
· В настоящее время коммерческие банки испытывают сложности в приобретении (разработке) точных, робастных и прозрачных методик и соответствующих программных средств для оценки кредитных рисков физических и юридических лиц
· Предлагаемые на рынке западные скоринговые методики и соответствующие программные средства для оценки кредитных рисков физических и юридических лиц и решения задачи резервирования имеют низкие точность, робастность и прозрачность
· Необходима разработка более перспективных моделей и соответствующих программных средств для оценки кредитных рисков физических и юридических лиц, которые обладают существенными преимуществами по точности, робастности, прозрачности и возможности автоматизации анализа, оценки и управления рисками
· Среди представленных методик логит-модель обладает наилучшими прогнозными свойствами.
В России наличие национального кредитного бюро могло бы существенно облегчить переход на принципы Базеля П. А в его отсутствие крайне затруднительно сформировать базу по оценке кредитных рисков отдельных заемщиков. Соответственно будет сложно выйти за рамки стандартизованного подхода в рамках Базеля II, тогда как далеко не все виды рисков могут быть оценены рейтинговыми агентствами.
Развивающиеся страны также высказали мнение, что применение рейтинговых методик при оценке риска активов в условиях неразвитой рыночной культуры может привести не к повышению качества оценки, а к элементарной продаже рейтингов. Базельский комитет признает, что если новые рейтинги предназначаются для банков в целях регулирования, а не для инвесторов, то их качество может ухудшиться.
В связи с этим призывают отказаться от стандартизованного подхода и заменить его «базовым подходом». Ключевым отличием «базового подхода» является то, что по отношению к кредитам других государств национальные органы банковского надзора наделяются правом самостоятельно определять степень риска. В России рейтинговым агентствам будет крайне сложно определить категории риска для каждого отдельного заемщика, учитывая недостаточность данных по кредитным историям.
Применение положений Соглашения «Базель II» может привести к дисбалансам на различных сегментах финансовых рынков. Так, новые положения стимулируют рост рынков недвижимости, поскольку они предъявляют более низкие требования к достаточности собственного капитала по кредитам, обеспеченным залогом недвижимости. Базель II также устанавливает более низкие уровни риска по кредитам под залог и для мелкого бизнеса. Соответственно стимулируются финансовые услуги розничного банковского бизнеса. С другой стороны, банкам, специализирующимся на секьюритизации активов, по всей видимости, придется повысить размеры достаточного капитала.
Новые положения повысят издержки банков. Стремясь получить одобрение надзорных органов на использование внутренних методик оценки риска, банки будут осуществлять значительные инвестиции в разработку этих методик, создание соответствующих моделей, сбор информации.
В условиях банковской системы России далеко не каждый банк может позволить себе осуществить подобные инвестиции. В России при недостаточном опыте функционирования банковской системы в рыночном режиме банкам крайне сложно самостоятельно определять уровни рисков. В соответствии с критериями Соглашения «Базель II» они должны располагать данными за большой промежуток времени о движении практически каждого кредита, чтобы быть в состоянии рассчитать вероятность банкротства заемщика и связанных с ним потерь для банка. Разумеется, России необходимо практически заново формировать сведения о платежеспособности заемщиков после финансового кризиса.
Основные положения Базеля II ориентированы на крупные банки промышленно развитых стран, для которых применение новых подходов действительно может принести существенную выгоду.
Вопрос об эффективной интеграции в мировую финансовую систему стоит уже сейчас, поэтому в той или иной степени ориентироваться на новые стандарты Базельского комитета по банковскому надзору будет необходимо. Крупным банкам имеет смысл постепенно заняться разработкой внутренних методик оценки риска, и это связано даже не столько с необходимостью следования внешним международным нормам, сколько с упомянутой важностью правильной оценки принимаемых ими на себя рисков. Для мелких и средних банков создание подобных систем ни в настоящее время, ни в обозримом будущем непосильно. Судя по положениям стратегии развития банковской системы, их количество будет постепенно сокращаться, поскольку Центральный банк РФ нацелен на консолидацию банковской системы. Что касается положений Базеля II, то на первом этапе для всех российских банков, очевидно, будет принят стандартизованный подход, который поднимет все проблемы, связанные с кредитными рейтингами. Решению данной проблемы мог бы помочь уже начавшийся процесс формирования бюро кредитных историй.
Динамичное развитие рынка банковских услуг и ожидаемое вступление в ВТО уже сейчас усиливают конкурентную среду в российской банковской системе. Иностранные банки стремятся проникнуть на российский рынок и собираются увеличивать свои инвестиции на нем.
Надо отметить, что крупные банки, которых немного, видимо, получают право самостоятельно оценивать риски и формировать резервы, остальным же придется прибегнуть для этого к помощи рейтинговых агентств. В результате это может привести к появлению у крупных банков конкурентных преимуществ, позволит им снизить объемы своих резервов, увеличить капитал. Как следствие, увеличится влияние крупных международных банков на развитие экономики.
У России есть свои особенности, связанные с нестабильностью экономики страны в целом, «перекосом» в развитии отраслей и межотраслевых связей, большой долей теневых доходов и др., что сказывается на параметрах отдельных потенциальных заемщиков. Например, одним из самых значимых показателей западных скоринговых систем является возраст потенциального заемщика (для Великобритании, Франции и Германии): чем старше человек, тем его оценка выше (он трактуется как надежный заемщик). Очевидна логика работы такой системы на Западе — проработавший всю жизнь человек успел накопить как средства, так и кредитную историю. У нас с очевидностью эта логика будет инвертированной: чем старше заемщик, тем его оценка (кредитоспособность) ниже. Поэтому нельзя просто перенести модель из одной страны в другую, из одной кредитной организации в другую. Не может быть создано единого алгоритма, работающего для всех стран одинаково хорошо. Более того, для различных регионов РФ, в силу различия наших регионов по условиям социально-экономического развития, система оценки риска будет различаться от региона к региону. Каждая конкретная модель должна соответствовать определенной стране, ее экономическим и финансовым условиям, традициям и устоям отдельных территорий, данной кредитной организации.
Литература
[1] Бююль А., Цефель П. SPSS: искусство обработки информации. Анализ статистических данных и восстановление скрытых закономерностей: Пер. с нем. – СПб.: ООО «ДиаСофтЮП», 2001. – 608 с.
[2] Дубров А. М., Мхитарян В. С., Трошин Л. И. Многомерные статистические методы: Учебник. – М.: Финансы и статистика, 2000. – 352 с.
[3] Рябинин И. А. Надежность и безопасность структурно-сложных систем. СПб.: Политехника, 2000.
[4] Соложенцев Е. Д. Сценарное логико-вероятностное управление риском в бизнесе и технике. СПб.: «Бизнес-пресса», 2006.
[5] Соложенцев Е. Д. , Степанова Н. В. , Карасев В. В. Прозрачность методик оценки кредитных рисков и рейтингов. СПб.: Изд-во С.-Петербургского ун-та, 2005.
Похожие работы


... связи между различными статьями, разделами или группами. Метод коэффициентов нужен для контроля достаточности капитала, уровня ликвидности, размера рискованности операций. Индексный метод достаточно распространенный метод в статистике. В финансовом анализе банковской деятельности он применяется главным образом для исследования деловой активности коммерческого банка Метод элиминирования – ...
... задолженности. Значение К24 должно стремиться к нулевой отметке. Высокое значение данного показателя может негативно отразиться на ликвидности Банка. По результатам проведенного комплексного анализа совокупного кредитного риска Банка можно определить его степень следующим образом: Качественная оценка риска Количественная оценка риска Допустимый уровень риска 0-20% Высокий уровень ...
... банковских специалистов, которые должны не только владеть основами современного количественного финансового анализа, но и обладать высокой профессиональной интуицией. 2.1. ПУТИ СНИЖЕНИЯ КРЕДИТНЫХ РИСКОВ В СОВРЕМЕННЫХ УСЛОВИЯХ Стратегия управления рисками в коммерческом банке должна основываться на интегрированной структуре, состоящей из обязанностей и функций, которые спускаются от уровня ...

... риска за год с 6,1-4,3 % просроченный ссудной задолженности в объеме кредитного портфеля наконец удельный вес снизился на 90%. Заключение Проведенное исследование на тему «Совершенствование управления кредитными рисками коммерческого банка» позволяет сделать следующие выводы. Кредит играет специфическую роль в экономике: он не только обеспечивает непрерывность производство, но и ускоряет ...
0 комментариев