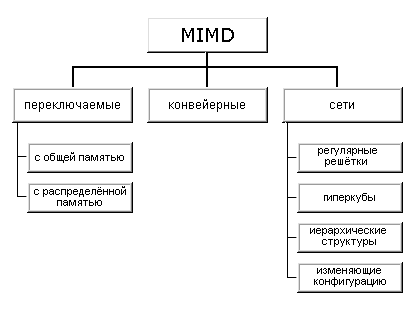
Классификация параллельных ВС
Конвейеры операций
Конфликты в конвейере и способы минимизации их влияния на производительность процессора
Суперскалярные архитектуры
Трудности реализации
VLIW-архитектура
Принцип действия VLIW-компилятора
Предсказание переходов
Матричные процессоры
Многопоточность в Pentium 4
Закон Амдала
Навигация
Многопоточность в Pentium 4
Принципы организации параллелизма выполнения машинных команд в процессорах
102663
знака
6
таблиц
1
изображение
6.4 Многопоточность в Pentium 4
Разобравшись с теорией многопоточности, рассмотрим практический пример - Pentium 4. Уже на этапе разработки этого процессора инженеры Intel продолжали работу над повышением его быстродействия без внесения изменений в программный интерфейс. Рассматривалось пять простейших способов:
- повышение тактовой частоты;
- размещение на одной микросхеме двух процессоров;
- введение новых функциональных блоков;
- удлинение конвейера;
- использование многопоточности.
Самый очевидный способ повышения быстродействия заключается в том, чтобы повысить тактовую частоту, не меняя другие параметры. Как правило, каждая последующая модель процессора имеет несколько более высокую тактовую частоту, чем предыдущая. К сожалению, при прямолинейном повышении тактовой частоты разработчики сталкиваются с двумя проблемами: увеличением энергопотребления (что актуально для портативных компьютеров и других вычислительных устройств, работающих на аккумуляторах) и перегревом (что требует создания более эффективных теплоотводов).
Второй способ - размещение на микросхеме двух процессоров - сравнительно прост, но он сопряжен с удвоением площади, занимаемой микросхемой. Если каждый процессор снабжается собственной кэш-памятью, количество микросхем на пластине уменьшается вдвое, но это также означает удвоение затрат на производство. Если для обоих процессоров предусматривается общая кэш-память, значительного увеличения занимаемой площади удается избежать, однако в этом случае возникает другая проблема - объем кэш-памяти в пересчете на каждый процессор уменьшается вдвое, а это неизбежно сказывается на производительности. Кроме того, если профессиональные серверные приложения способны полностью задействовать ресурсы нескольких процессоров, то в обычных настольных программах внутренний параллелизм развит в значительно меньшей степени.
Введение новых функциональных блоков также не представляет сложности, но здесь важно соблюсти баланс. Какой смысл в десятке блоков АЛУ, если микросхема не может выдавать команды на конвейер с такой скоростью, которая позволяет загрузить все эти блоки?
Конвейер с увеличенным числом ступеней, способный разделять задачи на более мелкие сегменты и обрабатывать их за короткие периоды времени, с одной стороны, повышает производительность, с другой, усиливает негативные последствия неверного прогнозирования переходов, кэш-промахов, прерываний и других событий, нарушающих нормальный ход обработки команд в процессоре. Кроме того, чтобы полностью реализовать возможности расширенного конвейера, необходимо повысить тактовую частоту, а это, как мы знаем, приводит к повышенным энергопотреблению и теплоотдаче.
Наконец, можно реализовать многопоточность. Преимущество этой технологии состоит во введении дополнительного программного потока, позволяющего ввести в действие те аппаратные ресурсы, которые в противном случае простаивали бы. По результатам экспериментальных исследований разработчики Intel выяснили, что увеличение площади микросхемы на 5 % при реализации многопоточности для многих приложений дает прирост производительности на 25 %. Первым процессором Intel с поддержкой многопоточности стал Хеоn 2002 года. Впоследствии, начиная с частоты 3,06 ГГц, многопоточность была внедрена в линейку Pentium 4. Intel называет реализацию многопоточности в Pentium 4 гиперпоточностью (hyperthreading).
7 Закон Амдала. Закон Густафсона
7.1 Ускорение, эффективность, загрузка и качество
Параллелизм достигается за счет того, что в составе вычислительной системы отдельные устройства присутствуют в нескольких копиях. Так, в состав процессора может входить несколько АЛУ, и высокая производительность обеспечивается за счет одновременной работы всех этих АЛУ. Второй подход был описан ранее.
Рассмотрим параллельное выполнение программы со следующими характеристиками:
О(n) — общее число операций (команд), выполненных на n-процессорной системе;
Т(n) — время выполнения О(n) операций на n-процессорной системе в виде числа квантов времени.
В общем случае Т(n) < О(n), если в единицу времени n процессорами выполняется более чем одна команда, где n > 2. Примем, что в однопроцессорной системе T(1)= О(1).
Ускорение (speedup), или точнее, среднее ускорение за счет параллельного выполнения программы — это отношение времени, требуемого для выполнения наилучшего из последовательных алгоритмов на одном процессоре, и времени параллельного вычисления на n процессорах. Без учета коммуникационных издержек ускорение S(n) определяется как
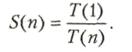
Как правило, ускорение удовлетворяет условию S(n) ![]() n. Эффективность (efficiency) n-процессорной системы — это ускорение на один процессор, определяемое выражением
n. Эффективность (efficiency) n-процессорной системы — это ускорение на один процессор, определяемое выражением
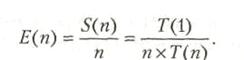
Эффективность обычно отвечает условию 1/n ![]() Е(n)
Е(n) ![]() n. Для более реалистичного описания производительности параллельных вычислений необходимо промоделировать ситуацию, когда параллельный алгоритм может потребовать больше операций, чем его последовательный аналог.
n. Для более реалистичного описания производительности параллельных вычислений необходимо промоделировать ситуацию, когда параллельный алгоритм может потребовать больше операций, чем его последовательный аналог.
Довольно часто организация вычислений на n процессорах связана с существенными издержками. Поэтому имеет смысл ввести понятие избыточности (redundancy) в виде
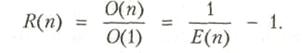
Это отношение отражает степень соответствия между программным и аппаратным параллелизмом. Очевидно, что 1 ![]() R(n)
R(n) ![]() n.
n.
Определим еще одно понятие, коэффициент полезного использования или утилизации (utilization), как
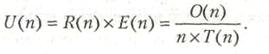
Тогда можно утверждать, что
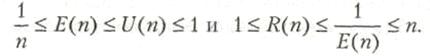
Рассмотрим пример. Пусть наилучший из известных последовательных алгоритмов занимает 8 с, а параллельный алгоритм занимает на пяти процессорах 2 с. Тогда:
S(n) = 8/2 = 4;
Е(n) = 4/5 = 0,8;
R(n) = 1/0,8 - 1 = 0,25.
Собственное ускорение определяется путем реализации параллельного алгоритма на одном процессоре.
Если ускорение, достигнутое на n процессорах, равно n, то говорят, что алгоритм показывает линейное ускорение.
В исключительных ситуациях ускорение S(n) может быть больше, чем n. В этих случаях иногда применяют термин суперлинейное ускорение. Данное явление имеет шансы на возникновение в двух следующих случаях:
Последовательная программа может выполняться в очень маленькой памяти, вызывая свопинги (подкачки), или, что менее очевидно, может приводить к большему числу кэш-промахов, чем параллельная версия, где обычно каждая параллельная часть кода выполняется с использованием много меньшего набра данных.
Другая причина повышенного ускорения иллюстрируется примером. Пусть нам нужно выполнить логическую операцию A1 v A2, где как A1 так и А2 имеют значение «Истина» с вероятностью 50%, причем среднее время вычисления Ai, обозначенное как T(Ai), существенно различается в зависимости от того, является ли результат истинным или ложным.
Пусть
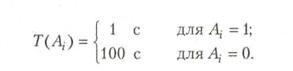
Теперь получаем четыре равновероятных случая (Т — «истина», F — «ложь»):

Таким образом, параллельные вычисления на двух процессорах ведут к среднему ускорению:
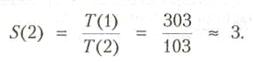
Отметим, что суперлинейное ускорение вызвано жесткостью последовательной обработки, так как после вычисления еще нужно проверить А2. К факторам, ограничивающим ускорение, следует отнести:
- Программные издержки. Даже если последовательные и параллельные алгоритмы выполняют одни и те же вычисления, параллельным алгоритмам присущи добавочные программные издержки — дополнительные индексные вычисления, неизбежно возникающие из-за декомпозиции данных и распределения их по процессорам; различные виды учетных операций, требуемые в параллельных алгоритмах, но отсутствующие в алгоритмах последовательных.
- Издержки из-за дисбаланса загрузки процессоров. Между точками синхронизации каждый из процессоров должен быть загружен одинаковым объемом работы, иначе часть процессоров будет ожидать, пока остальные завершат свои операции. Эта ситуация известна как дисбаланс загрузки. Таким образом, ускорение ограничивается наиболее медленным из процессоров.
- Коммуникационные издержки. Если принять, что обмен информацией и вычисления могут перекрываться, то любые коммуникации между процессорами снижают ускорение. В плане коммуникационных затрат важен уровень гранулярности, определяющий объем вычислительной работы, выполняемой между коммуникационными фазами алгоритма. Для уменьшения коммуникационных издержек выгоднее, чтобы вычислительные гранулы были достаточно крупными, и доля коммуникаций была меньше.
Еще одним показателем параллельных вычислений служит качество параллельного выполнения программ — характеристика, объединяющая ускорение, эффективность и избыточность. Качество определяется следующим образом:
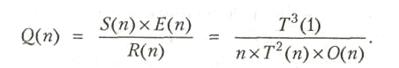
Поскольку как эффективность, так и величина, обратная избыточности, представляют собой дроби, то Q(n) ![]() S(n). Поскольку Е(n) — это всегда дробь, a R(n) -число между 1 и n, качество Q(n) при любых условиях ограничено сверху величиной ускорения S(n) [4].
S(n). Поскольку Е(n) — это всегда дробь, a R(n) -число между 1 и n, качество Q(n) при любых условиях ограничено сверху величиной ускорения S(n) [4].
Похожие работы
... практичных алгоритмов оптимизированного перебора, позволяющих за разумное время осуществлять распараллеливание достаточно больших участков. Анализ работ, посвященных оптимизации кода для процессоров с параллелизмом на уровне команд показывает, что для достижения наилучших результатов необходимо применение комплекса оптимизаций, среди которых можно выделить следующие классы. Преобразования циклов ...
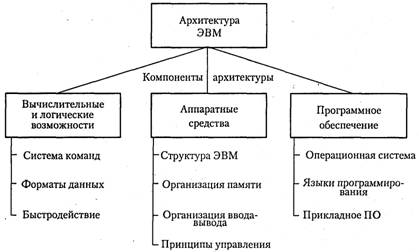
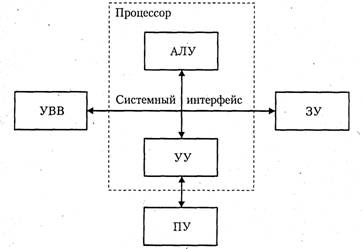
... выдвинулась концепция их взаимодействия. Так возникло принципиально новое понятие — архитектура ЭВМ. программирование вычислительный техника Под архитектурой ЭВМ понимается совокупность общих принципов организации аппаратно-программных средств и их характеристик, определяющая функциональные возможности ЭВМ при решении соответствующих классов задач. Архитектура ЭВМ охватывает широкий круг проблем ...
... сделал в машине М20,где были реализованы возможности написания программ в мнемокодах. И это значительно расширило круг специалистов, которые смогли воспользоваться преимуществами вычислительной техники. Машины второго поколения. БЭСМ-6 В 1948 году американскими учеными был создан полупроводниковый транзистор, который стал использоваться в качестве элементной базы ЭВМ. Это изобретение позволило ...
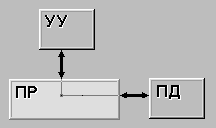
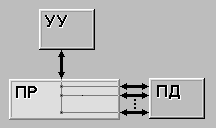
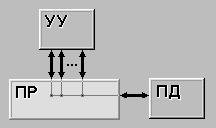
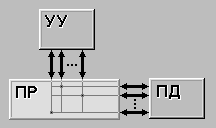
... во всех современных компьютерах это число совпадает с длиной машинного слова. Вторая характеристика равна числу слов m, обрабатываемых одновременно данной вычислительной системой. Немного изменив терминологию, функционирование любого компьютера можно представить как параллельную обработку n битовых слоев, на каждом из которых независимо преобразуются m бит. Опираясь на такую интерпретацию, вторую ...
0 комментариев