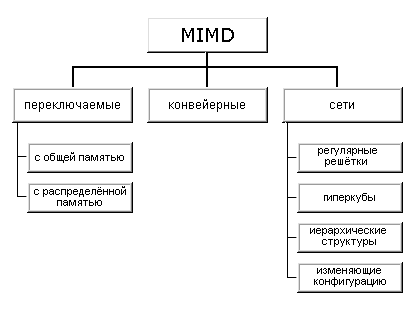
Классификация параллельных ВС
Конвейеры операций
Конфликты в конвейере и способы минимизации их влияния на производительность процессора
Суперскалярные архитектуры
Трудности реализации
VLIW-архитектура
Принцип действия VLIW-компилятора
Предсказание переходов
Матричные процессоры
Многопоточность в Pentium 4
Закон Амдала
Навигация
Трудности реализации
Принципы организации параллелизма выполнения машинных команд в процессорах
102663
знака
6
таблиц
1
изображение
3.2 Трудности реализации
При параллельной выдаче двух операций (одной целочисленной команды и одной команды ПТ) потребность в дополнительной аппаратуре, помимо обычной логики обнаружения конфликтов, минимальна: целочисленные операции и операции ПТ используют разные наборы регистров и разные функциональные устройства. Единственная сложность возникает, только если команды представляют собой команды загрузки, записи и пересылки чисел с плавающей точкой. Эти команды создают конфликты по портам регистров ПТ, а также могут приводить к новым конфликтам типа RAW, когда операция ПТ, которая могла бы быть выдана в том же такте, является зависимой от первой команды в паре.
Если пара команд состоит из одной команды загрузки с ПТ и одной операции с ПТ, которая от нее зависит, необходимо обнаруживать подобный конфликт и блокировать выдачу операции с ПТ. За исключением этого случая, все другие конфликты естественно могут возникать, как и в обычной машине, обеспечивающей выдачу одной команды в каждом такте. Для предотвращения ненужных приостановок могут, правда, потребоваться дополнительные цепи обхода.
Другой проблемой, которая может ограничить эффективность суперскалярной обработки, является задержка загрузки данных из памяти. В нашем примере простого конвейера команды загрузки имели задержку в один такт, что не позволяло следующей команде воспользоваться результатом команды загрузки без приостановки. В суперскалярном конвейере результат команды загрузки не может быть использован в том же самом и в следующем такте. Это означает, что следующие три команды не могут использовать результат команды загрузки без приостановки. Задержка перехода также становится длиною в три команды, поскольку команда перехода должна быть первой в паре команд. Чтобы эффективно использовать параллелизм, доступный на суперскалярной машине, нужны более сложные методы планирования потока команд, используемые компилятором или аппаратными средствами, а также более сложные схемы декодирования команд.
В общем случае в суперскалярной системе команды могут выполняться параллельно и возможно не в порядке, предписанном программой. Если не предпринимать никаких мер, такое неупорядоченное выполнение команд и наличие множества функциональных устройств с разными временами выполнения операций могут приводить к дополнительным трудностям. Например, при выполнении некоторой длинной команды с плавающей точкой (команды деления или вычисления квадратного корня) может возникнуть исключительная ситуация уже после того, как завершилось выполнение более быстрой операции, выданной после этой длинной команды. Для того, чтобы поддерживать модель точных прерываний, аппаратура должна гарантировать корректное состояние процессора при прерывании для организации последующего возврата.
Обычно в машинах с неупорядоченным выполнением команд предусматриваются дополнительные буферные схемы, гарантирующие завершение выполнения команд в строгом порядке, предписанном программой. Такие схемы представляют собой некоторый буфер "истории", то есть аппаратную очередь, в которую при выдаче попадают команды и текущие значения регистров результата этих команд в заданном программой порядке.
3.3 Историческая справка
В 1993 году корпорация Intel внедрила в массовое производство параллелизм на уровне команд, выпустив процессор Intel Pentium, обладавший способностью декодировать и выполнять команды вычислительного потока параллельно. Годом позже специалисты Intel реализовали двухпроцессорную обработку (два полноценных процессора помещались в два разъема на одной системной плате), создав аппаратную многопоточную среду для серверов и рабочих станций. В 1995 году был представлен процессор Intel Pentium Pro, поддерживавший эффективное объединение четырех процессоров на одной системной плате, что позволило обеспечить более высокую скорость обработки данных в многопоточных приложениях, ориентированных на серверные платформы и рабочие станции.
Появление в 2002 году технологии Hyper-Threading (HT) ознаменовало приход многопоточного параллелизма, то есть возможности выполнять разные потоки приложений одновременно на одноядерном процессоре. Тестирование производительности, проведенное корпорацией Intel, показало, что на процессорах с технологией HT скорость работы некоторых приложений возрастает в среднем на 30%.
Ныне, взяв курс на многоядерные платформы, корпорация Intel стала лидером в процессе перехода на многопоточные и параллельные вычисления на массовых ПК, обеспечив обработку данных на нескольких вычислительных ядрах одного процессора.
Большинство приложений, уже сегодня оптимизированных для параллельного исполнения вычислительных потоков, например, программ, поддерживающих технологию Hyper-Threading или предназначенных к исполнению на рабочих станциях или серверах с двухпроцессорной конфигурацией, при выполнении на многоядерном процессоре демонстрируют прекрасную масштабируемость производительности. К этой категории относятся мультимедийные приложения, научные приложения и системы CAD/CAM [7,9].
Первый суперскалярный МП i960 был выпущен фирмой Intel в 1987 году. Затем были разработаны МП SPARC (1987-1989 годы), MIPS (1988-1989 годы), МПi860 (1989 год)и ряд других суперскалярных МП, в частности:
1. Процессор Pentium был впервые поставлен фирмой Intel в 1993 году как продолжение семейства МП 80x86. Цель его создания - получение быстродействия RISC-МП и полная совместимость на уровне двоичных кодов с программным обеспечением, созданным для всех МП 80x86.
2. Группа фирм AIM (APPLE + IBM + MOTOROLA) совместно разработали семейство МП POWER PC и выпустили его первый образец МП 661 в 1993 году.
3. Фирма DEC в 1992 году для создания мощных рабочих станций выпустила МП 21064 с тактовой частотой 250 Мгц, а затем более мощный МП - 21164.
4. В 1994 году фирма MIPS Computer, известная разработкой суперконвейерных МП, выпустила первый суперскалярный МП MIPS R8000 (MIPS - Microprocessor Without Interlocked Pipeline Stages), а затем МП R10000.
5. В 1994 году фирма Sun Microsystem Inc. в продолжение развития своей серии SPARC (Scalable Processor Architecture) выпустила мощный МП UltraSPARC.
6. В 1994-1995 годах фирмой Hewlett-Packard был выпущен МП PA7200 с высокими показателями быстродействия, предполагается к выпуску МП РА8000.
Все указанные МП являются суперскалярными и поэтому характеризуются рядом общих свойств, в частности:
1. Формирование группы команд для загрузки конвейеров производится динамически в каждом такте. Для этого аппаратно на этапе предвыборки и дешифрации производится анализ зависимости по данным смежных команд. В конвейеры для параллельного исполнения подбираются независимые команды, при этом допускается изменение порядка выполнения команд.
2. Все МП используют динамическое прогнозирование ветвлений на основе буфера истории переходов. Иногда используется одновременное выполнение альтернативных ветвей.
3. Некоторые МП строятся таким образом, что число физических регистров превышает число РОН, определенных архитектурно (РРС620, Mips R10000, P6). Это необходимо для реализации альтернативных ветвей при переходах и для устранения зависимостей по данным, вызванных недостатком РОН. В процессе выполнения команд необходимо производить переименование физических регистров, то есть они выступают в качестве виртуальных.
Большинство указанных МП выпускается в однокристальном исполнении, однако в целях получения более высокого быстродействия для МП PPC 620 использовано 10 кристаллов пяти типов, а для МП R8000 - 4 кристалла трех типов.
Архитектура описанных выше суперскалярных МП приобретает традиционный характер, поэтому предпринимаются попытки освоить новые архитектуры. Одной из наиболее перспективных является разработка МП РА9000, производимая совместно фирмами Hewlett-Packard и Intel. Главная особенность РА9000 состоит в том , что генерация набора команд для одного такта полностью переносится в компилятор, что позволяет достичь высокого уровня оптимальности программы и значительно разгрузить кристалл от схем планирования и упаковки. Тем самым совершается переход к VLIW (Very Long Instruction Word) архитектуре [8,10].
Похожие работы
... практичных алгоритмов оптимизированного перебора, позволяющих за разумное время осуществлять распараллеливание достаточно больших участков. Анализ работ, посвященных оптимизации кода для процессоров с параллелизмом на уровне команд показывает, что для достижения наилучших результатов необходимо применение комплекса оптимизаций, среди которых можно выделить следующие классы. Преобразования циклов ...
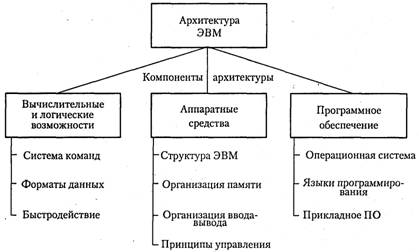
... выдвинулась концепция их взаимодействия. Так возникло принципиально новое понятие — архитектура ЭВМ. программирование вычислительный техника Под архитектурой ЭВМ понимается совокупность общих принципов организации аппаратно-программных средств и их характеристик, определяющая функциональные возможности ЭВМ при решении соответствующих классов задач. Архитектура ЭВМ охватывает широкий круг проблем ...
... сделал в машине М20,где были реализованы возможности написания программ в мнемокодах. И это значительно расширило круг специалистов, которые смогли воспользоваться преимуществами вычислительной техники. Машины второго поколения. БЭСМ-6 В 1948 году американскими учеными был создан полупроводниковый транзистор, который стал использоваться в качестве элементной базы ЭВМ. Это изобретение позволило ...
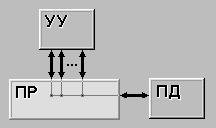
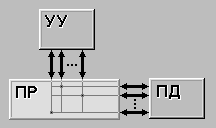
... во всех современных компьютерах это число совпадает с длиной машинного слова. Вторая характеристика равна числу слов m, обрабатываемых одновременно данной вычислительной системой. Немного изменив терминологию, функционирование любого компьютера можно представить как параллельную обработку n битовых слоев, на каждом из которых независимо преобразуются m бит. Опираясь на такую интерпретацию, вторую ...
0 комментариев