Навигация
1024 Мб ОЗУ
Компилятор Turbo Pascal 7.1
Фрагмент кода тестируемой программы приводится в Приложении 8.
Такой замер времени даст приблизительные результаты, так как напрямую зависит от характеристик и загрузки процессора. Поэтому во время проведения эксперимента, отключались все сторонние и фоновые приложения, которые не влияют на работу программы. При запуске одной и той же задачи можно получить разное время, поэтому совершается несколько запусков, из которых выбирается наилучший результат.
Эксперимент проводился для четырех алгоритмов – представителей классов алгоритмов. Так как все алгоритмы ставились в одинаковые условия, то можно провести их сравнительный анализ. Заметим, что данный анализ применим только для данных параметров поиска, и при иных условиях может отличаться.
|
| Алгоритм | Время выполнения (мс) | ||
| Длина ≤10 | Длина ≤100 | Длина ≤250 | |
| Послед. Поиск | 15 | 93 | 234 |
| Алгоритм Рабина | 15 | 63 | 93 |
| КМП | 5 | 30 | 50 |
| БМ | 31 | 31 | 32 |
Из таблицы видно, что алгоритм Бойера – Мура справился с экспериментальной задачей быстрее остальных. Следует, однако, заметить, что его эффективность растет лишь с увеличением длины строки и, соответственно, длины образца. Так при длине строки меньшей или равной 10 символов, он показал себя хуже, чем последовательный поиск. Аналогичные результаты показывает и алгоритм КМП, как для коротких, так и для длинных слов. Его можно использовать как универсальный, когда неизвестны длины строки и образца.
Алгоритм Рабина, при его схожести с последовательным работает быстрее, а его простота и малые трудозатраты на реализацию, делают его привлекательным для использования в неспециальных программах.
Наихудший результат показал алгоритм последовательного поиска. Как предполагалось лишь при небольшом увеличении длины строки, он работает существенно медленнее остальных алгоритмов.
Заключение
В процессе выполнения курсовой работы были рассмотрены различные алгоритмы поиска подстроки в строке и проведен их сравнительный анализ, результаты которого представлены в таблице 2 (см. приложение 9).
Изучив полученные результаты легко можно сделать вывод, что алгоритм Бойера – Мура является ведущим по всем параметрам. Но, как показывает эксперимент, алгоритм Кнута – Мориса - Пратта, превосходит алгоритм БМ на небольших длинах образца. Поэтому нельзя сделать вывод, что какой-то из алгоритмов является самым оптимальным. Каждый алгоритм эффективно работает в определенных классах задач, об этом еще говорят различные узконаправленные улучшения каждого из алгоритмов. Таким образом, тип алгоритмов поиска подстроки в строке следует выбирать только после точной постановки задачи, определение её целей и функциональности, которая она должна реализовать.
Только после этого этапа необходимо переходить к реализации программного кода.
В связи с глобализацией информации в сети internet был разработан интеллектуальный поиск. Который позволяет найти документ по смыслу содержащейся в нем информации, то есть документы по заданной теме. В системе реализован алгоритм с использованием компьютерной обработки документа. Согласно гипотезе Ципфа смысл документа зависит от частоты терминов, встречающихся в документе. Однако гораздо важнее не сама частота слова, а то, насколько часто в текущем документе это слово встречается относительно других слов.
Список используемой литературы:
1) Альсведе Р., Вегенер И. "Задачи поиска" , 1982г, Издательство "Мир"
2). Ахо, Альфред Структура данных и алгоритмы [Текст]. – М.: Издательский дом «Вильямс», 2000. - 384 с.
3). Белоусов А. Дискретная математика [Текст]. – М.: Издательство МГТУ им. Н.Э. Баумана, 2001. – 744 с.
4). Брайан, К. Практика программирования [Текст].- СПб:. Невский диалект, 2001. - 381 с.
5). Вирт, Н. Алгоритмы и структуры данных [Текст].– М:. Мир, 1989. – 360 с.
6) Кнут, Д. Искусство программирования на ЭВМ [Текст]: Том 3. – М:. Мир, 1978. – 356 с.
7). Кормен, Т. Алгоритмы: построение и анализ [Текст]/ Т. Кормен, Ч. Лейзерсон, Р. Ривест - М.: МЦНМО, 2002. М.: МЦНМО, 2002.
8). Успенский В. Теория алгоритмов: основные открытия и приложения [Текст]. – М.: Наука, 1987. – 288 с.
9). Шень, А. Программирование: теоремы и задачи [Текст]. – М.: Московский центр непрерывного математического образования, 1995.
Электронные источники.
1) http://www.ipkro.isu.ru/informat/methods/findsort/
2) http://www.delphikingdom.com/asp/viewitem.asp?catalogid=65
3) http://revolution./programming/00013926_0.html
4) http://ric.uni-altai.ru/fundamental/pascal1/lab15/l15-teor.htm
5) http://www.rsdn.ru/article/alg/textsearch.xml
Приложение 1
Реализация алгоритма последовательного поиска
|

Приложение 2
Реализация алгоритма Рабина
|

Приложение 3 Алгоритм Кнута-Морриса-Пратта
Нахождение наибольшего искомого префикса.
|

Приложение 4
Реализация алгоритма Кнута-Морриса-Пратта
|

Приложение 5
Алгоритм Бойера-Мура Реализация процедуры, вычисляющая таблицу смещений для образца p.
|

Приложение 6
Алгоритм Бойера-МураФункция, осуществляющая поиск.
|

Приложение 7
Реализация программного кода
|

|
Приложение 8
Фрагмент кода тестируемой программы
|

Приложение 9
Общие результаты с анализов рассмотренных алгоритмов
|
| Примечания | Алгоритмы, основанные на алгоритме последовательного поиска | Малые трудозатраты на программу, малая эффективность | Алгоритм Кнута-Морриса-Пратта | Универсальный алгоритм, если неизвестна длина образца | Алгоритм Бойера-Мура | Алгоритмы этой группы наиболее эффективны в обычных ситуациях. Быстродействие повышается при увеличении образца или алфавита. | |
| Время работы (мс) при длине строки ≤250 | 234 | 93 | 31 | 32 | |||
| Затраты памяти | нет | нет | O(m) | O(m+s) | |||
| Худшее время поиска | O((m-n+1)*n+1) | O((m-n+1)*n+1) | O(n+m) | O(n*m) | |||
| Среднее время поиска | O((m-n+1)*n+1)/2 | O(n+m) | O(n+m) | O(n+m) | |||
| Время на пред. обработку | нет | нет | O(m) | O(m+s) | |||
| Алгоритм | Алгоритм прямого поиска | Алгоритм Рабина | КМП | БМ | |||
Похожие работы
... - код не совпадает, сравнение не проводим. QWERYTEWEQWERTY FS = 25 - [E] + [Y] = 25 - 3 + 6 = 28 - код совпадает, полное сравнение совпадает. Ура! Текст программы: Program FSISHF; {поиск подстроки в строке} Const NStr = 30000; NSub = 3000; Var FStr : array[1..NStr] of char; FSub : array[1..NSub] of char; {substring} FSum, NSum : longint; {Контрольная сумма} Spec, Work : word; ...
... (Robert S. Boyer) и Муром (J. Strother Moore), считается наиболее быстрым среди алгоритмов общего назначения, предназначенных для поиска подстроки в строке. Прежде чем рассмотреть работу этого алгоритма, уточним некоторые термины. Под строкой мы будем понимать всю последовательность символов текста. Собственно говоря, речь не обязательно должна идти именно о тексте. В общем случае строка – это ...
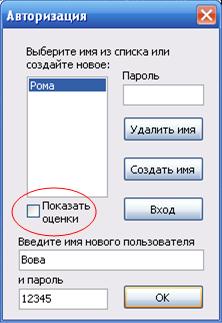
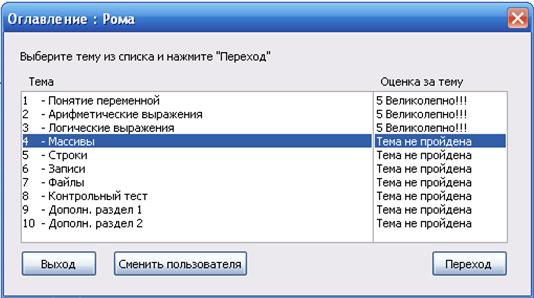
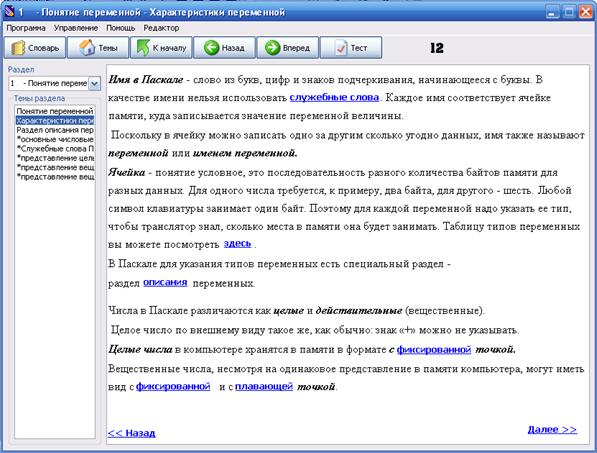
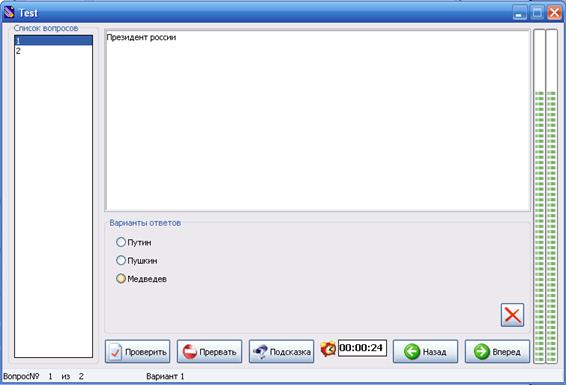
... какой либо ситуации - Определить результат действия программы. На основании сделанных выводов решено создать дополнительное обучающее средство в виде обучающей программы, поддерживающей индивидуальное изучение всех вопросов темы, а также, дополнительные сведения о типах данных. Кроме того, в программу будет встроен блок самоконтроля, поддерживающий проверку усвоения каждой изучаемой ...

... шкалы оценка пертинентности // НТИ. Сер. 2.- 1992.-№5.-С.19-27 Кноп К. Поиск в Интернете как хроническое заболевание // Мир Internet. - 2002. - N 10. - С. 33-35 Конжаев А. Стратегия информационного поиска // http://www.msiu.ru. Попов С. Поиск информации и принятие решения // НТИ. Сер.2.-2001.-№1.-С.1-4 Степанов В.К Русскоязычные поисковые механизмы в Интернет // ComputerWorld Россия.-1997.-N11 ...
0 комментариев