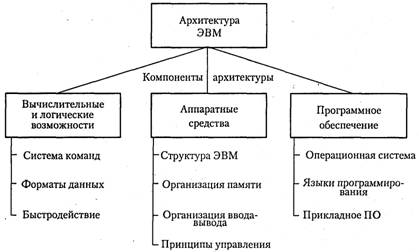
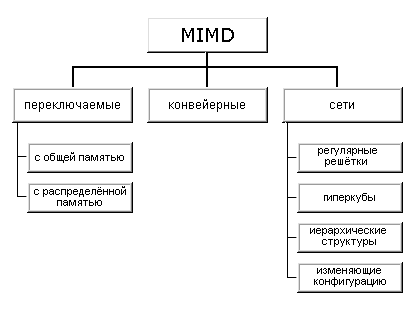
Классификация параллельных ВС
Конвейеры операций
Конфликты в конвейере и способы минимизации их влияния на производительность процессора
Суперскалярные архитектуры
Трудности реализации
VLIW-архитектура
Принцип действия VLIW-компилятора
Предсказание переходов
Матричные процессоры
Многопоточность в Pentium 4
Закон Амдала
Навигация
VLIW-архитектура
Принципы организации параллелизма выполнения машинных команд в процессорах
102663
знака
6
таблиц
1
изображение
4 VLIW-архитектура
В 1970 г. многие вычислительные системы оснащались дополнительными векторными сигнальными процессорами (VSP - Vector Signal Processor), использующими VLIW-подобные длинные инструкции, прошитые в ПЗУ. Эти процессоры применялись для выполнения быстрого преобразования Фурье (БПФ) и других вычислительных алгоритмов.
Первыми настоящими VLIW-компьютерами стали мини-суперкомпьютеры, выпущенные в начале 1980 года компаниями MultiFlow, Culler и Cydrome, но они не имели коммерческого успеха. Планировщик вычислений и программная конвейеризация были предложены Фишером и Рау (Cydrome). Сегодня это является основой технологии VLIW-компилятора.
Первый VLIW-компилятор компании Multi-Flow 7/300 использовал два АЛУ для целых чисел, два АЛУ для чисел с плавающей точкой и блок логического ветвления. Все это было собрано на нескольких микросхемах. Его 256-битное слово инструкции содержало семь 32-битных кодов операций. Модули для обработки целых чисел могли выполнять 2 операции за один такт длиной 130 нс (то есть всего 4 при двух АЛУ), что при обработке целых чисел обеспечивало быстродействие около 30MIPS (Million Instruction Per Second). Первый VLIW-компьютер Cydrome Cydra-5 использовал 256-битную инструкцию и специальный режим, обеспечивающий выполнение инструкций как последовательности из шести 40-битных операций. Поэтому его компиляторы могли генерировать смесь параллельного кода и обычного последовательного. Существует мнение, что в то время, как эти VLIW-машины использовали несколько микросхем, процессор Intel i860 стал первым VLIW-процессором на одной микросхеме. При установке правильной последовательности операций этот процессор в большей степени зависит от компилятора, нежели от аппаратуры.
Несмотря на то, что архитектура VLIW появилась еще на заре компьютерной индустрии (Тьюринг разработал VLIW-компьютер еще в 1946 году), она до сих пор не имела коммерческого успеха. Однако значительного повышения производительности и скорости вычислений можно добиться лишь путем переноса интеллектуальных функций из аппаратного обеспечения в программное (в компилятор). В целом успех этого мероприятия будет определяться в основном программными средствами, именно в этом и состоит проблема.
4.1 Аппаратно-программный комплекс VLIW
Архитектура VLIW представляет собой одну из последних реализаций концепции внутреннего параллелизма в процессорах. Их быстродействие можно повысить двумя способами: увеличив либо тактовую частоту, либо количество операций, выполняемых за один такт. В первом случае требуется изобретение "быстрых" технологий (например, использование арсенида галлия или кремния на сапфире) и применение таких архитектурных решений, как глубинная конвейеризация (конвейеризация в пределах одного такта, когда в каждый момент времени задействован весь кристалл, а не отдельные его части). Для увеличения количества выполняемых за один цикл операций необходимо на одной микросхеме разместить множество функциональных модулей обработки и обеспечить надежное параллельное исполнение машинных инструкций, что дает возможность включить в работу все модули одновременно. Надежность в таком контексте означает, что результаты вычислений будут правильными. Для примера рассмотрим два выражения, которые связаны друг с другом следующим образом: А=В+С и В=D+Е. Значение переменной А будет разным в зависимости от порядка, в котором вычисляются эти выражения (сначала А, а потом В, или наоборот), но в программе подразумевается только одно определенное значение.
Планирование порядка вычислений довольно трудная задача, которую приходится решать при проектировании современного процессора. В суперскалярных процессорах (процессор с двумя и более конвейерами, что позволяет выполнять более одной команды за один такт в идеальных условиях) для распознавания зависимостей между машинными инструкциями применяется специальное довольно сложное аппаратное решение (в процессоре Pentium Pro, например, для этого используется буфер переупорядочивания инструкций). Однако размеры такого аппаратного планировщика при увеличении количества функциональных модулей обработки возрастают в геометрической прогрессии, что, в конце концов, может "съесть" весь кристалл процессора. Поэтому суперскалярные проекты остановились на отметке пять-шесть управляемых за цикл инструкций. При другом подходе можно передать все планирование программному обеспечению, как это делается в конструкциях с VLIW. "Умный" компилятор должен выискать в программе все инструкции, которые являются совершенно независимыми, собрать их вместе в очень длинные строки (длинные инструкции) и затем отправить на одновременное исполнение функциональными модулями, количество которых строго равно количеству операций в такой длинной инструкции. Очень длинные инструкции обычно имеют размер от 256 бит до 1024 бит. Размер полей, кодирующих операции для каждого функционального модуля, в такой метаинструкции намного меньше.
4.2 Устройство VLIW-процессора
Процессор VLIW, имеющий такую схему, может выполнять восемь операций за один такт и работать при аналогичной тактовой частоте на 80-100% быстрее существующих суперскалярных чипов. Добавочные функциональные блоки могут повысить производительность (за счет уменьшения конфликтов), не слишком усложняя чип. Однако это расширение ограничивается физическими возможностями: количеством портов чтения-записи, необходимым для обеспечения одновременного доступа функциональных блоков к файлу, регистров и взаимосвязей, которое геометрически растет при увеличении количества функциональных блоков. К тому же компилятор должен распараллелить программу до необходимого уровня, чтобы обеспечить загрузку каждому блоку. Процессор выполняет 8 операций за один цикл.
Эта гипотетическая инструкция длиной в 256 бит имеет восемь операционных полей, каждое из которых выполняет традиционную трехоперандную инструкцию (< оп. > < рег. источник > < рег. получатель >). Каждое операционное поле может непосредственно управлять специфическим функциональным блоком при минимальном декодировании.
Аппаратная реализация VLIW-процессора очень проста: несколько небольших функциональных модулей (сложения, умножения, ветвления и т.д.), подключенных к шине процессора, и несколько регистров и блоков кэш-памяти. VLIW-архитектура представляет интерес для полупроводниковой промышленности по двум причинам. Первая причина - теперь на кристалле больше места может быть отведено для блоков обработки, а не, скажем, для блока предсказания переходов. Вторая причина - VLIW-процессор может быть высокоскоростным, так как предельная скорость обработки определяется только внутренними особенностями самих функциональных модулей.
VLIW изымает микрокод из процессора и переносит его в компилятор, в результате чего эмуляция инструкций процессора 8086, таких, как STOS, осуществляется очень эффективно, поскольку процессор получает для исполнения уже готовые макросы. Но вместе с тем это порождает и некоторые трудности, ведь написание микрокода - невероятно трудоемкий и длительный процесс. Архитектуре VLIW может обеспечить жизнеспособность только "умный" компилятор, который возьмет эту работу на себя. Именно это ограничивает использование вычислительных машин с архитектурой VLIW: пока она нашла свое применение только в векторных (для научных расчетов) и сигнальных процессорах.
Похожие работы
... практичных алгоритмов оптимизированного перебора, позволяющих за разумное время осуществлять распараллеливание достаточно больших участков. Анализ работ, посвященных оптимизации кода для процессоров с параллелизмом на уровне команд показывает, что для достижения наилучших результатов необходимо применение комплекса оптимизаций, среди которых можно выделить следующие классы. Преобразования циклов ...
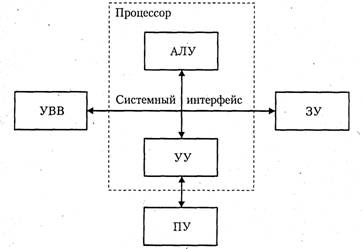
... выдвинулась концепция их взаимодействия. Так возникло принципиально новое понятие — архитектура ЭВМ. программирование вычислительный техника Под архитектурой ЭВМ понимается совокупность общих принципов организации аппаратно-программных средств и их характеристик, определяющая функциональные возможности ЭВМ при решении соответствующих классов задач. Архитектура ЭВМ охватывает широкий круг проблем ...
... сделал в машине М20,где были реализованы возможности написания программ в мнемокодах. И это значительно расширило круг специалистов, которые смогли воспользоваться преимуществами вычислительной техники. Машины второго поколения. БЭСМ-6 В 1948 году американскими учеными был создан полупроводниковый транзистор, который стал использоваться в качестве элементной базы ЭВМ. Это изобретение позволило ...
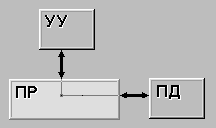
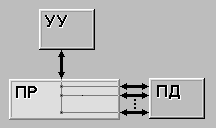
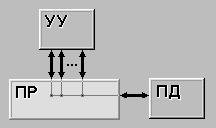
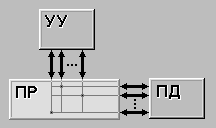
... во всех современных компьютерах это число совпадает с длиной машинного слова. Вторая характеристика равна числу слов m, обрабатываемых одновременно данной вычислительной системой. Немного изменив терминологию, функционирование любого компьютера можно представить как параллельную обработку n битовых слоев, на каждом из которых независимо преобразуются m бит. Опираясь на такую интерпретацию, вторую ...
0 комментариев