Навигация
2.1.6. Расширение ММХ
Расширение ММХ ориентированно на мультимедийное, 2D и 3D-графическое и коммуникационное применение. Основная идея расширения MMX заключается в одновременной обработки нескольких элементов данных за одну инструкцию – так называемая технология SIMD (single Instruction – Multiple Data).
Расширение ММХ использует новые типы упакованных 64-битных данных:
упакованные байты (Packed byte) – восемь байт;
упакованные слова (Packed word) – четыре слова;
упакованные двойные слова (Packed doubleword) – два двойных слова;
учетверенное слово (Quadword) – одно слово.
Эти типы данных могут специальным образом обрабатываться в регистрах ММХ0-ММХ7, представляющих собой младшие биты стека 80-битных регистров FPU. Как и регистры FPU, эти регистры не могут использоваться для адресации памяти, совпадение регистров FPU и ММХ накладывает ограничения на чередование кодов FPU и ММХ – забота об их независимости лежит на программисте приложений ММХ.
Еще одна особенность технологии ММХ – поддержка арифметики с насыщением (saturating arithmetic). Ее отличие от обычной арифметики с циклическим переполнением (wraparound mode) заключается в том, что при возникновении переполнения в результате фиксируется максимальное возможное значение для используемого типа данных, а перенос игнорируется. В случае антипереполнения в результате фиксируется минимальное возможно значение. Граничные значения определяются типом (знаковые или беззнаковые) и разрядностью переменных. Такой режим вычислений актуален, например, для вычисления цветов в графике.
В систему команд введено 57 дополнительных инструкций для одновременной обработки нескольких единиц данных. Одновременно обрабатываемое 64-битное слово может содержать как одну единицу обработки, так и 8 однобайтных, 4 двухбайтных или 2 четырехбайтных операнда. Новые инструкции включают следующие группы:
арифметические (Arithmetic Instructions), включающие сложение и вычитание в разных режимах, умножение и комбинацию умножения и сложения;
сравнение (Comparison Instructions) элементов данных на равенство или по величине;
преобразование форматов (Conversion Instructions);
логические (Logical Instructions) – И, И-НЕ, ИЛИ и Исключающее ИЛИ, выполняемые над 64-битными операндами;
сдвиги (Shift Instructions) – логические и арифметические;
пересылки данных (Data Transfer Instructions) между регистрами ММХ и целочисленными регистрами или памятью;
очистка ММХ (Empty MMX State) – установка признаков пустых регистров в слове тегов.
Инструкции ММХ не влияют на флаги условий.
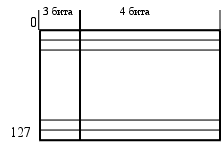
Регистры ММХ, в отличии от регистров FPU, адресуются физически а не относительно значения TOS. Более того, любая инструкция ММХ обнуляет поле TOS регистра состояния FPU. В слове тегов свободному регистру соответствует комбинация “11”, остальные комбинации указывают только на занятость регистра. После каждой операции ММХ биты тегов используемого регистра назначения обнуляются. Неиспользуемые в ММХ биты [79:64] регистров FPU заполняются единицами, так что ошибочное использование данных ММХ инструкций FPU приведет к исключению.
Инструкции ММХ не порождают новых исключений. Исключения при их выполнении могут возникать только при нарушении границ при обращениях к памяти (данные и инструкции). Однако если предшествующая инструкция FPU породила условие исключения, то оно произойдет при выполнении инструкции ММХ. После его обработки инструкция ММХ может быть благополучна исполнена.
Инструкции ММХ доступны из любого режима процессора. При переключении задач необходимо следить за корректностью сохранения контекста, как и при работе с FPU.
Часто чередование годов FPU и ММХ может снизить производительность за счет необходимости сохранения и восстановления весьма объемного контекста FPU.
2.1.7. Внутренний кэш
Внутренне кэширование обращений к памяти применяется в процессорах, начиная с 486-го. С кэшированием связаны новые функции процессоров, биты регистров и внешние сигналы.
Процессоры 486 и Pentium имеют внутренний кэш первого уровня, в Pentium Pro и Pentium II имеется и вторичный кэш. Процессоры могут иметь как единый кэш инструкций и данных, так и общий. Выделенный кэш инструкций обычно используется только для чтения. Для внутреннего кэша обычно используется наборно-ассоциативная архитектура.
Строки в кэш-памяти выделяются только при чтении, политика записи первых процессоров 486 – только Write Through (сквозная запись) – полностью программно-прозрачная. Более поздние модификации 486-го и все старшие процессоры позволяют переключаться на политику Write Back (обратная запись).
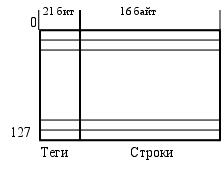
Работу кэша рассмотрим на примере четырехканального наборно-ассоциативного кэша процессора 486, его физическая структура приведена на рис. 3.1.7. Кэш является несекторированным – каждый бит достоверности (Valid bit) относится к целой строке, так что стока не может являться “частично достоверной”.
Работу внутренней кэш-памяти характеризуют следующие процессы: обслуживание запросов процессора на обращение к памяти, выделение и замещение строк для кэширования областей физической памяти, обеспечение согласованности данных внутреннего кэша и оперативной памяти, управление кэшированием.
Любой внутренний запрос процессора на обращение к памяти направляется на внутренний кэш. Теги четырех строк набора, который обслуживает данный адрес, сравниваются со старшими битами запрошенного физического адреса. Если адресуемая область представлена в строке кэш-памяти (случая попадания –cache hit), запрос на чтение обслуживается только кэш-памятью, не выходя на внешнюю шину. Запрос на запись модифицирует данную строку, и в зависимости от политики записи либо сразу выходит на внешнюю шину (при сквозной записи), либо несколько позже (при использовании алгоритма обратной записи).
4 Ru
. . .
. . .
. . .
. . .
. . .
Теги действительности
Канал 1
Канал 4
Диспетчер
Рис 3.1.7. Структура первичного кэша процессора 486
В случае промаха (Cache Miss) запрос на запись направляется только на внешнюю шину, а запрос на чтение обслуживается сложнее. Если этот зарос относится к кэшируемой области памяти, выполняется цикл заполнения целой строки кэша – все 16 байт (32 для Pentium) читаются из оперативной памяти и помещаются в одну из строк кэша, обслуживающего данный адрес. Если затребованные данные не укладываются в одной строке, заполняется и соседняя. Заполнение строки процессор старается выполнить самым быстрым способом – пакетным циклом с 32-битными передачами (64-битными для Pentium и старше).
Внутренний запрос процессора на данные удовлетворяется сразу, как только затребованные данные считываются из ОЗУ – заполнение строки до конца может происходить параллельно с обработкой полученных данных. Если в наборе, который обслуживает данный адрес памяти, имеется свободная строка (с нулевым битом достоверности), заполнена будет она и для нее установится бит достоверности. Если свободных строк в наборе нет, будет замещена строка, к которой дольше всех не было обращений. Выбор строки для замещения выполняется на основе анализа бит LRU (Least Recently Used) по алгоритму “псевдо-LRU”. Эти биты (по три на каждый из наборов) модифицируются при каждом обращении к строке данного набора (кэш-попадании или замещении).
Таким образом, выделение и замещение строк выполнятся только кэш-промахов чтения, при промахах записи заполнение строк не производится. Если затребованная область памяти присутствует в строке внутреннего кэша, то он обслужит этот запрос. Управлять кэшированием можно только на этапе заполнения строк; кроме того, существует возможность их аннулирования – объявления недостоверными и очистка всей кэш-памяти.
Очистка внутренней кэш-памяти при сквозной записи (обнуление бит достоверности всех строк) осуществляется внешним сигналом FLUSH# за один такт системной шины (и, конечно же, по сигналу RESET). Кроме того, имеются инструкции аннулирования INVD и WBINVD. Инструкция INVD аннулирует строки внутреннего кэша без выгрузки модифицированных строк, поэтому ее неосторожное использование при включенной политике обратной записи может привести к нарушению целостности данных в иерархической памяти. Инструкция WBINVD предварительно выгружает модифицированные строки в основную память (при сквозной записи ее действие совпадает с INVD). При обратной записи очистка кэша подразумевает и выгрузку всех модифицированных строк в основную память. Для этого, естественно, может потребоваться и значительное число тактов системной шины, необходимых для проведения всех операций записи.
Аннулирование строк выполняется внешними схемами – оно необходимо в системах, у которых в оперативную память запись может производить не только один процессор, а и другие контроллеры шины – процессор или периферийные контроллеры. В этом случае требуются специальные средства для поддержания согласованности данных во всех ступенях памяти – в первичной и вторичной кэш-памяти и динамического ОЗУ. Если внешний (по отношению к рассматриваемому процессору) контроллер выполняет запись в память, процессору должен быть подан сигнал AHOLD. По этому сигналу процессор немедленно отдает управление шиной адреса A[31:4], на которой внешним контроллером устанавливается адрес памяти, сопровождаемый стробом EADS#. Если адресованная память присутствует в первичном кэше, процессор аннулирует строку – сбрасывает бит достоверности этой строки (она освобождается). Аннулирование строки процессор выполняет в любом состоянии.
Управление заполнением кэша возможно и на аппаратном и на программном уровнях. Процессор позволяет кэшировать любую область физической памяти. Внешние схемы могут запрещать процессору кэшировать определенные области памяти установкой высокого уровня сигнала KEN# во время циклов доступа к этим областям памяти. Этот сигнал управляет только возможностью заполнения строк кэша из адресованной области памяти. Программно можно управлять кэшируемостью каждой страницы памяти – запрещать единичным значением бита PCD (Page Cache Disable) в таблице или каталоге страниц. Для процессоров с WB-кэшем бит PWT (Page Write Through) позволяет постранично управлять и алгоритмом записи. Общее программное управление кэшированием осуществляется посредством бит управляющего регистра CR0:CD (Cache Disable) и NW (No Write Through). Возможны следующие сочетания бит регистра:
CD=1, NW=1 – если после установки такого значения выполнить очистку кэша, кэш будет полностью отключен. Если же перед установкой этого сочетания бит кэша был заполнен, а очистка не производилась, кэш превращается в “замороженную” область статической памяти;
CD=1, CW=0 – заполнение кэша запрещено, но сквозная запись разрешена. Эффект аналогичен временному переводу сигнала KEN# в высокое (пассивное) состояние. Этот режим может использоваться для временного отключения кэша, после которого возможно его включение без очистки;
CD=0, NW=1 – запрещенная комбинация (вызывает отказ общей защиты);
CD=0, NW=0 – нормальный режим работы со сквозной записью.
Для полного запрета кэша необходимо установить CD=1 и NW=1, после чего выполнить очистку (Flush). Без очистки кэш будет обслуживать запросы в случае попаданий.
Процессоры 486 и старше имеют выходные сигналы PCD и PWT, управляющие работой вторичного (внешнего) кэша (они же управляют и внутренним кэшем). В циклах обращения к памяти, когда страничные преобразования не используются (например, при обращении к таблице каталогов страниц), источником сигналов являются биты PCD и PWT регистра CR3, при обращении к каталогу страниц – биты PCD и PWT из дескриптора соответствующего вхождения каталога, при обращении к самим данным – биты PCD и PWT из дескриптора страницы. Кроме того, оба этих сигнала могут принудительно устанавливаться общими битами управления кэшированием CD и NW регистра CRO.
Режим обратной записи может разрешаться только аппаратно сигналом WB/WT#, вырабатываемым внешними схемами.
В пространстве памяти РС имеются области, для которых кэширование принципиально недопустимо (например, разделяемая память адаптеров) или непригодна политика обратной записи. Кроме того, кэширование иногда полезно отключать при выполнении однократно исполняемых участков программы (например, инициализации) с тем, чтобы из кэша не вытиснялись более часто используемые фрагменты. Напомним, что запретить можно только заполнение строк, а обращение к памяти, уже представленной действительными строками кэша, все равно будет обслуживаться из кэша. Для полного запрета работы кэша строки должны быть аннулированы.
Программно при включенном режиме страничного преобразования кэшированием управляют биты атрибутов страниц (на уровне таблицы страниц и их каталога), биты PCD и PWT регистра CR3, и, наконец, глобально кэшированием управляют биты CD и NW регистра CR0.
Аппаратно (сигналом KEN#) внешние схемы могут управлять кэшированием (разрешать заполнение строк) для каждого конкретного адреса обращения к физической памяти.
Похожие работы
... . В качестве такого разъема AMD решила использовать 462-контактный Socket A, который по своим размерам, да и по внешнему виду похож как на Socket 7, так и на Socket 370. Поэтому, с Socket A процессорами AMD можно использовать старые Socket 7 и Socket 370 кулеры. Единственное, не следует при этом забывать, что тепловыделение Duron несколько превосходит количество тепла, отдаваемое Celeron, поэтому ...
... меньше размер транзистора, тем меньше тепла он излучает при работе. Первые процессоры Итак, разобравшись с некоторыми основными свойствами процессоров, перейдем непосредственно к истории. В далеком 1971 году корпорация Intel явила миру первый микропроцессор, прадедушку того гигагерцового монстра, что стоит у тебя в компьютере. Первый микропроцессор имел индекс 4004. Это был четырехразрядный ...
... оснащать их дополнительными устройствами сотен различных производителей. Итак, после начала широкого внедрения персональных компьютеров в повседневную жизнь, продолжилось быстрое развитие вычислительной техники. Остановимся на наиболее важном элементе: микропроцессор – это эффективный с технологической и экономической точки зрения инструмент для переработки возрастающих потоков информации. Новое ...
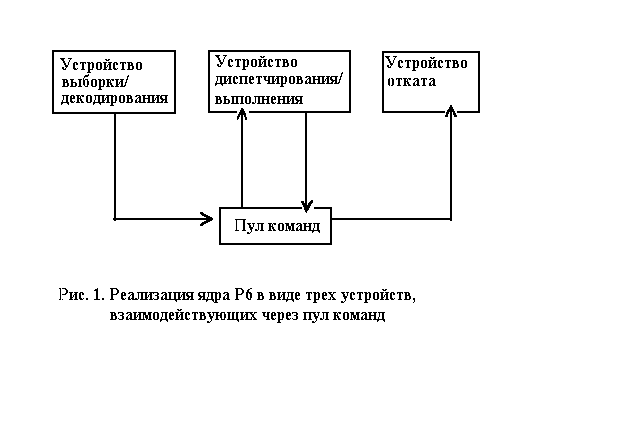
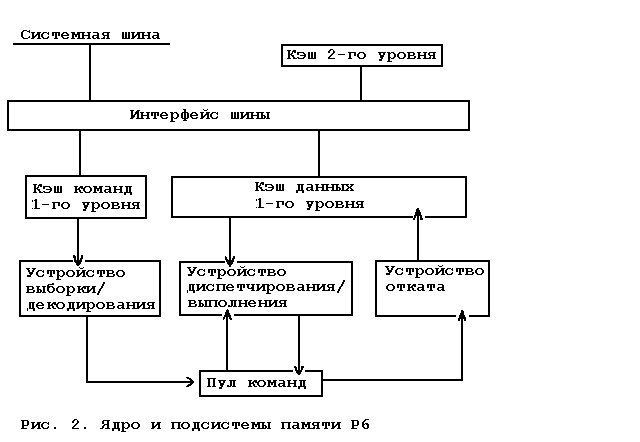
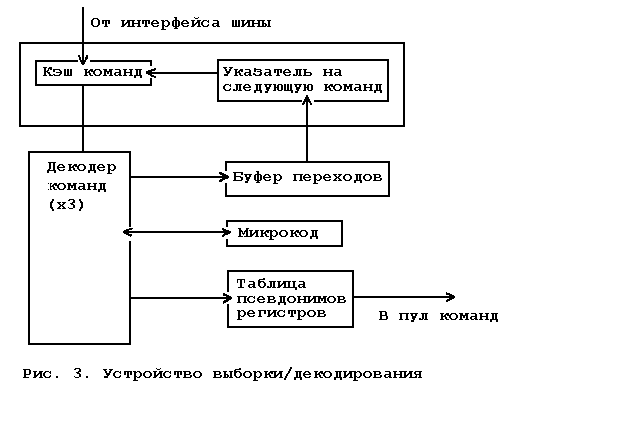
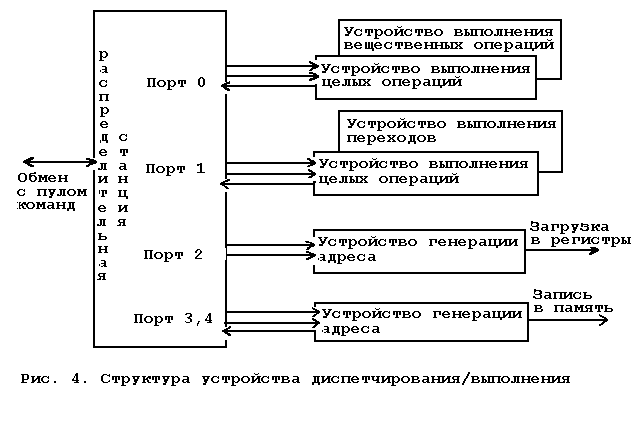
... устройство выбор- ки/декодирования должно правильно предсказать для того, чтобы ра- бота устройства диспетчирования/выполнения не оказалась бесполез- ной. Небольшое количество регистров в архитектуре процессоров «Intel» приводит к интенсивному использованию каждого из них и, как следствие, к возникновению множества мнимых зависимостей меж- ду командами, использующими один и тот же регистр ...
0 комментариев