Навигация
Алгоритмы поиска подстроки в строке
28127
знаков
4
таблицы
12
изображений
Введение
Глава 1. Теоретические сведения об алгоритмах поиска подстроки в строке 1.1. Основные понятия
Глава 2. Практическая часть. Дан некоторый текст, в котором следует найти фрагмент этого текста.
Глава 3. Анализ алгоритмов

Цель курсовой работы: Изучить и проанализировать алгоритмы поиска подстроки в строке, и рассмотреть ряд практических задач на данную тематику.
Задачи курсовой работы: изучить задачи связанные с проблемой поиска подстроки в строке, дать основные определения; рассмотреть применение различных алгоритмов поиска подстроки в строке на практике; написать программный код, реализующий один из алгоритмов поиска подстроки в строке.
Тема моей курсовой работы является актуальной и на сегодняшний день, те, кому приходиться часто работать с текстовыми редакторами, знают цену функции нахождения нужных слов в тексте, существенно облегчающей редактирование документов и поиск нужной информации. Действительно, современные программы обработки текста приучили нас к такой удобной возможности, как поиск и замена фрагментов, и если разрабатывать подобную программу, пользователь вправе ожидать, что в его распоряжении будут соответствующие команды.
Конечно, сейчас функции поиска инкапсулированы во многие языки программирования высокого уровня, поэтому чтобы найти строчку в небольшом тексте используется встроенная функция. Но если такого рода поиск является ключевой задачей программы, знать принципы организации функций поиска будет полезным. В готовых подпрограммах далеко не всегда все написано лучшим образом. Во-первых, в стандартных функциях не всегда используются самые эффективные алгоритмы, а во-вторых, вполне возможно, что понадобится изменить стандартное поведение этих функций (например, предусмотреть возможность поиска по шаблону). Наконец, область применения функции поиска не ограничивается одними лишь текстовыми редакторами. Следует отметить использование алгоритмов поиска при индексации страниц поисковым роботом, где актуальность информации напрямую зависит от скорости нахождения ключевых слов в тексте html. Работа простейшего спам–фильтра, заключается в нахождении в тексте письма фраз таких, как «Миллион за час» или «Раскрутка сайта». Это всё говорит об актуальности проблемы поиска.
Работа содержит три основных главы. В первой будут рассмотрены алгоритмы, их теоретическое обоснование, алгоритмическая модель, будет проведена попытка их классификации. Во второй главе будет рассмотрена практическая часть курсовой работы. Реализован программный код поиска подстроки в строке при помощи алгоритма последовательного поиска. В третьей главе работы будут приведены данные о практическом применении алгоритмов. В заключении будет сделан вывод о наиболее эффективном (с временной точки зрения) алгоритме.
Глава 1. Теоретические сведения об алгоритмах поиска подстроки в строке 1.1. Основные понятия
Определение. Строка (слово) - это последовательность знаков (называемых буквами) из некоторого конечного множества, называемого алфавитом.
Определение . Длина строки – количество знаков в строке.
Слова обозначаются буквами латинского алфавита, напр. X=x[1]x[2]…x[n] – слово длинной n, где x[i] (i-ая буква слова) принадлежит алфавиту. Lentgh(X)=![]() =n – обозначение длины строки.
=n – обозначение длины строки.
Определение . Слово не содержащее ни одной буквы называется пустым.
Пустое слово обычно обозначается буквой L. Length(L)=0.
Определение . Слово X называется префиксом слова Y, если есть такое слово Z, что Y=XZ. Причем само слово является префиксом для самого себя (т.к. найдется нулевое слово L, что X=LX.
Пример: слово ab является префиксом слова abcfa.
Определение . Слово X называется суффиксом слова Y, если есть такое слово Z, что Y=ZX. Аналогично, слово является суффиксом самого себя.
Пример: слово bfg является суффиксом слова vsenfbfg.
Определение . Слово X называется подстрокой строки Y, если найдутся такие строки Z1 и Z2, что Y=Z1XZ2. При этом Z1 называется левым, а Z2 - правым крылом подстроки. Подстрокой может быть и само слово. Иногда при этом слово X называют вхождением в слово Y. Среди всех вхождений слова X в слово Y, вхождение с наименьшей длиной своего левого крыла называют первым или главным вхождением. Для обозначения вхождения используют обозначение X![]() Y.
Y.
Пример: слова hrf и fhr является подстроками слова abhrfhr, gf![]() sfdgfro.
sfdgfro.
В программировании понятие сложности алгоритма связано с использованием ресурсов компьютера: насколько много процессорного
времени требует программа для своего выполнения, насколько много при этом расходуется память машины? Учет памяти обычно ведется по объему данных и не принимается во внимание память, расходуемая для записи команд программы. Время рассчитывается в относительных единицах так, чтобы эта оценка, по возможности, была одинаковой для машин с разной тактовой частотой.
Существует две характеристики сложности алгоритмов - временная и емкостная.
Временная сложность будет подсчитываться в исполняемых командах: количество арифметических операций, количество сравнений, пересылок (в зависимости от алгоритма). Емкостная сложность будет определяться количеством переменных, элементов массивов, элементов записей или просто количеством байт.
Эффективность алгоритма также будет оцениваться с помощью подсчета времени выполнения алгоритмом конкретно поставленной задачи, т.е. с помощью эксперимента, подробнее об этом в главе 2 данной работы.
1.2. Алгоритм последовательного (прямого) поискаСамый очевидный алгоритм. Обозначеное S - слово, в котором ищется образец X. Пусть m и n - длины слов S и X соответственно. Можно сравнить со словом X все подслова S, которые начинаются с позиций 1,2,...,m-n+1 в слове S; в случае равенства выводится соответствующая позиция. Реализация этого алгоритма представлена в приложении 1.
Это не эффективный алгоритм т.к. максимальное, количество сравнений будет равно O((m-n+1)*n+1), хотя большинство из них на самом деле лишние. Оценим скорость работы этого программного кода. В ней присутствуют два цикла (один вложенный), время работы внешнего большей степенью зависит от n, а внутренний в худшем случае делает m операций. Таким образом, время работы всего алгоритма есть O((n-m+1)m). Для маленьких строк поиск проработает быстро, но если в каком-то многомегабайтном файле будет искаться последовательность длинной 100 Кб, то придется ждать ну очень долго. Впрочем многим хватает и этого. Например, найдя строку aabc и обнаружив несоответствие в четвертом символе (совпало только aab), алгоритм будет продолжать сравнивать строку, начиная со следующего символа, хотя это однозначно не приведет к результату.
1.3. Алгоритм РабинаАлгоритм Рабина представляет собой модификацию линейного алгоритма.
В слове A, длина которого равна m, ищется образец X длины n. Вырежем "окошечко" размером n оно двигается по входному слову. Совпадает ли слово в "окошечке" с заданным образцом? Фиксируется некоторая числовая функция на словах длины n, тогда задача сводится к сравнению чисел, что, несомненно, быстрее. Если значения этой функции на слове в "окошечке" и на образце различны, то совпадения нет. Только если значения одинаковы, необходимо проверять последовательно совпадение по буквам.
Этот алгоритм выполняет линейный проход по строке (n шагов) и линейный проход по всему тексту (m шагов), стало быть, общее время работы есть O(n+m). При этом не учитывается временная сложность вычисления хеш-функции, так как, суть алгоритма в том и заключается, чтобы данная функция была настолько легко вычисляемой, что ее работа не влияла на общую работу алгоритма. Тогда, время работы алгоритма линейно зависит от размера строки и текста, стало быть программа работает быстро. Ведь вместо того, чтобы проверять каждую позицию на предмет соответствия с образцом, можно проверять только те, которые «напоминают» образец. Итак, для того, чтобы легко устанавливать явное несоответствие, будет использоваться функция, которая должна:
1. Легко вычисляться.
2. Как можно лучше различать несовпадающие строки.
3. hash( y[ i+1 , i+m ] ) должна легко вычисляться по hash( y[ i , i+m-1 ].
Во время поиска х будет сравниваться hash( x ) с hash( y[ i, i+m-1 ] ) для i от 0 до n-m включительно. Если обнаруживается совпадение, то проверяется посимвольно. Реализация этого алгоритма представлена в приложении 2.
Пример (удобной для вычисления функции). Заменяются все буквы в слове и образце их номерами, представляющими собой целые числа. Тогда удобной функцией является сумма цифр. (При сдвиге "окошечка" нужно добавить новое число и вычесть "пропавшее".)
Однако, проблема в том, что искомая строка может быть длинной, строк в тексте тоже хватает. А так как каждой строке нужно сопоставить уникальное число, то и чисел должно быть много, а стало быть, числа будут большими (порядка D*n, где D - количество различных символов), и работать с ними будет так же неудобно. Но какой интерес работать только с короткими строками и цифрами? Выше рассмотренный алгоритм можно улучшить.
Пример (семейства удобных функций). Выбирается некоторое число p (желательно простое) и некоторый вычет x по модулю p. Каждое слово длины n будет рассматриваться как последовательность целых чисел (заменив буквы их кодами). Эти числа будут рассматриваться как коэффициенты многочлена степени n-1 и вычисляется значение этого многочлена по модулю p в точке x. Это и будет одна из функций семейства (для каждой пары p и x получается своя функция). Сдвиг "окошечка" на 1 соответствует вычитанию старшего члена, умножению на x и добавлению свободного члена. Следующее соображение говорит в пользу того, что совпадения не слишком вероятны. Пусть число p фиксировано и к тому же оно является простым, а X и Y - два различных слова длины n. Тогда им соответствуют различные многочлены (мы предполагаем, что коды всех букв различны - это возможно при p, большем числа букв алфавита). Совпадение значений функции означает, что в точке x эти два различных многочлена совпадают, т.е. их разность обращается в 0. Разность есть многочлен степени n-1 и имеет не более n-1 корней. Таким образом, если n много меньше p, то случайному значению x мало шансов попасть в "неудачную" точку.
Строго говоря, время работы всего алгоритма в целом, есть O(m+n+mn/P), mn/P достаточно невелико, так что сложность работы почти линейная. Понятно, что простое число следует выбирать большим, чем больше это число, тем быстрее будет работать программа.
Алгоритм Рабина и алгоритм последовательного поиска являются алгоритмами с наименьшими трудозатратами, поэтому они годятся для использования при решении некоторого класса задач. Однако эти алгоритмы не являются наиболее оптимальными (хотя бы потому, что иногда выполняют явно бесполезную работу, о чем было сказано выше), поэтому будет рассматриваться следующий класс алгоритмов. Эти алгоритмы появились в результате тщательного исследования алгоритма последовательного поиска. Исследователи хотели найти способы более полно использовать информацию, полученную во время сканирования (алгоритм прямого поиска ее просто выбрасывает).
1.4.Алгоритм Кнута - Морриса - Пратта (КМП)Метод использует предобработку искомой строки, а именно: на ее основе создается так называемая префикс-функция. Суть этой функции в нахождении для каждой подстроки S[1..i] строки S наибольшей подстроки S[1..j] (j<i), присутствующей одновременно и в начале, и в конце подстроки (как префикс и как суффикс). Например, для подстроки abcHelloabc такой подстрокой является abc (одновременно и префиксом, и суффиксом). Смысл префикс-функции в том, что можно отбросить заведомо неверные варианты, т.е. если при поиске совпала подстрока abcHelloabc (следующий символ не совпал), то имеет смысл продолжать проверку продолжить поиск уже с четвертого символа (первые три и так совпадут). Вначале рассматриваются некоторые вспомогательные утверждения. Для произвольного слова X рассматриваются все его начала, одновременно являющиеся его концами, и выбираются из них самое длинное (не считая, конечно, самого слова X). Оно обозначается n(X). Такая функция носит название префикс – функции [13].
Примеры.
n(aba)=a, n(n(aba))=n(a)=L;
n(abab)=ab, n(n(abab))=n(ab)=L;
n(ababa)=aba, n(n(ababa))=n(aba)=a, n(n(n(ababa)))=n(a)=L; n(abc)=L.
Справедливо следующее предложение:
(1) Последовательность слов n(X),n(n(X)),n(n(n(X))),... "обрывается" (на пустом слове L).
(2) Все слова n(X),n(n(X)),n(n(n(X))),...,L являются началами слова X.
(3) Любое слово, одновременно являющееся началом и концом слова X (кроме самого X), входит в последовательность n(X),n(n(X)),....,L.
Метод КМП использует предобработку искомой строки, а именно: на ее основе создается префикс-функция. При этом используется следующая идея: если префикс (он же суффикс) строки длинной i длиннее одного символа, то он одновременно и префикс подстроки длинной i-1. Таким образом, проверяется префикс предыдущей подстроки, если же тот не подходит, то префикс ее префикса, и т.д. Действуя так, находится наибольший искомый префикс. (см. приложение 3).
Следующий вопрос, на который стоит ответить: почему время работы процедуры линейно, ведь в ней присутствует вложенный цикл? Ну, во-первых, присвоение префикс-функции происходит четко m раз, остальное время меняется переменная k. Так как в цикле while она уменьшается (P[k]<k), но не становится меньше 0, то уменьшаться она может не чаще, чем возрастать. Переменная k возрастает на 1 не более m раз. Значит, переменная k меняется всего не более 2m раз. Выходит, что время работы всей процедуры есть O(m).
Алгоритм последовательного поиска и алгоритм КМП помимо нахождения самих строк считают, сколько символов совпало в процессе работы. Реализация этого алгоритма представлена в приложении 4.
1.5. Алгоритм Бойера – МураАлгоритм Бойера-Мура, разработанный двумя учеными – Бойером и Муром, считается наиболее быстрым среди алгоритмов общего назначения, предназначенных для поиска подстроки в строке.
Простейший вариант алгоритма Бойера-Мура состоит из следующих шагов. На первом шаге строится таблица смещений для искомого образца. Процесс построения таблицы будет описан ниже. Далее совмещается начало строки и образца и начинается проверка с последнего символа образца. Если последний символ образца и соответствующий ему при наложении символ строки не совпадают, образец сдвигается относительно строки на величину, полученную из таблицы смещений, и снова проводится сравнение, начиная с последнего символа образца. Если же символы совпадают, производится сравнение предпоследнего символа образца и т. д. Если все символы образца совпали с наложенными символами строки, значит нашлась подстрока и поиск окончен. Если же какой-то (не последний) символ образца не совпадает с соответствующим символом строки, сдвигается образец на один символ вправо и снова начинается проверку с последнего символа. Весь алгоритм выполняется до тех пор, пока либо не будет найдено вхождение искомого образца, либо не будет достигнут конец строки.
Величина сдвига в случае несовпадения последнего символа вычисляется исходя из следующих соображений: сдвиг образца должен быть минимальным, таким, чтобы не пропустить вхождение образца в строке. Если данный символ строки встречается в образце, смещается образец таким образом, чтобы символ строки совпал с самым правым вхождением этого символа в образце. Если же образец вообще не содержит этого символа, сдвигается образец на величину, равную его длине, так что первый символ образца накладывается на следующий за проверявшимся символ строки.
Величина смещения для каждого символа образца зависит только от порядка символов в образце, поэтому смещения удобно вычислить заранее и хранить в виде одномерного массива, где каждому символу алфавита соответствует смещение относительно последнего символа образца.
Пример. Пусть есть алфавит из пяти символов: a, b, c, d, e и надо найти вхождение образца “abbad” в строке “abeccacbadbabbad”. Следующие схемы иллюстрируют все этапы выполнения алгоритма. Таблица смещений будет выглядеть так.
![]()
Начало поиска.
![]()
Последний символ образца не совпадает с наложенным символом строки. Сдвигается образец вправо на 5 позиций:
![]()
Три символа образца совпали, а четвертый – нет. Сдвигается образец вправо на одну позицию:
![]()
Последний символ снова не совпадает с символом строки. В соответствии с таблицей смещений сдвигается образец на 2 позиции:
![]()
Еще раз сдвигается образец на 2 позиции:
![]()
Теперь, в соответствии с таблицей, сдвигается образец на одну позицию, и получается искомое вхождение образца:
![]()
Прежде всего следует определить тип данных «таблица смещений». Для кодовой таблицы, состоящей из 256 символов, определение этого типа будет выглядеть так:
Type
TBMTable = Array [0..255] of Integer;
Реализация процедуры, вычисляющая таблицу смещений для образца p, представлена в приложении 5.
Теперь пишется функция, осуществляющая поиск (см. Приложение 6).
Параметр StartPos позволяет указать позицию в строке s, с которой следует начинать поиск. Это может быть полезно в том случае, если надо найти все вхождения p в s. Для поиска с самого начала строки следует задать StartPos равным 1. Если результат поиска не равен нулю, то для того, чтобы найти следующее вхождение p в s, нужно задать StartPos равным значению «предыдущий результат плюс длина образца».
Глава 2. Практическая часть. Дан некоторый текст, в котором следует найти фрагмент этого текста.
Данную задачу можно интерпретировать как поиск подстроки в строке.
Эту задачу я реализовал при помощи алгоритма последовательного (прямого) поиска. Программный код задачи реализовал на языке программирования Turbo Pascal 7.1 и он представлен в приложении 7.
Описание работы программы.
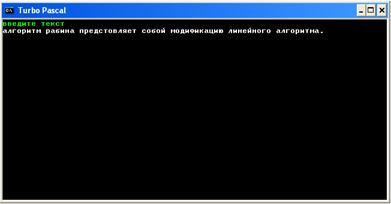
После запуска программа запрашивает ввод текста:
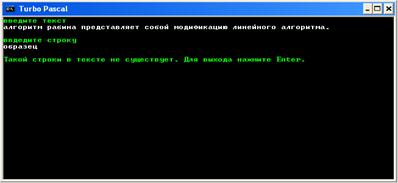
Например, введём следующий текст: ”алгоритм рабина представляет собой модификацию линейного алгоритма.”
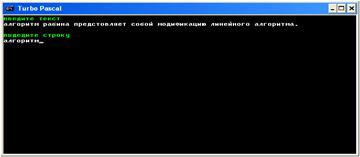
Далее программа запрашивает ввод строки(подстроки) для поиска:
Например, вводим фрагмент текста: ”алгоритм”
После ввода, программа ищет строку в тексте, если строка существует то программа выводит текст на экран, выделяет строку красным цветом и выдает с какого символа начинается строка:
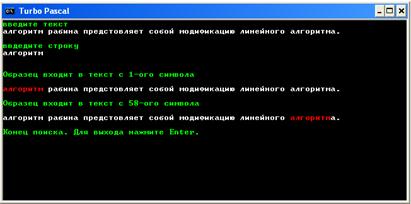
Если фрагмента нет в тексте, то программа выдаст сообщение о том, что данной строки в тексте не существует:
Глава 3. Анализ алгоритмов
В курсовой работе я рассмотрел несколько алгоритмов. Была проведена оценка их временной и емкостной сложности. Экспериментальный анализ состоял в измерении времени, за которое алгоритм выполняет конкретно поставленную задачу.
Задача: Имеется несколько текстовых файлов, содержащих 10000 записей вида:
- строка
- подстрока (имеющаяся в данной строке)
- место вхождения
- длина подстроки,
причем с разными максимальными длинами строк и подстрок.
Алфавит кириллицы содержит 32 буквы, поэтому длина строки будет не более 10, 100, 250 символов.
Проводится поиск подстрок в строках для каждого из алгоритмов и измеряется время работы программы. При этом будет учитываться следующее:
· строки предварительно загружаем в оперативную память (в виде массива), причем время считывания в массив не учитывается. Предобработка (создание таблиц перехода) входит в общее время.
· каждый алгоритм запускается 5 раз, время выбирается наименьшее.
Эксперимент проходил на ПК:
Процессор Intel Pentium IV 2,66Ггц
Похожие работы
... - код не совпадает, сравнение не проводим. QWERYTEWEQWERTY FS = 25 - [E] + [Y] = 25 - 3 + 6 = 28 - код совпадает, полное сравнение совпадает. Ура! Текст программы: Program FSISHF; {поиск подстроки в строке} Const NStr = 30000; NSub = 3000; Var FStr : array[1..NStr] of char; FSub : array[1..NSub] of char; {substring} FSum, NSum : longint; {Контрольная сумма} Spec, Work : word; ...
... (Robert S. Boyer) и Муром (J. Strother Moore), считается наиболее быстрым среди алгоритмов общего назначения, предназначенных для поиска подстроки в строке. Прежде чем рассмотреть работу этого алгоритма, уточним некоторые термины. Под строкой мы будем понимать всю последовательность символов текста. Собственно говоря, речь не обязательно должна идти именно о тексте. В общем случае строка – это ...
... какой либо ситуации - Определить результат действия программы. На основании сделанных выводов решено создать дополнительное обучающее средство в виде обучающей программы, поддерживающей индивидуальное изучение всех вопросов темы, а также, дополнительные сведения о типах данных. Кроме того, в программу будет встроен блок самоконтроля, поддерживающий проверку усвоения каждой изучаемой ...
... шкалы оценка пертинентности // НТИ. Сер. 2.- 1992.-№5.-С.19-27 Кноп К. Поиск в Интернете как хроническое заболевание // Мир Internet. - 2002. - N 10. - С. 33-35 Конжаев А. Стратегия информационного поиска // http://www.msiu.ru. Попов С. Поиск информации и принятие решения // НТИ. Сер.2.-2001.-№1.-С.1-4 Степанов В.К Русскоязычные поисковые механизмы в Интернет // ComputerWorld Россия.-1997.-N11 ...
0 комментариев