Понятие, содержание, объект и предмет информатики
Информатизация общества
Большинство работающих (около 70 %) занято в информационной сфере, т. е. сфере производства информации и информационных услуг
Информация и ее свойства
Меры информации
Семантическая мера информации
Кодирование сигналов
Кодирование звука
Потенциальный код с инверсией при единице
Модуляция сигналов
Процесс сбора информации
Процесс передачи информации
Телетайпная связь, при которой ввод информации в телетайп может осуществляться вручную с клавиатуры и автоматизированно с перфоленты
Хранение информации
Системы хранения данных
Система хранения данных начального уровня (рис. 1.18)
Принципы информационного права
Методы информационного права
Основы защиты информации
Классификация способов и средств защиты
Арифметические и логические основы ЭВМ
Десятичная система счисления
Восьмеричная система счисления
Метод деления
Генератор тактовых импульсов генерирует последовательность электрических импульсов, их частота определяет тактовую частоту машины
Многосвязный интерфейс: каждый блок ПК связан с прочими блоками своими локальными проводами. Он применяется только в простейших бытовых ПК
Функциональные характеристики ПЭВМ
Система шин МП
Общая характеристика способов реализации
Внешняя память
Правила обращения с дисками
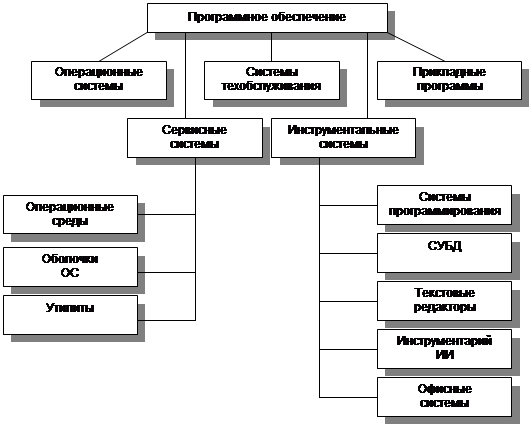
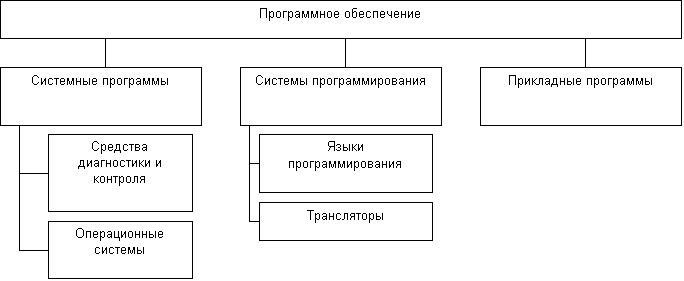
Общая характеристика и состав программного
Система программирования
Прикладное программирование
Коммуникационные ППП предназначены для организации взаимодействия пользователя с удаленными абонентами или информационными ресурсами сети
Состав и структура операционной системы MS-DOS
Логическая структура гибкого магнитного диска
Логическая структура жесткого магнитного диска
Файловая система MS-DOS
Характеристика компьютерных вирусов
Загрузочные вирусы
Общие сведения об архивации файлов
Операционная система Windows
Навигация
Кодирование сигналов
Информатика и программное обеспечение ПЭВМ
448518
знаков
14
таблиц
55
изображений
1.5 Кодирование сигналов
1.5.1 Основные виды и способы обработки
и кодирования данных
Этап подготовки информации связан с процессом формирования структуры информационного потока. Такая структура должна обеспечивать возможность передачи информации от объекта к субъекту (от источника к потребителю) по каналам коммуникаций посредством определенных сигналов или знаков, а также возможность однозначного понимания этих сигналов и обеспечения их записи на соответствующие носители информации. Для этого осуществляется кодирование сигналов.
Кодирование информации – одна из базовых тем курса теоретических основ информатики, отражающая фундаментальную необходимость представления информации в какой-либо форме. При этом слово "кодирование" понимается не в узком смысле – как способ сделать сообщение непонятным для всех, кто не владеет ключом кода, а в широком – как представление информации в виде сообщения на любом языке. В канале связи сообщение, составленное из символов (букв) одного алфавита, может преобразоваться в сообщение из символов (букв) другого алфавита.
Код – правило (алгоритм), сопоставляющее каждое конкретное сообщение (информацию) со строго определенной комбинацией различных символов (или соответствующих им сигналов).
Кодирование – процесс преобразования сообщения (информации) в комбинацию различных символов или соответствующих им сигналов, осуществляющийся в момент поступления сообщения от источника в канал связи.
Кодовое слово – последовательность символов, которая в процессе кодирования присваивается каждому из множеств передаваемых сообщений.
Декодирование – процесс восстановления содержания сообщения по данному коду.
Необходимым условием декодирования является взаимно однозначное соответствие кодовых слов во вторичном алфавите кодируемым символам первичного алфавита.
Устройство, обеспечивающее кодирование, называют кодировщиком.
Система кодирования – совокупность правил кодового обозначения объектов – применяется для замены названия объекта на условное обозначение (код) в целях обеспечения удобной и более эффективной обработки информации, т. е. кодирование – это отображение информации с помощью некоторого языка. Любой язык состоит из алфавита, включающего в себя буквы, цифры и другие символы, и правил составления слов и фраз (синтаксических правил).
Первичный алфавит – символы, при помощи которых записано передаваемое сообщении; вторичный – символы, при помощи которых сообщение трансформируется в код.
Код характеризуется длиной (числом позиций в коде) и структурой (порядком расположения символов, используемых для обозначения классификационного признака).
Неравномерные (некомплектные) коды – это коды, с помощью которых сообщения кодируются комбинациями с неравномерным количеством символов; равномерные (комплектные) – коды, с помощью которых сообщения представлены комбинациями с равным количеством символов.
5) Для хранения в ЭВМ информация кодируется. При выборе языка создатели руководствовались следующими соображениями:
- буквы алфавита должны надежно распознаваться (нельзя допустить, чтобы одна буква была принята за другую);
- алфавит должен быть как можно проще, т. е. содержать поменьше букв;
- синтаксис языка (правила построения слов и фраз) должен быть строгим, однозначным, не допускающим неопределенности.
6) Таким свойством обладают математические теории, в них все строго определено.
7) 1.5.2 Кодирование текста
Не возникает никаких проблем при кодировании информации, представимой с помощью ограниченного набора символов – алфавита. Достаточно пронумеровать все знаки этого алфавита и затем записывать в память компьютера и обрабатывать соответствующие номера. Самым простым алфавитом является тот, в котором всего две буквы, два символа.
При кодировании текста для каждого его символа отводится обычно 1 байт. Именно по этой причине ячейка памяти в компьютере сделана так, что может хранить сразу восемь бит (1 байт), т. е. целый символ. Это позволяет использовать 28 = 256 различных символов, так как в ЭВМ надо кодировать все буквы: английские – 52 буквы (прописные и строчные), русские – 66 букв, 10 цифр, знаки препинания, арифметических операций и т. п.:
| Разрядность | Пример | Количество |
| 1 | 0 | 2 = 21 |
| 2 | 00 | 4 = 22 |
| 3 | 000 | 8 = 23 |
| 4 | 0000 | 16 = 24 |
8)
9) Хорошо видно, что если у числа разрядность равна n, то количество n-разрядных чисел равно 2n:
10)
| Разрядность | Количество чисел |
| 5 | 25 = 32 |
| 6 | 26 = 62 |
| 7 | 27 = 128 |
| 8 | 28 = 256 |
| 9 | 29 = 512 |
| 10 | 210 = 1024 |
11)
12) и так далее.
13) Чтобы закодировать порядка 256 букв и символов, требуется использовать 8-разрядные числа.
Соответствие между символом и его кодом может быть выбрано совершенно произвольно. Однако на практике необходимо иметь возможность прочесть на одном компьютере текст, созданный на другом, поэтому таблицы кодировок стараются стандартизовать. Практически все использующиеся сейчас таблицы основаны на "американском стандартном коде обмена информацией" ASCII. Он определяет значения для нижней половины кодовой таблицы – первых 127 кодов (32 управляющих кода, основные знаки препинания и арифметические символы, цифры и латинские буквы). В результате, эти символы отображаются верно, какая бы кодировка не использовалась на конкретном компьютере. Хуже обстоит дело с национальными символами и типографскими знаками препинания. А особенно не повезло языкам, использующим кириллицу (русскому, украинскому, белорусскому, болгарскому и т. д.).
Например, для русского языка сейчас широко используются пять таблиц кодировок:
- CP866 (альтернативная DOS) – на PC-совместимых компьютерах при работе с операционными системами DOS и OS/2, а также в любительской международной сети Фидо (Fidonet);
- CP1251 (Windows-кодировка) – на PC-совместимых компью-терах при работе под Windows 3.1 и Windows 95;
- KOI-8r – самая старая из использующихся до сих пор кодировок. Применяется на компьютерах, работающих под UNIX, является фактическим стандартом для русских текстов в сети Internet;
- Macintosh Cyrillic – предназначена для работы со всеми кириллическими языками на Макинтошах.
- ISO-8859. Эта кодировка задумывалась как международный стандарт для кириллицы, однако на территории России практически не применяется.
14) Сейчас, когда объем памяти компьютеров чрезвычайно вырос, уже нет необходимости очень сильно "экономить" при кодировании текста. Можно позволить себе роскошь "тратить" для хранения текста вдвое больше памяти (выделяя для каждого символа не 1, а 2 байт). При этом появляется возможность разместить в кодовой таблице – каждый на своем месте – не только буквы европейских алфавитов (латинского, кириллицы, греческого), но и буквы арабского, грузинского и многих других языков и даже большую часть японских и китайских иероглифов, поскольку два байта могут хранить число от 0 до 65 535. Двухбайтная международная кодировка Unicode, разработанная несколько лет назад, теперь начинает внедряться на практике. В компьютере все составные части соединяются между собой с помощью шины (магистрали), т. е. пучка проводов.
15) Теперь нам должно стать понятно, почему шина содержит 8, 16 или 32 провода. Если в шине 8 проводов, то по ней можно передать одновременно 8 бит, т. е. 1 байт (1 символ) информации. Такой компьютер называется восьмиразрядным, (первые персональные компьютеры IBM).
16) Если в шине 16 проводов, то по ней можно передать одновременно 2 байт информации; если 32 провода – 4 байт, если 64 провода – 8 байт.
17)
18) 1.5.3. Два способа кодирования изображения
Изображение на экране компьютера (или при печати с по-мощью принтера) составляется из маленьких точек – пикселов. Их так много, и они настолько малы, что человеческий глаз воспринимает картинку как непрерывную. Следовательно, качество изображения будет тем выше, чем плотнее расположены пиксели (т. е. чем больше разрешение устройства вывода) и точнее закодирован цвет каждого из них.
В простейшем случае каждый пиксел может быть или черным, или белым. Значит, для его кодирования достаточно одного бита. Однако при этом полутона приходится имитировать, чередуя черные и белые пиксели (заметим, что примерно так формируют полутоновое изображение на принтерах и при типографской печати). Чтобы получить реальные полутона, для хранения каждого пикселя нужно отводить большее количество разрядов. В этом случае черный цвет по-прежнему будет представлен нулем, а белый – максимально возможным числом. Например, при восьмибитном кодировании получится 256 разных значений яркости – 256 полутонов.
Сложнее обстоит дело с цветными изображениями, так как здесь нужно закодировать не только яркость, но и оттенок пикселя. Изображение на мониторе формируется путем сложения в различных пропорциях трех основных цветов: красного, зеленого и синего. Значит просто нам нужно хранить информацию о яркости каждой из этих составляющих.
Для получения наивысшей точности цветопередачи достаточно иметь по 256 значений для каждого из основных цветов (вместе это дает 2563 – более 16 млн. оттенков). Во многих случаях можно обойтись несколько меньшей точностью цветопередачи. Если использовать для представления каждой составляющей по 5 бит (тогда для хранения данных пикселя будет нужно не 3, а 2 байт), удастся закодировать 32 768 оттенков.
На практике встречаются (и нередко) ситуации, когда гораздо важнее не идеальная точность, а минимальный размер файла: бывают изображения, где изначально используется небольшое количество цветов. В этих случаях поступают так: собирают все нужные оттенки в таблицу и нумеруют, после чего хранят уже не полный код цвета каждого пикселя, а номера (индексы) цветов в таблице. Чаще всего используют 256-цветные таблицы. В разных компьютерах могут быть приняты разные стандартные таблицы цветов, поэтому не исключено, что открыв полученный от кого-нибудь графический файл, можно увидеть совершенно немыслимую картинку.
При печати на бумаге используется несколько иная цветовая модель: если монитор испускает свет, то оттенок получается в результате сложения цветов, а краски поглощают свет – цвета вычитаются. Поэтому в качестве основных используют голубую, сиреневую и желтую краски. Кроме того, из-за неидеальности красителей к ним обычно добавляют четвертую краску – черную. Для хранения информации о каждой краске чаще всего используют 1 байт.
Растровые изображения очень хорошо передают реальные образы. Они замечательно подходят для фотографий, картин и в случаях, когда требуется максимальная "естественность". Такие изображения легко выводить на монитор или принтер, поскольку эти устройства тоже основаны на растровом принципе. Однако есть у них и ряд недостатков. Растровое изображение высокого качества (с высоким разрешением и большой глубиной цвета) может занимать десятки, и даже сотни мегабайт памяти. Для их обработки нужны мощные компьютеры, но и они нередко "задумываются" на десятки минут. Любое изменение размеров неизбежно приводит к ухудшению качества: при увеличении пикселы не могут появиться "из ничего", при уменьшении – часть пикселов будет просто выброшена.
Есть другой способ представления изображений – объектная (векторная) графика. В этом случае в памяти хранится не сам рисунок, а правила его построения, т. е., например, не все пикселы круга, а команда "построить круг радиусом 30 с центром в точке с координатами (50, 135) и закрасить его красным цветом". Быстродействия современных компьютеров вполне достаточно, чтобы перерисовка происходила почти мгновенно.
На первый взгляд, все становится гораздо более сложным. Зачем же это нужно? Во-первых, и это самое главное, векторное изображение можно как угодно масштабировать, выводить на устройства, имеющие любое разрешение, – и всегда будет получаться результат с наивысшим для данного устройства качеством, ведь картинка каждый раз "рисуется" заново, используя столько пикселов, сколько возможно.
Во-вторых, в векторном изображении все части (так называемые "примитивы") могут быть изменены независимо друг от друга: любой из них можно увеличить, повернуть, деформировать, перекрасить, даже стереть, но остальных объектов это никоим образом не коснется.
В-третьих, даже очень сложные векторные рисунки, содержащие тысячи объектов, редко занимают более нескольких сотен килобайт, т. е. в десятки, сотни, а то и тысячи раз меньше аналогичного растрового.
Но почему, если все так хорошо, векторная графика не вытеснила растровую? Сам принцип ее формирования предполагает использование объектов с исключительно ровными четкими границами, а это сразу выдает их искусственность, поэтому область применения векторной графики довольно ограничена – это чертежи, схемы, стилизованные рисунки, эмблемы и другие подобные изображения.
Похожие работы
... вычислительной техники, а также принципы функционирования этих средств и методы управления ими. Из этого определения видно, что информатика очень близка к технологии, поэтому ее предмет нередко называют информационной технологией. Предмет информатики составляют следующие понятия: а) аппаратное обеспечение средств вычислительной техники; б) программное обеспечение средств вычислительной техники ...
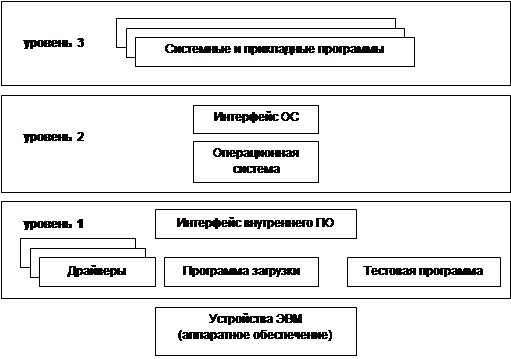
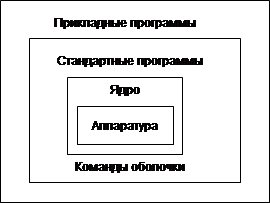
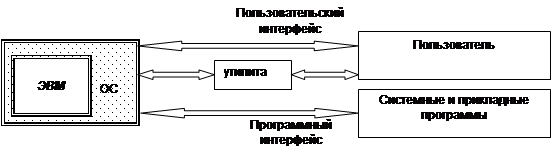
... – набор утилит и некоторые инструментальные программы (пользовательский интерфейс). К третьему уровню относятся все остальные программы. Программы второго и третьего уровней хранятся в файлах. Программное обеспечение первого уровня является машинно-зависимым [computer-independent]. То есть для каждого микропроцессора или семейства ЭВМ набор данных программ уникален. Операционная система имеет ...
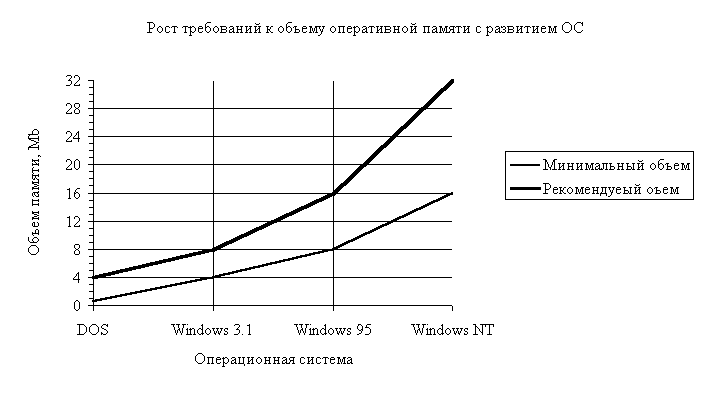

... Вы сможете работать на своем компьютере. От выбора ОС зависят также производительность вашей работы, степень защиты Ваших данных, необходимые аппаратные средства и т.д. [9] 5. Персональная ЭВМ: развернутая структура; структура программного обеспечения; выбор ПЭВМ (если возможно, то по прайс-листу некоторой фирмы). Развернутая структура (тонкие линии показывают управляющие связи, толстые – ...
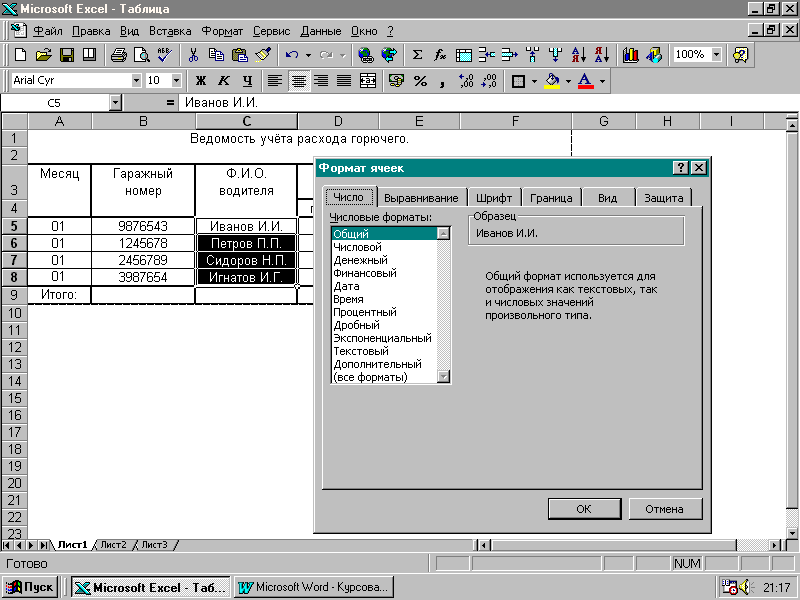
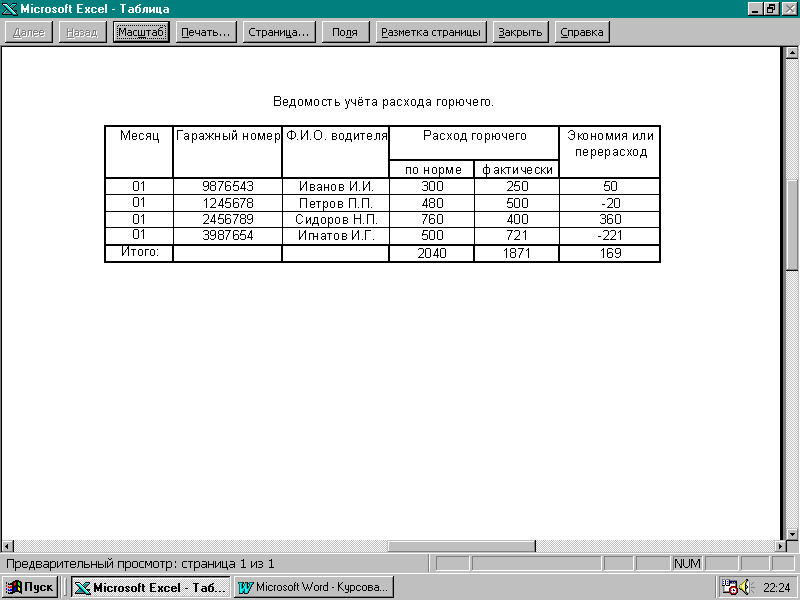
... » (Zero Administration Initiative), которая будет реализована во всех следующих версиях Windows. SMS- сервер управления системами У SMS две задачи — централизовать управление сетью и упростить распространение программного обеспечения и его модернизацию на клиентских системах. SMS подойдет и малой, и большой сети — это инструмент управления сетью на базе Windows NT, эффективно использующий ...
0 комментариев