Классификация параллельных ВС
Конвейеры операций
Конфликты в конвейере и способы минимизации их влияния на производительность процессора
Суперскалярные архитектуры
Трудности реализации
VLIW-архитектура
Принцип действия VLIW-компилятора
Предсказание переходов
Матричные процессоры
Многопоточность в Pentium 4
Закон Амдала
Навигация
Суперскалярные архитектуры
Принципы организации параллелизма выполнения машинных команд в процессорах
102663
знака
6
таблиц
1
изображение
3 Суперскалярные архитектуры
3.1 Работа суперскалярного конвейера
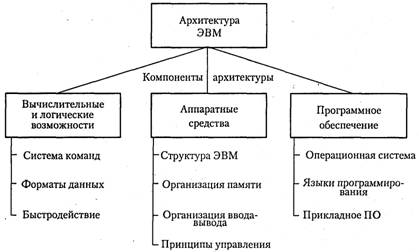
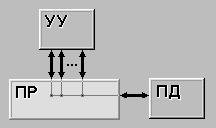
Одна из возможных схем процессора с двумя конвейерами показана на рисунке 3.1. В ее основе лежит конвейер, изображенный на рисунке 2.1. Здесь общий блок выборки команд вызывает из памяти сразу по две команды и помещает каждую из них в один из конвейеров. Каждый конвейер содержит АЛУ для параллельных операций. Чтобы выполняться параллельно, две команды не должны конфликтовать из-за ресурсов (например, регистров), и ни одна из них не должна зависеть от результата выполнения другой. Как и в случае с одним конвейером, либо компилятор должен гарантировать отсутствие нештатных ситуаций (когда, например, аппаратура не обеспечивает проверку команд на несовместимость и при обработке таких команд выдает некорректный результат), либо за счет дополнительной аппаратуры конфликты должны выявляться и устраняться непосредственно в ходе выполнения команд.
Сначала конвейеры (как сдвоенные, так и обычные) использовались только в RISC-компьютерах. У процессора 386 и его предшественников их не было. Конвейеры в процессорах компании Intel появились, только начиная с модели 486. Процессор 486 имел один пятиступенчатый конвейер, a Pentium - два таких конвейера. Похожая схема изображена на рисунке 3.1, но разделение функций между второй и третьей ступенями (они назывались декодер 1 и декодер 2) было другим. Главный конвейер (u-конвейер) мог выполнять произвольные команды. Второй конвейер (v-конвейер) мог выполнять только простые команды с целыми числами, а также одну простую команду с плавающей точкой (FXCH) [2,5].
Имеются сложные правила определения, является ли пара команд совместимой в отношении возможности параллельного выполнения. Если команды, входящие в пару, были сложными или несовместимыми, выполнялась только одна из них (в u-конвейере). Оставшаяся вторая команда составляла затем пару со следующей командой. Команды всегда выполнялись по порядку. Таким образом, процессор Pentium содержал особые компиляторы, которые объединяли совместимые команды в пары и могли порождать программы, выполняющиеся быстрее, чем в предыдущих версиях. Измерения показали, что программы, в которых применяются операции с целыми числами, при той же тактовой частоте на Pentium выполняются почти в два раза быстрее, чем на 486. Вне всяких сомнений, преимущество в скорости было достигнуто благодаря второму конвейеру.
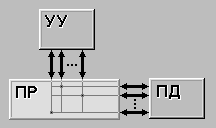
Стоит отметить, что переход к четырем конвейерам возможен, но требует громоздкого аппаратного обеспечения. Вместо этого используется другой подход. Основная идея - один конвейер с большим количеством функциональных блоков, как показано на рисунке 3.2. Pentium II, к примеру, имеет сходную структуру. В 1987 году для обозначения этого подхода был введен термин суперскалярная архитектура. Однако подобная идея нашла воплощение еще тридцатью годами ранее в компьютере CDC 6600. Этот компьютер вызывал команду из памяти каждые 100 не и помещал ее в один из 10 функциональных блоков для параллельного выполнения. Пока команды выполнялись, центральный процессор вызывал следующую команду.
Со временем значение понятия "суперскалярный" несколько изменилось. Теперь суперскалярными называют процессоры, способные запускать несколько команд зачастую от четырех до шести) за один тактовый цикл. Естественно, чтобы передавать все эти команды, в суперскалярном процессоре должно быть несколько функциональных блоков. Поскольку в процессорах этого типа, как правило, предусматривается один конвейер, его устройство обычно соответствует рисунку 3.2.
В свете такой терминологической динамики на сегодняшний день можно утверждать, что компьютер 6600 не был суперскалярным с технической точки зрения - ведь за один тактовый цикл в нем запускалось не больше одной команды. Однако при этом был достигнут аналогичный результат - команды запускались быстрее, чем выполнялись. На самом деле разница в производительности между ЦП с циклом в 100 не, передающим за этот период по одной команде четырем функциональным блокам, и ЦП с циклом в 400 не, запускающим за это время четыре команды, трудноуловима. В обоих процессорах соблюдается принцип превышения скорости запуска над скоростью управления; при этом рабочая нагрузка распределяется между несколькими функциональными блоками.
Отметим, что на выходе ступени 3 команды появляются значительно быстрее, чем ступень 4 способна их обрабатывать. Если бы на выходе ступени 3 команды появлялись каждые 10 не, а все функциональные блоки делали свою работу также за 10 не, то на ступени 4 всегда функционировал бы только один блок, что сделало бы саму идею конвейера бессмысленной. Как видно из рисунка 3.2, на ступени 4 может быть несколько АЛУ.
Суперскалярные процессоры имеют:
- многоуровневую иерархическую память, включая до трех уровней кэш-памяти;
- раздельные кэш-памяти команд и данных;
- устройство выборки команд, обеспечивающее выборку на исполнение совокупности команд;
- таблицы предсказания переходов;
- переименование регистров;
- поддержку внеочередного исполнения команд;
- набор функциональных устройств для преобразования данных в форматах с фиксированной и плавающей точкой.
Суперскалярные машины используют параллелизм на уровне команд путем посылки нескольких команд из обычного потока команд в несколько функциональных устройств. Дополнительно, чтобы снять ограничения последовательного выполнения команд, эти машины используют механизмы внеочередной выдачи и внеочередного завершения команд, прогнозирование переходов, кэши целевых адресов переходов и условное (по предположению) выполнение команд. Возросшая сложность, реализуемая этими механизмами, создает также проблемы реализации точного прерывания.
В типичной суперскалярной машине аппаратура может осуществлять выдачу от одной до шести команд в одном такте. Обычно эти команды должны быть независимыми и удовлетворять некоторым ограничениям, например таким, что в каждом такте не может выдаваться более одной команды обращения к памяти. Если какая-либо команда в потоке команд является логически зависимой или не удовлетворяет критериям выдачи, на выполнение будут выданы только команды, предшествующие данной. Поэтому скорость выдачи команд в суперскалярных машинах является переменной. Это отличает их от VLIW-машин, в которых полную ответственность за формирование пакета команд, которые могут выдаваться одновременно, несет компилятор, а аппаратура в динамике не принимает никаких решений относительно выдачи нескольких команд.
Предположим, что машина может выдавать на выполнение две команды в одном такте. Одной из таких команд может быть команда загрузки регистров из памяти, записи регистров в память, команда переходов, операции целочисленного АЛУ, а другой может быть любая операция плавающей точки (ПТ). Параллельная выдача целочисленной операции и операции с плавающей точкой намного проще, чем выдача двух произвольных команд. В реальных системах (например, в процессорах PA7100, hyperSPARC, Pentium и др.) применяется именно такой подход. В более мощных процессорах (например, MIPS R10000, UltraSPARC, PowerPC 620 и др.) реализована выдача до четырех команд в одном такте.
Выдача двух команд в каждом такте требует одновременной выборки и декодирования по крайней мере 64 бит. Чтобы упростить декодирование можно потребовать, чтобы команды располагались в памяти парами и были выровнены по 64-битовым границам. В противном случае необходимо анализировать команды в процессе выборки и, возможно, менять их местами в момент пересылки в целочисленное устройство и в устройство ПТ. При этом возникают дополнительные требования к схемам обнаружения конфликтов. В любом случае вторая команда может выдаваться, только если может быть выдана на выполнение первая команда. Аппаратура принимает такие решения в динамике, обеспечивая выдачу только первой команды, если условия для одновременной выдачи двух команд не соблюдаются. В таблице 3.1 представлена диаграмма работы подобного конвейера в идеальном случае, когда в каждом такте на выполнение выдается пара команд.
Такой конвейер позволяет существенно увеличить скорость выдачи команд. Однако чтобы он смог так работать, необходимо иметь либо полностью конвейеризованные устройства плавающей точки, либо соответствующее число независимых функциональных устройств. В противном случае устройство плавающей точки станет узким горлом и эффект, достигнутый за счет выдачи в каждом такте пары команд, сведется к минимуму.
Рассмотрим следующие этапы выполнения команды:
- выборка команды - IF;
- декодирование команды - ID;
- выполнение операции - EX;
- обращение к памяти - MEM;
- запоминание результата - WB.
| Тип команды | Ступень конвейера | |||||||
| Целочисленная команда | IF | ID | EX | MEM | WB | |||
| Команда ПТ | IF | ID | EX | MEM | WB | |||
| Целочисленная команда | IF | ID | EX | MEM | WB | |||
| КомандаПТ | IF | ID | EX | MEM | WB | |||
| Целочисленная команда | IF | ID | EX | MEM | WB | |||
| Команда ПТ | IF | ID | EX | MEM | WB | |||
| Целочисленная команда | IF | ID | EX | MEM | WB | |||
| Команда ПТ | IF | ID | EX | MEM | WB | |||
Таблица 3.1 Работа суперскалярного конвейера
Похожие работы
... практичных алгоритмов оптимизированного перебора, позволяющих за разумное время осуществлять распараллеливание достаточно больших участков. Анализ работ, посвященных оптимизации кода для процессоров с параллелизмом на уровне команд показывает, что для достижения наилучших результатов необходимо применение комплекса оптимизаций, среди которых можно выделить следующие классы. Преобразования циклов ...
... выдвинулась концепция их взаимодействия. Так возникло принципиально новое понятие — архитектура ЭВМ. программирование вычислительный техника Под архитектурой ЭВМ понимается совокупность общих принципов организации аппаратно-программных средств и их характеристик, определяющая функциональные возможности ЭВМ при решении соответствующих классов задач. Архитектура ЭВМ охватывает широкий круг проблем ...
... сделал в машине М20,где были реализованы возможности написания программ в мнемокодах. И это значительно расширило круг специалистов, которые смогли воспользоваться преимуществами вычислительной техники. Машины второго поколения. БЭСМ-6 В 1948 году американскими учеными был создан полупроводниковый транзистор, который стал использоваться в качестве элементной базы ЭВМ. Это изобретение позволило ...
... во всех современных компьютерах это число совпадает с длиной машинного слова. Вторая характеристика равна числу слов m, обрабатываемых одновременно данной вычислительной системой. Немного изменив терминологию, функционирование любого компьютера можно представить как параллельную обработку n битовых слоев, на каждом из которых независимо преобразуются m бит. Опираясь на такую интерпретацию, вторую ...
0 комментариев