Процесс кластеризации
Алгоритм нечеткой кластеризации
Применение кластеризации
Структура сети Кохонена
Анализ отклика (выбор нейрона)
Выбор начальных значений векторов весовых коэффициентов и нейронов
Архитектура сети
Правило обучения слоя Кохонена
Моделирование кластеризации данных
Создание сети
Моделирование одномерной карты Кохонена
Навигация
Процесс кластеризации
Моделирование сети кластеризации данных в MATLAB NEURAL NETWORK TOOL
77313
знаков
3
таблицы
20
изображений
1.2 Процесс кластеризации
Процесс кластеризации зависит от выбранного метода и почти всегда является итеративным. Он может стать увлекательным процессом и включать множество экспериментов по выбору разнообразных параметров, например, меры расстояния, типа стандартизации переменных, количества кластеров и т.д. Однако эксперименты не должны быть самоцелью - ведь конечной целью кластеризации является получение содержательных сведений о структуре исследуемых данных. Полученные результаты требуют дальнейшей интерпретации, исследования и изучения свойств и характеристик объектов для возможности точного описания сформированных кластеров.
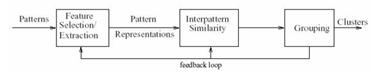
Рисунок 1.3 – Общая схема кластеризации
Кластеризация данных включает в себя следующие этапы:
а) Выделение характеристик.
Для начала необходимо выбрать свойства, которые характеризуют наши объекты, ими могут быть количественные характеристики (координаты, интервалы…), качественные характеристики (цвет, статус, воинское звание…) и т.д. Затем стоит попробовать уменьшить размерность пространства характеристических векторов, то есть выделить наиболее важные свойства объектов. Уменьшение размерности ускоряет процесс кластеризации и в ряде случаев позволяет визуально оценивать результаты. Выделенные характеристики стоит нормализовать. Далее все объекты представляются в виде характеристических векторов. Мы будем полностью отождествлять объект с его характеристическим вектором.
б) Определение метрики.
Следующим этапом кластеризации является выбор метрики, по которой мы будем определять близость объектов. Метрика выбирается в зависимости от:
· пространства, в котором расположены объекты;
· неявных характеристик кластеров.
Например, если все координаты объекта непрерывны и вещественны, а кластера должны представлять собой нечто вроде гиперсфер, то используется классическая евклидова метрика (на самом деле, чаще всего так и есть):
![]() . (1.1)
. (1.1)
в) Представление результатов.
Результаты кластеризации должны быть представлены в удобном для обработки виде, чтобы осуществить оценку качества кластеризации. Обычно используется один из следующих способов:· представление кластеров центроидами;
· представление кластеров набором характерных точек;
· представление кластеров их ограничениями.
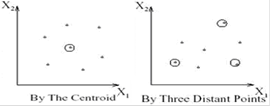
Рисунок 1.4 – Способы представления кластеров
Оценка качества кластеризации может быть проведена на основе следующих процедур:
· ручная проверка;
· установление контрольных точек и проверка на полученных кластерах;
· определение стабильности кластеризации путем добавления в модель новых переменных;
· создание и сравнение кластеров с использованием различных методов.
Разные методы кластеризации могут создавать разные кластеры, и это является нормальным явлением. Однако создание схожих кластеров различными методами указывает на правильность кластеризации.
1.3 Алгоритмы кластеризации
Следует отметить, что в результате применения различных методов кластерного анализа могут быть получены кластеры различной формы. Например, возможны кластеры "цепочного" типа, когда кластеры представлены длинными "цепочками", кластеры удлиненной формы и т.д., а некоторые методы могут создавать кластеры произвольной формы. Различные методы могут стремиться создавать кластеры определенных размеров (например, малых или крупных), либо предполагать в наборе данных наличие кластеров различного размера. Некоторые методы кластерного анализа особенно чувствительны к шумам или выбросам, другие - менее. В результате применения различных методов кластеризации могут быть получены неодинаковые результаты, это нормально и является особенностью работы того или иного алгоритма. Данные особенности следует учитывать при выборе метода кластеризации. На сегодняшний день разработано более сотни различных алгоритмов кластеризации.
Классифицировать алгоритмы можно следующим образом:
· строящие «снизу вверх» и «сверху вниз»;
· монотетические и политетические;
· непересекающиеся и нечеткие;
· детерминированные и стохастические;
· потоковые (оnline) и не потоковые;
· зависящие и не зависящие от порядка рассмотрения объектов.
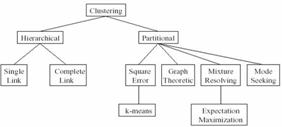
Рисунок 1.5 – Классификация алгоритмов кластеризации
Далее будут рассмотрены основные алгоритмы кластеризации.
1.3.1 Иерархические алгоритмы
Результатом работы иерархических алгоритмов является дендограмма (иерархия), позволяющая разбить исходное множество объектов на любое число кластеров. Два наиболее популярных алгоритма, оба строят разбиение «снизу вверх»:
· single-link – на каждом шаге объединяет два кластера с наименьшим расстоянием между двумя любыми представителями;
· complete-link – на каждом шаге объединяет два кластера с наименьшим расстоянием между двумя наиболее удаленными представителями.

Рисунок 1.6 – Пример single-link алгоритма

Рисунок 1.7 – Пример complete-link алгоритма
1.3.2 k-Means алгоритм
Данный алгоритм состоит из следующих шагов:
1. Случайно выбрать k точек, являющихся начальными координатами «центрами масс» кластеров (любые k из n объектов, или вообще k случайных точек).
2. Отнести каждый объект к кластеру с ближайшим «центром масс».
3. Пересчитать «центры масс» кластеров согласно текущему членству.
4. Если критерий остановки не удовлетворен, вернуться к шагу 2.
В качестве критерия остановки обычно выбирают один из двух: отсутствие перехода объектов из кластера в кластер на шаге 2 или минимальное изменение среднеквадратической ошибки.
Алгоритм чувствителен к начальному выбору «центр масс».
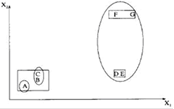
Рисунок 1.8 – Пример k-Means алгоритма
1.3.3 Минимальное покрывающее дерево
Данный метод производит иерархическую кластеризацию «сверху вниз». Сначала все объекты помещаются в один кластер, затем на каждом шаге один из кластеров разбивается на два, так чтобы расстояние между ними было максимальным.
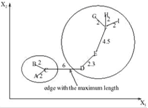
Рисунок 1.9 – Пример алгоритма минимального покрывающего дерева
1.3.4 Метод ближайшего соседа
Этот метод является одним из старейших методов кластеризации. Он был создан в 1978 году. Он прост и наименее оптимален из всех представленных.
Для каждого объекта вне кластера делаем следующее:
1. Находим его ближайшего соседа, кластер которого определен.
2. Если расстояние до этого соседа меньше порога, то относим его в тот же кластер. Иначе из рассматриваемого объекта создается еще один кластер.
Далее рассматривается результат и при необходимости увеличивается порог, например, если много кластеров из одного объекта.
0 комментариев