Навигация
Проверка статистической значимости коэффициентов регрессии
44276
знаков
10
таблиц
1
изображение
5. Проверка статистической значимости коэффициентов регрессии
Коэффициенты регрессии, рассчитанные по уравнению (7), строго говоря, определены не точно, а с некоторой погрешностью. Мерой этой погрешности является дисперсия оценок коэффициентов. Неизбежное наличие погрешности в определении коэффициентов регрессии обусловлено колебаниями значений функции отклика при дублировании экспериментов в каждом опыте. С учетом этого уравнение (7) можно записать в следующем виде: 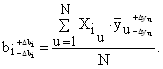 Очевидно, что при достаточно малых значениях коэффициентов bi абсолютная погрешность их определения 2×Dbi, обусловленная погрешностью определения значений функции отклика, может оказаться недопустимо большой. В этом случае значение коэффициента следует признать статистически незначимым, а сам коэффициент исключить из регрессионной модели. Статистическая незначимость коэффициента означает отсутствие его влияния на исследуемый процесс.
Очевидно, что при достаточно малых значениях коэффициентов bi абсолютная погрешность их определения 2×Dbi, обусловленная погрешностью определения значений функции отклика, может оказаться недопустимо большой. В этом случае значение коэффициента следует признать статистически незначимым, а сам коэффициент исключить из регрессионной модели. Статистическая незначимость коэффициента означает отсутствие его влияния на исследуемый процесс.
Поскольку дублирование экспериментов равномерное, дисперсию оценок коэффициентов уравнения регрессии можно рассчитать по зависимости:
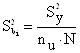 , (10)
, (10)
где nu – количество дублей в каждом опыте (nu = 3); N – количество опытов (N = 8); ![]() - средняя дисперсия эксперимента.
- средняя дисперсия эксперимента.
Если ряд дисперсий однороден, средняя дисперсия эксперимента рассчитывается по уравнению:
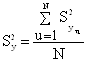 , (11)
, (11)
где ![]() - значения построчных дисперсий (табл. 4).
- значения построчных дисперсий (табл. 4).
Если ряд дисперсий неоднороден (значения функции отклика в разных опытах определены с различной точностью), но в результатах измерений значений функции отклика отсутствуют грубые ошибки и промахи, в качестве средней дисперсии эксперимента принимается максимальная построчная дисперсия. В соответствии с данными табл. 4 максимальная построчная дисперсия получена в первом опыте: ![]() . Ее значение и принимаем как среднюю дисперсию эксперимента:
. Ее значение и принимаем как среднюю дисперсию эксперимента:![]() . Тогда дисперсия оценок коэффициентов регрессии равна
. Тогда дисперсия оценок коэффициентов регрессии равна ![]()
Среднеквадратичная ошибка ![]() оценки коэффициентов регрессии определяется как:
оценки коэффициентов регрессии определяется как:
![]() . (12)
. (12)
Для рассматриваемого случая ![]()
Рассчитаем доверительный интервал коэффициентов регрессии ![]() :
:
![]() , (13)
, (13)
где ![]() - критерий Стьюдента, зависящий от уровня значимости a и числа степеней свободы f2 при определении дисперсии эксперимента:
- критерий Стьюдента, зависящий от уровня значимости a и числа степеней свободы f2 при определении дисперсии эксперимента:
![]()
Для полного факторного эксперимента 23 f2 = (3-1)×8 = 16.
Выбрав уровень значимости a = 0,05, при числе степеней свободы f2 = 16 из табл. Б1 (приложение Б) найдем табличное значение критерия Стьюдента (t-критерия) t0,05;16 = 2,12. По выражению (13) рассчитаем доверительный интервал коэффициентов регрессии: ![]()
Коэффициенты уравнения регрессии, абсолютная величина которых равна доверительному интервалу или больше его, следует признать статистически значимыми. Т.е. для статистически значимых коэффициентов должно выполняться условие:
![]() или
или ![]() . (14)
. (14)
Условие (14) означает, что абсолютные значения статистически значимых коэффициентов регрессии bi должны не менее чем в ![]() раз превышать абсолютную ошибку их определения
раз превышать абсолютную ошибку их определения ![]() .
.
Статистически значимыми коэффициентами, точность оценки которых можно считать удовлетворительной, являются коэффициенты b0, b1, b2, b12 = b4, b13 = b5, b23 = b6 и b123 = b7.
Статистически незначимые коэффициенты (b3) из модели следует исключить, поскольку их значения не могут считаться достоверными.
Подставляя значения статистически значимых коэффициентов в выражение (9), получим следующее уравнение регрессии:
![]() . (15)
. (15)
6. Проверка адекватности модели
Процедура проверки адекватности модели сводится к выполнению ряда последовательных вычислений:
1. Расчет теоретических значений функции отклика в каждом опыте по уравнению (15).
2. Сопоставление расчетных и экспериментальных значений функции отклика и нахождение дисперсии неадекватности.
3. Расчет критерия Фишера и окончательный вывод на основе сопоставления его расчетного и табличного значений об адекватности или неадекватности модели.
С помощью полученного уравнения (15) определим расчетные значения функции отклика (удельной потери массы y). Все значения Хi в данное уравнение входят в кодовом масштабе. Например, в 4-м опыте х1 = +1, х2 = +1, х3 = -1, х4 = +1, х7 = -1 (табл. 3, 5). Тогда расчетное значение удельной потери массы в этом опыте будет равно:
у(4) = 111,9-11,03+34,5-13,14-1,83-4,13-14,89= 101,38 г/см2.
Подсчитанные таким образом значения удельной потери массы приведены в табл. 6. Данные табл. 4 будем использовать для определения дисперсии неадекватности. При равномерном дублировании экспериментов дисперсия неадекватности ![]() определяется по зависимости:
определяется по зависимости:
 ;
; ![]() , (16)
, (16)
где ![]() и
и ![]() - значения функции отклика в u-м эксперименте, соответственно рассчитанные по уравнению регрессии и определенные экспериментально; f1 – число степеней свободы;
- значения функции отклика в u-м эксперименте, соответственно рассчитанные по уравнению регрессии и определенные экспериментально; f1 – число степеней свободы; ![]() - число оставленных коэффициентов уравнения регрессии, включая b0 (
- число оставленных коэффициентов уравнения регрессии, включая b0 (![]() ); N - число опытов плана (N = 8). Тогда f1 = 8 - 7 = 1.
); N - число опытов плана (N = 8). Тогда f1 = 8 - 7 = 1.
Таким образом, если из регрессионной модели исключен, хотя бы один статистически незначимый коэффициент (а это неизбежно, если варьируемые факторы действительно являются независимыми переменными), массив разностей ![]() будет содержать информацию об ошибках в предсказании значений функции отклика.
будет содержать информацию об ошибках в предсказании значений функции отклика.
Таблица 6
Сопоставление экспериментальных и расчетных данных
| Номер эксперимента, u |
|
|
|
|
| 1 | 97,3 | 66,36 | 30,94 | 957,3 |
| 2 | 127,6 | 96,7 | 30,9 | 954,8 |
| 3 | 153,7 | 183,16 | -29,46 | 867,9 |
| 4 | 71,9 | 101,38 | -29,48 | 869,1 |
| 5 | 113,7 | 84,22 | 29,48 | 869,1 |
| 6 | 91,8 | 62,32 | 29,48 | 869,1 |
| 7 | 127,1 | 157,98 | -30,88 | 953,6 |
| 8 | 112,2 | 143,08 | -30,88 | 953,6 |
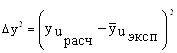
В рассматриваемом случае построенная модель (15) включает шесть коэффициентов: ![]() . Тогда в соответствии с выражением (16)
. Тогда в соответствии с выражением (16) ![]() .
.
Гипотеза об адекватности модели (15) проверяется по критерию Фишера. Его расчетное значение находим по уравнению:
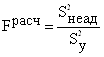 . (17)
. (17)
![]() .
.
Из выражения (17) следует, что расчетное значение критерия Фишера представляет собой отношение дисперсии неадекватности к дисперсии опыта. По сути дела он позволяет ответить на вопрос: во сколько раз модель предсказывает значения функции отклика хуже по сравнению с опытом? Тогда табличное значение критерия Фишера должно регламентировать допустимое отклонение расчетных значений функции отклика относительно опытных данных.
Табличное значение критерия Фишера определяется в зависимости от уровня значимости a и числа степеней свободы f1 и f2, определенных ранее: F(a; f1; f2). При уровне значимости a = 0,05 табличное значение F - критерия (табл. В1, приложение В) равно ![]() .
.
Похожие работы
вание отсеивающего эксперимента, основное значение которого выделение из всей совокупности факторов группы существенных факторов, подлежащих дальнейшему детальному изучению; планирование эксперимента для дисперсионного анализа, т.е. составление планов для объектов с качественными факторами; планирование регрессионного эксперимента, позволяющего получать регрессионные модели (полиномиальные и ...
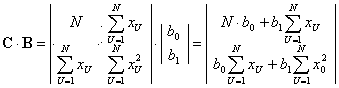
... qвос = 0,05 (в данном случае Gкр=0,3894), то гипотеза об однородности выборочных дисперсий отвечает результатам наблюдений. В данном случае воспроизводимость эксперимента выполняется. 2.4 Построение диаграммы рассеяния Вид диаграммы рассеяния приведен на рисунке 1. Рисунок 1 Рассчитанные значения вкладов и количество выделяющихся точек для соответствующих факторов приведены в ...


... планирование отсеивающего эксперимента, основное значение которого выделение из всей совокупности факторов группы существенных факторов, подлежащих дальнейшему детальному изучению; · планирование эксперимента для дисперсионного анализа, т.е. составление планов для объектов с качественными факторами; · планирование регрессионного эксперимента, позволяющего получать ...

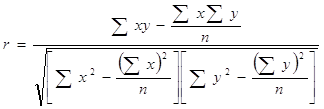
... ŷ = a0 + a1x , где ŷ - теоретические значения результативного признака, полученные по уравнению регрессии; a0 , a1 - коэффициенты (параметры) уравнения регрессии. Задача регрессионного анализа состоит в построении модели, позволяющей по значениям независимых показателей получать оценки значений зависимой переменной. Регрессионный анализ является основным средством исследования ...
0 комментариев