Навигация
1. Основные понятия.
С целью математического описания конкретного вида зависимостей с использованием регрессионного анализа подбирают класс функций, связывающих результативный показатель y и аргументы x1, x2,…,хk , отбирают наиболее информативные аргументы, вычисляют оценки неизвестных значений параметров уравнения связи и анализируют точность полученного уравнения.[8]
Функция f(x1, x2,…,хk ), описывающая зависимость условного среднего значения результативного признака у от заданных значений аргументов, называется функцией (уравнением) регрессии.
Термин "регрессия" (лат. - "regression" - отступление, возврат к чему-либо) введен английским психологом и антропологом Ф.Гальтпном и связан только со спецификой одного из первых конкретных примеров, в котором это понятие было использовано.
Обрабатывая статистические данные в связи с вопросом о наследственности роста, Ф.Гальтон нашел, что если отцы отклоняются от среднего роста всех отцов на x дюймов, то их сыновья отклоняются от среднего роста всех сыновей меньше, чем на x дюймов. Выявленная тенденция была названа «регрессией к среднему состоянию». Задача регрессионного анализа состоит в построении модели, позволяющей по значениям независимых показателей получать оценки значений зависимой переменной. Регрессионный анализ является основным средством исследования зависимостей между социально-экономическими переменными. Эту задачу мы рассмотрим в рамках самой распространенной в статистических пакетах классической модели линейной регрессии. Специфика социологических исследований состоит в том, что очень часто необходимо изучать и предсказывать социальные события. Вторая часть данной главы будет посвящена регрессии, целью которой является построение моделей, предсказывающих вероятности событий. Величина называется ошибкой регрессии. Первые математические результаты, связанные с регрессионным анализом, сделаны в предположении, что регрессионная ошибка распределена нормально с параметрами, ошибка для различных объектов считаются независимыми. Кроме того, в данной модели мы рассматриваем переменные как неслучайные значения. Такое, на практике, получается, когда идет активный эксперимент, в котором задают значения (например, назначили зарплату работнику), а затем измеряют (оценили, какой стала производительность труда).
Для точного описания уравнения регрессии необходимо знать условный закон распределения результативного показателя у. В статистической практике такую информацию получить обычно не удается, поэтому ограничиваются поиском подходящих аппроксимаций для функции f( x1, x2,…,хk ), основанных на исходных статистических данных.
В рамках отдельных модельных допущений о типе распределения вектора показателей (у, x1, x2,…,хk ) может быть получен общий вид уравнения регрессии f(x)=M(y/x) x=( x1, x2,…,хk )![]() . Например, в предложении, что исследуемая совокупность показателей подчиняется (k + 1) - мерному нормальному закону распределения с вектором математических ожиданий
. Например, в предложении, что исследуемая совокупность показателей подчиняется (k + 1) - мерному нормальному закону распределения с вектором математических ожиданий
M =![]() ,
,
где Mx = ![]() , my = MY
, my = MY
и ковариационной матрицей S = 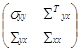 ,
,
где syy = s2у = M (y-My)![]() ;
;
S yx = ![]() ; S xx =
; S xx = 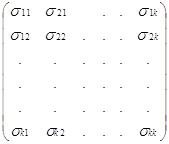 ;
;
s ij = M (xi – Mxi);(xj – Mxj); sjj = sj![]() = M (xj – Mxj)
= M (xj – Mxj)![]() .[12]
.[12]
Из этого следует, что уравнение регрессии (условное математическое ожидание) имеет вид:
M(y/x) = my + ![]() (x - Mx).
(x - Mx).
Таким образом, если многомерная случайная величина (у, x1, x2,…,хk ) подчиняется (k +1)-мерному нормальному закону распределения, то уравнение регрессии результативного показателя у по объясняющим переменным x1, x2,…,хk имеет линейный по х вид. Метод включения и исключения переменных состоит в следующем. Из множества факторов, рассматриваемых исследователем как возможные аргументы регрессионного уравнения, отбирается один, который более всего связан корреляционной зависимостью. Далее проводится та же процедура при двух выбранных переменных, при трех и т.д. Процедура повторяется до тех пор, пока в уравнение не будут включены все аргументы выделенные исследователем, удовлетворяющие критериям значимости включения. Замечание: во избежание зацикливания процесса включения исключения значимость включения устанавливается меньше значимости исключения. Переменные, порождаемые регрессионным уравнением. Сохранение переменных, порождаемых регрессией, производится подкомандой. Благодаря полученным оценкам коэффициентов уравнения регрессии могут быть оценены прогнозные значения зависимой переменной, причем они могут быть вычислены и там, где значения определены, и там где они не определены.
Однако в статистической практике обычно приходится ограничиваться поиском подходящих аппроксимаций для неизвестной истинной функции регрессии f(x), так как исследователь не располагает точным знанием условного закона распределения вероятностей анализируемого результатирующего показателя у при заданных эначениях аргументов х=х.
Рассмотрим взаимоотношение между истиной f(х)= M(y/x), модельной у и оценкой у регрессии. Однако при небольшой взаимосвязи между переменными, если стандартизовать переменные и рассчитать уравнение регрессии для стандартизованных переменных, то оценки коэффициентов регрессии позволят по их абсолютной величине судить о том, какой аргумент в большей степени влияет на функцию. Стандартизация переменных. Бета коэффициенты. Коэффициенты в последнем уравнении получены при одинаковых масштабах изменения всех переменных и сравнимы. В случае взаимосвязи между аргументами в правой части уравнения могут происходить странные вещи. Надежность и значимость коэффициента регрессии. Здесь обозначен коэффициент детерминации, получаемый при построении уравнения регрессии, в котором в качестве зависимой переменной взята другая переменная. Из выражения видно, что величина коэффициента тем неустойчивее, чем сильнее переменная связана с остальными переменными. Эта статистика имеет распределение Стьюдента. В выдаче пакета печатается наблюдаемая ее двусторонняя значимость - вероятность случайно при нулевом регрессионном коэффициенте получить значение статистики, большее по абсолютной величине, чем выборочное. Значимость включения переменной в регрессию. При последовательном подборе переменных предусмотрена автоматизация, основанная на значимости включения и исключения переменных.
Пусть результативный показатель у связан с аргументом х соотношением::
y
= ![]() + e ,
+ e ,
где e - случайная величина, имеющая нормальный закон распределения, причем М e = 0 и
D e = ![]() .
.
Истинная функция регрессии в этом случае имеет вид:
F(x) = M(y/x) = 2x![]() .
.
Предположим, что точный вид истинного уравнения регрессии нам не известен, но мы располагаем девятъю наблюдениями над двумерной случайной величиной, связанной соотношением уi = 2x![]() + ei, и предcтавленной на рисунке:
+ ei, и предcтавленной на рисунке:
![]() у
у
|

![]() 60
60
![]() 50
50
|
![]()
![]() 30
30
![]() 20
20
![]()
![]()
![]()
![]()
![]()
![]() 10
10
|
0 2 4 6 8 10
Взаимное расположение истинной f(x) и теоритической у модели регрессии.
Расположение точек на рисунке позволяет ограничиться классом линейных зависимостей вида: у = b0 + b1 x.[2]
С помощью метода наименьших квадратов найдем оценку уравнения регрессии
у = b0 +b1 x.
Дли сравнения на рисунке приводятся графики истинной функции регрессии f{х) =2x![]() , теоретической аппроксимирующей функции регрессии
, теоретической аппроксимирующей функции регрессии ![]() = b0 + b1 x. К последней сходится по вероятности оценка уравнения регрессии
= b0 + b1 x. К последней сходится по вероятности оценка уравнения регрессии ![]() при неограниченном увеличении объема выборки (n
при неограниченном увеличении объема выборки (n ![]() ).
).
Поскольку мы ошиблись в выборе класса функции регрессии, что, к сожалению, достаточно часто встречается в практике статистических исследований, то наши статистические выводы и оценки не будут обладать свойством состоятельности, т.е., как бы
мы не увеличивали объем наблюдений, наша выборочная оценка ![]() не будет сходиться к истинной функции регрессии f(х). Задача регрессионного анализа состоит в построении модели, позволяющей по значениям независимых показателей получать оценки значений зависимой переменной. Регрессионный анализ является основным средством исследования зависимостей между социально-экономическими переменными. Эту задачу мы рассмотрим в рамках самой распространенной в статистических пакетах классической модели линейной регрессии. Специфика социологических исследований состоит в том, что очень часто необходимо изучать и предсказывать социальные события. Вторая часть данной главы будет посвящена регрессии, целью которой является построение моделей, предсказывающих вероятности событий. Величина называется ошибкой регрессии. Первые математические результаты, связанные с регрессионным анализом, сделаны в предположении, что регрессионная ошибка распределена нормально с параметрами, ошибка для различных объектов считаются независимыми. Кроме того, в данной модели мы рассматриваем переменные как неслучайные значения. Такое, на практике, получается, когда идет активный эксперимент, в котором задают значения (например, назначили зарплату работнику), а затем измеряют (оценили, какой стала производительность труда).
не будет сходиться к истинной функции регрессии f(х). Задача регрессионного анализа состоит в построении модели, позволяющей по значениям независимых показателей получать оценки значений зависимой переменной. Регрессионный анализ является основным средством исследования зависимостей между социально-экономическими переменными. Эту задачу мы рассмотрим в рамках самой распространенной в статистических пакетах классической модели линейной регрессии. Специфика социологических исследований состоит в том, что очень часто необходимо изучать и предсказывать социальные события. Вторая часть данной главы будет посвящена регрессии, целью которой является построение моделей, предсказывающих вероятности событий. Величина называется ошибкой регрессии. Первые математические результаты, связанные с регрессионным анализом, сделаны в предположении, что регрессионная ошибка распределена нормально с параметрами, ошибка для различных объектов считаются независимыми. Кроме того, в данной модели мы рассматриваем переменные как неслучайные значения. Такое, на практике, получается, когда идет активный эксперимент, в котором задают значения (например, назначили зарплату работнику), а затем измеряют (оценили, какой стала производительность труда).
Если бы мы правильно выбрали класс функций регрессии, то неточность в описании f(x) с помощью ![]() объяснялась бы только ограниченностью выборки и, следовательно, она могла бы быть сделана сколько угодно малой при n
объяснялась бы только ограниченностью выборки и, следовательно, она могла бы быть сделана сколько угодно малой при n ![]() .
.
С целью наилучшего восстановления по исходным статистическим данным условного значения результатирующего показателя у(х) и неизвестной функции регрессии f(x) = M(y/x) наиболее часто используют следующие критерии адекватности (функции потерь).[7]
1. Метод наименьших квадратов, согласно которому минимизируется квадрат отклонения наблюдаемых значений результативного показателя yi(i=1,2,…,n) от модельных значений ![]() i = f(xi, b), где b = (b0, b1,…,bk)
i = f(xi, b), где b = (b0, b1,…,bk)![]() - коэффициенты уравнения регрессии, xi – значение вектора аргументов в i-м наблюдении:
- коэффициенты уравнения регрессии, xi – значение вектора аргументов в i-м наблюдении:
![]() .
.
Решается задача отыскания оценки ![]() вектора b. Получаемая регрессия называется среднеквадратической. За это иногда зависимую переменную называют откликом. Теория регрессионных уравнений со случайными независимыми переменными сложнее, но известно, что, при большом числе наблюдений, использование метода разработанного корректно. Для получения оценок коэффициентов регрессии минимизируется сумма квадратов ошибок регрессии. В пакете вычисляются статистики, позволяющие решить эти задачи. Существует ли линейная регрессионная зависимость? Для проверки одновременного отличия всех коэффициентов регрессии от нуля проведем анализ квадратичного разброса значений зависимой переменной относительно среднего. Его можно разложить на две суммы следующим образом. Статистика в условиях гипотезы равенства нулю регрессионных коэффициентов имеет распределение Фишера и, естественно, по этой статистике проверяют, являются ли коэффициенты одновременно нулевыми. Коэффициенты детерминации и множественной корреляции. При сравнении качества регрессии, оцененной по различным зависимым переменным, полезно исследовать доли объясненной и необъясненной дисперсии. Корень из коэффициента детерминации называется коэффициентом корреляции. Следует иметь в виду, что является смещенной оценкой. Абсолютные значения коэффициентов не позволяют сделать такой вывод.
вектора b. Получаемая регрессия называется среднеквадратической. За это иногда зависимую переменную называют откликом. Теория регрессионных уравнений со случайными независимыми переменными сложнее, но известно, что, при большом числе наблюдений, использование метода разработанного корректно. Для получения оценок коэффициентов регрессии минимизируется сумма квадратов ошибок регрессии. В пакете вычисляются статистики, позволяющие решить эти задачи. Существует ли линейная регрессионная зависимость? Для проверки одновременного отличия всех коэффициентов регрессии от нуля проведем анализ квадратичного разброса значений зависимой переменной относительно среднего. Его можно разложить на две суммы следующим образом. Статистика в условиях гипотезы равенства нулю регрессионных коэффициентов имеет распределение Фишера и, естественно, по этой статистике проверяют, являются ли коэффициенты одновременно нулевыми. Коэффициенты детерминации и множественной корреляции. При сравнении качества регрессии, оцененной по различным зависимым переменным, полезно исследовать доли объясненной и необъясненной дисперсии. Корень из коэффициента детерминации называется коэффициентом корреляции. Следует иметь в виду, что является смещенной оценкой. Абсолютные значения коэффициентов не позволяют сделать такой вывод.
2. Метод наименьших модулей, согласно которому минимизируется сумма абсолютных отклонений наблюдаемых значений результативного показателя от модульных значений ![]() = f(xi, b), т.е.
= f(xi, b), т.е.
![]() .
.
Получаемая регрессия называется среднеабсолютной (медианой).
3. Метод минимакса сводится к минимизации максимума модуля отклонения наблюдаемого значения результативного показателя yi от модельного значения f(xi, b), т.е.
![]() .
.
Получаемая при этом регрессия называется минимаксной. Рассмотрим, что представляет собой эта значимость. Обозначим коэффициент детерминации, полученный при исключении из правой части уравнения переменной. При этом мы получим уменьшение объясненной дисперсии, на величину. Для оценки значимости включения переменной используется статистика, имеющая распределение Фишера при нулевом теоретическом приросте. Вообще, если из уравнения регрессии исключаются переменных, статистикой значимости исключения будет. Пошаговая процедура построения модели. Основным критерием отбора аргументов должно быть качественное представление о факторах, влияющих на зависимую переменную, которую мы пытаемся смоделировать. Очень хорошо реализован процесс построения регрессионной модели: на машину переложена значительная доля трудностей в решении этой задачи. Возможно построение последовательное построение модели добавлением и удалением блоков переменных. Но мы рассмотрим только работу с отдельными переменными. По умолчанию программа включает все заданные переменные.
В практических положениях часто встречаются задачи, в которых изучается случайная величина у, зависящая от некоторого множества переменных x1, x2,…,хk и неизвестных параметров bj(j=0,1,2,…,k). Будем рассматривать (у, x1, x2,…,хk ) как
(k +1) – мерную генеральную совокупность, из которой взята случайная выборка объемов n, где (уi,xi1,xi2,…,xik) результат i-го наблюдения i=1,2,…,n. Требуется по результатам наблюдений оценить неизвестные параметры bj(j=0,1,2,…,k). [4]
Похожие работы
... модели меньше ошибка, но в первой лучше показатели качества регрессионного уравнения, более того, вторая модель неадекватна, т.е. не соответствует исходным данным и оценкам, полученным при помощи регрессионного анализа и регрессионная модель отражает анализируемые данные не точно. Следовательно, более точной является первая модель. Таким образом, модель зависимости уровня рентабельности от числа ...
... теперь на основе выше рассчитанного доверительный интервал: 3.Сравнительный анализ расчетов, произведенных с помощью формул Excel и с использованием «Пакета анализа» Если сравнивать между собой результаты, полученные при расчетах линейной и степенной регрессионной модели, то можно выделить следующее: 1. Значение b1 в линейной регрессионной модели < b1 в степенной регрессионной ...
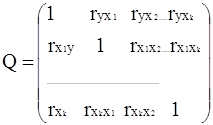
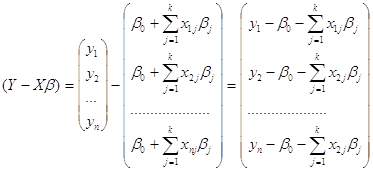
... 9472;───────┴─────────┘ Реализация алгоритма многомерного регрессионного анализа начинается с расчета важнейших статистических характеристик исходной информации и матрицы выборочных парных коэффициентов корреляции. Рассмотрим более подробно вариационные характеристики переменной у: ...
Использование корреляционно-регрессионного анализа для обработки экономических статистических данных
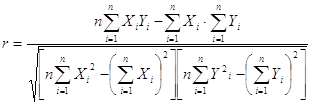
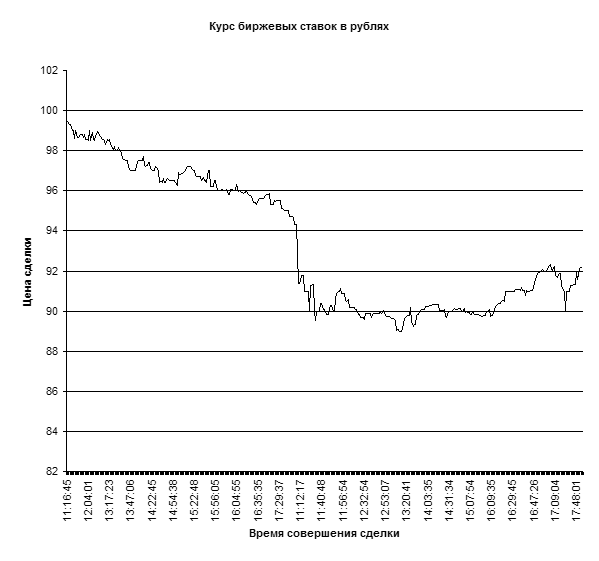
... быстро выполняемой счетной операцией. Данная работа посвящена изучению возможности обработки статистических данных биржевых ставок методами корреляционного и регрессионного анализа с использованием пакета прикладных программ Microsoft Excel. Роль корреляцонно-регрессионного анализа в обработке экономических данных Корреляционный анализ и регрессионный анализ являются смежными разделами ...
0 комментариев