Навигация
Устойчивость статистических процедур (робастность)
46528
знаков
0
таблиц
0
изображений
6. Устойчивость статистических процедур (робастность)
Если в параметрических постановках на данных накладываются слишком жесткие требования - их функции распределения должны принадлежать определенному параметрическому семейству, то в непараметрических, наоборот, излишне слабые - требуется лишь, чтобы функции распределения были непрерывны. При этом игнорируется априорная информация о том, каков "примерный вид" распределения. Априори можно ожидать, что учет этого "примерного вида" улучшит показатели качества статистических процедур. Развитием этой идеи является теория устойчивости (робастности) статистических процедур, в которой предполагается, что распределение исходных данных мало отличается от некоторого параметрического семейства. С 60-х годов эту теорию разрабатывали П.Хубер[33], Ф.Хампель [34] и многие другие. Из монографий на русском языке, трактующих о робастности и устойчивости статистических процедур, самой ранней и наиболее общей была книга [35], следующей - монография [36]. Частными случаями реализации идеи робастности (устойчивости) статистических процедур являются рассматриваемые ниже статистика объектов нечисловой природы и интервальная статистика.
Имеется большое разнообразие моделей робастности в зависимости от того, какие именно отклонения от заданного параметрического семейства допускаются. Наиболее популярной [33,34] оказалась модель выбросов, в которой исходная выборка "засоряется" малым числом "выбросов", имеющих принципиально иное распределение. Однако эта модель представляется "тупиковой", поскольку в большинстве случаев большие выбросы либо невозможны из-за ограниченности шкалы прибора, либо от них можно избавиться, применяя лишь статистики, построенные по центральной части вариационного ряда. Кроме того, в подобных моделях обычно считается известной частота засорения, что в сочетании со сказанным выше делает их малопригодными для практического использования.
Более перспективным представляется модель Ю.Н.Благовещенского [37], в которой расстояние между распределением каждого элемента выборки и базовым распределением не превосходит заданной малой величины.
7. Бутстреп (размножение выборок)
Другое из упомянутых выше направлений - бутстреп - связано с интенсивным использованием возможностей вычислительной техники. Основная идея состоит в том, чтобы теоретическое исследование заменить вычислительным экспериментом. Вместо описания выборки распределением из параметрического семейства строим большое число "похожих" выборок, т.е. "размножаем" выборку. Затем вместо оценивания характеристик и параметров и проверки гипотез на основе свойств теоретического распределения решаем эти задачи вычислительным методом, рассчитывая интересующие нас статистики по каждой из "похожих" выборок и анализируя полученные при этом распределения. Например, вместо того, чтобы теоретическим путем находить распределение статистики, доверительные интервалы и другие характеристики, моделируют много выборок, похожих на исходную, рассчитывают соответствующие значения интересующей исследователя статистики и изучают их эмпирическое распределение. Квантили этого распределения задают доверительные интервалы, и т.д.
Термин "бутстреп" мгновенно получил известность после первой же статьи Б.Эфрона 1979 г. [39] по этой тематике. Он сразу же стал обсуждаться в массе публикаций, в том числе и научно-популярных [40]. В "Заводской лаборатории" была помещена подборка статей по бутстрепу [41], выпущен сборник статей Б.Эфрона [42]. Основная идея бутстрепа по Б.Эфрону состоит в том, что методом Монте-Карло (статистических испытаний) многократно извлекаются выборки из эмпирического распределения. Эти выборки, естественно, являются вариантами исходной, напоминают ее.
Сама по себе идея "размножения выборок" была известна гораздо раньше. Статья Б.Эфрона [39] называется так: "Бутстреп-методы: новый взгляд на метод складного ножа". Упомянутый "метод складного ножа" (jackknife) предложен М.Кенуем еще в 1949 г., за 30 лет до статьи Б.Эфрона. "Размножение выборок" при этом осуществляется путем исключения одного наблюдения. При этом для выборки объема n получаем n "похожих" на нее выборок объема (n - 1) каждая. Если же исключать по 2 наблюдения, то число "похожих" выборок возрастает до n (n - 1) / 2 объема (n - 2) каждая.
Преимущества и недостатки бутстрепа как статистического метода обсуждаются в [43]. Там же и в [18] приводится информация о ряде аналогичных методов. Необходимо подчеркнуть, что бутстреп по Эфрону [39-42] - лишь один из вариантов методов "размножения выборки" (resampling), и, на наш взгляд, не самый удачный. Метод "складного ножа" представляется более полезным. На его основе можно сформулировать следующую простую практическую рекомендацию.
Предположим, что Вы по выборке делаете какие-либо статистические выводы. Вы хотите узнать также, насколько эти выводы устойчивы. Если у Вас есть другие (контрольные) выборки, описывающие то же явление, то Вы можете применить к ним ту же статистическую процедуру и сравнить результаты. А если таких выборок нет? Тогда Вы можете их построить искусственно. Берете исходную выборку и исключаете один элемент. Получаете похожую выборку. Затем возвращаете этот элемент и исключаете другой. Получаете вторую похожую выборку. Поступив так со всеми элементами исходной выборки, получаете столько выборок, похожих на исходную, каков ее объем. Остается обработать их тем же способом, что и исходную, и изучить устойчивость получаемых выводов - разброс оценок параметров, частоты принятия или отклонения гипотез и т.д.
Можно изменять не выборку, а сами данные. Поскольку всегда имеются погрешности измерения, то реальные данные - это не числа, а интервалы (результат измерения плюс-минус погрешность). Нужна статистическая теория анализа таких данных.
Похожие работы
... ПО “Уралмаш”, “АвтоВАЗ”, МИИТ, Казахского политехнического института, Донецкого государственного университета и многих других. Затем Институт в качестве Лаборатории эконометрических исследований разрабатывал эконометрические методы анализа нечисловых данных, а также процедуры расчета и прогнозирования индекса инфляции и валового внутреннего продукта. Институт высоких статистических технологий и ...
... математическая лучше всего представлена в [2,4]. По историческим причинам основные российские работы публикуются в [3]. Обзор современного состояния статистики математической дан в [6]. Статистика объектов нечисловой природы - раздел математической статистики, в котором статистическими данными являются объекты нечисловой природы, т.е. элементы множеств, не являющихся линейными пространствами. ...


... знаниях. Целью прогнозирования является минимизация погрешности прогностических оценок. Очевидно, что научно обоснованные и планомерно разрабатываемые прогнозы являются более точными и эффективными (как основа принятия решений), чем случайные и интуитивные прогнозы. Известны различные методы прогнозирования: экспертные методы; метод анализа "индекса деловой активности"; статистические методы ...
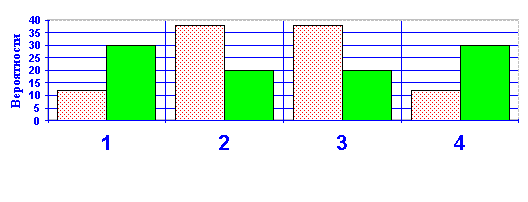
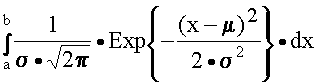
... гипотезу. Вроде бы это надо делать так: Теперь результаты наблюдений над выручкой G можно представить в виде четырех наблюдений над U: –11,+1,+3,+7. Теория математической статистики предлагает следующий, т.н. биномиальный критерий проверки гипотез в подобных ситуациях. Предполагается, что распределение вероятностей наблюдаемой величины U симметрично относительно значения математического ...
0 комментариев