Навигация
4.2 Опис програми
Основним результатом дипломної роботи є програмний продукт. В роботі представлена програма під назвою «Інтервальне значення параметрів», яка реалізує знаходження інтервалів для коефіцієнтів регресії. Під час роботи ця програма використовує допоміжні процедури, які обчислюють класичну оцінку коефіцієнтів регресії та нотну. Програма написана в прикладному математичному пакеті Maple, який являється одним з самих потужних інтелектуальних систем комп`ютерної алгебри. Результати програми представлені на графіках.
Програма складається з чотирьох процедур та реалізації графічного інтерфейсу.
Спочатку відбувається підключення необхідних модулів:
restart;
with(LinearAlgebra):
with(plots):
with(stats):
Надалі розглянемо процедури, які були використані в даній програмі.
Розглянемо процедуру під назвою ocenki_parametrov. Ця процедура отримує вхідні дані, які вводить користувач та знаходить оцінки коефіцієнтів лінійної регресії за допомогою методу найменших квадратів (МНК). В ній оголошені такі змінні: viborka– це вибірка з якою ми будемо працювати, вона вводиться з клавіатури користувачем; nomer_zavis_koord –вектор Y.
В процедурі задані локальні змінні, які використовуються у якомусь невеликому відрізку програми, це може бути невеликий цикл тощо.
В якості локальних змінних оголошенні kol_strok- кількість строк матриці matrica_X що вводиться з клавіатури користувачем, kol_stolbcov- кількість стовпчиків даної матриці, X_transpon- транспонована матриця до матриці Х, vektor_Y- вектор спостережень, otvet- вектор-стовпчик оцінок коефіцієнтів, що знаходяться за формулою ![]() .
.
otvet:=MatrixMatrixMultiply(MatrixMatrixMultiply(otvet_prom,X_transpon),vektor_Y):.
Розглянемо процедуру під назвою Notna ocenki_parametrov. Ця процедура отримує вхідні дані, які вводить користувач та знаходить нотну. В ній оголошені такі змінні: viborka– це вибірка з якою ми будемо працювати, вона вводиться з клавіатури користувачем; nomer_zavis_koord –вектор Y, pogr – це похибка, її користувач визначає самостійно і вводить з клавіатури.
В процедурі задані локальні та глобальні змінні, локальні змінні використовуються у якомусь невеликому відрізку програми, це може бути невеликий цикл тощо, а глобальні змінні фігурують на протязі всієї програми.
В якості локальних змінних оголошені n- кількість строк матриці Х, m- кількість стовпчиків матриці Х, j,k,c,i – номер елемента вибірки, kol_strok та kol_stolbcov - розмір матриці Х, matrica_X що вводиться з клавіатури користувачем, vektor_Y- вектор спостережень, pogr_Y,pogr_X - це похибки, її користувач визначає самостійно і вводить з клавіатури, vector_beta - вектор-стовпчик знайденних оцінок коефіцієнтів в процедурі ocenki_parametrov,
pod_sum_vnutr – значення яке відповідає формулі
![]() ,
,
summa_vnutr - значення яке відповідає формулі
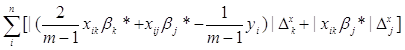 ,
,
sum_vnesh - значення яке відповідає формулі
![]() ,
,
pod_summa_2 - значення яке відповідає формулі ![]() , summa_2 - значення яке відповідає формулі
, summa_2 - значення яке відповідає формулі
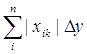 ,
,
summa - значення яке відповідає формулі
![]() .
.
Глобальні змінні otv – значення нотни, знайдене за формолою
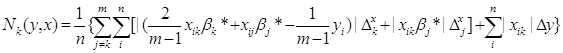
Далі в процедурі формуються масиви для pod_sum_vnutr, summa_vnutr, sum_vnesh, pod_summa_2, summa_2, summa які використовуються для подальших обчислень.
pod_sum_vnutr:=array(1..n):
summa_vnutr:=array(1..m):
sum_vnesh:=array(1..m):
pod_summa_2:=array(1..n):
summa_2:=array(1..m):
summa:=array(1..m):
Розмір матриці Х формується за допомогою функцій RowDimension та ColumnDimension.
kol_strok:=RowDimension(viborka):
kol_stolbcov:=ColumnDimension(viborka):
Так як формула для знаходження нотни є складною, обчислимо її частинами, щоб спростити дії для машини та не помилитись.
Спочатку рахуємо вираз під внутрішньою сумою.
for i to n do
pod_sum_vnutr[i]:=abs(2*matrica_X[i,k]*vector_beta[k,1]/(m-1) +matrica_X[i,j]*vector_beta[j,1]-vektor_Y[i,1]/(m-1))*pogr_X[k] +abs(matrica_X[i,k]*vector_beta[j,1])*pogr_X[j]
end do:
Далі знаходимо значення під внутрішньою сумою.
for j to m do
summa_vnutr[j]:=sum('pod_sum_vnutr[ii]','ii'=1..n):
end do:
Рахуємо зовнішню суму.
for k to m do
sum_vnesh[k]:=sum('summa_vnutr[jj]','jj'=1..k-1) +sum('summa_vnutr[jj]','jj'=k+1..m):
end do:
Рахуємо другу частину формули.
for c to n do
pod_summa_2[c]:=abs(matrica_X[c,k]):
end do:
summa_2[k]:=sum('pod_summa_2[d]','d'=1..n)*pogr_Y:
summa[k]:=(sum_vnesh[k]+summa_2[k])/n:
Виводимо відповідь: otv:=summa:
Розглянемо процедуру під назвою interval_znachen_param. В цій процедурі, використовуючи результати попередніх двох процедур ocenki_parametrov та Notna ocenki_parametrov, рахуються інтервали в яких знаходяться оцінки коефіцієнтів регресії. В ній оголошені такі змінні: viborka– це вибірка довільного об’єму та вимірності з якою ми будемо працювати, вона вводиться з клавіатури користувачем; nomer_zavis_koord –номер координати, яка трактується як залежна, pogr – вектор максимальних величин похибок, з якими визначенні координати елементів вибірки.
В процедурі задані локальні та глобальні змінні, локальні змінні використовуються у якомусь невеликому відрізку програми, це може бути невеликий цикл тощо, а глобальні змінні фігурують на протязі всієї програми.
В якості локальних змінних оголошені razmer – кількість стовпців, massiv_interv_koeff, parametric – знайдені оцінки коефіцієнтів, notna-знайдена нотна, і – номер коефіцієнту регресії.
Глобальні змінні interv – шуканий інтервал.
Далі в програмі формуються масиви для massiv_interv_koeff, interv, які використовуються для подальших обчислень.
massiv_interv_koeff:=array(1..razmer):
interv:=Matrix(1..razmer,1..2):
Так як формула для правої та лівої границі інтервалу в методі інтервальних даних є складною, обчислимо її частинами, щоб спростити дії для машини та не помилитись.
for i to razmer do
massiv_interv_koeff[i]:=parametri[i,1]:
interv[i,1]:=massiv_interv_koeff[i]-notna[i]:
interv[i,2]:=massiv_interv_koeff[i]+notna[i]:
end do:
Програма повертає значення верхньої та нижньої меж інтервалів, які накривають коефіцієнти регресії. В результаті роботи цієї процедури ми отримали результати, обчислені у вигляді зручному для побудови графіка за цими даними.
Розглянемо процедуру під назвою generator_viborki. В цій процедурі ми вибираємо вибірку довільного об’єму, значення якої є нормально розподіленими. В ній оголошені такі змінні: DIGITS – кількість знаків після коми, obem_vibork- об’єм нашої вибірки, distrib- вибір розподілу, parametr- коефіцієнти.
В процедурі задані глобальні змінні, що фігурують на протязі всієї програми.
В якості глобальних змінних оголошені VIBORK- це вибірка з якою ми будемо працювати.
Далі в програмі формується масив для VIBORK.
VIBORK:=array(1..obem_vibork):
if distrib=NORMAL then
for i to obem_vibork do
VIBORK[i]:=stats[random, normald[0,parametr]](1):
end do:
Таким чином ми отримаємо вибірку.
Розглянемо процедуру під назвою grafic_ocenok. В цій процедурі за отриманими вище даними будуємо графіки на яких зображені інтервали для коефіцієнтів регресії. В ній оголошені такі змінні: DIGITS – кількість знаків після коми, digits_okrug - кількість знаків після коми значень нашої вибірки, kol_razb - обєм нашої вибірки, distrib – вибір розподілу, parametr - кількість коефіцієнтів регресії, model – рівняння регресії, pogr - похибка.
В процедурі задані локальні та глобальні змінні, локальні змінні використовуються у якомусь невеликому відрізку програми, це може бути невеликий цикл тощо, а глобальні змінні фігурують на протязі всієї програми.
В якості локальних змінних оголошені gg1n, gg1v, gg2n,gg2v – нижня і верхня границі інтервалів для кожного коефіцієнту регресії, s - обєм вибірки.
Глобальні змінні ViBVreM - це округлена вибірка, INTERVAL- інтервальне значення параметрів.
Далі в програмі формуються масиви для верхніх і нижніх меж
gg1n:=array(2..kol_razb):
gg1v:=array(2..kol_razb):
Задаємо колір нижньої та верхньої меж та істинного значення для двох коефіцієнтів.
ggg1n:=[seq([b,gg1n[b]],b=2..kol_razb)]:
g1:=plot(ggg1n,'colour'='blue',legend="Нижня межа");
ggg1v:=[seq([b,gg1v[b]],b=2..kol_razb)]:
g2:=plot(ggg1v,'colour'='green',legend="Верхня межа");
ggg2n:=[seq([b,gg2n[b]],b=2..kol_razb)]:
g21:=plot(ggg2n,'colour'='blue',legend="Нижня межа");
ggg2v:=[seq([b,gg2v[b]],b=2..kol_razb)]:
g22:=plot(ggg2v,'colour'='green',legend="Верхня межа");
gt:=plot(2,t=0..kol_razb,'colour'='red',legend="Істинне значення"):
gt:=plot(-4,t=0..kol_razb,'colour'='red',legend="Істинне значення"):
Підписуємо графіки
display([g1,g2,gt],'title'="Обчислення першого коефіціента регресіі",'titlefont'=[TIMES,BOLD,18]):
display([g21,g22,gt],'title'="Обчислення другого коефіціента регресіі",'titlefont'=[TIMES,BOLD,18]):
Таким чином результати розробленої програми представлені на графіках.
Похожие работы



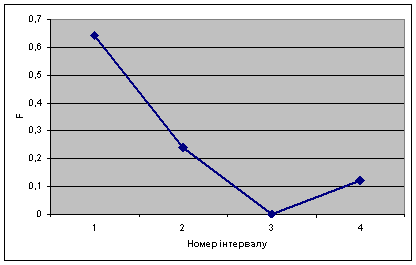
... іжності між емпіричними і теоретичними частотами розподілу не можуть бути випадковими і припущення про близькість емпіричного розподілу до нормального повинна бути спростоване. Розділ 3. Кореляційний аналіз виробництва льоноволокна Одним з найважливіших завдань статистики є вивчення об'єктивно існуючих зв'язків між явищами. При дослідженні таких зв'язків з'ясовуються причинно-наслідкові ві ...
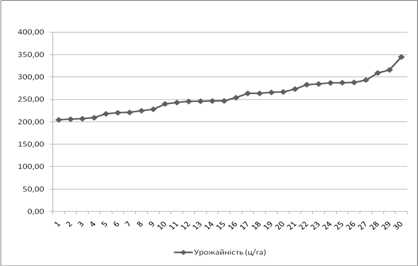
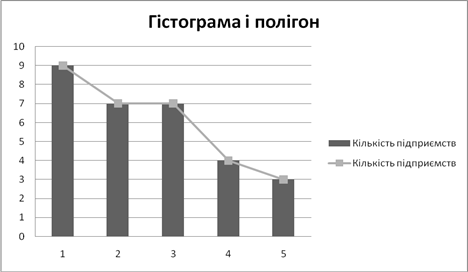
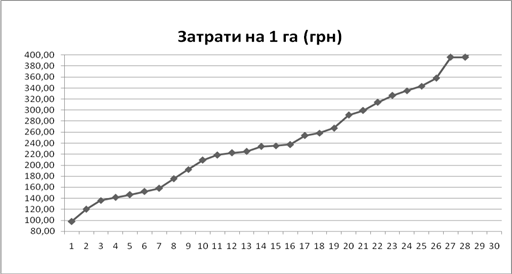
... ідного індексу, а абсолютні величини змін валового збору за рахунок даного фактора — як різницю чисельника і знаменника відповідного індексу. 2. СТАТИСТИЧНИЙ АНАЛІЗ УРОЖАЙНОСТІ ТЕХНІЧНИХ КУЛЬТУР 2.1 Аналіз рівня та факторів урожайності методом аналітичного групування Групування — невід'ємний елемент зведення, його найважливіший етап. Це процес утворення груп одиниць сукупності, однорідних ...
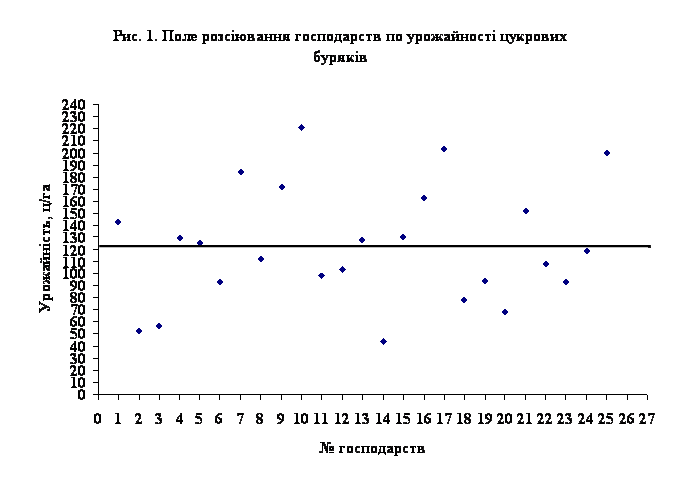
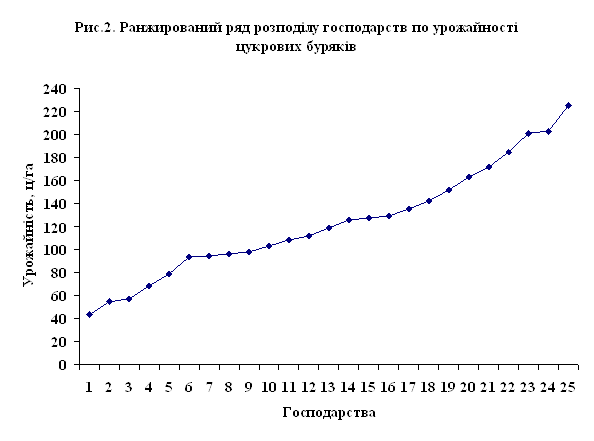
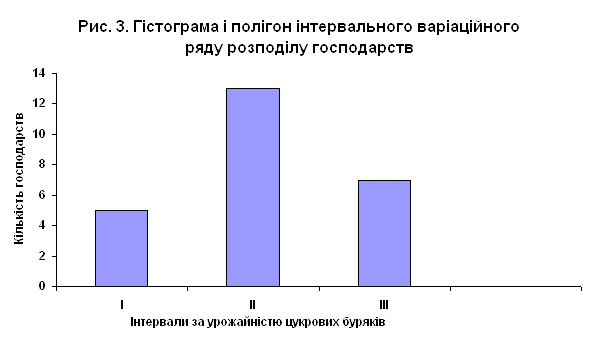
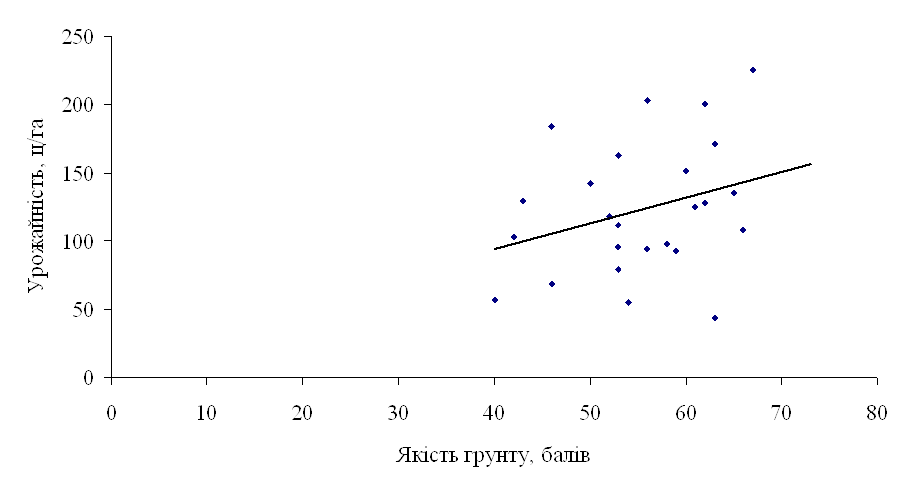
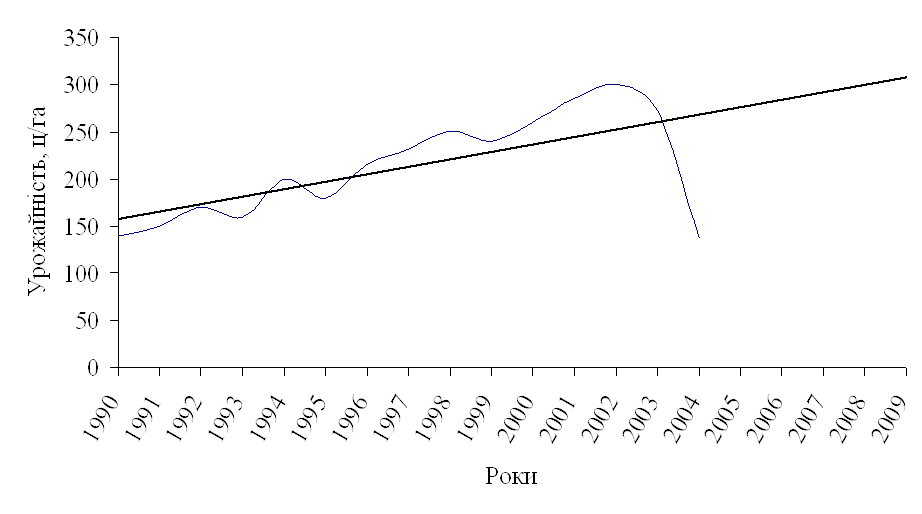
... лінію регресії (рис.4). Рис 4. Кореляційне поле залежності урожайності цукрових буряків від якості ґрунту Розділ IV. Динаміка та прогнозування урожайності цукрових буряків 4.1 Перспективи розвитку урожайності цукрових буряків в господарствах Андрушівського району Рядом динаміки називається тимчасова послідовність значень статистичних показників. Ряд динаміки складається із ...
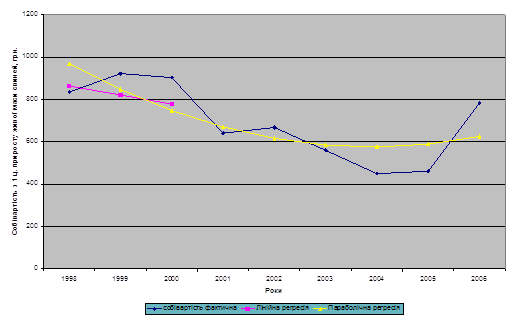
... курсової роботи виступають річні звіти за 2004, 2005, 2006 роки, матеріали статистичної звітності та економічний паспорт ВАТ "Сонячне" Тарутинського району Одеської області 1.1. Значення, завдання та джерела даних для економіко-статистичного аналізу собівартості продукції тваринництва. Одним із найважливіших показників роботи підприємства та галузі економіки в цілому є собівартість ...
0 комментариев