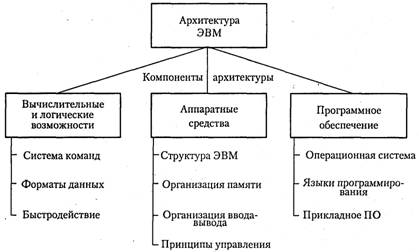
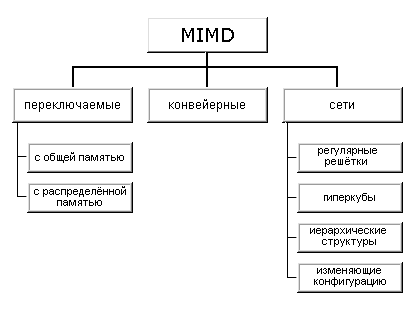
Классификация параллельных ВС
Конвейеры операций
Конфликты в конвейере и способы минимизации их влияния на производительность процессора
Суперскалярные архитектуры
Трудности реализации
VLIW-архитектура
Принцип действия VLIW-компилятора
Предсказание переходов
Матричные процессоры
Многопоточность в Pentium 4
Закон Амдала
Навигация
Принцип действия VLIW-компилятора
Принципы организации параллелизма выполнения машинных команд в процессорах
102663
знака
6
таблиц
1
изображение
4.3 Принцип действия VLIW-компилятора
Вновь вспыхнувший в последнее время интерес к VLIW, как к архитектуре, которую можно использовать для реализации вычислений общего назначения, дал существенный толчок развитию техники компиляции для VLIW. VLIW-компилятор упаковывает группы независимых операций в очень длинные слова инструкций таким способом, чтобы обеспечить эффективное их исполнение функциональными модулями за один машинный такт. Компилятор сначала обнаруживает все зависимости между данными, а затем определяет, как их развязать. Чаще всего это делается путем переупорядочивания всей программы, разные ее блоки перемещаются с одного места в другое. Этот подход отличается от применяемого в суперскалярном процессоре, который для определения зависимостей использует специальное аппаратное решение прямо во время выполнения программы (оптимизирующие компиляторы, безусловно, улучшают работу суперскалярного процессора, но не делают его "привязанным" к ним). Большинство суперскалярных процессоров может обнаружить зависимости и планировать параллельное исполнение только внутри базовых программных блоков (группа последовательных операторов программы, не содержащих внутри себя останова или логического ветвления, допустимых только в конце).
Для обеспечения большего параллелизма VLIW-компьютеры должны наблюдать за операциями из разных базовых блоков, чтобы поместить эти операции в одну и ту же длинную инструкцию, их "область обзора" должна быть шире, чем у суперскалярных процессоров. Это обеспечивается путем прокладки "маршрута" по всей программе (трассировка). Трассировка - наиболее оптимальный для некоторого набора исходных данных маршрут по программе для обеспечения правильного результата, гарантирует непересечение этих данных. То есть маршрут, который "проходит" по участкам, пригодным для параллельного выполнения (эти участки формируются, кроме всего прочего, и путем переноса кода из других мест программы), после чего остается упаковать эти участки в длинные инструкции и передать на выполнение. Планировщик вычислений осуществляет оптимизацию на уровне всей программы, а не ее отдельных базовых блоков. Для VLIW, так же, как и для RISC, ветвления в программе являются "врагом", препятствующим эффективному ее выполнению: типичный программный код (тот, что не используется в научных расчетах) содержит около шести ветвлений на инструкцию. В то время как RISC для прогнозирования ветвлений использует аппаратное решение, VLIW оставляет это за компилятором. Компилятор использует информацию, собранную им путем профилирования программы, хотя у будущих VLIW-процессоров предполагается небольшое аппаратное расширение, обеспечивающее сбор для компилятора статистической информации непосредственно во время выполнения программы. Компилятор прогнозирует наиболее подходящий маршрут и планирует его прохождение, рассматривая его как один большой базовый блок, а затем повторяет этот процесс для всех других возникших после этого программных веток, и так до самого конца программы. Он также умеет делать при анализе кода и другие "умные шаги", такие, как развертывание программного цикла и IF-преобразование, в процессе которого временно удаляются все логические переходы из секции, подвергающейся трассировке. Там, где RISC может только просмотреть код вперед на предмет ветвлений, VLIW-компилятор перемещает его с одного места в другое до обнаруженного ветвления (согласно трассировке), но предусматривает при необходимости возможность отката назад, к предыдущему программному состоянию. Соответствующее аппаратное обеспечение, добавленное к VLIW-процессору, может оказать определенную поддержку компилятору. Например, операции, имеющие по несколько ветвлений, могут входить в одну длинную инструкцию и, следовательно, выполняться за один машинный такт. Поэтому выполнение условных операций, которые зависят от результатов предыдущих, может быть реализовано программным способом, а не аппаратным. Цена, которую приходится платить за увеличение быстродействия VLIW-процессора, намного меньше стоимости компиляции. Именно поэтому основные расходы приходятся на компиляторы.
4.4 Трудности реализации VLIW
При реализации архитектуры VLIW возникают и другие серьезные проблемы: VLIW-компилятор должен в деталях "знать" внутренние особенности архитектуры процессора, опускаясь до внутреннего устройства самих функциональных модулей. Как следствие, при выпуске новой версии VLIW-процессора с большим количеством обрабатывающих модулей (или даже с тем же количеством, но другим быстродействием) все старое программное обеспечение, скорее всего, потребует полной перекомпиляции. Надо ли было при переходе, скажем, на процессор 486 избавляться от имеющегося ПО для процессора 386? Конечно, нет, а вот при переходе от одного VLIW-процессора к другому придется, и это разработчик должен учесть при планировании своих затрат - потребуются дополнительные средства на перекомпиляцию. Сторонники VLIW-архитектуры в оправдание предлагают разделить процесс компиляции на две стадии. Все программное обеспечение должно готовиться в аппаратно-независимом формате с использованием промежуточного кода, который окончательно транслируется в машинно-зависимый код только после установки на машине пользователя. Пример такого подхода демонстрирует фонд OSF со своим стандартом ANDF (Architecture-Neutral Distribution Format). Но кросс-платформенное программное обеспечение пока еще только желаемое, а в действительности разработчики ПО для ПК зачастую весьма инертны по отношению к принятию радикально новых технологий. Другая трудность - это по своей сути статическая природа оптимизации, которую обеспечивает VLIW-компилятор. Как поведет себя программа, когда столкнется во время компиляции с непредусмотренными динамическими ситуациями, такими как, например, ожидание ввода-вывода? Архитектура VLIW возникла в ответ на требования со стороны научно-технических организаций, где при вычислениях особенно необходимо большое быстродействие процессора, но для объектно-ориентированных и управляемых по событиям программ она менее подходит, а ведь именно такие программы составляют сейчас большинство в мире ПК. Но и это еще не все: а как можно проверить, что компилятор выполняет такие сложные преобразования надежно и правильно? Пока никак. Вот почему VLIW-компиляторы называют "вещью в себе". Однако решение сложной задачи обеспечения взаимодействия аппаратного и программного обеспечения в архитектуре VLIW требует серьезных предварительных исследований.
Таким образом, достоинства VLIW заключаются в следующем. Во-первых, компилятор может более эффективно исследовать зависимости между командами и выбирать параллельно исполняемые команды, чем это делает аппаратура суперскалярного процессора, ограниченная размером окна исполнения.
Во-вторых, VLIW процессор имеет более простое устройство управления и потенциально может иметь более высокую тактовую частоту.
Однако у VLIW процессоров есть серьезный фактор, снижающий их производительность. Это команды ветвления, зависящие от данных, значения которых становятся известны только в динамике вычислений. Окно исполнения VLIW-процессора не может быть очень большим ввиду отсутствия у компилятора информации о зависимостях, формируемых динамически, в процессе выполнения. Этот недостаток препятствует возможности переупорядочивания операций в VLIW процессор. Кроме того, VLIW реализация требует большого размера памяти имен, многовходовых регистровых файлов, большого числа перекрестных связей. Возможен также останов, когда во время выполнения возникла ситуация, отличающаяся от состояния в момент генерации плана выполнения (например, во время выполнения произошло неудачное обращение в кэш-память).
Похожие работы
... практичных алгоритмов оптимизированного перебора, позволяющих за разумное время осуществлять распараллеливание достаточно больших участков. Анализ работ, посвященных оптимизации кода для процессоров с параллелизмом на уровне команд показывает, что для достижения наилучших результатов необходимо применение комплекса оптимизаций, среди которых можно выделить следующие классы. Преобразования циклов ...
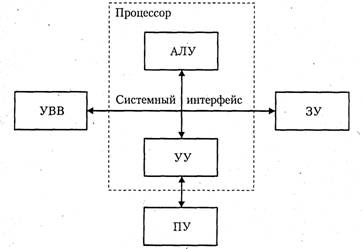
... выдвинулась концепция их взаимодействия. Так возникло принципиально новое понятие — архитектура ЭВМ. программирование вычислительный техника Под архитектурой ЭВМ понимается совокупность общих принципов организации аппаратно-программных средств и их характеристик, определяющая функциональные возможности ЭВМ при решении соответствующих классов задач. Архитектура ЭВМ охватывает широкий круг проблем ...
... сделал в машине М20,где были реализованы возможности написания программ в мнемокодах. И это значительно расширило круг специалистов, которые смогли воспользоваться преимуществами вычислительной техники. Машины второго поколения. БЭСМ-6 В 1948 году американскими учеными был создан полупроводниковый транзистор, который стал использоваться в качестве элементной базы ЭВМ. Это изобретение позволило ...
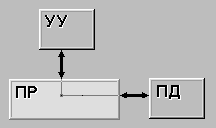
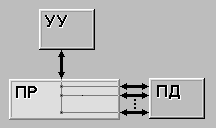
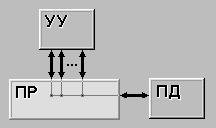
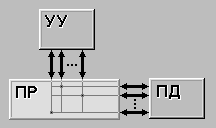
... во всех современных компьютерах это число совпадает с длиной машинного слова. Вторая характеристика равна числу слов m, обрабатываемых одновременно данной вычислительной системой. Немного изменив терминологию, функционирование любого компьютера можно представить как параллельную обработку n битовых слоев, на каждом из которых независимо преобразуются m бит. Опираясь на такую интерпретацию, вторую ...
0 комментариев