Навигация
Выборочные средние отклика (y) для каждого значения x лежат на прямой;
29536
знаков
5
таблиц
3
изображения
1. Выборочные средние отклика (y) для каждого значения x лежат на прямой;
2. Для любого значения x, соответствующие значения y нормально распределены;
3. Для любого значения x, y – имеют одинаковую дисперсию ![]() .
.
При прогнозировании является ли среднее ошибок оценки подходящей мерой для прогнозирования.
![]()
Средняя ошибка оценки всегда равна нулю. Один из способов доказать этот факт, это выбрать в качестве меры прогнозирования дисперсию ошибки оценки.
Стандартная ошибка оценки ![]()
Стандартную ошибку оценки применяют для определения пределов, в окрестности предсказанного ![]() попадает фактическое значение yi.
попадает фактическое значение yi.
В приделах Se – расположено 69% фактических значений объекта, в приделах 2Se – 95%, в приделах 3Se – 97,5%.
Связь b1 и b0 с другими описательными статистиками
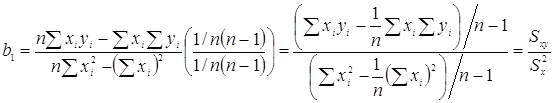
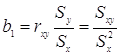
Если x и y распределены по нормальному закону и имеют одинаковую дисперсию, то ![]() .
.
Поскольку rxyне зависит от Sx и Sy, b1 - принимает максимальное значение при rxy =1 и минимальное значение при rxy = -1, следовательно b1 никогда не может быть больше ![]() , при rxy =1 и не может быть меньше
, при rxy =1 и не может быть меньше ![]() при rxy = -1.
при rxy = -1.
Если между переменными отсутствует линейная связь, b1=0 уравнение регрессии сводится к прямой без наклона, то есть ![]() .
.
Измерение нелинейной связи между переменными
Для определения меры нелинейной связи между переменными используется коэффициент ![]()
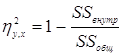
Эта мера может быть использована и для оценки линейной связи.
Пример вычисления:
| x/возраст | 10 | 14 | 18 | 22 | 26 | 30 | 34 | 38 |
| 7 | 8 | 9 | 11 | 9 | 8 | 7 | 8 | |
| 8 | 9 | 10 | 11 | 10 | 9 | 9 | ||
| 9 | 10 | 11 | 12 | 11 | 9 | 10 | ||
| 9 | 11 | 12 | 12 | 10 | ||||
| 10 |
![]()
![]()
Находим среднее для каждого возраста и суммируем отношения каждого yi от среднего соответствующего группы.
Для 10 - ![]() =8,6; 18 – 9,5; 22 – 11,5; 26 – 10; 90 – 9; 34 – 8,67; 38 – 8.
=8,6; 18 – 9,5; 22 – 11,5; 26 – 10; 90 – 9; 34 – 8,67; 38 – 8.
![]()
![]()
![]() - является мерой нелинейности связи и
- является мерой нелинейности связи и ![]()
Другие меры связи
1. Измерения в дихотомической шкале (например, женат – не женат, мужчина – женщина)
2. Измерение в дихотомической шкале наименований в предположении нормального распределения. Предполагается, что при более полных, более совершенных измерениях данные распределятся по нормальному закону.
3. Шкала порядка
4. Измерение в шкале интервалов или отношений.
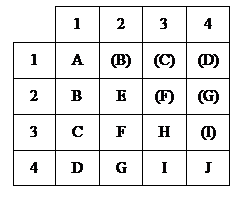 Рассмотренный ранее коэффициент кореляции Пирсона соответствует сочетанию J при измерении исходных данных. Для описания степени кореляции при других комбинациях шкал измерений исходных данных используются следующие меры.
Рассмотренный ранее коэффициент кореляции Пирсона соответствует сочетанию J при измерении исходных данных. Для описания степени кореляции при других комбинациях шкал измерений исходных данных используются следующие меры.
Случай A.
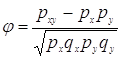
px– доля людей имеющих 1 по x, py– доля людей имеющих 1 по y
qx– доля людей имеющих 0 по x, qy– доля людей имеющих 0 по y
pxy - доля людей имеющих 1 по x и y
| № | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| x | 0 | 1 | 0 | 0 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 1 |
| y | 0 | 1 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 1 |
x – женат / холост
y – исключенные из учебного заведения / оставшиеся
px=0,4167 ; py= 0,5 ; qx=0,5833 ; qy= 0,5 ; pxy =0,333; φ=0,507
Если нет особого интереса к доле pxи py, дихатомические данные располагают в таблице сопряженности признаков. Пример таблицы сопряженности по приведенным данным
 φ – определяется по формуле:
φ – определяется по формуле:
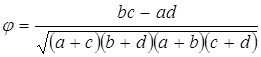
Коэффициент φ, это тот же коэффициент кореляции Пирсона, но эти данные не похожи на двумерное нормальное распределение, которое мы представляли при вычислении коэффициента Пирсона. Это рассматривается как большое неудобство статистиками.
Случай B.
Удовлетворительного коэффициента для этого случая не существует, рекомендуется исходить из предположения о нормальном распределении данных и вычислять φ в качестве меры связи для этого случая.
Случай C.
Для этого случая подходят коэффициенты, о котором мы расскажем в случае I.
Случай D.
Используется биссериальный коэффициент кореляции: 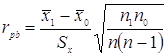
![]() - среднее по x объектов имеющих 1 по y.
- среднее по x объектов имеющих 1 по y.
![]() - среднее по x объектов имеющих 0 по y.
- среднее по x объектов имеющих 0 по y.
Sx – стандартное отклонение
Случай E.
Тетрахорический коэффициент кореляции: ![]()
Более удобно при расчете обращаться к статическим таблицам, содержащим вычисления из этого уравнения. Они составлены при условии, что bc/ad>1. В противном случае таблица содержит ad/bc и величина тетрахорического коэффициента будет отрицательной.
Случай F.
Удовлетворительного коэффициента не разработано, рекомендуется продположить нормальное распределение для x и использовать биссериальный ранговый коэффициент (см. случай G).
Случай G.
Биссериальный коэффициент: 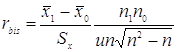
u – ордината нормального распределения.
Случай H.
Используется коэффициент ранговой кореляции Спирмана: 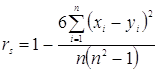
В том случае, если при измерении встречается связанные ранги, это уравнение не подходит в качестве меры кореляции.
Связанный ранг возникает в том случае, если у некоторых объектов получено одинаковое значение переменной. В этом случае ранги, которые должны были бы получить эти объекты суммируются и делятся на количество объектов и каждый получает, пролученный при вычислении ранг.
До сих пор коэффициенты кореляции представляли из себя или могли быть объяснены в терминах произведения моментов. Коэффициент кореляции, не связвнный с моментами построен Кендаллом и называется τ – Кендалла
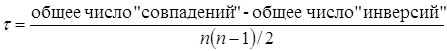
Случай I.
Для этого случая коэффициенты не разработаны, рекомендуется преобразовать оценки по y в ранги и найти или коэффициент Спирмана или Кендалла
Бисериальная ранговая кореляция: 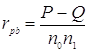
P – сумма всех совпадений; Q – сумма всех инверсий;
n0– число объектов при нулевой дихотомии; n1– число объектов при единичной дихотомии.
Похожие работы


... мышц и скоростью их сокращения, между спортивным достижением в одном и другом виде спорта и так далее. Теперь можно составить содержание элективного курса «Основы теории вероятностей и математической статистики» для классов оборонно-спортивного профиля. 1. Комбинаторика. Основные формулы комбинаторики: о перемножении шансов, о выборе с учетом порядка, перестановки с повторениями, размещения с ...
... опираться на теорию множеств, математическую логику, теорию алгоритмов. На основе применения «неколичественного» математического аппарата в теоретическом языкознании сформировалось направление, условно называемое комбинаторной лингвистикой – в ней используются методы математической статистики теории вероятностей, теории информации, математического анализа Современные инструментальные методы ...
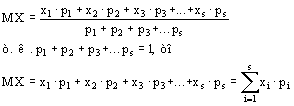
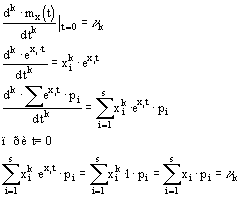
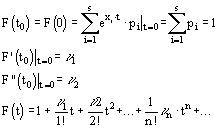
... Доказать: По определению второй смешанной производной. Найдем по двумерной плотности одномерные плотности случайных величин X и Y. Т.к. полученное равенство верно для всех х, то подинтегральные выражение аналогично В математической теории вероятности вводится как базовая формула (1) ибо предлагается, что плотность вероятности как аналитическая функция может не существовать. Но т.к. в нашем ...
... гипотезу. Вроде бы это надо делать так: Теперь результаты наблюдений над выручкой G можно представить в виде четырех наблюдений над U: –11,+1,+3,+7. Теория математической статистики предлагает следующий, т.н. биномиальный критерий проверки гипотез в подобных ситуациях. Предполагается, что распределение вероятностей наблюдаемой величины U симметрично относительно значения математического ...
0 комментариев