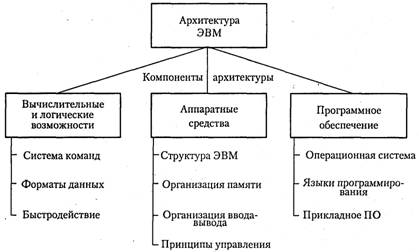
Классификация параллельных ВС
Конвейеры операций
Конфликты в конвейере и способы минимизации их влияния на производительность процессора
Суперскалярные архитектуры
Трудности реализации
VLIW-архитектура
Принцип действия VLIW-компилятора
Предсказание переходов
Матричные процессоры
Многопоточность в Pentium 4
Закон Амдала
Навигация
Матричные процессоры
Принципы организации параллелизма выполнения машинных команд в процессорах
102663
знака
6
таблиц
1
изображение
6 Матричные процессоры
Конвейеры и суперскалярная архитектура обычно повышают скорость работы всего лишь в 5-10 раз. Чтобы увеличить производительность в 50, 100 и более раз, нужно создавать компьютеры с несколькими процессорами.
В любой параллельной компьютерной системе процессоры, выполняющие разные части единого задания, должны как-то взаимодействовать друг с другом, чтобы обмениваться информацией. Как именно должен происходить обмен? Для этого было предложено и реализовано две стратегии: мультипроцессоры и мультикомпьютеры. Ключевое различие между стратегиями состоит в наличии или отсутствии общей памяти. Это различие сказывается как на конструкции, устройстве и программировании таких систем, так и на их стоимости и размерах.
6.1 Матричные процессоры
Многие задачи в физических и технических науках предполагают использование массивов или других упорядоченных структур. Часто одни и те же вычисления могут производиться над разными наборами данных в одно и то же время. Упорядоченность и структурированность программ, предназначенных для выполнения такого рода вычислений, очень удобны в плане ускорения вычислений за счет параллельной обработки команд.
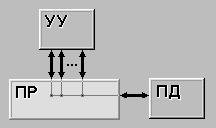
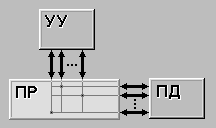
Матричный процессор (array processor) состоит из большого числа сходных процессоров, которые выполняют одну и ту же последовательность команд применительно к разным наборам данных. Первым в мире таким процессором был ILLIAC IV (Университет Иллинойс). Схематически он изображен на рисунке 6.1. Первоначально предполагалось сконструировать машину, состоящую из четырех квадрантов, каждый из которых содержал матрицу размером 8 х 8 из блоков процессор/память. Для каждого квадранта имелся один блок контроля. Он рассылал команды, которые выполнялись всеми процессорами одновременно, при этом каждый процессор использовал собственные данные из собственной памяти (загрузка данных происходила при инициализации). Это решение, значительно отличающееся от стандартной фон-неймановской машины, иногда называют архитектурой SIMD (Single Instruction-stream Multiple Data-stream - один поток команд с несколькими потоками данных). Из-за очень высокой стоимости был построен только один такой квадрант, но он мог выполнять 50 млн операций с плавающей точкой в секунду. Если бы при создании машины использовалось четыре квадранта, она могла бы выполнять 1 млрд операций с плавающей точкой в секунду, и вычислительные возможности такой машины в два раза превышали бы возможности компьютеров всего мира.
6.2 Векторный процессор
С точки зрения программиста, векторный процессор (vector processor) очень похож на матричный. Как и матричный, он чрезвычайно эффективен при выполнении последовательности операций над парами элементов данных. Однако в отличие от матричного процессора, все операции сложения выполняются в одном блоке суммирования, который имеет конвейерную структуру. Компания Cray Research, основателем которой был Сеймур Крей, выпустила множество моделей векторных процессоров, начиная с модели Сгау-1 A974.
Оба типа процессоров работают с массивами данных. Оба они выполняют одни и те же команды, которые, например, попарно складывают элементы двух векторов. Однако если у матричного процессора столько же суммирующих устройств, сколько элементов в массиве, векторный процессор содержит векторный регистр, состоящий из набора условных регистров. Эти регистры загружаются из памяти единственной командой, которая фактически делает это последовательно. Команда сложения попарно складывает элементы двух таких векторов, загружая их из двух векторных регистров в суммирующее устройство с конвейерной структурой. В результате из суммирующего устройства выходит другой вектор, который либо помещается в векторный регистр, либо сразу используется в качестве операнда при выполнении другой операции с векторами.
Матричные процессоры в настоящее время не выпускаются, но принцип, на котором они основаны, по-прежнему актуален. Аналогичная идея применяется в наборах ММХ- и SSE-команд процессоров Pentium 4, и она успешно решает задачу ускоренного выполнения мультимедийных программ. В этом отношении компьютер ILLIAC IV можно считать одним из прародителей процессора
Pentium 4.
6.3 Внутрипроцессорная многопоточность
Для всех современных конвейеризованных процессоров характерна одна и та же проблема - если при запросе к памяти слово не обнаруживается в кэшах первого и второго уровней, на загрузку этого слова в кэш уходит длительное время, в течение которого конвейер простаивает. Одна из методик решения этой проблемы называется внутрипроцессорной многопоточностью (on-chip multithreading). Она позволяет процессору одновременно управлять несколькими программными потоками и тем самым маскировать простои. Вкратце принцип можно изложить так: если программный поток 1 блокируется, процессор может обеспечить полную загрузку аппаратуры, запустив программный поток 2.
Основополагающая идея проста, реализуется она разными способами. Первый из них, называемый мелкомодульной многопоточностью (fine-grained multithreading), применительно к процессору, способному вызывать одну команду за такт, иллюстрирует рисунок 6.2. На рисунке 6.2 а-в изображено три программных потока (А, В, С), соответствующих 12 машинным циклам. В ходе первого цикла поток А выполняет команду A1. Поскольку эта команда завершается за один цикл, при наступлении второго цикла запускается команда А2. Ее обращение в кэш первого уровня оказывается неудачным, поэтому до извлечения нужного слова из кэша второго уровня проходит два цикла. Исполнение потока продолжается в цикле 5. Как показано на рисунке, потоки В и С также регулярно простаивают. В рамках такого решения вызов последующей команды до завершения предыдущей не осуществляется. Точнее, при наличии сложного счетчика обращений в некоторых случаях это допустимо, но такую возможность мы для простоты исключаем.
При мелкомодульной многопоточности простой маскируется путем исполнения потоков "по кругу", то есть в смежных циклах запускаются разные потоки (рисунок 6.2 г). К моменту наступления цикла 4 обращение к памяти, инициированное командой A1, завершается, поэтому даже если команде A2 нужен результат команды A1, она запускается. В таком случае максимальная продолжительность простоя составляет два цикла, то есть при наличии трех программных потоков простаивающая операция все равно завершается вовремя. При простое в 4 цикла для беспрерывной работы понадобилось бы 4 программных потока, и т. д.
Поскольку разные программные потоки никак друг с другом не связаны, каждому из них нужен свой набор регистров. Он должен быть указан для каждой вызываемой команды, и тогда аппаратное обеспечение будет знать, к какому набору регистров при необходимости нужно обращаться. Следовательно, максимальное число одновременно исполняемых программных потоков определяется в период разработки микросхемы.
Обращениями к памяти причины простоя не ограничиваются. Иногда для исполнения следующей команды требуется результат предыдущей команды, который еще не вычислен. В других случаях команда вызвана быть не может, так как она следует за условным переходом, направление которого еще неизвестно. Общее правило формулируется так: если в конвейере k ступеней, но по кругу можно запустить, по меньшей мере, k программных потоков, то в одном потоке в любой отдельно взятый момент не может выполняться более одной команды, поэтому конфликты между ними исключены. В такой ситуации процессор может работать на полной скорости, без простоя.
Естественно, далеко не всегда число доступных потоков равно числу ступеней конвейера, поэтому некоторые разработчики предпочитают методику, называемую крупномодульной многопоточностью (coarse-grained multithreading), которую иллюстрирует рисунок 6.2, д. В данном случае программный поток А продолжает выполняться последовательно, вплоть до простоя. При этом теряется один цикл. Далее происходит переключение на первую команду программного потока B (B1). Так как эта команда сразу переходит в состояние простоя, в цикле 6 выполняется уже команда C1. Так как каждый раз при простое команды теряется один цикл, по своей эффективности крупномодульная многопоточность, казалось бы, уступает мелкомодульной, однако у нее есть одно существенное преимущество - за счет меньшего числа программных потоков значительно сокращается расход ресурсов процессора. При недостаточном количестве активных потоков эта методика оптимальна.
Судя по нашему описанию, при крупномодульной многопоточности просто выполняется переключение между потоками, однако это - не единственный предусматриваемый данной методикой вариант действий. Есть возможность немедленного переключения с команд, которые потенциально способны вызвать простой (например, загрузка, сохранение и переходы), без выяснения, действительно ли намечается простой. Эта стратегия позволяет переключаться раньше обычного (сразу после декодирования команды) и исключает бесконечные циклы. Иными словами, исполнение продолжается до того момента, пока не обнаружится возможность возникновения проблемы, после чего следует переключение. Такие частые переключения роднят крупномодульную многопоточность с мелкомодульной.
Вне зависимости от используемого варианта многопоточности, необходимо как-то отслеживать принадлежность каждой операции к тому или иному программному потоку. В рамках мелкомодульной многопоточности каждой операции присваивается идентификатор потока, поэтому при перемещениях по конвейеру ее принадлежность не вызывает сомнений. Крупномодульная многопоточность предусматривает возможность очистки конвейера перед запуском каждого последующего потока. В таком случае четко определяется идентичность потока, исполняемого в данный момент. Естественно, данная методика эффективна только в том случае, если паузы между переключениями значительно больше времени, необходимого для очистки конвейера.
Все сказанное относится к процессорам, способным вызывать не более одной команды за тактовый цикл. Однако мы знаем, что для современных процессоров это ограничение не актуально. Применительно к изображению на рисунке 6.3 мы допускаем, что процессор может вызывать по 2 команды за цикл, однако утверждение о невозможности запуска последующих команд в случае простоя предыдущей остается в силе. Рисунок 6.3, а иллюстрирует механизм мелкомодульной многопоточности в сдвоенном суперскалярном процессоре. Как видно, в потоке А первые две команды запускаются во время первого цикла, однако в потоке В во втором цикле запускается только одна команда.
В суперскалярных процессорах есть еще один способ организации многопоточности - так называемая синхронная многопоточность (simultaneous multithreading), которую иллюстрирует рисунок 6.3, в. Эта методика представляет собой усовершенствованный вариант крупномодульной многопоточности, где каждый программный поток может запускать по две команды за такт, однако в случае простоя с целью обеспечения полной загрузки процессора запускаются команды следующего потока. При синхронной многопоточности полностью загружаются все функциональные блоки. В случае невозможности запуска команды из-за занятости функционального блока выбирается команда из другого потока. На рисунке предполагается, что в цикле 11 простаивает команда B8, поэтому в цикле 12 запускается команда С7.
Похожие работы
... практичных алгоритмов оптимизированного перебора, позволяющих за разумное время осуществлять распараллеливание достаточно больших участков. Анализ работ, посвященных оптимизации кода для процессоров с параллелизмом на уровне команд показывает, что для достижения наилучших результатов необходимо применение комплекса оптимизаций, среди которых можно выделить следующие классы. Преобразования циклов ...
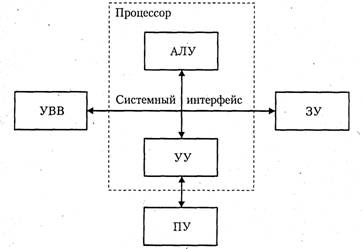
... выдвинулась концепция их взаимодействия. Так возникло принципиально новое понятие — архитектура ЭВМ. программирование вычислительный техника Под архитектурой ЭВМ понимается совокупность общих принципов организации аппаратно-программных средств и их характеристик, определяющая функциональные возможности ЭВМ при решении соответствующих классов задач. Архитектура ЭВМ охватывает широкий круг проблем ...
... сделал в машине М20,где были реализованы возможности написания программ в мнемокодах. И это значительно расширило круг специалистов, которые смогли воспользоваться преимуществами вычислительной техники. Машины второго поколения. БЭСМ-6 В 1948 году американскими учеными был создан полупроводниковый транзистор, который стал использоваться в качестве элементной базы ЭВМ. Это изобретение позволило ...
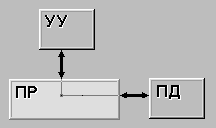
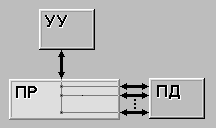
... во всех современных компьютерах это число совпадает с длиной машинного слова. Вторая характеристика равна числу слов m, обрабатываемых одновременно данной вычислительной системой. Немного изменив терминологию, функционирование любого компьютера можно представить как параллельную обработку n битовых слоев, на каждом из которых независимо преобразуются m бит. Опираясь на такую интерпретацию, вторую ...
0 комментариев