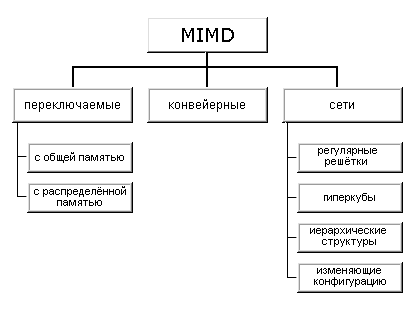
Классификация параллельных ВС
Конвейеры операций
Конфликты в конвейере и способы минимизации их влияния на производительность процессора
Суперскалярные архитектуры
Трудности реализации
VLIW-архитектура
Принцип действия VLIW-компилятора
Предсказание переходов
Матричные процессоры
Многопоточность в Pentium 4
Закон Амдала
Навигация
Предсказание переходов
Принципы организации параллелизма выполнения машинных команд в процессорах
102663
знака
6
таблиц
1
изображение
5 Предсказание переходов
Команды, помещенные в окно исполнения, могут быть зависимы по данным. Эти зависимости обусловлены использованием одних и тех же ресурсов памяти (регистров, ячеек памяти) в разных командах. Поэтому для правильного исполнения программы необходимо использование этих ресурсов в предписываемом программой порядке.
Поскольку при суперскалярной обработке необходимо извлекать из памяти несколько команд за один такт для загрузки параллельно работающих функциональных устройств, повышенные требования предъявляются к пропускной способности интерфейса «процессор-память». В современных процессорах применяются многоуровневые раздельные кэш-памяти данных и команд.
Для уменьшения потерь процессорных тактов, связанных с промахами при обращении к кэш-памяти в случае выполнения команд ветвления, в состав системы кэширования вводятся средства предсказания переходов, основное назначение которых — повысить вероятность наличия в кэшпамяти требуемой команды.
Исполнение условных ветвлений состоит из следующих этапов:
- распознавание команды условного ветвления;
- проверка выполнения условия перехода;
- вычисление адреса перехода;
- передача управления в случае перехода.
На каждом этапе используются специальные приемы повышения производительности [1].
1. Для быстрого декодирования применяются либо дополнительные биты в поле команды, либо преддекодирование команд при их выборке из кэш-памяти команд.
2. Часто, когда команда уже выбрана из кэш-памяти команд, условие перехода еще не вычислено. Чтобы не задерживать поток команд, в данном случае используется предсказание перехода по одной из нескольких возможных схем.
Механизм предсказания переходов выполняет две основные функции — предсказание программного адреса инструкции, на которую производится переход (для всех инструкций перехода), и предсказание направления ветвления (для инструкций условного перехода). Оба предсказания должны быть выполнены заблаговременно — раньше, чем начнётся декодирование и обработка инструкции перехода — для того, чтобы выборка нового блока инструкций была произведена без потерь лишних тактов либо с минимальными потерями.
Необходимость предсказания адреса «целевой» инструкции вызвана тем, что этот адрес может быть извлечён из x86-инструкции перехода и вычислен только на финальной стадии декодирования, с большой задержкой. Более того, даже простое выделение инструкций переменной длины из считанного блока и поиск среди них инструкций перехода займёт какое-то время. Поэтому в процессорах архитектуры x86 предсказание производят по целому блоку, без разбиения его на составляющие инструкции.
В современных процессорах для предсказания адреса перехода обычно используют специальную таблицу адресов переходов BTB (Branch Target Buffer). Эта таблица устроена подобно кэшу и содержит адреса инструкций, на которые ранее производились переходы. Например, в процессоре P-III таблица BTB имеет размер 512 элементов и организована в виде 128 наборов с ассоциативностью 4. Для адресации набора используются младшие разряды адреса 16-байтового блока инструкций. Если в этом блоке есть инструкции перехода, и если эти инструкции отрабатывали ранее, то алгоритм предсказания может очень быстро найти адрес целевой инструкции в таблице BTB и начать считывание блока, содержащего эту инструкцию. Адреса целевых инструкций помещаются в BTB в момент отставки соответствующих инструкций перехода.
В других современных процессорах размер таблицы BTB достигает 2048 элементов (K8) и 4096 элементов (P-4). Организация данной подсистемы в процессоре K8 несколько отличается от классической и основывается на предварительной разметке блоков инструкций в так называемых массивах селекторов перед помещением их в I-кэш. Эти селекторы привязаны к положению инструкций в I-кэше и при их вытеснении оттуда сохраняются в L2-кэше (в так называемых ECC-битах, предназначающихся для коррекции ошибок). Элементы таблицы BTB также привязаны к положению инструкций в I-кэше и теряются при их вытеснении. Это несколько снижает эффективность предсказания адресов переходов в процессоре K8.
Для предсказания направления условного перехода используется другой механизм, основанный на изучении поведения переходов в программе в процессе её выполнения (своего рода «сбор статистики»). Этот механизм учитывает как локальное поведение конкретной инструкции перехода (например, «как правило, переходит», «как правило, не переходит»), так и глобальные закономерности («чередуется по определённому закону» и т.п.). История поведения инструкций условного перехода записывается в специальных структурах, обычно называемых «таблицами истории переходов» (Branch History Table, BHT). Современные механизмы предсказания переходов обеспечивают правильное предсказание более чем в 90 процентах случаев.
Перечислим некоторые механизмы, используемые в новом процессоре P8, имеющем наиболее совершенную систему предсказания переходов:
- сочетание локального и глобального механизмов для предсказания «обычных» инструкций перехода с учётом истории их поведения;
- статический предсказатель для инструкций, совершающих переход в первый раз, основанный на эмпирических закономерностях (например, «переход назад» обычно предсказывается как совершённый, так как может означать переход по циклу, а «переход вперёд» — как несовершённый);
- предсказатель коротких циклов, распознающий такие переходы и определяющий число итераций цикла (позволяет правильно предсказать момент выхода из цикла);
- предсказатель косвенных переходов, определяющий целевые адреса для различных исполнений инструкции перехода (с учётом возможного чередования этих адресов);
предсказатель целевых адресов для инструкций выхода из подпрограммы, использующий небольшой аппаратный стек для запоминания адресов возврата (Return Address Stack) для эффективной отработки инструкций Call — Return.
В других процессорах компании Intel используется только часть перечисленных механизмов. Эти механизмы совершенствуются с каждым новым поколением процессоров.
В процессорах AMD K8 и IBM PPC970 используются более простые механизмы предсказания обычных переходов, и отсутствуют механизмы предсказания циклов и чередующихся косвенных переходов.
Если после формирования анализируемых признаков оказалось, что направление перехода выбрано верно, все полученные результаты переписываются из буфера по месту назначения, а выполнение программы продолжается в обычном порядке. Если направление перехода предсказано неверно, то буфер результатов очищается. Также очищается и конвейер, содержащий команды, находящиеся на разных этапах обработки, следующие за командой условного перехода. При этом аннулируются результаты всех уже выполненных этапов этих команд. Конвейер начинает загружаться с первой команды другой ветви программы. Так как конвейерная обработка эффективна при большом числе последовательно выполненных команд, то перезагрузка конвейера приводит к значительным потерям производительности. Поэтому вопросам эффективного предсказания направления ветвления разработчики всех процессоров уделяют большое внимание.
Методы предсказания переходов делятся на статические и динамические. При использовании статических методов до выполнения программы для каждой команды условного перехода указывается направление наиболее вероятного ветвления. Это указание делается или программистом с помощью специальных средств, имеющихся в некоторых языках программирования, по опыту выполнения аналогичных программ либо результатам тестового выполнения программы, или программой-компилятором по заложенным в ней алгоритмам. Статические методы предсказания ветвлений слишком упрощены; они предписывают всегда выполнять или не выполнять определенные типы переходов. В некоторых процессорах (не принадлежащих к семейству x86) команды содержат «намек» на направление предполагаемого перехода, который компилятор может сделать на основе ожидаемого им поведения программы.
Но в целом более эффективное решение — динамический алгоритм предсказания ветвлений, который учитывает направления переходов, реализовывавшиеся этой командой при выполнении программы. Например, подсчитывается количество переходов, выполненных ранее по тому или иному направлению, и на основании этого определяется направление перехода при следующем выполнении данной команды. Динамический алгоритм предсказания ветвлений на самом деле оценивает поведение команд перехода за предшествующий период времени (поскольку один и тот же переход часто выполняется более чем один раз, например, в цикле). Благодаря информации о предыстории предсказания будущих ветвлений могут делаться гораздо более точно. Таблица предсказания ветвлений организуется по ассоциативному принципу, подобно кэш-памяти, ее элементы доступны по адресу команды, ветвление которой предсказывается. В некоторых реализациях элемент таблицы предсказания ветвления является счетчиком, значение которого увеличивается при правильном предсказании и уменьшается при неправильном. При этом значение счетчика определяет преобладающее направление ветвлений. Если требуется осуществить смену значения счетчика команд, то необходим, по крайней мере, один такт для распознавания команды ветвления, модификации счетчика команд и выборки команды по заданному значению счетчика команд. Эти задержки вызывают пустые такты в конвейерах процессора. Более сложные решения используют буферы, содержащие наборы команд для двух возможных результатов ветвлений.
Возможно также использование «отложенных переходов», когда одна или несколько команд после команды ветвления выполняются безусловно.
В момент определения действительного значения условия ветвления вносится изменение в историю ветвления. Если предсказание было неверным, то должна инициироваться выборка правильных команд. Результаты команд, которые были условно выполнены, должны быть аннулированы.
Механизм предсказания переходов работает одновременно с декодером инструкций и независимо от него. Благодаря эффективной реализации предсказания адреса перехода в процессорах P-III, P-M, P-M2, P8 и K8 при правильном предсказании теряется всего 1 такт. Это означает, что минимальное время, затрачиваемое на итерацию цикла (либо на один переход в цепочке переходов) составляет 2 такта. По существу, предсказатель переходов в таком цикле (или цепочке) работает в своём независимом цикле, состоящем из двух стадий — предсказания и считывания нового блока кэша — а декодер и прочие подсистемы процессора обрабатывают инструкции из вновь считываемых блоков. Поскольку предсказатель переходов «просматривает» целый блок, который может содержать большое число инструкций, то он может «опережать» декодер в своём просмотре. Благодаря этому переход может быть совершён раньше, чем исчерпаются инструкции в текущем блоке, и указанной потери такта не произойдёт — этот такт будет скрыт на фоне бесперебойной работы декодера.
В процессоре PPC970 предсказатель переходов работает менее эффективно — при правильном предсказании теряется 2 такта, а минимальное время итерации цикла составляет 3 такта. Хотя предсказатель просматривает инструкции с некоторым опережением, это может лишь частично скрыть потерю указанных двух тактов, и в результате эффективность исполнения перехода окажется ниже, чем в других процессорах.
Когда инструкция перехода попадёт в функциональное устройство для исполнения, будет выяснено, правильно предсказан этот переход, или нет. В момент её отставки при неправильном предсказании перехода все последующие инструкции будут отменены, и начнётся считывание инструкций из I-кэша по правильному адресу. Такую процедуру называют сбросом конвейера, а время (в тактах), которое было потрачено на выполнение инструкции перехода с момента её считывания из кэша, называют длиной конвейера непредсказанного перехода. Это время характеризует чистую потерю в идеальных условиях, когда инструкция проходила через все этапы «гладко» и нигде не задерживалась по внешним причинам. В реальных условиях потеря на неправильно предсказанный переход может оказаться выше.
Длина конвейера непредсказанного перехода не всегда указывается в документации и известна весьма приблизительно. Её довольно трудно замерить, так как современные предсказатели переходов работают достаточно эффективно и не позволяют добиться гарантированной доли неправильных предсказаний в тестах. Можно дать следующие примерные оценки длины конвейера: P-III — 11, P-M — 12, P-4 — 20, P-4E — 30, P8 — 14, K8 — 11, PPC970 — 13. Нужно учесть, что в процессорах P-4 и P-4E длина такта меньше, чем в других процессорах, и потеря на непредсказанный переход, выраженная в «нормализованных» тактах с учётом соотношения 1:1.4, составит соответственно 15 и 22.
Похожие работы
... практичных алгоритмов оптимизированного перебора, позволяющих за разумное время осуществлять распараллеливание достаточно больших участков. Анализ работ, посвященных оптимизации кода для процессоров с параллелизмом на уровне команд показывает, что для достижения наилучших результатов необходимо применение комплекса оптимизаций, среди которых можно выделить следующие классы. Преобразования циклов ...
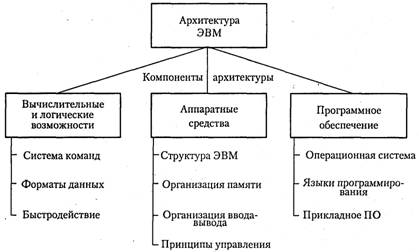
... выдвинулась концепция их взаимодействия. Так возникло принципиально новое понятие — архитектура ЭВМ. программирование вычислительный техника Под архитектурой ЭВМ понимается совокупность общих принципов организации аппаратно-программных средств и их характеристик, определяющая функциональные возможности ЭВМ при решении соответствующих классов задач. Архитектура ЭВМ охватывает широкий круг проблем ...
... сделал в машине М20,где были реализованы возможности написания программ в мнемокодах. И это значительно расширило круг специалистов, которые смогли воспользоваться преимуществами вычислительной техники. Машины второго поколения. БЭСМ-6 В 1948 году американскими учеными был создан полупроводниковый транзистор, который стал использоваться в качестве элементной базы ЭВМ. Это изобретение позволило ...
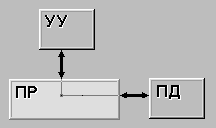
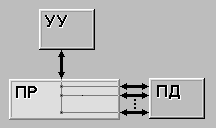
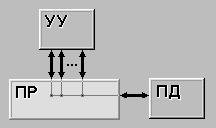
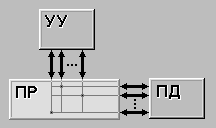
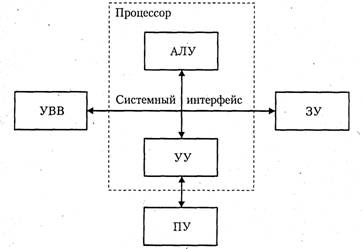
... во всех современных компьютерах это число совпадает с длиной машинного слова. Вторая характеристика равна числу слов m, обрабатываемых одновременно данной вычислительной системой. Немного изменив терминологию, функционирование любого компьютера можно представить как параллельную обработку n битовых слоев, на каждом из которых независимо преобразуются m бит. Опираясь на такую интерпретацию, вторую ...
0 комментариев