Моделирование
в задачах создания
и оптимизации
систем
распознавания..................................................................…………………
Совсем
уже утрированный
случай из
техники: дверной
замок распознает
свой ключ и
разрешает
открыть помещение
Основные определения
Системы распознавания
СР
должна создаваться
методом последовательных
приближений
внутренней
структуры на
ее математической
модели по мере
накопления
необходимой
информации
Взаимосвязь
размерности
вектора признаков
и эффективности
СР
История вопроса
Основные определения
Моделирование
сложных систем и опытно-теоретический
метод их испытаний
Навигация
СР должна создаваться методом последовательных приближений внутренней структуры на ее математической модели по мере накопления необходимой информации
Построение систем распознавания образов
126460
знаков
2
таблицы
0
изображений
3. СР должна создаваться методом последовательных приближений внутренней структуры на ее математической модели по мере накопления необходимой информации.
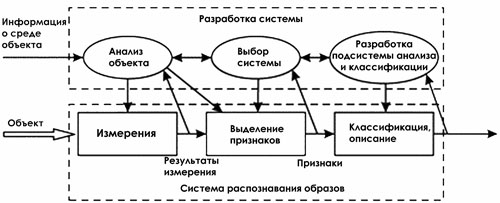
Теперь, после того как мы на качественном уровне рассмотрели проблематику распознавания, можно провести дополнительную детализацию и определить последовательность задач создания соответствующих систем.
Л Е К Ц И Я 2.2
Формулировка задач создания систем
распознавания и методы их решения
ЗАДАЧА № 1
Определение полного перечня признаков (параметров), характеризующих объекты или явления, для которых данная система разрабатывается.
В решении этой задачи - главное найти все признаки, характеризующие существо распознаваемых объектов (явлений). Любые ограничения, любая неполнота, как мы в последующем убедимся, приводят к ошибкам или полной невозможности правильной классификации объектов (явлений).
Можем себе представить такую неполноту в уже рассмотренной нами задаче распознавания самолетов как использование одного признака - потолок высоты полета самолетов. В результате - бомбардировщики не удастся отличать от истребителей ( при создании бомбардировщиков стремятся к обеспечению максимально возможной высоты полета, а при создании истребителей добиваются, чтобы они могли уничтожать бомбардировщики).
Реально даже целая группа признаков может оказаться неэффективной.
Поэтому для решения 1-ой задачи создания СР необходимо найти все возможные признаки, описывающие объекты распознавания, с тем, чтобы при оценке эффективности решений системы не возвращаться к этой задаче, обнаружив ограниченность выбранных признаков на последующих этапах разработки.
Но чтобы назначать признаки распознавания, необходимо, во-первых, понять, что не существует способов их автоматической генерации. На сегодня это под силу только человеку. Поэтому говорят, что выбор признаков - эвристическая операция. Во-вторых, выбор признаков можно осуществлять, имея представление об их общих свойствах. С этих позиций достаточно принять, что признаки могут подразделяться на:
-детерминированные;
-вероятностные;
-логические;
-структурные.
А. Детерминированные признаки - это такие характеристики объектов или явлений, которые имеют конкретные и постоянные числовые значения.
Примерами детерминированных признаков могут быть, например, ТТХ бомбардировщиков и истребителей США (таблицы № 1, 2).
Числовые значения признаков по каждому из самолетов можно интерпретировать как координаты точек, представляющих каждый самолет в 11-мерном пространстве признаков.
Необходимо иметь в виду, что в задачах распознавания с детерминированными признаками ошибки измерения этих признаков не играют никакой роли, если, например, точность измерений такого признака, как размах крыльев самолета значительно выше (например, 1 мм), чем различие этого признака у разных классов самолетов (например, 10 м).
Представить такую систему, где используются детерминированные признаки не так трудно:
-распознавание принадлежности самолета, данные которого получены разведкой или из открытой печати и не привязаны к классам (бомбардировщик- А1, истребитель-А2 и т.п.);
-распознавание на конвейере деталей по отличию геометрических характеристик, если ошибки измерений существенно меньше разметов этих деталей.
Распознавание осуществляется путем сравнения полученных размеров с имеющимися в базе данных характеристиками деталей.
Б. Вероятностные признаки - это характеристики объекта (явления), носящие случайный характер.
С такими признаками в основном и имеют дело в природе и технике.
Отличаются эти признаки тем, что в силу случайности соответствующей величины признак одного класса может принимать значения из области значений других классов, каждый из которых подлежит распознаванию в системе.
Таблица № 1
| Характеристики | Т и п ы с а м о л е т о в | |||
| В-1А | В-52 | В-57А | FB-111 | |
| Экипаж (чел.) | 4 | 6 | 2 | 2 |
| Vmax (км\ч) при H=15 км | 2330 | 1020 | 935 | 2330 |
| Vmin (км\ч) при H=0.3 км | 1200 | 500 | 500 | 1350 |
| Потолок (м) | 15240 | 15000 | 13750 | 20000 |
| Бомб.нагрузка (т) | 22 | 34 | 14 | 16 |
| Макс.взлетная масса (т) | 180 | 221 | 25 | 45 |
| Размах крыльев (м) | 42 | 56 | 19 | 21 |
| Длина самолета (м) | 44 | 48 | 20 | 22 |
| Кол-во двигателей | 4 | 8 | 2 | 2 |
| Тяга двигателей (т) | 13.6 | 7.7 | 3.3 | 9.2 |
| Дальность полета (км | 11000 | 20000 | 4380 | 6600 |
Таблица № 2
| Характериcтики | Т и п ы с а м о л е т о в | ||||
| F - 4 E Фантом | F - 105 E Тандер-чиф | F - 15 Игл | F - 100 D Супер-сейбр | Хантер | |
| Экипаж (чел.) | 2 | 2 | 1 | 1 | 1 |
| Vmax (км\ч) при H =15 км | 2330 | 2230 | 2655 | 1400 | 1000 |
| Vmin (км\ч) при H =0.3 (км) | 1470 | 1400 | 1470 | 1220 | 1150 |
| Потолок (м) | 19000 | 15000 | 21000 | 15000 | 17000 |
| Бомб.нагр. (т) | 7.2 | 6.4 | - | 3.4 | 0.9 |
| Макс.взлетн. масса (т) | 26 | 24 | 25 | 18 | 11 |
| Размах крыльев (м) | 12 | 11 | 14 | 11 | 10 |
| Длина самолета (м) | 18 | 21 | 19 | 12 | 13 |
| Кол-во двигателей | 2 | 1 | 2 | 1 | 1 |
| Тяга двигателей (т) | 5.4 | 12 | 10.9 | 5.3 | 4.5 |
| Дальность полета (км) | 885 | 760 | 1100 | 860 | 560 |
Если признак не может принять значений в области соответствующих значений для других классов, то, следовательно, имеем дело не с вероятностным, а с тем же детерминированным признаком. Это как раз подчеркивает, почему вероятностные системы являются системами более общего порядка.
Для того, чтобы можно было в условиях случайности говорить о возможности распознавания, следует потребовать, чтобы вероятности наблюдения значений признака в своем классе были как можно больше, чем в чужих. В противном случае данный признак не позволит построить СР, использующую описание классов на его основе. Эффективность его недостаточна для достоверного решения и необходимо искать другие признаки, имеющие большую разделительную способность.
Вспомним из теории вероятностей, чем характеризуется случайная величина - законом распределения вероятностей. То есть, точно так же законом распределения должен характеризоваться каждый вероятностный признак.
Вспомним и то, что в качестве законов распределения вероятностей в теории вероятностей выступают интегральная функция F(x) - интегральный закон или плотность распределения вероятностей (ПРВ) - дифференциальный закон f(x). При этом связь между ними:
Вспомним, что самый распространенный в природе закон распределения - нормальный или Гауссов - имеет ПРВ
Если предположить, что какой-либо вероятностный признак (например, размах крыльев, измеренный каким-либо средством измерений с ошибками) распределен по нормальному закону, то для 3-х условных классов, отличающихся размахами крыльев, распределения этого параметра будут выглядеть, как показано на рис.2.1.
Из рис. 2.1 видно, что если для неизвестного самолета мы с помощью упомянутого средства измерений определили размах крыльев Lкр с естественной случайной ошибкой , то с определенной вероятностью это измерение может быть отнесено к каждому из классов. Однако, легко заметить, что если это значение лежит ближе к одному из центров рассеяния (например, Mx1), то вероятность отнесения его к соответствующему распределению, а значит и классу, максимальная.
f(Lкр)
Mx1 Mx2 Mx3 Lкр
Рис.2.1
Примеры вероятностных признаков распознавания:
-среднее значение мощности сигнала радиолокатора, отраженного от самолета (причина - изрезанность круговой диаграммы рассеяния сигнала радиолокатора самолетом и электронные и атмосферные шумы в том же радиолокационном диапазоне);
-размер листа растения (причины - отличия в питании, освещенности, влаги и т.п.);
-размер патологического изменения какого-либо органа человека (причины - различные стадии заболевания при его обнаружении, различные ракурсы и сечения наблюдений образования и т.п.) и т.д.
В. Логические признаки распознавания - это характеристики объекта или явления, представленные в виде элементарных высказываний об истинности (“да”, "нет” или “истина”, “ложь”).
Эти признаки, как мы понимаем, не имеют количественного выражения, то есть являются качественными суждениями о наличии, либо об отсутствии некоторых свойств или составляющих у объектов или явлений.
Примеры логических признаков:
-наличие ТРД на самолете ;
-боль в горле пациента ;
-кашель ;
-насморк ;
-растворимость реактива и т.д.
Здесь по каждому признаку можно сказать только то, что он есть, либо его нет.
К логическим можно отнести также такие признаки, у которых не важна величина, а лишь факт попадания или непопадания ее в заданный интервал. (например, крейсерская скорость самолета больше или меньше 2000 км/ч).
Г. Структурные признаки - непроизводные (то есть, элементарные, не производимые из других элементарных признаков) элементы (символы), примитивы изображения объекта распознавания.
Появление структурных признаков обязано возникновению проблемы распознавания изображений с ее специфическими особенностями и трудностями.
Примеры структурных признаков:
а)для изображения прямоугольника:
- горизонтальный отрезок прямой;
- вертикальный отрезок прямой.
б) для любого изображения на экране дисплея:
-пиксел.
Забегая далеко вперед в изложении материала, следует отметить, что традиционно для описания изображений использовались разложения его в ряды по ортогональным функциям (ряды Фурье, полиномы Эрмита, Лежандра, Чебышева, разложения Карунена-Лоэва и др.).
Структурное описание в отличии от разложений:
-понятнее (физичнее) для человека, решающего задачу распознавания объекта;
-приемлемо и для компьютерной реализации при распознавании;
-свободно от трудоемкости вычислений и потерь информации, свойственных разложениям.
Оказывается, что оперируя ограниченным числом атомарных (непроизводных) элементов (примитивов), можно получить описание разнообразных объектов. То есть, для отличающихся объектов можно иметь набор одинаковых непроизводных элементов. Но для того, чтобы описание можно было бы выполнить, наряду с определением непроизводных элементов должны вводиться правила комбинирования, определяющие способы построения объекта из упомянутых непроизводных элементов. В результате два одинаковых непроизводных элемента различных объектов могут быть соединены друг с другом по разным правилам. Это и будет их отличать.
В целом для описания какого-либо объекта непроизводные элементы объединяются в цепочки (предложения) по своему, характерному только для этого объекта, набору правил.
В результате связей из непроизводных элементов (структурных признаков) образуется объект, аналогично тому, как предложения языка строятся путем соединения слов, в свою очередь состоящих из букв. В этом структурные методы проявляют аналогию с синтаксисом естественного языка. Отсюда структурные признаки носят еще название лингвистических или синтаксических.
( Пример - код Фримена).
* * *
Таким образом, мы рассмотрели очень подробно 1-ую задачу создания систем распознавания - определение полного перечня признаков (параметров), характеризующих объекты или явления, для которых данная система разрабатывается. Главные выводы:
1) Выбор, назначение признаков распознавания - эвристическая операция, зависящая от творчества, изобретательности разработчика.
2) Состав признаков , выбираемых на этом этапе, должен быть как можно более разносторонним и полным, независимым от того, можно или нельзя эти признаки получить.
3) Выбор признаков должен осуществляться в группах детерминированных, вероятностных, логических и структурных.
Л Е К Ц И Я 2.3
Формулировка задач создания систем
распознавания и методы их решения
( продолжение)
ЗАДАЧА № 2
Первоначальная классификация объектов (явлений), подлежащих распознаванию, составление априорного алфавита классов.
Нам уже знакома на описательном уровне эта задача: необходимо выбрать (назначить) классы объектов (явлений) распознавания. Решение ее осуществляется наиболее часто эвристически, как и выбор признаков распознавания, а логика ее решения следующая:
1-е - определяется, какие решения могут приниматься по результатам распознавания либо человеком, либо автоматической системой управления объектом (цель распознавания).
2-е - на основе определенной выше цели формулируются требования к системе распознавания, позволяющие выбрать принцип классификации.
3-е - составляется априорный алфавит классов объектов (явлений).
Предположим по результатам некоторого метода медицинской диагностики состояния печени человека необходимо принимать решения о методе лечения (см.1-й пункт в рассмотренной последовательности решения задачи априорной классификации - цель). Насколько серьезно принятие такого решения, учитывая возможность хирургического вмешательства, я надеюсь, понятно.
Тогда, очевидно, что требованием к системе (см.2-й пункт последовательности) - надежное (с высокой вероятностью) диагностирование каждого заболевания печени.
Следовательно, в априорный алфавит классов (см.3-й пункт рассмотренной последовательности) необходимо включить все возможные заболевания печени, а их - 11. То есть, классов распознаваемых заболеваний печени, диагностируемых некоторой гипотетической системой распознавания должно быть 11. Для более четкого понимания назовем эти классы:
1.Острый гепатит.
2.Хронический гепатит.
3.Жировая инфильтрация.
4.Цирроз.
5.Киста простая.
6.Киста паразитарная.
7.Абсцесс.
8.Опухоль.
9.Метастазы.
10.Гематома.
11.Конкременты.
Заметим, что, кроме ситуации, предложенной рассмотренной задачи, возможны и другие, когда количество классов, по которым надежно распознаются некоторые объекты (явления), заранее неизвестно и должно определяться самой системой распознавания. Эта задача называется задачей кластеризации, в которой можно отказаться уже от эвристического подхода. Однако решение здесь достигается при выборе некоторых общих правил кластеризации, которые задает разработчик системы.
ЗАДАЧА № 3
Разработка априорного словаря признаков распознавания.
Решая задачу №1, мы должны были найти все возможные признаки распознавания заданных объектов или явлений. Точно также при решении задачи №2 определился состав классов.
Теперь, располагая соответствующим перечнем и априорным алфавитом классов, необходимо провести анализ возможностей измерения признаков или расчета их по данным измерений, выбрать те из них, которые обеспечиваются измерениями, а также в случае необходимости разработать предложения и создать новые средства измерений для обеспечения требуемой эффективности распознавания.
Таким образом, главное содержание рассматриваемой задачи построения СР - создание словаря, обеспечиваемого реально возможными измерениями.
Однако, хороший или плохой набор признаков распознавания, получился в результате указанных действий разработчика СР, можно понять, выполнив испытания системы распознавания в целом и оценив эффективность распознавания. Но системы распознавания на указанном этапе разработки еще не существует. В то же время, как мы заметили, появилась необходимость оценки эффективности. И рассматривая очередные задачи создания СР, мы обнаружим, что рассматриваемая задача остается актуальной на протяжении всех последующих этапов создания системы распознавания (описание классов, выбор алгоритма распознавания). Только методом последовательных приближений удается добиться выбора словаря признаков, обеспечивающего желаемое качество решений.
Выходом из создавшегося положения является возможность создания на данном этапе математической модели системы. Математические модели СР и используются для реализации указанных последовательных приближений, о чем упоминалось на описательном уровне при рассмотрении задач построения систем распознавания.
ЗАДАЧА № 4
Описание классов априорного алфавита на языке априорного словаря признаков.
Априорное описание классов - наиболее трудоемкая из задач в процессе создания системы распознавания, требующая глубокого изучения свойств объектов распознавания, а также и наиболее творческая задача.
В рамках этой задачи необходимо каждому классу поставить в соответствие числовые параметры детерминированных и вероятностных признаков, значения логических признаков и предложения, составленные из структурных признаков-примитивов.
Значения этих параметров описаний можно получить из совокупности следующих работ и действий:
-специально поставленные экспериментальные работы или --экспериментальные наблюдения;
-результаты обработки экспериментальных данных;
-математические расчеты;
-результаты математического моделирования;
-извлечения из литературных источников.
Что же такое описание класса на языке признаков? Рассмотрим это отдельно для детерминированных, вероятностных, логических и структурных признаков.
Если признаки распознаваемых объектов - детерминированные, то описанием класса может быть точка в №-мерном пространстве детерминированных признаков из априорного словаря, сумма расстояний которой от точек, представляющих объекты данного класса, минимальна.
Легко себе представить такой эталон, вернувшись к рассмотренным нами таблицам ТТХ самолетов. Здесь мы имеем дело с 11-мерным пространством признаков. Каждая координата - это одна какая-нибудь характеристика, например “экипаж”. Если рассматривать только одну координату “экипаж”, то точкой эталона для истребителей будет - 1, для бомбардировщиков - 4. Это точки, суммы расстояний которых от всех истребителей и всех бомбардировщиков, представляющих эти два класса, минимальны.
Точно также это можно сделать по всем 11 координатам (т.е. “потолок”, “размах крыльев”, ”бомбовая нагрузка “ и т.д.), в результате чего будем уже иметь дело с точками эталонов в 11-мерном пространстве.
Если признаки распознавания - логические, то для описания каждого класса необходимо прежде всего иметь полный набор элементарных логических высказываний A,B,C, входящих в состав априорного словаря. Но это только признаки. Для описания классов этого недостаточно. Еще необходимо установить соответствие между набором значений приведенных признаков A,B,C и классами W1, W2,...Wm.
Так для простоты понимания и без притязаний на медицинскую достоверность возьмем такой пример: необходимо распознавать два заболевания - обычная простуда и ангина (W1,W2), а в качестве логических признаков выберем
А - повышенная температура (А=0 - нет, А=1 - да);
В - насморк (В=0 - нет, В=1 - да);
С - нарывы в горле (С=0 - нет, С=1 - да).
Тогда так называемое булево соотношение между классом W1 (обычное простудное заболевание) и значениями признаками (а эти значения - бинарные) выглядит так
Здесь умножение, как вы знаете, соответствует логическому “И”, а сложение - “ИЛИ”.
Точно также для второго класса заболеваний получим следующее описание
Подробнее здесь мы эти вопросы не рассматриваем, так как логическим системам в дальнейшем курсе уделим достаточное внимание.
Если распределение объектов распознавания, представляемых числовыми значениями их признаков по областям соответствующего пространства вероятностное, то для описания классов необходимо определить характеристики этих распределений. А из теории вероятности известно, что это
-функции ПРВ fi (x1,x2,....,xn), где x1.....xn - вероятностные признаки, I - номер класса;
-P(Wi) - априорная вероятность того, что объект, случайно выбранный из общей совокупности, окажется принадлежащим к классу Wi.
Как получить ПРВ классов системы распознавания? В распоряжении разработчика СР - три способа:
-экспериментальное определение по статистическим данным;
-теоретический вывод;
-моделирование.
То же касается априорной вероятности класса P(Wi).
Если признаки распознавания - структурные, то описанием каж-дого класса должен быть набор предложений (цепочек из непроизводных элементов с правилами соединения). Каждое из предложений класса - характеристика структурных особенностей объектов этого класса. Пример - код Фримена.
ЗАДАЧА № 5
Выбор алгоритма классификации, обеспечивающего отнесение распознаваемого объекта или явления к соответствующему классу.
Непосредственное решение задачи распознавания на основе использования словаря признаков и алфавита классов объектов или явлений фактически заключается в разбиении пространства значений признаков распознавания на области D1,D2,...,Dn, соответствующие классам W1,W2,...,Wn (вспоминаем определение “образа”).
Указанное разбиение должно быть выполнено таким образом, чтобы обеспечивались минимальные значения ошибок отнесения классифицируемых объектов или явлений к “чужим” классам.
Результатом такой операции является отнесение объекта, имеющего набор признаков X1,X2,....,Xn (точка в n-мерном пространстве), к классу Wi, если указанная точка лежит в соответствующей классу области признаков - Di.
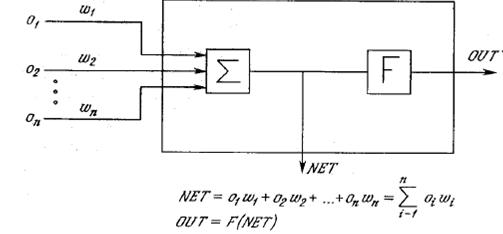
Разбиение пространства признаков можно представлять как построение разделяющих функций fi(x1,x2,....,xn) между множествами (областями) признаков Di, принадлежащим разным классам.
Упомянутые функции должны обладать следующим свойством:
-если объект, имеющий вектор признаков фактически относится к классу , то значение разделяющей функции
должно быть большим, чем значение ее для класса - (здесь индекс q - означает номер класса, к которому принадлежит вектор признаков).
Отсюда легко определить выражение решающей границы между областями Di, соответствующим классам Wi:
Для двух распознаваемых классов разбиение двумерного пространства выглядит так (рис 2.2). Физически распознавание основывается на сравнении значений той или иной меры близости распознаваемого объекта с каждым классом. При этом если значение выбранной меры близости (сходства) L данного объекта w с каким-либо классом Wg достигает экстремума относительно значений ее по другим классам, то есть
то принимается решение о принадлежности этого объекта классу Wg, то есть wWg.
Надеюсь понятно, что если мера близости не имеет экстремума, то мы находимся на границе, где не можем отдать предпочтение ни одному из классов.
X1 o o o o
xx x o o o
x o o F2(X1,X2) > F1(X1,X2)
x x x o o o o
x o o o o o
x x x x x o o o o o
F1(X1,X2)>F2(X1,X2) x o
x x x x x x x o o
x x x x x x
x x x x x
X2
Рис.2.2
В алгоритмах распознавания, использующих детерминированные признаки в качестве меры близости, используется среднеквадратическое расстояние между данным объектом w и совокупностью объектов (w1,w2,....,wn), представляющих (описывающих) каждый класс. Так для сравнения с классом Wg это выглядит так
где kg - количество объектов, представляющих Wg-й класс.
При этом в качестве методов измерений расстояния между объектами d(w,wg) могут использоваться любые методы (творческий процесс здесь не ограничивается).
Так, если сравнивать непосредственно координаты (признаки), то
где N - размерность признакового пространства.
Если сравнивать угловые отклонения, то рассматривая вектора, составляющими которых являются признаки распознаваемого объекта w и класса wg, будем иметь:
где ||Xw|| и ||Xwg|| - нормы соответствующих векторов.
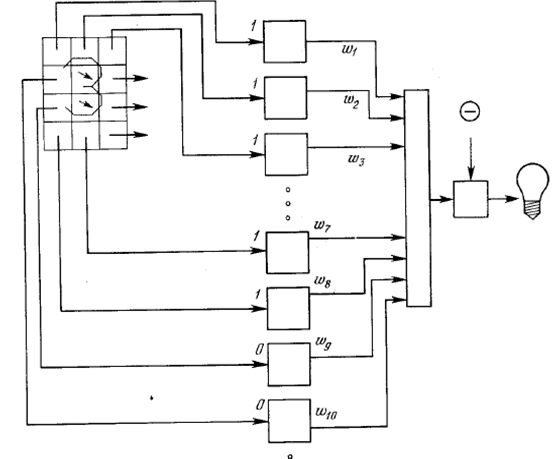
В алгоритме распознавания, использующем детерминированные признаки можно учитывать и их веса Vj (устанавливать степень доверия или важности). Тогда рассмотренное среднеквадратическое расстояние принимает следующий вид:
В алгоритмах распознавания, использующих вероятностные признаки, в качестве меры близости используется риск, связанный с решением о принадлежности объекта к классу Wi, где i - номер класса. (i=1,2,..,m.).
Описания классов, как мы недавно рассмотрели
В рассматриваемом случае к исходным данным для расчета меры близости относится платежная матрица вида:
Здесь на главной диагонали - потери при правильных решениях. Обычно принимают Сii=0 или Cii R2
Вывод:
При заданном признаковом пространстве и прочих равных условиях уменьшение числа классов приводит к меньшению ошибок распознавания.
Следствие:
При увеличении числа классов для уменьшения среднего риска (через уменьшение вероятности ошибочных решений) необходимо включать в состав словаря признаков такие, которые имеют меньший разброс.
Действительно, для рассмотренного нами одномерного случая по приведенному рисунку можно проследить, что вероятности ошибочных решений снижаются, если распределения имеют меньший разброс. То есть, при этом опять-таки уменьшается риск ошибочных решений в системе и тем самым достигается большая эффективность, но теперь уже без уменьшения числа классов.
Л е к ц и я 4.2
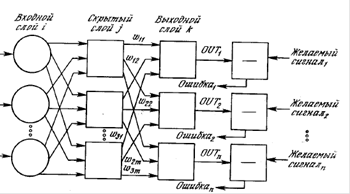
Оптимизация алфавита классов и словаря признаков
(продолжение)
Похожие работы
... именно по этой причине современное распознавание образов само питается идеями этих дисциплин. Не претендуя на полноту (а на нее в небольшом эссе претендовать невозможно) опишем историю распознавания образов, ключевые идеи [5, c. 107]. 2. Определения Прежде, чем приступить к основным методам распознавания образов, приведем несколько необходимых определений. Распознавание образов (объектов, ...
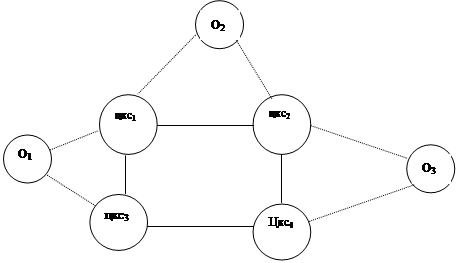
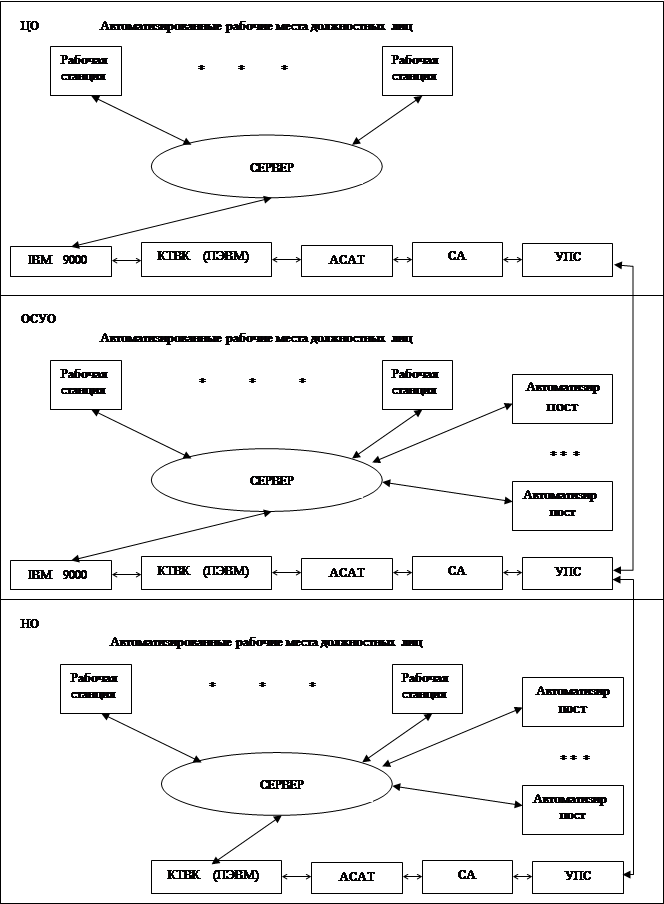
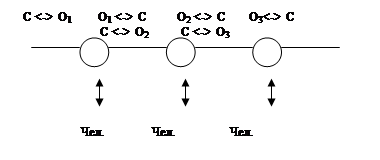
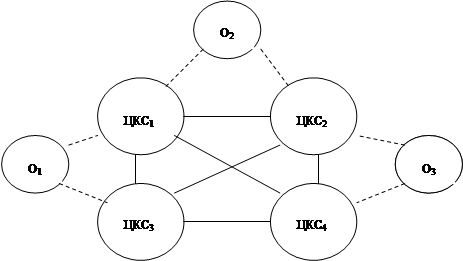
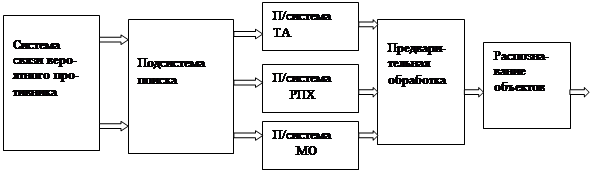
... звеньях основной акцент делается на получение и передачу информации в вышестоящие органы. В вышестоящих органах возрастает число задач, связанных с планированием, управлением и обработкой информации. В каждом звене имеется своя автоматизированная система, которая в свою очередь может иметь несколько уровней. Так специальная система состоит из объектов центрального звена, объектов среднего уровня ...
... свойства), которые сами являются результатами или компонентами промежуточных стадий этого процесса. 3. Афизикальные принципы формопорождения в процессах психического отражения Проведенный анализ методологических оснований естественнонаучного исследования непосредственно-чувственного отражения, а также способов его моделирования в технических системах привел нас к выводу о том, что в психологии, ...
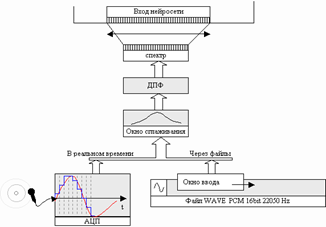
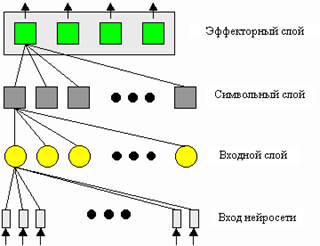
... , но только для обычных последовательных вычислительных машин. А какие же ещё машины смогут решить все вышеперечисленные проблемы? – спросите Вы. Совершенно верно, это нейросети. 2. Возможность использования нейросетей для построения системы распознавания речи Классификация - это одна из «любимых» для нейросетей задач. Причем нейросеть может выполнять классификацию даже при обучении без ...
0 комментариев