Навигация
Кластерный анализ в задачах социально-экономического прогнозирования
32764
знака
3
таблицы
22
изображения
Глава 1.
КЛАСТЕРНЫЙ АНАЛИЗ В ЗАДАЧАХ СОЦИАЛЬНО-ЭКОНОМИЧЕСКОГО ПРОГНОЗИРОВАНИЯ
Введение в кластерный анализ.
При анализе и прогнозировании социально-экономических явлений исследователь довольно часто сталкивается с многомерностью их описания. Это происходит при решении задачи сегментирования рынка, построении типологии стран по достаточно большому числу показателей, прогнозирования конъюнктуры рынка отдельных товаров, изучении и прогнозировании экономической депрессии и многих других проблем.
Методы многомерного анализа - наиболее действенный количественный инструмент исследования социально-экономических процессов, описываемых большим числом характеристик. К ним относятся кластерный анализ, таксономия, распознавание образов, факторный анализ.
Кластерный анализ наиболее ярко отражает черты многомерного анализа в классификации, факторный анализ – в исследовании связи.
Иногда подход кластерного анализа называют в литературе численной таксономией, численной классификацией, распознаванием с самообучением и т.д.
Первое применение кластерный анализ нашел в социологии. Название кластерный анализ происходит от английского слова cluster – гроздь, скопление. Впервые в 1939 был определен предмет кластерного анализа и сделано его описание исследователем Трионом. Главное назначение кластерного анализа – разбиение множества исследуемых объектов и признаков на однородные в соответствующем понимании группы или кластеры. Это означает, что решается задача классификации данных и выявления соответствующей структуры в ней. Методы кластерного анализа можно применять в самых различных случаях, даже в тех случаях, когда речь идет о простой группировке, в которой все сводится к образованию групп по количественному сходству.
Большое достоинство кластерного анализа в том, что он позволяет производить разбиение объектов не по одному параметру, а по целому набору признаков. Кроме того, кластерный анализ в отличие от большинства математико-статистических методов не накладывает никаких ограничений на вид рассматриваемых объектов, и позволяет рассматривать множество исходных данных практически произвольной природы. Это имеет большое значение, например, для прогнозирования конъюнктуры, когда показатели имеют разнообразный вид, затрудняющий применение традиционных эконометрических подходов.
Кластерный анализ позволяет рассматривать достаточно большой объем информации и резко сокращать, сжимать большие массивы социально-экономической информации, делать их компактными и наглядными.
Важное значение кластерный анализ имеет применительно к совокупностям временных рядов, характеризующих экономическое развитие (например, общехозяйственной и товарной конъюнктуры). Здесь можно выделять периоды, когда значения соответствующих показателей были достаточно близкими, а также определять группы временных рядов, динамика которых наиболее схожа.
Кластерный анализ можно использовать циклически. В этом случае исследование производится до тех пор, пока не будут достигнуты необходимые результаты. При этом каждый цикл здесь может давать информацию, которая способна сильно изменить направленность и подходы дальнейшего применения кластерного анализа. Этот процесс можно представить системой с обратной связью.
В задачах социально-экономического прогнозирования весьма перспективно сочетание кластерного анализа с другими количественными методами (например, с регрессионным анализом).
Как и любой другой метод, кластерный анализ имеет определенные недостатки и ограничения: В частности, состав и количество кластеров зависит от выбираемых критериев разбиения. При сведении исходного массива данных к более компактному виду могут возникать определенные искажения, а также могут теряться индивидуальные черты отдельных объектов за счет замены их характеристиками обобщенных значений параметров кластера. При проведении классификации объектов игнорируется очень часто возможность отсутствия в рассматриваемой совокупности каких-либо значений кластеров.
В кластерном анализе считается, что:
а) выбранные характеристики допускают в принципе желательное разбиение на кластеры;
б) единицы измерения (масштаб) выбраны правильно.
Выбор масштаба играет большую роль. Как правило, данные нормализуют вычитанием среднего и делением на стандартное отклоненение, так что дисперсия оказывается равной единице.
Задача кластерного анализа.
Задача кластерного анализа заключается в том, чтобы на основании данных, содержащихся во множестве Х, разбить множество объектов G на m (m – целое) кластеров (подмножеств) Q1, Q2, …, Qm, так, чтобы каждый объект Gj принадлежал одному и только одному подмножеству разбиения и чтобы объекты, принадлежащие одному и тому же кластеру, были сходными, в то время, как объекты, принадлежащие разным кластерам были разнородными.
Например, пусть G включает n стран, любая из которых характеризуется ВНП на душу населения (F1), числом М автомашин на 1 тысячу человек (F2), душевым потреблением электроэнергии (F3), душевым потреблением стали (F4) и т.д. Тогда Х1 (вектор измерений) представляет собой набор указанных характеристик для первой страны, Х2 - для второй, Х3 для третьей, и т.д. Задача заключается в том, чтобы разбить страны по уровню развития.
Решением задачи кластерного анализа являются разбиения, удовлетворяющие некоторому критерию оптимальности. Этот критерий может представлять собой некоторый функционал, выражающий уровни желательности различных разбиений и группировок, который называют целевой функцией. Например, в качестве целевой функции может быть взята внутригрупповая сумма квадратов отклонения:
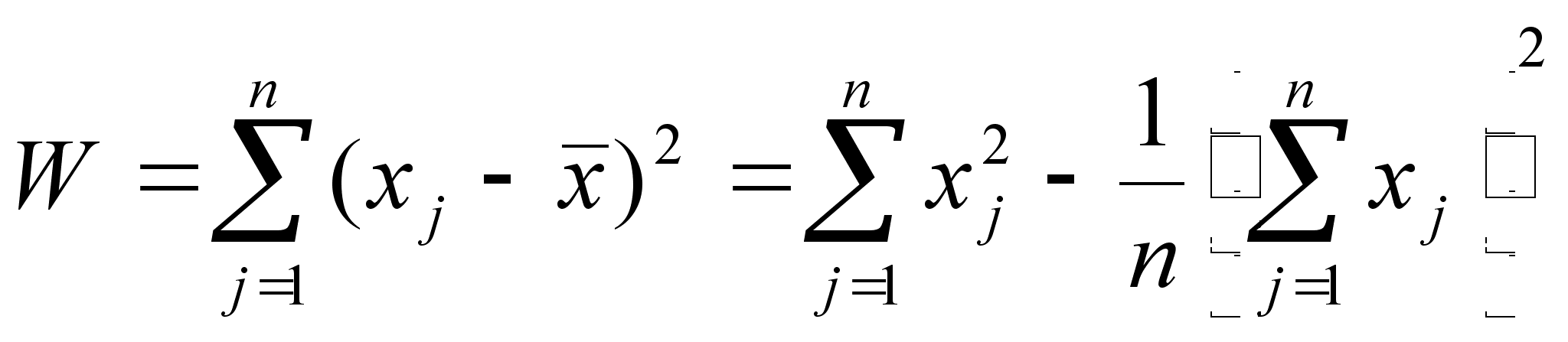
где xj - представляет собой измерения j-го объекта.
Для решения задачи кластерного анализа необходимо определить понятие сходства и разнородности.
Понятно то, что объекты -ый и j-ый попадали бы в один кластер, когда расстояние (отдаленность) между точками Х и Хj было бы достаточно маленьким и попадали бы в разные кластеры, когда это расстояние было бы достаточно большим. Таким образом, попадание в один или разные кластеры объектов определяется понятием расстояния между Х и Хj из Ер, где Ер - р-мерное евклидово пространство. Неотрицательная функция d(Х , Хj) называется функцией расстояния (метрикой), если:
а) d(Хi , Хj) 0, для всех Х и Хj из Ер
б) d(Хi, Хj) = 0, тогда и только тогда, когда Х = Хj
в) d(Хi, Хj) = d(Хj, Х)
г) d(Хi, Хj) d(Хi, Хk) + d(Хk, Хj), где Хj; Хi и Хk - любые три вектора из Ер.
Значение d(Хi, Хj) для Хi и Хj называется расстоянием между Хi и Хj и эквивалентно расстоянию между Gi и Gj соответственно выбранным характеристикам (F1, F2, F3, ..., Fр).
Наиболее часто употребляются следующие функции расстояний:
1. Евклидово
расстояние
d2(Хi
, Хj)
= 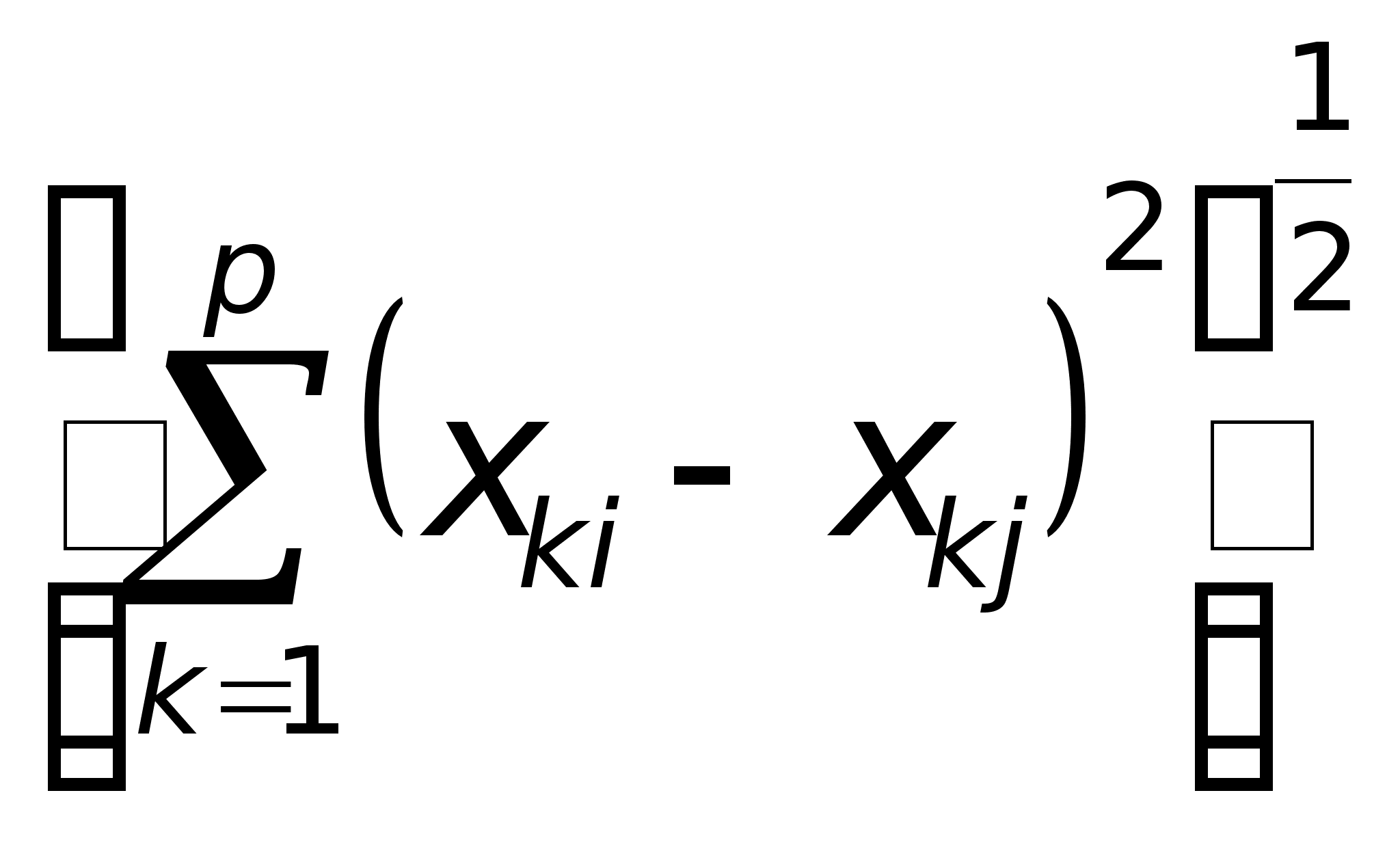
2. l1
- норма d1(Хi
, Хj)
= 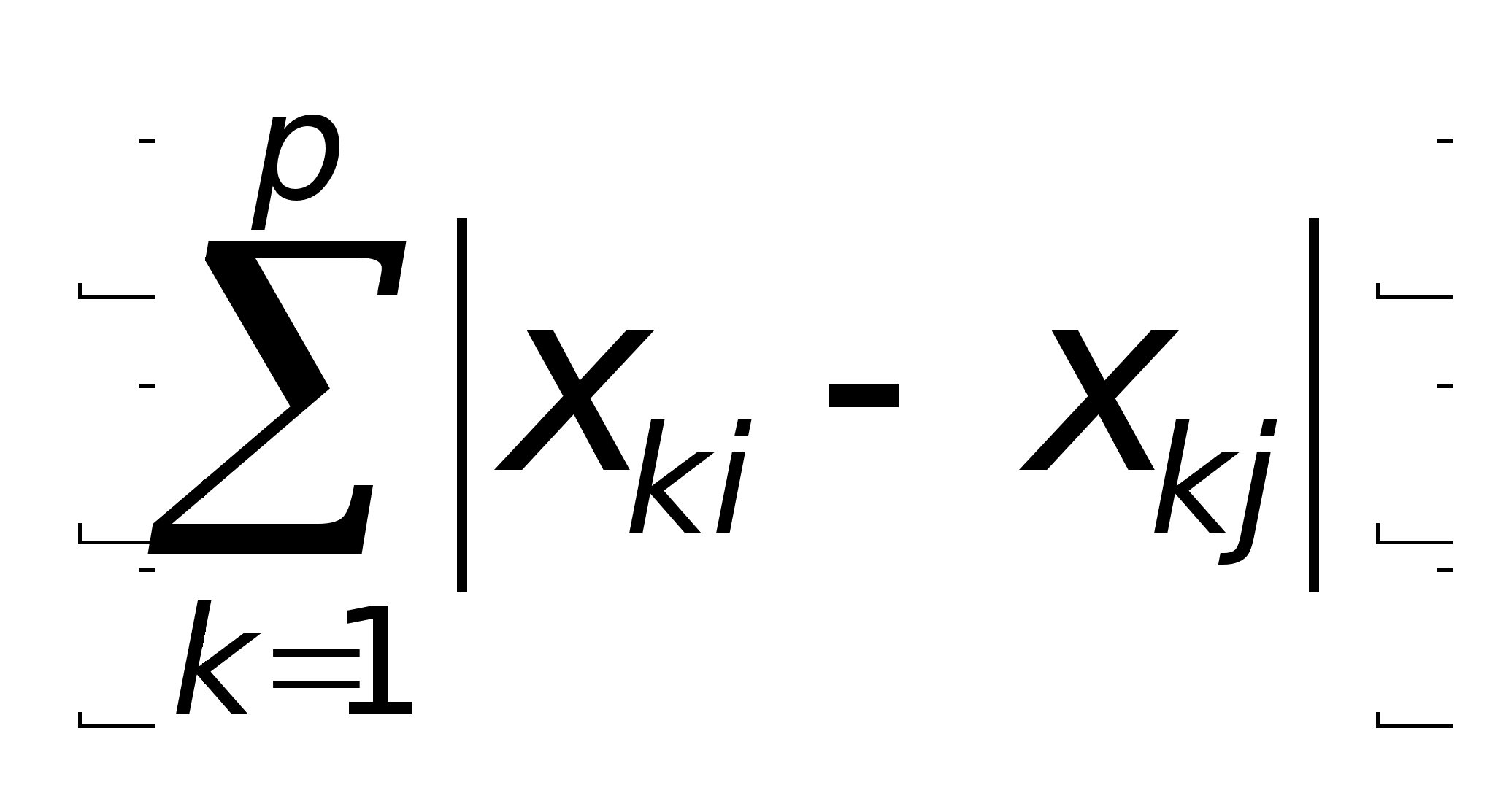
3. Сюпремум
- норма d(Хi
, Хj)
= sup![]()
k = 1, 2, ..., р
4. lp
- норма dр(Хi
, Хj)
= 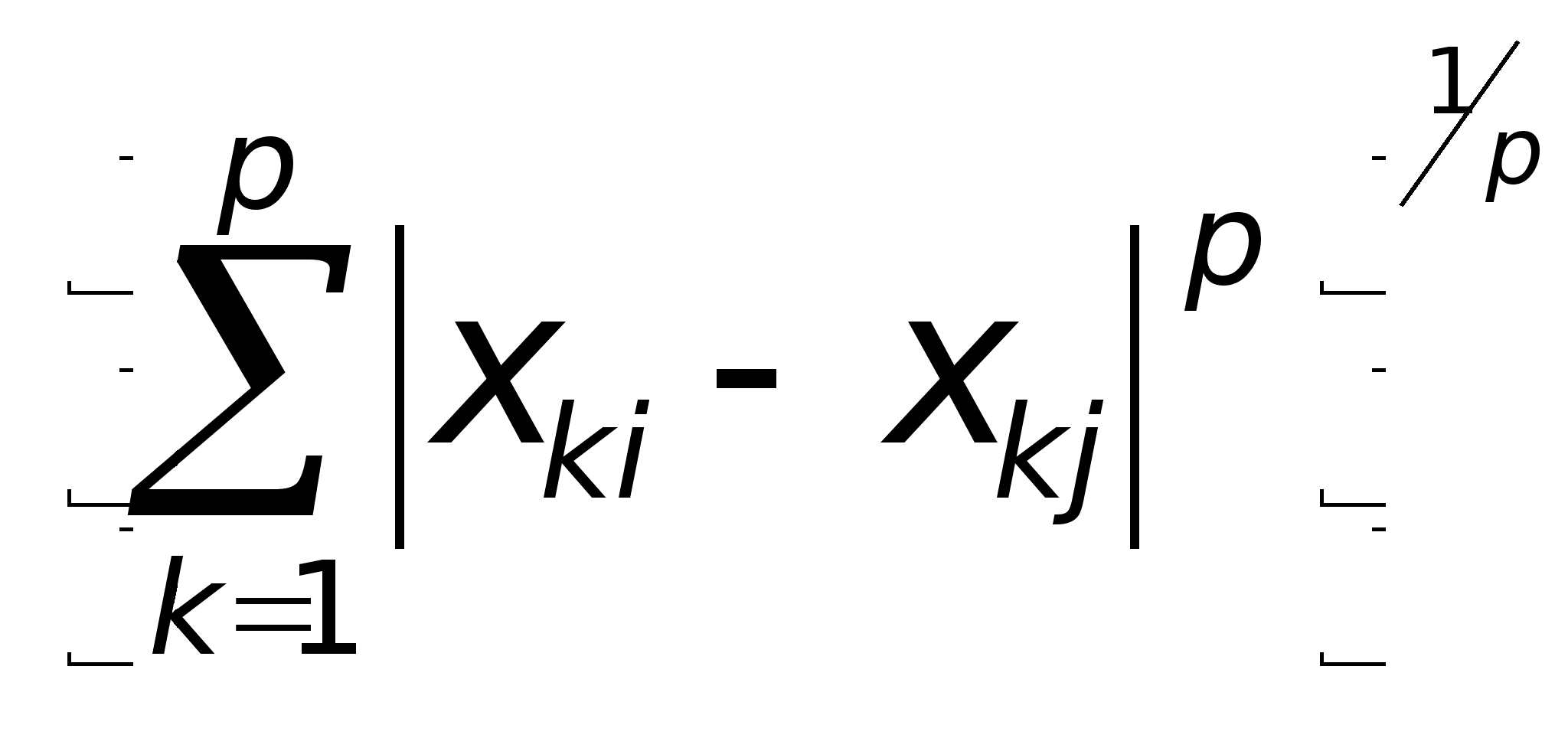
Евклидова метрика является наиболее популярной. Метрика l1 наиболее легкая для вычислений. Сюпремум-норма легко считается и включает в себя процедуру упорядочения, а lp - норма охватывает функции расстояний 1, 2, 3,.
Пусть n измерений Х1, Х2,..., Хn представлены в виде матрицы данных размером p n:
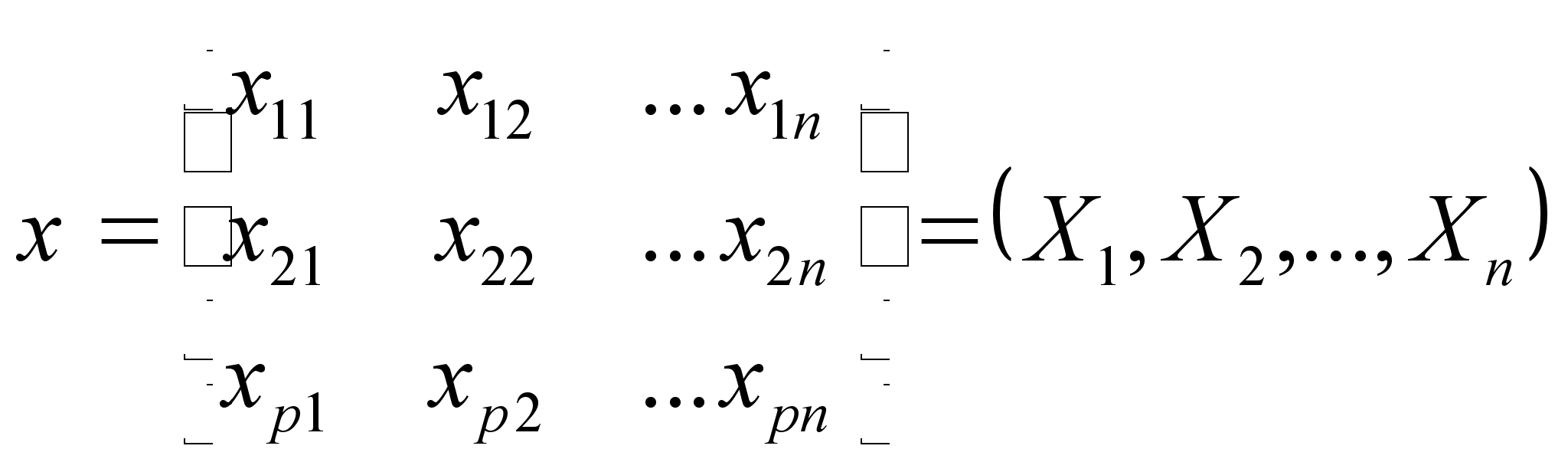
Тогда расстояние между парами векторов d(Х , Хj) могут быть представлены в виде симметричной матрицы расстояний:
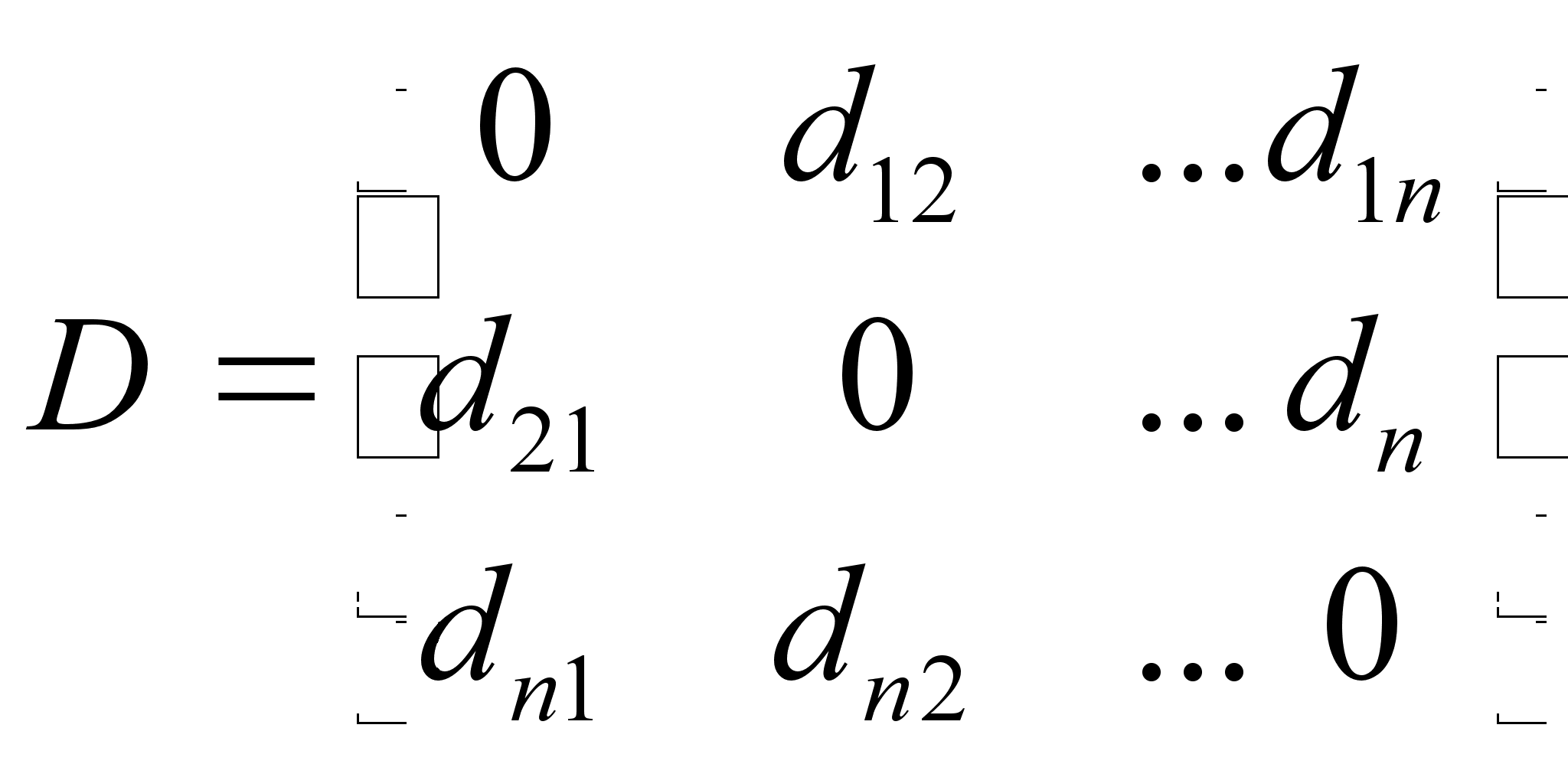
Понятием, противоположным расстоянию, является понятие сходства между объектами G. и Gj. Неотрицательная вещественная функция S(Х ; Хj) = Sj называется мерой сходства, если :
1) 0 S(Хi , Хj)1 для Х Хj
2) S(Хi , Хi) = 1
3) S(Хi , Хj) = S(Хj , Х)
Пары значений мер сходства можно объединить в матрицу сходства:
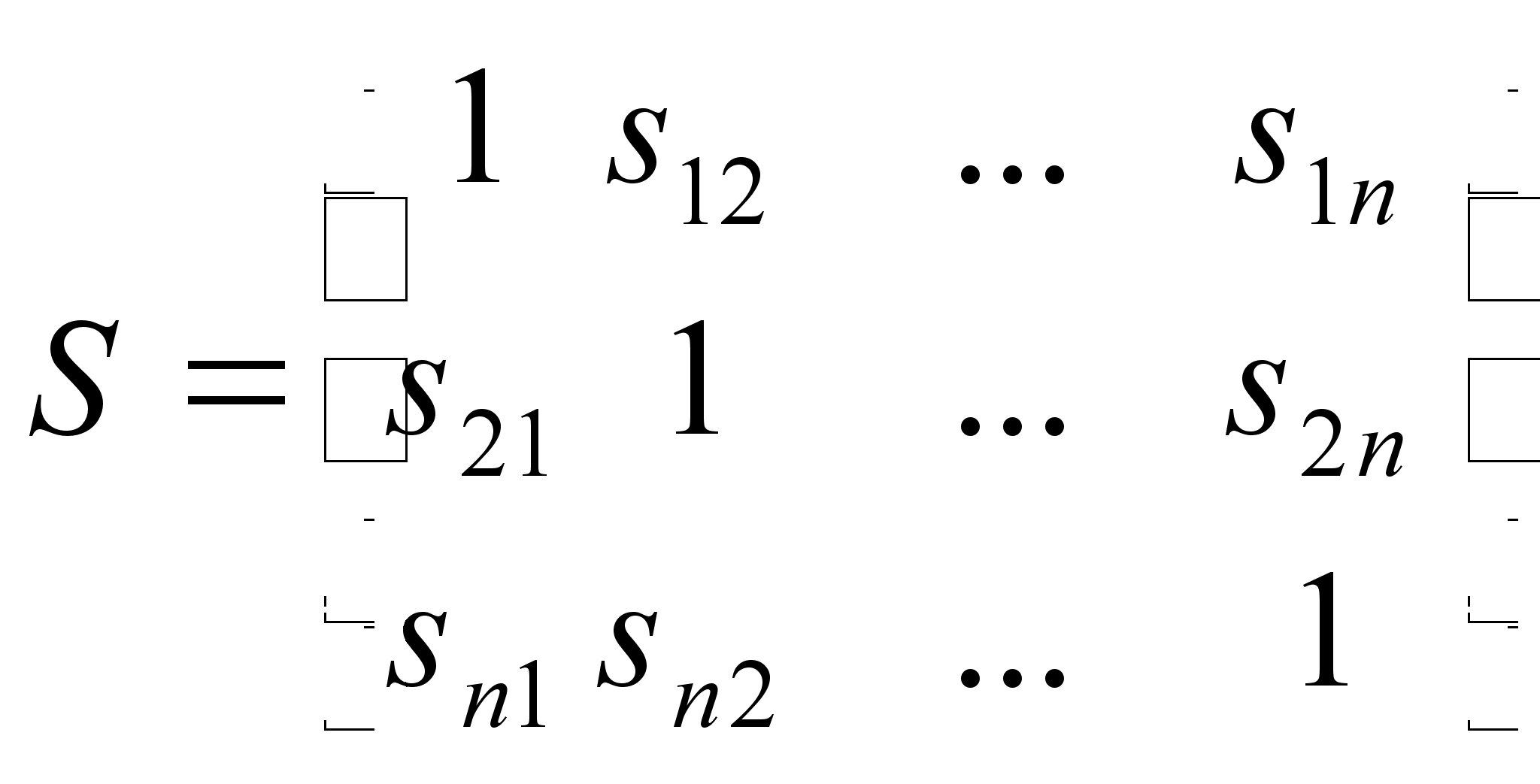
Величину Sij называют коэффициентом сходства.
Похожие работы
... предварительно нормируются, т.е. выражаются через отношение этих значений к некоторой величине, отражающей определенные свойства данного показателя. Нормирование исходных данных для кластерного анализа иногда проводится посредством деления исходных величин на среднеквадратичное отклонение соответствующих показателей. Другой способ сводиться к вычислению, так называемого, стандартизованного вклада ...
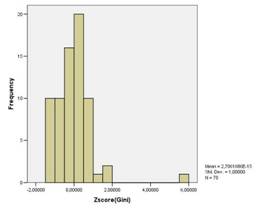
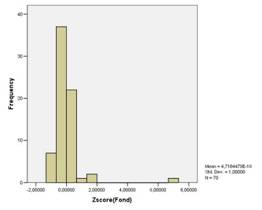
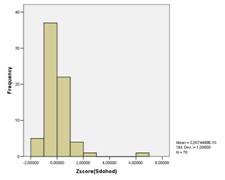
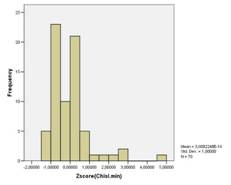
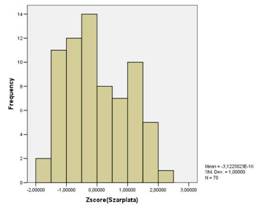
... пятого кластера стали Санкт-Петербург, Свердловская область. А вот шестой кластер состоит лишь из одного региона России- Республики Ингушетии. Для создания качественного представления о социально-экономическом положении (различиях в имущественном обеспечении и неравенстве в доходах) очень полезно будет рассмотреть таблицу окончательных кластерных центров. Таблица 9 «Окончательные кластерные ...

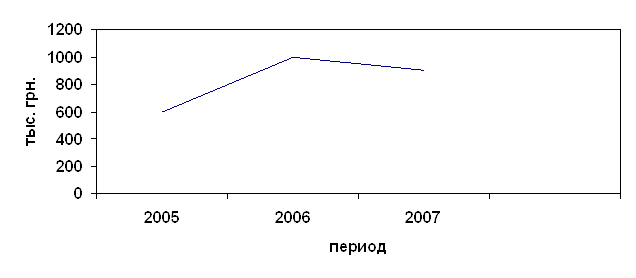
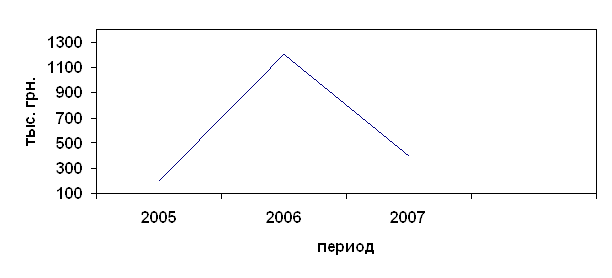
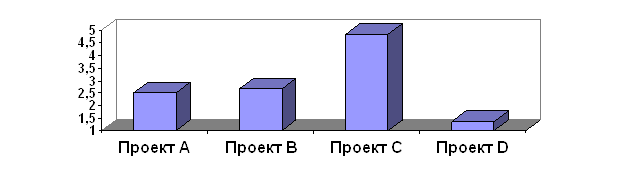
... . Работа имеет три раздела: В первой главе характеризируются и рассматриваются основные принципы анализа капиталовложений. Вторая глава представляет собой анализ эффективности инвестиционных проектов. Третья глава состоит из рассмотрения проблем оптимизации капиталовложений. РАЗДЕЛ 1. ОСНОВНЫЕ ПРИНЦИПЫ АНАЛИЗА ИНВЕСТИЦИОННЫХ ПРОЕКТОВ 1.1. Характеристика видов инвестиционных проектов ...
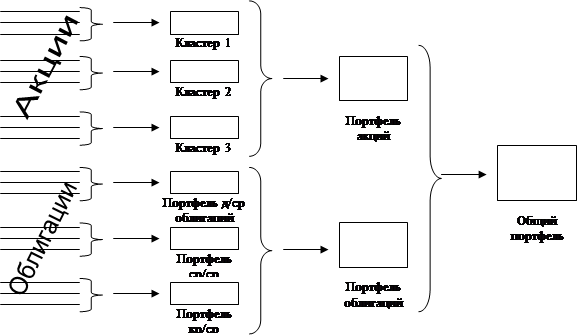
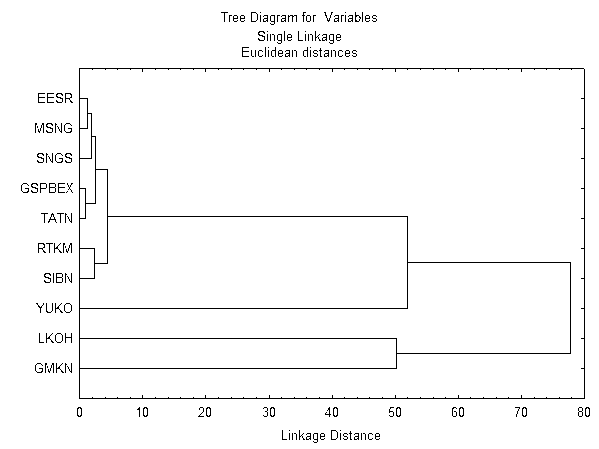
... играет большую роль. Как правило, данные нормализуют вычитанием среднего и делением на стандартное отклонение, так что дисперсия оказывается равной единице. 2. Кластерный анализ в портфельном инвестировании Общеизвестно, что изменение курсовой стоимости и дивидендов различных ценных бумаг не только в России, но и во всем ...
0 комментариев