Навигация
Если константу прибавить к каждому значению, то среднее увеличивается на ту же константу
29348
знаков
0
таблиц
0
изображений
2. Если константу прибавить к каждому значению, то среднее увеличивается на ту же константу.
3. Если каждое значение умножить на константу, то среднее то же будет умножено на эту константу.
4. Сумма квадратов отклонений значений от их среднего меньше суммы квадратов отклонений от любой другой точки, то есть: ![]()
![]() - среднее для каждого класса,
- среднее для каждого класса, ![]() - количество учащихся
- количество учащихся
Среднее общее группы:
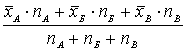
Для определения моды и медианы объединенной группы необходимы конкретные значения измерений.
Мода – это такое число в группе, с которым совпадает наибольшее количество значений в группе.
Медиана – это такая точка на числовой оси, для которой сумма абсолютных значений разности всех значений меньше суммы разностей для любой другой точки. Если именно так определять понятие ошибки, то медиана дает минимальную ошибку. Если же ошибка определяется как сумма квадратов разностей, то минимальную ошибку дает среднее.
Выбор меры центральной тенденции В малых группах мода очень нестабильна; На медиану не влияет величины очень больших и очень малых значений; На величину среднего влияет каждое значение; Некоторые множества данных не имеют меры центральной тенденции. Такая ситуация близка к бимодальной гистограмме или U-образной; Центральная тенденция групп, содержащая крайние значения наилучшим образом представляется в том случае, если гистограмма унимодальна; Если гистограмма симметрична и унимодальна, то средняя мода и медиана совпадают. Другие меры центральной тенденцииСреднее геометрическое: ![]() ;Среднегармоническое:
;Среднегармоническое: 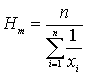
Для оценки меры неоднородности (разброса, изменчивости), в группе вводят специальные меры, с помощью которых после их исследования можно уменьшить изменчивость данных. Первая из мер изменчивости называется размахом.
Размах – это разность максимального и минимального значений в группе.
Включающий размах – это разность между естественной верхней границей интервала, включая наибольшее значение, и естественной нижней границей, включая наименьшее значение интервала. ![]() . Включающий размах отличается от исключающего на единицу.
. Включающий размах отличается от исключающего на единицу.
Размах от 90-го до 10-го процентеля: D = P90 – P10 . Эта мера более стабильна, чем предыдущая, так как на нее влияет множество значений.
Полу-междуквантильный размах: ![]() , Q используется в распределениях, которые симметричны относительно медианы и среднего, для корректировки границ.
, Q используется в распределениях, которые симметричны относительно медианы и среднего, для корректировки границ.
Дисперсия. Каждая из предыдущих мер возрастает с ростом рассеяния и уменьшается однородностей. Дисперсию, в отличие от предыдущих мер, используют при вычислении каждого из полученных измерений. Вычисляются значения отклонений ![]() и чтобы при суммировании
и чтобы при суммировании 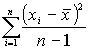 не потерять величины этих отклонений, разница возводится в квадрат, поскольку мы оцениваем отклонение каждого измерения, делим на количество измерений. Обозначается дисперсия как
не потерять величины этих отклонений, разница возводится в квадрат, поскольку мы оцениваем отклонение каждого измерения, делим на количество измерений. Обозначается дисперсия как ![]() .
.
![]()
Для вычисления дисперсии не нужно вычислять среднее.
Дисперсия при сгруппированных данных вычисляется по такой же формуле, но ![]()
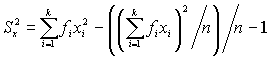
i изменяется от 1 до k, где k – количество разных значений ![]() .
.
Стандартное отклонение: 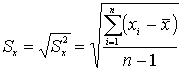
Для унимодальных симметричных распределений почти 70% значений лежит в интервале ![]() .
.
1. Влияние на дисперсию увеличения каждого значения на какую либо константу:
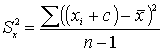 , после выполнения математических операций убеждаемся, что дисперсия не изменяется.
, после выполнения математических операций убеждаемся, что дисперсия не изменяется.
2. Изменение дисперсии при умножении каждого исходного значения на константу:
![]() , то есть дисперсия увеличивается на квадрат константы.
, то есть дисперсия увеличивается на квадрат константы.
3. Дисперсия объединенной группы:
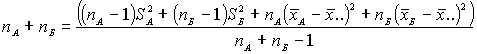
где:
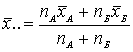
![]() - количество значений группы А, для Б аналогично
- количество значений группы А, для Б аналогично
![]() - среднее группы А, для Б аналогично
- среднее группы А, для Б аналогично
Среднее отклонение – это совокупность отклонений каждого значения от среднего, взятого по модулю:
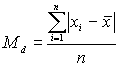
Очень проста в вычислениях, но редко используется, ввиду того, что нет теоретического обоснования.
Стандартизованные данныеЧасто появляется потребность оценить положение какого-либо конкретного значения по отношению к среднему в единицах стандартного отклонения
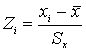
Любое множество данных можно преобразовать в такое множество, у которого среднее равно нулю, а стандартное отклонение равно единице.
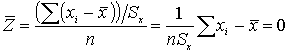
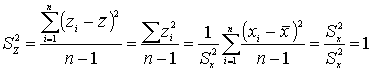
Значение стандартизованных данных Z позволяют преобразовать множество x в произвольную шкалу с удобными характеристиками среднего и стандартизованного отклонения. Сами оценки Z могут быть отрицательными или содержать дроби. Мы избавимся от этих шероховатостей, умножая стандартизованные данные на константу и прибавляем к ним константу.
сz – будет иметь стандартное отклонение
![]() , где с, d – константы – будут иметь среднее равное d.
, где с, d – константы – будут иметь среднее равное d.
Асимметрия – это свойство распределения частот. На практике симметричные полигоны и гистограммы не встречаются и чтобы выявить и оценить степень асимметрии, вводят следующую меру:
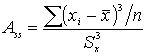
В единицах стандартного отклонения асимметрия равна:
Асимметрия бывает положительной и отрицательной. Положительная сдвигается влево, а отрицательная – вправо.
Чтобы упростить вычисление Ass можно использовать следующую формулу:
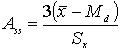
Асимметрия в этом уравнении принимает значения от –3 до +3
Четвертый момент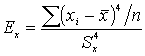
Эксцесс – это мера крутости кривой распределения. Унимодальная кривая распределения может быть островершинной, плосковершинной, средне вершинной.
Эксцесс для стандартных данных:
| Характер распределения | Величина эксцесса |
| Нормальное Островершинное Плосковершинное | 3 больше 3 и может быть очень большим больше нуля, но меньше 3 |
Эти четыре момента составляют набор особенностей распределения при анализе данных.
Нормальное распределениеНормальное распределение лучше всего описывается кривой созданной ДеМуавром по следующей формуле:
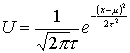
где U – высота кривой над осью x, t и μ – числа, которые определяют положение кривой относительно числовой оси и регулируют ее размах. Для μ=0, t =1 график принимает вид:
Эта кривая при μ=0, t =1 получила статус стандарта, ее называют единичной нормальной кривой, то есть любые собранные данные стремятся преобразовать так, чтобы кривая их распределения была максимально близка к этой стандартной кривой. Созданы статистические таблицы со значениями площади под единичной нормальной кривой влево от любой точки на оси z в (-3; 3). Общая площадь под кривой равна 1. И все остальные площади рассматривают как процент от целого.
Свойства нормальных кривых:
Семейство нормальных кривых включают в себе все кривые, которые можно получить по данной формуле, отличающиеся друг от друга только парой значений t и μ .
1. 68% площади лежит в интервале ![]()
2. 95% площади лежит в интервале ![]()
3. 99,7% площади лежит в интервале ![]()
Если x имеет нормальное распределение со средним μ и стандартным отклонение t , то z равное ![]() характеризуется распределением со средним равным нулю и стандартным отклонением равным 1. Площадь между двумя значениями x в нормальном распределении равна площади между ux стандартизованными величинами в единичном нормальном распределении. Нормализованную кривую изобрели для решения задач теории вероятности, но оказалось на практике, что она отлично аппроксимирует распределение черт при большом числе наблюдений для множества переменных. Можно предположить, сто не имея материальных ограничений на количество объектов и время проведения эксперимента, статистическое исследование приводило к нормально кривой.
характеризуется распределением со средним равным нулю и стандартным отклонением равным 1. Площадь между двумя значениями x в нормальном распределении равна площади между ux стандартизованными величинами в единичном нормальном распределении. Нормализованную кривую изобрели для решения задач теории вероятности, но оказалось на практике, что она отлично аппроксимирует распределение черт при большом числе наблюдений для множества переменных. Можно предположить, сто не имея материальных ограничений на количество объектов и время проведения эксперимента, статистическое исследование приводило к нормально кривой.
Если при исследовании появляется вопрос о связи между двумя переменными для одного и того же объекта (например, рост и интеллект) мы говорим о двумерных связях и результаты эксперимента находят свое отражение в двумерном распределении частот.
Уравнение поверхности называется двумерным нормальным распределением (гладкая непрерывная колоколообразная поверхность)
Характеристики нормального распределения
Распределение значений x без учета значений y есть нормальное распределение; Распределение значений y без учета значений x, тоже нормальное распределение; Для каждого фиксированного значения x значение y дают нормальное распределение с дисперсиейПри решении вопроса о наличии взаимосвязи (корреляции) между двумя переменными, руководствуются несколькими коэффициентами. Связь, выраженная графически, называется диаграммной рассеивания, где x – оценка IQ, y – оценка теста по математике.
Положение каждого объекта на диаграмме распределения определяется парой значений xi, yi и выражаются по отношению к мере центральной тенденции величинами ![]() ,
, ![]() . Если объект имеет высокие показатели по обеим переменным, то эти величины получаются большими и положительными, в противном случае, если xi, yi малы, то разность большой и отрицательной.
. Если объект имеет высокие показатели по обеим переменным, то эти величины получаются большими и положительными, в противном случае, если xi, yi малы, то разность большой и отрицательной.
В дальнейшем будем говорить о произведении этих разностей и в том случае когда наблюдается прямая связь между этими переменными, произведение будет большим и положительным, следовательно такой же будет и сумма этих произведений ![]() .
.
В случае обратной связи, когда большим значениям yi соответствуют малые значения xi и наоборот, в этом случае произведение разностей будет большим и отрицательным и сумма разностей также будет большой и отрицательной.
Если между переменными не наблюдается какой-либо связи , количество положительных и отрицательных произведений примерно рано и сумма их близка к нулю. Таким образом большая положительная сумма – жесткая прямая зависимость; большая отрицательная сумма – сильная обратная зависимость; близость к нулю – отсутствие зависимости.
Недостатком этой меры является то, что ее величина зависит от числа пар переменных x участвующих в расчетах.
Чтобы избежать связь независимого состояния V групп, мы усредняем эти значения:
Частный случай, ковариация переменной с самой сабой – дисперсия
Чтобы избавить меру связи от отклонений двух групп значений:
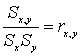 - коэффициент кореляции Пирсона или произведение моментов.
- коэффициент кореляции Пирсона или произведение моментов.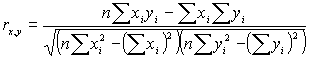
Значение коэффициента Пирсона не может выйти за границы интервала (-1; 1).
Влияние линейного преобразования переменных на коэффициент кореляцииВместо xi вводим в формулу bx+ a, где a, b – коэффициенты, для yi вводим в формулу dy+ c, где c, d – коэффициенты.
![]()
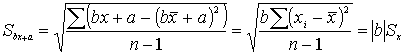
![]()
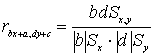
Вопрос о кореляции между переменными будучи решен положительно не означает наличия более общего вида связи (заработная плата учителям и количество поступивших в ВУЗы после окончания школы). Если мы проводим идентификацию групп с различным средним, наличие кореляции не исключено, но возможно другое объяснение взаимосвязи, чем вытекающее их эксперимента. Отсутствие связи при нулевом коэффициента Пирсона означает всего лишь отсутствие линейной связи.
Дисперсия суммы и разности переменных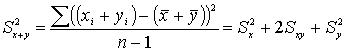
![]()
![]()
Переменная, которую мы хотим оценить называется зависимой переменной или откликом , обозначим ее через y.
Переменная которую мы используем для оценки называется независимой переменной или фактором, ее обозначим через x.
Конкретная характеристика (переменная x) имеющаяся в нашем распоряжении, позволяет получить до проведения эксперимента значение y, зависимой переменной. Мы получаем ![]() используя xi и коэффициенты b1 и b0.
используя xi и коэффициенты b1 и b0.
Даже при наилучшем линейном предсказании, предсказание ![]() будет отличаться от реального yi на какую-то величину, которую мы назовем ошибкой оценки и обозначим ei:
будет отличаться от реального yi на какую-то величину, которую мы назовем ошибкой оценки и обозначим ei:
Точность предсказания зависит от того, насколько удачно подобраны коэффициента b1 и b0. Критерием успешности подбора коэффициентов является минимальная величина суммы квадратов всех ошибок оценки ![]() – критерий наименьших квадратов
– критерий наименьших квадратов
Другой критерий: ![]() . Этот критерий приводит к медианой линии регрессии. Из уравнения
. Этот критерий приводит к медианой линии регрессии. Из уравнения ![]() следует
следует ![]()
Исходя из минимизации формулы наименьших квадратов найдем формулы:
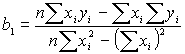 ;
;Наше исследование получается наиболее результативным, если мы предполагаем, что фактор и отклик имеют двумерные нормальные распределения.
Свойства двумерного нормального распределения
Похожие работы
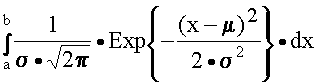
... гипотезу. Вроде бы это надо делать так: Теперь результаты наблюдений над выручкой G можно представить в виде четырех наблюдений над U: –11,+1,+3,+7. Теория математической статистики предлагает следующий, т.н. биномиальный критерий проверки гипотез в подобных ситуациях. Предполагается, что распределение вероятностей наблюдаемой величины U симметрично относительно значения математического ...
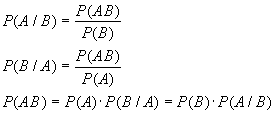
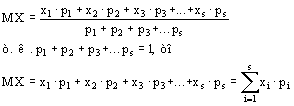
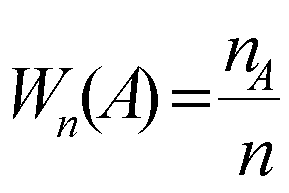
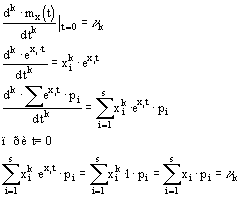
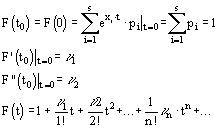
... Доказать: По определению второй смешанной производной. Найдем по двумерной плотности одномерные плотности случайных величин X и Y. Т.к. полученное равенство верно для всех х, то подинтегральные выражение аналогично В математической теории вероятности вводится как базовая формула (1) ибо предлагается, что плотность вероятности как аналитическая функция может не существовать. Но т.к. в нашем ...
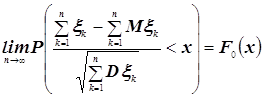
... проверить знания студента из первой части курса, которая излагается в первых четырёх модулях. Во вторых вопросах билета проверяются знания классической предельной проблемы теории вероятностей и математической статистики, которые излагаются в следующих пяти модулях. 1. Вероятностная модель с не более чем счётным числом элементарных исходов. Пример: испытания с равновозможными исходами. 2. ...

... выборок. 5. Исследовательские проекты и их защита. 3 2 1 2 2 2 1 1 1 3 2 1 2 2 Всего 10 5 10 Итого 60 34 Глава 2 Методика обучения школьников основам комбинаторики, теории вероятностей и математической статистики в рамках профильной школы 2.1. Организация при формировании пространственного образа, c использованием ...
0 комментариев