Министерство торговли как потребитель и источник информации
Комплекс прикладных задач "Делопроизводство, документооборот и электронный архив"
Постановка задачи и её спецификация
Проблема индексаци документов
Индексация по реквизитам
Архивирование документов
Устройства хранения данных
Программная реализация
Деловая игра по курсу "Гражданская оборона"
Механическое воздействие ударной волны
Методика оценки воздействия поражающих факторов ядерного взрыва
Разработка рекомендаций по защите
Автоматизированная система по курсу «Экология и охрана труда»
Обоснование проектных решений
Расчетные формулы для выбросов из низких источников
Автоматизированная обучающая система по курсу экономики
Анализ при переменной интенсивности наращения
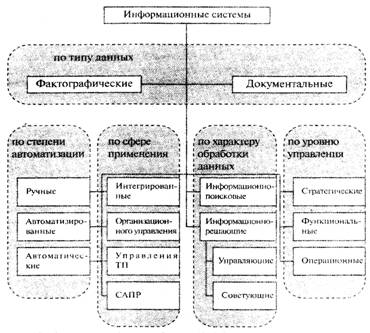
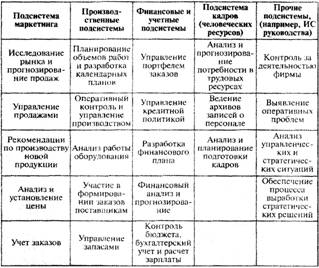
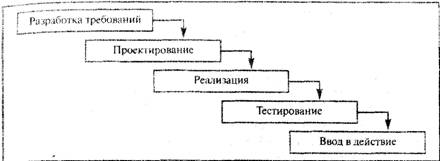
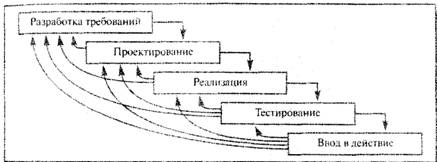
Навигация
Проблема индексаци документов
Математическое обеспечение комплекса задач “Автоматизированная система документооборота учереждения
200314
знаков
8
таблиц
2
изображения
2.1.4. Проблема индексаци документов
Процессом, аналогичным индексации, в бумажном делопроизводстве является регистрация.
Регистрация является "священной коровой" российского делопроизводства. Историческая неразвитость системы управления в сочетании с большими расстояниями и традиционно низкой ответственностью исполнителей породила своеобразный, скрупулезный подход к регистрации документов на всех уровнях управления.
Хрестоматийным примером может послужить журнал учета входящих документов, уникальный в мировой практике документ, являющийся российским "know-how".
Индексация электронных документов, осуществляемая системами автоматизации делопроизводства, преследует несколько иную цель – получить максимальное количество достоверной информации о формируемом документе и создать его регистрационную карточку. Процесс этот тем более важен, что в дальнейшем система управления документами имеет дело именно с этой карточкой, не затрагивая реальные объекты файловой системы. Далее мы в общих чертах рассмотрим известные методы индексации.
2.1.4.1. Индексация по ключевым словам
Метод индексации по ключевым словам широко использовался на начальном этапе развития СУД. Суть его заключается в выделении совокупности ключевых для работы с данным документом слов, вносимых в индексный файл. Недостатки данного метода очевидны – процесс индексирования требует дорогостоящего экспертного участия, результат индексации субъективен и не гарантирует надежного управления документом. Пользователь, например, при поиске документа вполне может использовать свой набор ключевых слов и, таким образом, не добьется результата.
В настоящее время метод индексации по ключевым словам в чистом виде не применяется.
2.1.4.2. Полнотекстовая индексация
Совершенствование и распространение систем оптического распознавания текста, обсуждавшееся нами в прошлый раз, а также совершенствование алгоритмов, основанных на элементах искусственного интеллекта, вывели на сцену метод автоматической полнотекстовой индексации (Full Text Retrieval). В этом случае весь текст подвергается автоматической обработке, основанной на морфологическом анализе (выделении грамматических классов, морфем и анализе формообразования слов). Обработанный текст заносится в индексный файл и используется при поиске документов.
Таким образом, с минимальными издержками формируется индексная база данных, обеспечивающая пользователям СУД возможности для быстрого и эффективного поиска.
На сегодняшний день та или иная реализация метода полнотекстовой индексации используется практически во всех системах управления документами.
В этой связи хотелось бы рассмотреть "нечеткй поиск". Данное понятие в приложении к системам управления документами связано с продуктом компании Excalibur Technologies – системой Excalibur EFS. В основе системы лежит технология так называемого "адаптивного распознавания образов", позволяющая, с точки зрения разработчиков, обеспечить эффективный поиск в распознанных документах, непрошедших трудоемкий этап выявления и исправления ошибок. Таким образом, декларируется возможность работы с документами, заведомо содержащими ошибки.
Вопрос сравнения эффективности систем, использующих полнотекстовую индексацию и "нечеткий поиск", нетривиальный, требует исследования и здесь не рассматривается. Мы только позволим себе прокомментировать тезисы, с помощью которых принято обосновывать преимущества.
Тезис: "Удельная стоимость ввода одной страницы текста с использованием технологий оптического распознавания в системах с полнотекстовой индексацией высока (2 – 10 USD на страницу) за счет необходимости исправления ошибок ввода".
Комментарий: Применение встроенных средств проверки орфографии в сочетании с эффективными алгоритмами распознавания в современных OCR - системах существенно снижает заявленную выше стоимость обработки. Кроме того, использование описываемых технологий именно в делопроизводстве предъявляет определенные, достаточно жесткие требования к отсутствию фактических ошибок в документах.
Тезис: "Механизм четкого (полнотекстового) поиска не дает возможности найти информацию, если были допущены ошибки при вводе информации".
Комментарий: Определенная опасность, конечно же, существует. Однако современные системы предоставляют пользователю при составлении запроса ряд дополнительных возможностей для поиска: регулировка параметра "близости слов", поиск в диапазоне значений слов, поиск слов по введенному значению морфемы.
Тезис: "Размер индексной базы в системах с полнотекстовым поиском составляет от 100 до 400% от объема проиндексированных файлов, то есть является недопустимо большим".
Комментарий: Тезис устарел. Применение качественного морфологического анализа и использование стоп-словарей, содержащих перечень слов языка, не эффективных для поиска, позволяет уменьшить объем индексной базы до 25-30% от общего объема файлов.
На сегодняшний день, очевидно, что системы, использующие полнотекстовую индексацию, отвечают требованиям абсолютного большинства пользователей.
Сейчас же мы рассмотрим наиболее старый и универсальный метод индексации – реквизитный.
Похожие работы
... проекта. В этом случае редактор кода вызывается кнопкой View Code (Просмотр кода) панели инструментов окна Проводника. 2.3 Характеристика программы Данная программа написана на языке Visual Basic 6.0 и представляет собой 1 приложением, предназначенных выполнять все функции, которые требуются заданию. В конечный продукт входит 1 откомпилированное приложения, размер которого составляет ...
... ЛС (отбор жизненно важных ЛС, обеспечение их безопасности и качества, рациональное применение и т.д.) зафиксированы далеко не все из средств, имеющихся в арсенале управления, организации и экономики производства, и основное внимание сосредоточено на конечных результатах, а не на действиях по их достижению. Государственный комитет Основными целями деятельности Государственного комитета являются ...
0 комментариев