Процесс кластеризации
Алгоритм нечеткой кластеризации
Применение кластеризации
Структура сети Кохонена
Анализ отклика (выбор нейрона)
Выбор начальных значений векторов весовых коэффициентов и нейронов
Архитектура сети
Правило обучения слоя Кохонена
Моделирование кластеризации данных
Создание сети
Моделирование одномерной карты Кохонена
Навигация
Моделирование сети кластеризации данных в MATLAB NEURAL NETWORK TOOL
Моделирование сети кластеризации данных в MATLAB NEURAL NETWORK TOOL
77313
знаков
3
таблицы
20
изображений
МОДЕЛИРОВАНИЕ СЕТИ КЛАСТЕРИЗАЦИИ ДАННЫХ В MATLAB NEURAL NETWORK TOOL
СОДЕРЖАНИЕ
Введение
1. Общие сведения о кластеризации
1.1 Понятие кластеризации
1.2 Процесс кластеризации
1.3 Алгоритмы кластеризации
1.3.1 Иерархические алгоритмы
1.3.2 k-Means алгоритм
1.3.3 Минимальное покрывающее дерево
1.3.4 Метод ближайшего соседа
1.3.5 Алгоритм нечеткой кластеризации
1.3.6 Применение нейронных сетей
1.3.7 Генетические алгоритмы
1.4 Применение кластеризации
2. Сеть Кохонена
2.1 Структура сети Кохонена
2.2 Обучение сети Кохонена
2.3 Выбор функции «соседства»
2.4 Карта Кохонена
2.5 Задачи, решаемые при помощи карт Кохонена
3. Моделирование сети кластеризации данных в MATLAB NEURAL NETWORK TOOLBOX
3.1 Самоорганизующиеся нейронные сети в MATLAB NNT
3.1.1 Архитектура сети
3.1.2 Создание сети
3.1.3 Правило обучения слоя Кохонена
3.1.4 Правило настройки смещений
3.1.5 Обучение сети
3.1.6 Моделирование кластеризации данных
3.2 Карта Кохонена в MATLAB NNT
3.2.1 Топология карты
3.2.2 Функции для расчета расстояний
3.2.3 Архитектура сети
3.2.4 Создание сети
3.2.5 Обучение сети
3.2.6 Моделирование одномерной карты Кохонена
3.2.7 Моделирование двумерной карты Кохонена
Выводы
Перечень ссылок
ВВЕДЕНИЕ
В настоящее время ни у кого не вызывает удивления проникновение компьютеров практически во все сферы человеческой деятельности. Совершенствование элементной базы, определяющей архитектуру компьютера, и распараллеливания вычислений позволяют быстро и эффективно решать задачи все возрастающей сложности. Решение многих проблем немыслимо без применения компьютеров. Однако, обладая огромным быстродействием, компьютер часто не в состоянии справиться с поставленной перед ним задачей так, как бы это сделал человек. Примерами таких задач могут быть задачи распознавания, понимания речи и текста, написанного от руки, и многие другие. Таким образом, сеть нейронов, образующая человеческий мозг, являясь, как и компьютерная сеть, системой параллельной обработки информации, во многих случаях оказывается более эффективной. Идея перехода от обработки заложенным в компьютер алгоритмом некоторых формализованных знаний к реализации в нем свойственных человеку приемов обработки информации привели к появлению искусственных нейронных сетей (ИНС).
Отличительной особенностью биологических систем является адаптация, благодаря которой такие системы в процессе обучения развиваются и приобретают новые свойства. Как и биологические нейронные сети, ИНС состоят из связанных между собой элементов, искусственных нейронов, функциональные возможности которых в той или иной степени соответствуют элементарным функциям биологического нейрона. Как и биологический прототип, ИНС обладает следующим свойствами:
· адаптивное обучение;
· самоорганизация;
· вычисления в реальном времени;
· устойчивость к сбоям.
Таким образом, можно выделить ряд преимуществ использования нейронных сетей:
· возможно построение удовлетворительной модели на нейронных сетях даже в условиях неполноты данных;
· искусственные нейронные сети легко работают в распределенных системах с большой параллелизацией в силу своей природы;
· поскольку искусственные нейронные сети подстраивают свои весовые коэффициенты, основываясь на исходных данных, это помогает сделать выбор значимых характеристик менее субъективным.
Сейчас мир переполнен различными данными и информацией - прогнозами погод, процентами продаж, финансовыми показателями и массой других. Часто возникают задачи анализа данных, которые с трудом можно представить в математической числовой форме. Например, когда нужно извлечь данные, принципы отбора которых заданы нечетко: выделить надежных партнеров, определить перспективный товар, проверить кредитоспособность клиентов или надежность банков и т.п. И для того, чтобы получить максимально точные результаты решения этих задач необходимо использовать различные методы анализа данных. В частности, можно использовать ИНС для кластеризации данных, что, на мой взгляд является наиболее перспективным подходом.
1. ОБЩИЕ СВЕДЕНИЯ О КЛАСТЕРИЗАЦИИ
1.1 Понятие кластеризации
Классификация – наиболее простая и распространенная задача. В результате решения задачи классификации обнаруживаются признаки, которые характеризуют группы объектов исследуемого набора данных - классы; по этим признакам новый объект можно отнести к тому или иному классу.
Кластеризация – это автоматическое разбиение элементов некоторого множества на группы в зависимости от их схожести. Синонимами термина "кластеризация" являются "автоматическая классификация", "обучение без учителя" и "таксономия".
Задача кластеризации сходна с задачей классификации, является ее логическим продолжением, но ее отличие в том, что классы изучаемого набора данных заранее не предопределены. Таким образом кластеризация предназначена для разбиения совокупности объектов на однородные группы (кластеры или классы). Если данные выборки представить как точки в признаковом пространстве, то задача кластеризации сводится к определению "сгущений точек".
Целью кластеризации является поиск существующих структур.
Кластеризация является описательной процедурой, она не делает никаких статистических выводов, но дает возможность провести разведочный анализ и изучить "структуру данных".
Само понятие "кластер" определено неоднозначно: в каждом исследовании свои "кластеры". Переводится понятие кластер как "скопление", "гроздь". В искусственных нейронных сетях под понятием кластер понимается подмножество «близких друг к другу» объектов из множества векторов характеристик. Следовательно, кластер можно охарактеризовать как группу объектов, имеющих общие свойства.
Характеристиками кластера можно назвать два признака:
· внутренняя однородность;
· внешняя изолированность.
В таблице 1.1 приведено сравнение некоторых параметров задач классификации и кластеризации.
Таблица 1.1
Сравнение классификации и кластеризации
| Характеристика | Классификация | Кластеризация |
| Контролируемость обучения | Контролируемое обучение | Неконтролируемое обучение |
| Стратегия | Обучение с учителем | Обучение без учителя |
| Наличие метки класса | Обучающее множество сопровождается меткой, указывающей класс, к которому относится наблюдение | Метки класса обучающего множества неизвестны |
| Основание для классификации | Новые данные классифицируются на основании обучающего множества | Дано множество данных с целью установления существования классов или кластеров данных |
На рисунке 1.1 схематически представлены задачи классификации и кластеризации
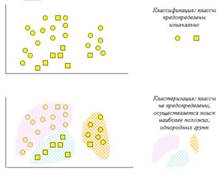
Рисунок 1.1 – Сравнение задач классификации и кластеризации
Кластеры могут быть непересекающимися, или эксклюзивными, и пересекающимися. Схематическое изображение непересекающихся и пересекающихся кластеров дано на рисунке 1.2
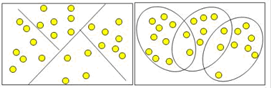
Рисунок 1.2 – Непересекающиеся и пересекающиеся кластеры
0 комментариев