Министерство торговли как потребитель и источник информации
Комплекс прикладных задач "Делопроизводство, документооборот и электронный архив"
Постановка задачи и её спецификация
Проблема индексаци документов
Индексация по реквизитам
Архивирование документов
Устройства хранения данных
Программная реализация
Деловая игра по курсу "Гражданская оборона"
Механическое воздействие ударной волны
Методика оценки воздействия поражающих факторов ядерного взрыва
Разработка рекомендаций по защите
Автоматизированная система по курсу «Экология и охрана труда»
Обоснование проектных решений
Расчетные формулы для выбросов из низких источников
Автоматизированная обучающая система по курсу экономики
Анализ при переменной интенсивности наращения
Навигация
Устройства хранения данных
Математическое обеспечение комплекса задач “Автоматизированная система документооборота учереждения
200314
знаков
8
таблиц
2
изображения
2.1.6.4. Устройства хранения данных
Как уже отмечалось, все данные в системе могут находиться в двух видах: индекс документа и собственно сам документ. Из-за высоких требований к скорости доступа к индексу документа и его целостности, он должен храниться в высокоскоростных отказоустойчивых системах хранения, например RAID-массивах.
Для хранения самих документов использование магнитных дисковых носителей не представляется возможным вследствие их высокой стоимости. Наиболее подходящими носителями могут быть магнитооптические, фазоинверсные (PD/CD), компакт- (CD-R) и WORM-диски (таблица 2.1). Для автоматизации поиска информации, размещенной на этих дисках, ее извлечения и работе собственно с дисками используются автоматические библиотеки или, как их еще называют, оптические дисковые автоматы (JukeBox). Сегодня известны библиотеки, имеющие до 60-ти дисководов и до 3 тыс. гнезд для дисков, выбираемых механизированным способом. Автоматические библиотеки могут быть многофункциональными, например, одновременно поддерживать магнитооптические, фазоинверсные и компакт-диски.
Таблица 2.1.
Оптические и магнитооптические накопители
| Тип диска | Емкость | Число циклов перезаписи |
| 5.25"-магнитооптические диски | 650 Мб, 1.3 Гб, 2.6 Гб | 1млн. |
| PD/CD-диски фазоинверсной записи | 650 Мб | 1тыс. |
| WORM-диски | 1-10 Гб | однократно |
| Компакт-диски CD-R | 650 Мб | однократно |
Преимущество магнитооптических дисков перед компакт-дисками основана на том, что первые позволяют перезаписывать информацию. Большинство технологических решений электронного архивирования поддерживает технологию миграции данных именно на магнитооптические диски, которые более устойчивы к ошибкам записи, имеют более высокую скорость чтения, однако уступают компакт-дискам в гарантийном сроке хранения информации и стоимости. Если магнитооптические диски, в лучшем случае, декларируют сохранность информации в течение 50 лет, то гарантия на компакт-диски может составлять 100 лет и более. Что касается стоимости систем хранения на базе магнитооптических и компакт-дисков, то она может отличаться в 4 раза. С учетом того, что большинство архивных документов, практически, не подлежат модификации и удалению, библиотеки на компакт-дисках могут быть предпочтительнее. Кроме того, компакт-диски удобнее в работе: их автономное чтение можно осуществлять на любом ПК, комплектуемом приводом CD-ROM.
Не вызывает сомнения, что вся информация в системе должна иметь резервные копии. Для графических образов сохранность информации может быть обеспечена созданием дублированных магнитооптических или компакт-дисков. Для хранения меняющейся поисковой информации в качестве сохранных накопителей удобнее использовать системы резервного копирования на магнитных лентах. Применяемые в персональных системах технологии (DC2000/Travan, DC6000, DAT) непригодны из-за ограничений в объеме. Возможным вариантом могут стать DLT-стримеры, восьмимиллиметровые библиотеки Exabyte (Mammoth) или специализированные катушечные системы. Наиболее распространены DLT-стримеры.
2.2. Обоснование проектных решений
2.2.1. Математическая модель применяемого метода
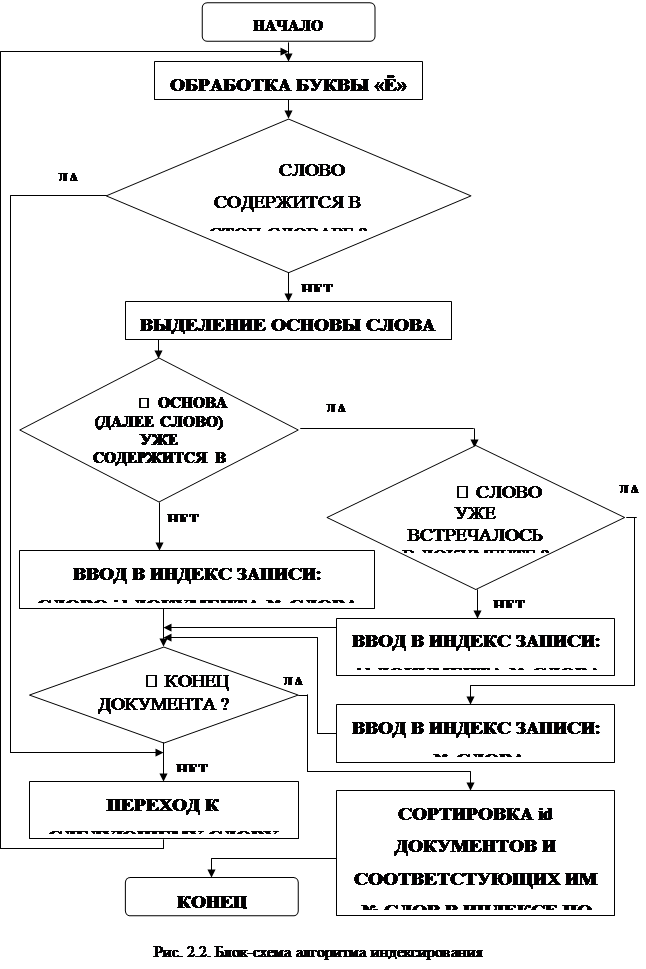
Ниже приведен разработанный алгоритм процесса индексирования документа:
1. Присвоение документу уникального идентификатора, внесение в файл идентификаторов
2. Определение формата документа
3. Определение кодировки документа
4. Перевод текста в «плоский» формат
5. Определение единицы поиска
6. Выделение отдельных слов
7. Выделение отдельных предложений
8. Обработка буквы «ё»
9. Исключение из запроса шумовых слов
10. Составление (пополнение) индекса определенного формата (рис. 2.1)
| Слово | id документа, номер слова, номер слова, . . . |
| id документа, номер слова, номер слова, . . . |
Рис. 2.1. Формат индекса
При индексировании нового документа в уже существующий индекс напротив слов добавляется идентификатор нового документа и номера данного слова в нем. При этом идентификаторы документов сортируются в соответствии с количеством вхождений слова в документ.
Таким образом, приведенный выше алгоритм обеспечивает составление единого индекса для всех индексируемых документов, что существенно уменьшает объем занимаемого индексами дискового пространства, а также уменьшает время, затрачиваемое на поиск документа.
Блок-схема алгоритма индексирования приведена на рис. 2.2.
Теперь коснемся процесса обработки запроса. Ниже приведен разработанный алгоритм процесса обработки запроса:
1. Определение кодировки запроса
2. Обработка буквы «ё»
3. Исключение из запроса шумовых слов
4. Проверка основ слов
5. Сортировка ответа по убыванию компактности вхождений слов в текст (в рамках ранжирования по релевантности)
Формализованное описание модели
В модели информационного потока вообще можно выделить несколько основных понятий: словарь, документ, поток и процедуры поиска и коррекции запросов.
Под словарем понимают упорядоченное множество терминов, мощность которого обозначают как D.
Документ - это двоичный вектор размерности D. Если термин входит в документ, то в соответствующем разряде этого двоичного вектора проставляется 1, в противном же случае - 0. Обычно все операции в линейной модели индексирования и поиска документов выполняются над поисковыми образами документов, но при этом их как правило называют просто документами.
Информационный поток или массив L представляют в виде матрицы размерности NxD, где в качестве строк выступают поисковые образы N документов. При таком рассмотрении можно сформулировать процедуру обращения к информационной системе следующим образом:
L x q = r; (2.1)
где q - вектор запроса, r - отклик системы на запрос.
Это традиционное определение процедуры поиска документов в ИПС, которое ввел Солтон в 1977 году. Оно было введено для решения проблемы автоматического индексирования документов, но оказалось чрезвычайно полезным и для описания процедуры поиска.
Существуют и другие определения процедуры обращения пользователя к системе, но для описания работы распределенных ИПС в интернете больше подходит определение Солтона - в подавляющем большинстве этих систем применяются информационно-поисковые языки типа "Like This". Данный подход хорошо известен как вычисление мер близости "документ-запрос".
В современных распределенных ИПС Internet реально используются только 6 мер близости. При этом наиболее часто в качестве меры близости рассматривают определение Солтона, например, системы RBSE и WAIS, и его же улучшенную меру близости - системы WebCrawler и Lycos.
Начало применению запросов типа "Like This" положила система WAIS. Именно в ней был впервые сформулирован отказ от использования традиционных информационно-поисковых языков булевого типа и было заявлено о переносе центра тяжести информационного поиска на языки, основанные на вычислении меры близости "документ-запрос". Основная причина такого подхода - желание снять с пользователей заботу по формулированию запросов на информационно-поисковых языках и дать им возможность использовать обычный естественный язык. Ради справедливости следует отметить, что от запросов на естественном языке практически сразу отказались. Система просто проводила нормализацию лексики и удаляла из списка терминов запроса общие и стоп-слова. Тем самым практически один в один выполнялись условия линейной модели индексирования и поиска. После этой процедуры система вычисляла меру близости по выражению и в соответствии с полученными значениями ранжировала информационный массив. Практически все ИПС в интернете устроены по этому принципу. Единственным исключением является применение более сложных мер близости.
Коррекция запросов по релевантности
Другим важным способом улучшения качества поиска в информационно-поисковых системах Internet стала процедура коррекции запроса по релевантности. Пионером здесь также выступила система WAIS. Пользователю предоставлялась возможность отметить документы, которые являлись релевантными его запросу. После этого запрос расширялся терминами этих документов и снова вычислялось выражение (2.1) для поисковых образов документов всего массива. В рамках линейной модели индексирования и поиска эта процедура может быть также выражена через матричные выражения.
В литературе по информационному поиску часто можно встретить термин "профиль", который относят к запросам пользователей. Но информационный профиль или тематический профиль имеется и у информационной системы. Наиболее просто тематический профиль системы материализуется в виде классификации, которая применяется в данной системе или рубрикаторе. Не исключение и информационные системы интернета, в которых профиль играет еще и роль навигационного средства, позволяющего получить доступ непосредственно к набору документов, попадающих в тот или иной раздел классификации. При этом многие системы интернета имеют несколько профилей, которые могут быть соотнесены с фасетной классификацией.
Естественно, что при таком положении дел в моделях, предназначенных для описания работы ИПС так же должно быть введено понятие профиля и выявлена его актуальность для информационного поиска.
Определим операцию расширения запроса как:
LT x r0 = q1(2.2)
В данном выражении LT - это транспонированная матрица L. Однако, это не совсем точно. Обычно пользователь не использует свое право отметки релевантных документов и только их термины используются в расширенном запросе или получают больший вес перед терминами других документов. Поэтому в выражение (2.2) надо ввести еще матрицу - F, призванную учитывать фактор пользователя.
LT x Fk-1 x rk-1 = qk(2.3)
L x qk = rk;
Как видно из (2.3) матрицы Fk-1 составляют систему фильтров пользователя, при помощи которых он корректирует свой запрос. Эти фильтры имеют в реальных системах конкретную интерпретацию. Так в WAIS и Lycos пользователь просто помечает релевантные документы. В этом случае фильтры превращаются в диагональные матрицы, которые в релевантных документах имеют главную диагональ с единицами, а в нерелевантных - с нули. Но, в общем случае, на диагонали можно размещать и веса релевантности. Эти фильтры могут быть и недиагональными. В этом случае пользователь будет взвешивать документы не только самостоятельно, но и с учетом их связи с другими документами массива, как релевантными, так и нерелевантными, например с учетом его гипертекстовых связей. Но в любом случае совершенно естественно предположить, что система предпочтений пользователя в течение одной сессии работы с ИПС остается неизменной, иначе пользователь просто не знает, что же он в самом деле ищет. Тогда все фильтры одинаковы и не изменяются от шага к шагу:
F0 = F1 = F2 = ... = Fk-1 = Fk = F (2.4)
В конечном итоге, если пользователь просто переберет все документы массива, то можно составить диагональную матрицу, например, состоящую из нулей и единиц.
Процесс коррекции запроса не бывает бесконечным. Обычно он завершается, когда пользователь устает просматривать найденные документы, и приходит к выводу, что нашел искомое, либо действительно больше нет новых релевантных документов. В принципе, даже при прямом просмотре, второй результат является концом процедуры поиска информации. Это значит, что начиная с некоторого вектора отклика этот самый отклик не изменяется:
(L x LT x F) x rk-1 = rk; (2.5)
(A x F) x r = lr:rk = lrk-1.
Из (2.5) следует, что процесс коррекции запросов по релевантности должен сходиться к собственному вектору матрицы ( L x LT x F). Если при этом пользователь хочет добиться максимального различия документов по степени релевантности, которая фактически определяется значениями компонентов вектора r, тогда речь идет о собственном векторе при максимальном собственном числе. Аналогичный результат можно получить и для набора терминов, которые характеризуют информационную потребность пользователя.
Однако, кроме профилей пользователя при моделировании взаимодействия пользователя и информационной системы. Существенную играет роль сам информационный массив, а точнее набор информационных образов документов массива, скажем, в ранжировании документов по степени релевантности. А именно об этом и идет речь в линейной модели индексирования и поиска информации. Чем ближе оказываются документы к информационной потребности пользователя, тем проще структура матрицы F. Идеальный случай, если эта матрица будет единичной - тогда пользователь вообще не нуждается в ручной коррекции, а система сама проранжирует все документы.
Приведенная трактовка процедуры коррекции запроса и профиля информационной системы имеет аналоги в других методах анализа информационных потоков. Если надо различить какие-либо группы пользователей по их тематике с применением некоторой информационной структуры, то можно прибегнуть к факторному анализу статистики посещения страниц. В этом случае главные компоненты будут задаваться собственными векторами корреляционной матрицы, которая позволяет определить направление максимального разброса показателей посещений, что соответствует собственному вектору при максимальном собственном числе.
Похожие работы
... проекта. В этом случае редактор кода вызывается кнопкой View Code (Просмотр кода) панели инструментов окна Проводника. 2.3 Характеристика программы Данная программа написана на языке Visual Basic 6.0 и представляет собой 1 приложением, предназначенных выполнять все функции, которые требуются заданию. В конечный продукт входит 1 откомпилированное приложения, размер которого составляет ...
... ЛС (отбор жизненно важных ЛС, обеспечение их безопасности и качества, рациональное применение и т.д.) зафиксированы далеко не все из средств, имеющихся в арсенале управления, организации и экономики производства, и основное внимание сосредоточено на конечных результатах, а не на действиях по их достижению. Государственный комитет Основными целями деятельности Государственного комитета являются ...
0 комментариев