Реферат по дисциплине: «Теория вероятности и математическая статистика»
Выполнил: Апаз С.В. группа ЭП – 21
Крымский Экономический Институт Киевского Национального Экономического Университета
Симферополь — 2002
Точечное оцениваниеКак и известно, выборка х1, х2, х3,…,хn является реализацией случай-ного вектора (Х1; Х2;… Хn). Это значит, что каждая числовая характеристика выборки есть реализация случайной величины, которая от выборки к выборке может принимать различные значения и, следовательно, сама является случайной. Такую случайную величину называют выборочной функцией или статистикой и обозначают ã=ã. Эта запись выражает зависимость выборочной функции от случайных компонент Хi, i=![]() , вектора (Х1; Х2;… Хn). Например, выборочными функциями являются среднее арифметическое
, вектора (Х1; Х2;… Хn). Например, выборочными функциями являются среднее арифметическое ![]() , статистическая дисперсия
, статистическая дисперсия ![]() , мода
, мода![]() , медиана
, медиана ![]()
Так как выборочная статистика величина случайная, то она имеет закон расрпделения, зависящий от закона распадения случайной величины Х в генеральной совокупности.
Пусть требуется подобрать распределение для исследуемой случайной величины Х по выборке х1, х2, х3,…,хn, извлеченной из генеральной совокупности ![]() с неизвестной функцией распределения F(х). Выбрав распределение (нормальное, биноминальное, показательное или др.), исходя из анализа выборки (например, по вид гистограммы или по виду полигона относительных частот), мы по данным выборки должны оценить параметры соответствующего распределения. Например, для нормального распре-деления нужно оценить параметры m и
с неизвестной функцией распределения F(х). Выбрав распределение (нормальное, биноминальное, показательное или др.), исходя из анализа выборки (например, по вид гистограммы или по виду полигона относительных частот), мы по данным выборки должны оценить параметры соответствующего распределения. Например, для нормального распре-деления нужно оценить параметры m и ![]() ; для распределения Пуасона – параметр l и т.д.
; для распределения Пуасона – параметр l и т.д.
Решение вопросов о "наилучшей оценке" неизвестного параметра и составляет теорию статистического оценивания.
Выборочная числовая характеристика, применяемая для получения оценки неизвестного параметра генеральной совокупности, называется точечной оценкой.
Например, Х – среднее арифметическое, может служить оценкой математического ожидания М (Х) генеральной совокупности ![]() . В принципе для неизвестного параметра а может существовать много число-вых характеристик выборки, которые вполне подходяще для того, чтобы служить оценками. Например, среднее арифметическое, медиана, мода могут показаться вполне приемлемыми для оценивания математического ожидания М (Х) совокупности. Чтобы решить, какая из статистик в данном множестве наилучшая, необходимо определить некоторые желаемые свойства таких оценок, т.е. указать условия, которым должны удовлетворять оценки.
. В принципе для неизвестного параметра а может существовать много число-вых характеристик выборки, которые вполне подходяще для того, чтобы служить оценками. Например, среднее арифметическое, медиана, мода могут показаться вполне приемлемыми для оценивания математического ожидания М (Х) совокупности. Чтобы решить, какая из статистик в данном множестве наилучшая, необходимо определить некоторые желаемые свойства таких оценок, т.е. указать условия, которым должны удовлетворять оценки.
Такими условиями являются: несмещенность, эффективности состоятельность.
Если М (ã)=а, то ã называется несмещенной оценкой а.
В других случаях говорят. Что оценка смещена.
Несмещенность оценки означает, что если использовать эту оценку, то в одних случаях может получиться. Что мы завышаем искомый параметр совокупности, в других – занижаем. Однако в среднем мы будет "попадать в цель".
Так, например, несмещенной оценкой для математического ожидания М(Х)=а случайной величины Х является средняя арифметическая ![]() = ã.
= ã.
Действительно,
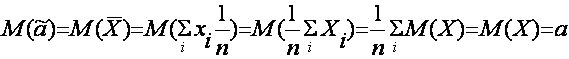 ,
,
так как результаты выборки х1, х2, х3,…,хn рассматривают как n независимых случайных величин Х1, Х2, Х3,…,Хn, каждая из которых распределена по тому же закону, что и случайная величина Х.
Ели существует больше одной несмещенной оценки, то выбирают более эффективную оценку, т.е. ту, для которой величина второго момента М (ã – а)2 меньше.
Оценка ã1 называется более эффективной, чем оценка ã2, если
М (ã1 – а)2< М (ã2 – а)2.
Ели обозначить через b= М(ã) – а смещение оценки, то
М(ã – а)2=D(ã)+b2, так как М(ã - М(ã)+ М(ã) – а)2= М((ã - М(ã))+ +М(ã) – а))2= М((ã - М(ã))+b)2= Мã - М(ã))2+2b´M(ã - М(ã)) + M(b2) = =D(ã)+b2 (M(ã - М(ã))=0, M(b2)=b2). Поэтому более эффективной оценкой будем считать ту несмещенную оценку, которая имеет меньшую дисперсию.
В частности, средняя арифметическая ![]() = ã является наиболее эффективной оценкой математического ожидания М(Х)= а, так как
= ã является наиболее эффективной оценкой математического ожидания М(Х)= а, так как
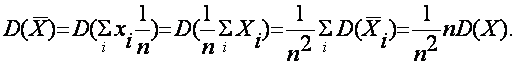
Все другие оценки М(Х) будут обладать большими дисперсиями. Например,
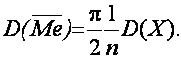
Минимальную величину среднеквадратической погрешности оценивают, используя неравенство Рао-Крамера
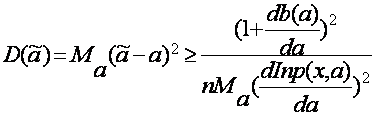 ,где b(a) – смещение оценки; n – объем выборки; функция
,где b(a) – смещение оценки; n – объем выборки; функция 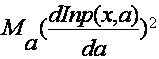 носит название информации Фишера. Любая несмещенная оценка, а, для которой b(a)º0 удовлетворяет неравенству
носит название информации Фишера. Любая несмещенная оценка, а, для которой b(a)º0 удовлетворяет неравенству
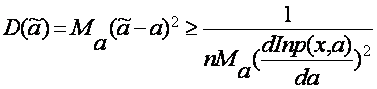
Таким образом, наименьшее возможное знамени среднеквадратических отклонений отлично от нуля и определяется правыми частями приведенных выше неравенств. При использовании той или иной оценки желательно, чтобы точность оценивания увеличилась с возрастанием объема производимой выборки. Предельная точность будет достигнута в том случае, когда численное значение оценки совпадает со значением параметра при неограниченном увеличении объема выборки. Такие оценки будет называться состоятельными.
Оценка ã называется состоятельной оценкой а, если при n®¥ она сходится по вероятности к а, то есть если 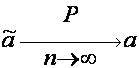 .
.
Например, средняя арифметическая ![]() = ã является состоятельной оценкой математического ожидания М(Х)= а совокупности, так как, согласно закону больших чисел,
= ã является состоятельной оценкой математического ожидания М(Х)= а совокупности, так как, согласно закону больших чисел, 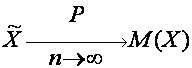
Наконец, при построении оценки ã должна использоваться вся информации, содержащаяся в выборке, о неизвестном параметре а, то есть оценка должна быть достаточной. Если ã – достаточная оценка. То никакая друга оценка не может дать о неизвестном параметре а дополнительных сведений.
При выборе оценок следует принимать во внимание перечисленные свой свойства и учитывать относительную простоту вычислений. Нередко выбирается не эффективная оценка только потому, что ее вычисление намного проще, чем вычисление эффективной оценки. Например, при контроле качества продукции мерой разброса совокупности часто служит выборочный размах, используемой вместо более сложной и более эффективной оценки – выборочного стандартного отклонения. Отметим, что при оценивании на основе малого числа наблюдений различие в эффективности оценок невелико.
Интервальное оцениваниеМы рассмотрели оценки неизвестных параметров закона распределения случайной величины Х по данным выборки. Получаемые при этом точечные оценки ãi не совпадают (за исключение редких случаев) с истинным значением неизвестных параметров аi. Следовательно, всегда имеется некоторая погрешность при замене неизвестного параметра его оценкой, т.е. |ã – а|<d:
![]() (1.1)
(1.1)
И если эта вероятность близка к единице, т.е. если![]() ,то диапазон практически возможных значений ошибки, возникающей при замене а на, равен ±d. Причем большие про абсолютной величине ошибки появляются с вероятностью e, e>0.
,то диапазон практически возможных значений ошибки, возникающей при замене а на, равен ±d. Причем большие про абсолютной величине ошибки появляются с вероятностью e, e>0.
Чем меньше для данного e>0 будет d>0, тем точнее оценка ã. Из соотношения (1.1) видно, что вероятность тог, что интервал ] ã - d; ã+d [ со случайными концами накроет неизвестный параметр, равна 1 - e. Эта вероятность называется доверительной вероятностью.
Случайный интервал, определяемый результатами наблюдений, который с заданной вероятностью а = 1 - e накрывает неизвестный параметр а, называемый доверительным интервалом для параметра а, соответствующим доверительной вероятности а = 1 - e.
Граничные точки доверительного интервала называются соответственно нижним и верхним доверительным пределами.
Заданному а = 1 - e соответствует неединственный доверительный интервал. Доверительные интервалы могут изменяться от выборки к выборке. Более тог, для данной выборки различные методы построения доверительных интервалов могут привести к различным интервалам. Поэтому выработаны определенные правила. Используя их и эффективные оценки неизвестных параметров, получают кратчайшие интервалы для заданной доверительной вероятности а = 1 - e.
Рассмотрим общие принципы построения доверительных интервалов. Предположим, что доверительный интервал находим для некоторого параметра а совокупности и в качестве точечной оценки этого параметра возьмем выборочную несмещенную М(ã) = а и эффективную оценку ã = ã(Х1; Х2;… Хn), имеющую среднее квадратическое отклонение sã.
Если бы закон распределения оценки ã был известен, то для нахождения доверительного интервала нужно было бы найти такое значение d, для которого ![]() . Но закон распределения оценки ã зависит от закона распределения случайной величины Х и, следовательно, от его неизвестного параметра а. Для того чтобы не применять закон распределения случайной величины Х, поступают следующим образом.
. Но закон распределения оценки ã зависит от закона распределения случайной величины Х и, следовательно, от его неизвестного параметра а. Для того чтобы не применять закон распределения случайной величины Х, поступают следующим образом.
Так как мы считаем значение выборки х1, х2, х3,…,хn, имеющими те же законы распределения, что и исследуемая случайная величина Х, то, согласно центральной предельной теореме (теоретическое выборочное распределение средних ![]() при большом n может быт хорошо аппроксимировано соответствующим нормальным распределением параметрами М(
при большом n может быт хорошо аппроксимировано соответствующим нормальным распределением параметрами М(![]() ) = М(
) = М(![]() ) и
) и 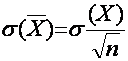 , большинство числовых характеристик выборки имеют нормальное или близкое значение к нормальному выборочное распределение.
, большинство числовых характеристик выборки имеют нормальное или близкое значение к нормальному выборочное распределение.
Поэтому с помощью вероятностей, которые находим из таблиц нормального распределения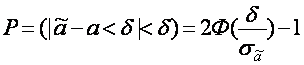 , где
, где 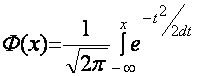 , для заданного d можно найти такое интервал ] ã - d; ã+d [, в котором лежит значение ã, вычисленное по данной выборке можно решить и обратную задачу: по данной вероятности найти значение d
, для заданного d можно найти такое интервал ] ã - d; ã+d [, в котором лежит значение ã, вычисленное по данной выборке можно решить и обратную задачу: по данной вероятности найти значение d
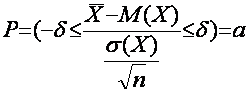 , такое что
, такое что ![]() .
.
Неравенства а - d≤ ã ≤а + d эквивалентны неравенствам ã - d≤ а ≤ ã + d (вычтем ã - d из каждой части и умножим на –1). Тем самым указаны методы построения доверительных интервалов ] ã - d; ã + d [ для параметра а.
Таким образом, при построении доверительных интервалов составляется случайная величина Y (например, 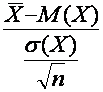 , связанная с неизвестным параметром а, его оценкой и имеющая известную плотность распределения вероятностей p(y). Используя эту плотность, определим доверительный интервал по формуле
, связанная с неизвестным параметром а, его оценкой и имеющая известную плотность распределения вероятностей p(y). Используя эту плотность, определим доверительный интервал по формуле 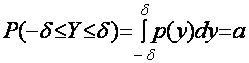 .
.
В качестве доверительно вероятности (иначе – уровня доверия) обычно полагают
а =0,95 (0,99). Это значит, что при извлечении n выборок из одной и той же генеральной совокупности доверительный интервал примерно в 95% (99%) случаев будет накрывать неизвестный параметр (относительно неизвестного параметра вероятные события не допускаются). При увеличении же доверительной вероятности строится более широкий доверительный интервал, который малопригоден для практики. Еще раз подчеркнем, что чем меньше длина доверительного интервала, тем точнее оценка.
Отметим, что для точного нахождения доверительных интервалов необходимо знать закон распределения случайной величины Х, тогда как для применения приближенных методов это не обязательно.
Список литературыГурский Е.И. «Теория вероятности и математическая статистика».
Хеннекен П.А. «Теория вероятности»
Барковский В.В. «Теория вероятности и математическая статисти
Похожие работы
... проверить знания студента из первой части курса, которая излагается в первых четырёх модулях. Во вторых вопросах билета проверяются знания классической предельной проблемы теории вероятностей и математической статистики, которые излагаются в следующих пяти модулях. 1. Вероятностная модель с не более чем счётным числом элементарных исходов. Пример: испытания с равновозможными исходами. 2. ...
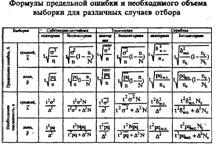
... Вариационные ряды позволяют получить первое представление об изучаемом распределении. Далее необходимо исследовать числовые характеристики распределения (аналогичные характеристикам распределения теории вероятностей): характеристики положения (средняя арифметическая, мода, медиана); характеристики рассеяния (дисперсия, среднее квадратическое отклонение, коэффициент вариации); характеристики ...
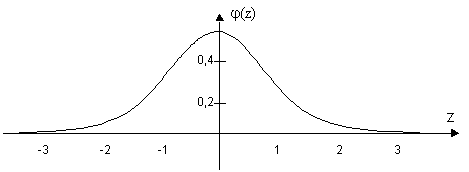

... : , где - значение критерия Пирсона для уровня значимости , - для уровня значимости , -число степеней свободы. 1.2 Наиболее важные распределения, применяемые в математической статистике 1.2.1 Нормальное распределение Случайная величина , распределенная по нормальному закону, описывается плотностью вероятности: . Нормальное распределение определяется двумя параметрами – ...
... несколько уравнений, а в каждом уравнении - несколько переменных. Задача оценивания параметров такой разветвленной модели решается с помощью сложных и причудливых методов. Однако все они имеют одну и ту же теоретическую основу. Поэтому для получения начального представления о содержании эконометрических методов мы ограничимся в последующих параграфах рассмотрением простой линейной регрессии. ...
0 комментариев