Навигация
Аддитивная модель Фри – Вильсона
163457
знаков
23
таблицы
38
изображений
1.1.5 Аддитивная модель Фри – Вильсона
В аддитивной модели предполагается, что биологический отклик соединения может быть представлен как сумма активностей заместителей плюс некая общая средняя активность.
Эта модель основана на предположении о том, что вклад данного заместителя, находящегося в структуре в данном положении, всегда одинаков независимо от того, в каком соединении присутствует рассматриваемый заместитель. Величины вкладов заместителей рассчитываются с помощью множественного линейного регрессионного анализа. Для построения линии регрессии необходима только информация о молекулярной структуре и биологической активности соединений, никакие физико-химические параметры не используются.
При анализе данных методом Фри - Вильсона для каждого соединения составляется линейное уравнение, а параметры рассчитываются методом наименьших квадратов. Здесь применяются те же статистические критерии, что и при анализе методом Ханша. Если рассчитанные статистические критерии являются удовлетворительными и тем самым обоснована применимость аддитивной схемы, то с помощью полученных таким образом параметров линейного соотношения можно восстановить величины биологической активности соединений, составляющих исходную выборку. При этом отдельные сильные отклонения от линейной зависимости могут быть сразу же идентифицированы. И наконец, наиболее важный результат состоит в том, что с помощью рассчитанных значений параметров можно предсказать активность соединений, образованных путем всевозможных сочетаний и перестановок исходных заместителей. Относительные вклады в биологическую активность различных заместителей, расположенных в соединении в различных положениях, могут быть упорядочены
Главный недостаток метода Фри — Вильсона заключается в том, что для описания всех заместителей требуется очень большое число переменных. К тому же иногда приходится иметь дело с вырожденными матрицами. Таким образом, при использовании метода Фри — Вильсона исследователю приходится выбирать одну из двух возможностей: либо испытывать большое количество производных, либо ограничивать количество заместителей и их положений в структуре. Результат выбора, очевидно, определяется спецификой конкретной задачи.
1.1.6 Метод Хюккеля, расширенный метод ХюккеляИсторически метод, предложенный Эрихом Хюккелем в 1931 г., являлся первым полуэмпирическим квантово - химическим методом. В настоящее время он используется лишь для качественного объяснения свойств главным образом π - сопряженных молекул. Для количественных расчетов используется вариант данного метода, введенный в практику в 1961 г. Р. Хоффманом и получивший название расширенного метода Хюккеля. Он является простейшим, наиболее быстрым и вместе с тем наименее точным полуэмпирическим квантово-химическим методом. Его использование ограничивается в основном анализом структуры молекулярных орбиталей — определением их формы и последовательности.
Электрон - электронное взаимодействие в этом методе в явном виде не учитывается, диагональные элементы матрицы Н аппроксимируются потенциалами ионизации, взятыми с обратным знаком, а для недиагональных членов используется одно из приближений.
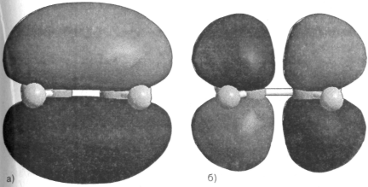
Рисунок 1.7.1. Вид молекулярных орбиталей HOMO (а) и LUMО (б) молекулы этилена, рассчитанных расширенным методом Хюккеля в программе HyperChem 7.0.
Подобный подход хорошо работает при расчете систем с относительно равномерным распределением заряда, например углеводородов, для которых он и был первоначально использован. Однако даже и в таких случаях бывают казусы. Например, в соответствии с предсказанием расчета, бензол должен распадаться на три молекулы ацетилена с выделением значительного количества теплоты. Что касается систем, содержащих гетероатомы, то для них более адекватным является интегративный расширенный метод Хюккеля. В этом методе уже учитывается зависимость гамильтониана от заряда на данном центре, причем зависимость полагается линейной.
1.2 Современные методы анализа «структура вещества – проявляемая физиологическая активность» 1.2.1 Принципы распознавания образов
Одна из основных предпосылок методов конструирования лекарств — предположение о том, что соединения сходной структуры имеют сходные типы биологической активности. Очень трудно дать строгое определение понятия структурного сходства, о чем свидетельствует обилие и разнообразие параметров, используемых при выводе эмпирических соотношений, связывающих структуру соединений с их биологической активностью. До сих пор наиболее распространенным методом чтения координат и методом построения таких соотношений был регрессионный анализ. Целью этого подхода является построение эмпирических соотношений, связывающих различные сочетания физических, химических или структурных параметров с биологической реакцией соединения. Этот метод особенно эффективен при исследовании не слишком длинных гомологических рядов соединений.
Методам распознавания образов посвящено множество монографий [16]. Этот факт, несомненно, является отражением широкой применимости методов распознавания. Применение методов распознавания образов к химическим задачам началось в середине 1960-х годов в связи с масс-спектральными исследованиями. После этого аналогичные работы стали проводиться во многих других областях химии.
Одна из интересных особенностей этих методов заключается в том, что они могут иметь дело с многомерными данными, т. е. данными, в которых для представления каждого объекта используется более трех параметров. К тому же этими методами можно анализировать данные, полученные из разных источников, а также данные, связи между которыми имеют разрывный характер. При соответствующем подходе методы распознавания образов дают возможность установить критерий отбора из исходного множества данных тех параметров, которые существенны для описания исследуемых свойств. Далее с помощью этого набора наиболее значимых признаков могут быть получены указания о направлении дальнейших исследований.
1.2.2 Основные понятия методов распознавания образовПрежде чем начать обсуждение методов распознавания образов, необходимо объяснить, что подразумевается под классификацией объекта или группы объектов. В процессе классификации формируется правило разделения группы объектов на несколько категорий, а при распознавании это классификационное правило используется для отнесения неизвестного объекта к одной из рассматриваемых категорий. Классификационное правило устанавливается в виде некоторой гипотезы, полученной в результате анализа экспериментальных данных. Проверка правильности этой гипотезы проводится путем ее испытания на объектах, не включенных в группу данных, с помощью которых было получено классификационное правило. В случае удачных испытаний гипотеза считается правильной. Процесс классификации заключается не только в выработке классификационного правила и его дальнейшего применения для распознавания. Ниже на простом примере будут продемонстрированы основные особенности задачи распознавания образов.
В качестве примера построения классификационного правила рассмотрим следующую воображаемую задачу. Предположим, что мы хотим автоматизировать процесс идентификации аномальных клеток при анализе крови в клинической лаборатории. Попробуем составить опытный проект оптической воспринимающей системы, способной отличить лейкимические клетки от здоровых на основе оптической проницаемости (рис. 2.1.1). Будем считать, что если прозрачность клетки превосходит некоторый уровень Хо, то она относится к лейкемическим клеткам.
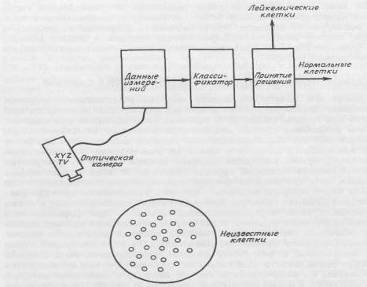
Рисунок 2.1.1 Схема оптической системы распознавания образов
Поскольку надежность такой классификации слишком низка, необходимо искать дополнительные признаки, которые могли бы оказаться полезными при различении разных типов клеток. Предположим, что лейкимические клетки имеют более ярко выраженную клеточную структуру, чем нормальные. В этом случае можно настроить камеру на измерение контрастности образцов и таким образом получить характеристику структурированности для каждой клетки эталонного набора образцов. В результате получим двумерную диаграмму, показанную на рис. 2.1.2
Цель методов отбора признаков — добиться наибольшего эффекта наименьшим числом признаков. Сокращение количества необходимых признаков облегчает процедуру классификации и в некоторых случаях увеличивает надежность результатов.
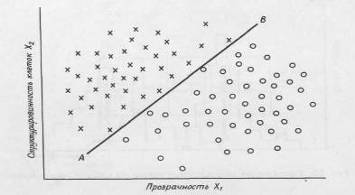
Рисунок 2.1.2 Разделение образов клеток на два класса в пространстве двух признаков — структурированности и прозрачности клеток.
Вся процедура распознавания образов складывается из трех последовательных операций: измерения, предварительной обработки и классификации. В результате применения этих операций последовательно формируются пространство измерений, пространство признаков и классификационное правило. Разделение всей процедуры распознавания образов на три стадии является несколько условным, поскольку приемы, используемые в одной из стадий, часто с успехом могут применяться и на других этапах обработки.
Предварительная обработка
С помощью методов предварительной обработки проводится преобразование исходных данных. К методам предварительной обработки относятся: масштабирование, нормализация, преобразования кластеризации, отбор признаков, многомерный скейлинг и нелинейное отображение.
Масштабирование и нормализация
Для преобразования данных, полученных разными датчиками, к виду, удобному для обработки, необходимо выбрать масштаб и выполнить нормализацию. Эти преобразования особенно важны, когда данные получены из разных источников. В этом случае они могут отличаться на несколько порядков величины, так что большие по величине дескрипторы будут подавлять малые. Этот недостаток может быть устранен путем автоматического выбора масштаба [17].
После преобразования масштаба желательно таким образом преобразовать данные, чтобы измерения, дающие больший вклад в кластеризацию, имели соответственно большие веса. Одним из простейших методов такого преобразования является метод дисперсионного взвешивания.
Хотя процедуры типа масштабирования могут уменьшить эффект разнородности исходных данных, а в методе дисперсионного взвешивания признаки получают веса, соответствующие их вкладу в кластеризацию, обе эти операции изменяют исходные данные одинаково.
Одним из недостатков методов предварительной обработки данных является то, что они учитывают все признаки, в том числе и те, которые могут не иметь отношения к рассматриваемой классификационной задаче. В результате возможно попадание в весьма неблагоприятную ситуацию, особенно в том случае, если несущественные признаки будут увеличивать ошибку процедуры классификации, не говоря уже о сложности и стоимости этих преобразований. Поскольку не все признаки существенны для решения рассматриваемой задачи, необходимо найти метод уменьшения их количества. Такой метод называется отбором признаков.
В результате выполнения этих преобразований мы переходим в новое пространство, в котором интересующий нас класс имеет минимальное внутриклассовое расстояние, а дисперсионная матрица выборки данных диагональная. Признаки, имеющие наименьшие значения дисперсии (диагональные элементы дисперсионной матрицы), считаются наиболее существенными для кластеризации. «Оптимальное» подмножество данных формируется из n признаков, имеющих наименьшие значения дисперсии.
Существуют еще несколько методов отбора наиболее информативных признаков. Такие критерии, как дивергенция помогают выделить наиболее существенные дескрипторы. Некоторые из этих методов основаны на гипотезе о виде распределения данных. Если такая гипотеза ошибочна, то результаты статистического анализа могут оказаться ненадежными. Еще одно затруднение заключается в том, что для выбора наилучшего набора дескрипторов должны быть проверены все возможные комбинации исходного набора дескрипторов. Такая проверка практически трудноосуществима в случае наборов признаков, объем которых n превышает 20, поскольку число вычислительных итераций возрастает как n!. Это приводит к дальнейшему снижению ценности рассматриваемых процедур. Требуются такие методы отбора признаков, которые, с одной стороны, были бы близки к оптимальным, а, с другой, не были бы сопряжены с большими объемами вычислений.
Часто необходимые сведения могут быть получены с помощью значительно более простых методов. Одним из таких методов является оценка прогнозирующей способности отдельных признаков. Прогнозирующие способности отдельных признаков могут быть рассчитаны с помощью следующего алгоритма:
1. Значения дескрипторов упорядочиваются по возрастанию.
2. Начиная с наименьшего значения, отмечают количество элементов на класс, превышающее и не достигающее этого значения.
3. Выбирают следующее по величине значение дескриптора и повторяют расчеты до тех пор, пока не будут перебраны все значения данного дескриптора.
4. Отмечают наибольший процент правильных предсказаний для всей выборки и для каждого класса.
При отборе отдельных признаков полезно сопоставить значения различных статистических характеристик системы. Так, для каждого класса без труда могут быть рассчитаны выборочное среднее, стандартное отклонение, наибольшее значение, наименьшее значение и общее количество отличных от нуля значений. Таким образом, можно составить представление об информативности анализируемых данных, а также решить вопрос о том, оправдано ли включение в систему данного дескриптора.
Еще одним полезным критерием является коэффициент корреляции. Сильно коррелированные дескрипторы могут содержать в сущности одну и ту же информацию. Если несколько дескрипторов сильно коррелированны, то можно оставить какой-либо один из них при условии, что после такого отбора общее количество информации не изменится.
Многомерный скейлинг и нелинейное отображение
Очень часто рассматриваемое преобразование приводит к тому, что множества векторов-образов, не пересекавшиеся в исходном пространстве, начинают пересекаться в пространстве меньшей размерности. Этот недостаток вызывает затруднения при объяснении структуры данных. Его можно преодолеть с помощью других, нелинейных методов понижения размерности.
К ним относятся методы нелинейного отображения и многомерного скейлинга. Основная идея заключается в отыскании такой проекции в дву- или трехмерном пространстве, которая походила бы на исходное изображение. Можно использовать различные критерии сходства, однако чаще всего для этой цели используют расстояние. Обычно расстояние измеряют в евклидовой метрике, но в случае необходимости можно применить и другие метрики. Ошибка такого преобразования будет измеряться разностью расстояний в новом и старом представлениях.
Удобно описывать разность между новым и старым расстояниями с помощью такой функции критерия, которая была бы инвариантной по отношению к искажениям конфигурационных многогранников, а также к растяжениям векторов.
Помимо всего прочего многомерный скейлинг дает удобный метод визуального представления структуры данных. Это часто помогает подобрать наиболее подходящий к данному случаю метод классификации. Сфера применения методов скейлинга не ограничивается только предварительной обработкой. Если при нелинейном отображении не возникает существенных искажений исходных данных, классификация может быть проведена самим исследователем путем визуального анализа отображений на пространство низкой размерности.
Классификация
Представление о кластеризации объектов в пространстве информативных измерений является центральным в приложениях методов распознавания образов. Нахождение такого преобразования, с помощью которого можно кластеризовать исследуемую выборку и в результате получить классы объектов, обладающих заданным свойством, является общей целью процедур измерения, предварительной обработки и априорного отбора признаков. По существу, распознавание образов является методом выявления сходства между исследуемыми объектами. В результате классификации отыскиваются некоторые соотношения, характеризующие это сходство. Существует много различных методов классификации, однако в фармакологических приложениях преимущественно используются непараметрические методы. Для понимания основ непараметрических методов необходимо небольшое введение в теорию параметрических методов.
Параметрические методы классификации основаны на байесовской статистике. Эти методы формируют классификационное правило непосредственно из вероятностного распределения данных. Вид вероятностного распределения данных зависит от типа и числа датчиков, методов предварительной обработки и отбора признаков. Цель классификации заключается в максимальном увеличении доли правильных классификаций путем построения функции, определяющей границы между различными классами.
Классификатор может быть построен непосредственно из формулы Байеса
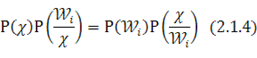
В этом соотношении X - вектор-образ, компоненты которого получены в результате работы различных датчиков. Численные значения этих компонент определяют распределение данных в N-мерном пространстве. Функция Р (Х) описывает распределение данных независимо от того, к какому классу они принадлежат. Р (![]() ) — вероятность наблюдения класса Wi. Р(W/X) - условная вероятность того, что вектор X принадлежит классу Wi. P(X/Wi) — условная вероятность того, что из класса Wi будет выбран объект, описываемый вектором-образом X.
) — вероятность наблюдения класса Wi. Р(W/X) - условная вероятность того, что вектор X принадлежит классу Wi. P(X/Wi) — условная вероятность того, что из класса Wi будет выбран объект, описываемый вектором-образом X.
Понятие о кластеризации - одно из наиболее привлекательных в классификационной задаче. Этот подход естественным образом возникает из геометрической интерпретации задачи. Смысл метода кластеризации ясен из приведенного выше примера, в котором мы искали границу, отделяющую кластер нормальных клеток от кластера аномальных клеток. Поскольку в этой задаче мы имели дело с системой низкой размерности, то достаточно было ограничиться визуальными методами построения разделяющей поверхности. Следовательно, необходимо разработать систематический подход, позволяющий дать более строгое определение кластера.
Есть несколько алгоритмов разделения множества исходных данных на кластеры. В большинстве из этих алгоритмов при выполнении кластеризации в качестве меры близости объектов используются различные способы определения расстояний. Использование расстояния в качестве меры близости является естественным, если учесть, что исследуемые объекты изображаются точками в евклидовом пространстве. Однако критерии, основанные на том или ином способе определения расстояния, являются только одним из возможных способов определения кластеров. Хартиган [18] указал шесть типов алгоритмов кластеризации, отличающихся друг от друга способами выделения кластеров.
1.Сортировка
Объекты разделяются на кластеры в соответствии со значениями, которые принимает какой-либо существенный признак, характеризующий объекты. Затем внутри выделенных таким образом кластеров проводится дальнейшая сортировка путем анализа значений другого признака и т. д.
2.Перегруппировка
Задается некоторое начальное распределение объектов по кластерам. Далее объекты перемещают из одного кластера в другой в соответствии с каким-либо критерием, например величиной стандартного отклонения для данного кластера. Алгоритмы перегруппировки отличаются высокой скоростью, однако конечный результат иногда зависит от вида начального распределения.
3. Объединение
Сначала каждый объект исходной выборки данных выделяется в отдельный кластер. Далее отыскивается пара кластеров с наименьшим межкластерным расстоянием и объединяется в один кластер большего размера. Этот процесс продолжают до тех пор, пока не будет выполняться некоторое условие оптимальности или все объекты не окажутся в одном кластере. Для больших выборок, включающих более 1000 элементов, этот алгоритм неэкономичен, и определение оптимальных условий требует привлечения некоторых аппроксимаций.
4. Разбиение
Алгоритмы разбиения полностью противоположны алгоритмам объединения. В этих алгоритмах исходная выборка данных последовательно разбивается на все более мелкие кластеры в соответствии с некоторыми правилами (минимальный или максимальный размер, стандартное отклонение и т. д.). Трудности, возникающие при реализации этих алгоритмов, обычно связаны с выбором формы функций разбиения.
0 комментариев