Навигация
Статистическое моделирование связи методом корреляционного и регрессионного анализа
83374
знака
2
таблицы
16
изображений
1.3. Статистическое моделирование связи методом корреляционного и регрессионного анализа.
Задачи корреляционного анализа сводятся к измерению тесноты известной связи между варьирующими признаками, определению неизвестных причинных связей (причинный характер которых должен быть выяснен с помощью теоретического анализа) и оценки факторов, оказывающих наибольшее влияние на результативный признак. [4]
Задачами регрессионного анализа являются выбор типа модели (формы связи), установление степени влияния независимых переменных на зависимую и определение расчётных значений зависимой переменной (функции регрессии). Задача регрессионного анализа состоит в построении модели, позволяющей по значениям независимых показателей получать оценки значений зависимой переменной. Регрессионный анализ является основным средством исследования зависимостей между социально-экономическими переменными. Эту задачу мы рассмотрим в рамках самой распространенной в статистических пакетах классической модели линейной регрессии. Специфика социологических исследований состоит в том, что очень часто необходимо изучать и предсказывать социальные события. Вторая часть данной главы будет посвящена регрессии, целью которой является построение моделей, предсказывающих вероятности событий. Величина называется ошибкой регрессии. Первые математические результаты, связанные с регрессионным анализом, сделаны в предположении, что регрессионная ошибка распределена нормально с параметрами, ошибка для различных объектов считаются независимыми. Кроме того, в данной модели мы рассматриваем переменные как неслучайные значения. Такое, на практике, получается, когда идет активный эксперимент, в котором задают значения (например, назначили зарплату работнику), а затем измеряют (оценили, какой стала производительность труда).
Решение всех названных задач приводит к необходимости комплексного использования этих методов. Рассмотрим, что представляет собой эта значимость. Обозначим коэффициент детерминации, полученный при исключении из правой части уравнения переменной. При этом мы получим уменьшение объясненной дисперсии, на величину. Для оценки значимости включения переменной используется статистика, имеющая распределение Фишера при нулевом теоретическом приросте. Вообще, если из уравнения регрессии исключаются переменных, статистикой значимости исключения будет. Пошаговая процедура построения модели. Основным критерием отбора аргументов должно быть качественное представление о факторах, влияющих на зависимую переменную, которую мы пытаемся смоделировать. Очень хорошо реализован процесс построения регрессионной модели: на машину переложена значительная доля трудностей в решении этой задачи. Возможно построение последовательное построение модели добавлением и удалением блоков переменных. Но мы рассмотрим только работу с отдельными переменными. По умолчанию программа включает все заданные переменные.
Корреляционный и регрессионный анализ. Исследование связей в условиях массового наблюдения и действия случайных факторов осуществляется, как правило, с помощью экономико-статистических моделей. В широком смысле модель – это аналог, условный образ (изображение, описание, схема, чертёж и т.п.) какого-либо объекта, процесса или события, приближенно воссоздающий «оригинал». Модель представляет собой логическое или математическое описание компонентов и функций, отображающих существенные свойства моделируемого объекта или процесса, даёт возможность установить основные закономерности изменения оригинала. В модели оперируют показателями, исчисленными для качественно однородных массовых явлений (совокупностей). Выражение и модели в виде функциональных уравнений используют для расчёта средних значений моделируемого показателя по набору заданных величин и для выявления степени влияния на него отдельных факторов. Метод включения и исключения переменных состоит в следующем. Из множества факторов, рассматриваемых исследователем как возможные аргументы регрессионного уравнения, отбирается один, который более всего связан корреляционной зависимостью. Далее проводится та же процедура при двух выбранных переменных, при трех и т.д. Процедура повторяется до тех пор, пока в уравнение не будут включены все аргументы, выделенные исследователем, удовлетворяющие критериям значимости включения. Замечание: во избежание зацикливания процесса включения исключения значимость включения устанавливается меньше значимости исключения. Переменные, порождаемые регрессионным уравнением. Сохранение переменных, порождаемых регрессией, производится подкомандой. Благодаря полученным оценкам коэффициентов уравнения регрессии могут быть оценены прогнозные значения зависимой переменной, причем они могут быть вычислены и там, где значения определены, и там где они не определены.
По количеству включаемых факторов модели могут быть однофакторными и многофакторными (два и более факторов).
В зависимости от познавательной цели статистические модели подразделяются на структурные, динамические и модели связи.
Двухмерная линейная модель корреляционного и регрессионного анализа (однофакторный линейный корреляционный и регрессионный анализ). Наиболее разработанной в теории статистики является методология так называемой парной корреляции, рассматривающая влияние вариации факторного анализа х на результативный признак у и представляющая собой однофакторный корреляционный и регрессионный анализ. Овладение теорией и практикой построения и анализа двухмерной модели корреляционного и регрессионного анализа представляет собой исходную основу для изучения многофакторных стохастических связей. Однако при небольшой взаимосвязи между переменными, если стандартизовать переменные и рассчитать уравнение регрессии для стандартизованных переменных, то оценки коэффициентов регрессии позволят по их абсолютной величине судить о том, какой аргумент в большей степени влияет на функцию. Стандартизация переменных. Бета коэффициенты. Коэффициенты в последнем уравнении получены при одинаковых масштабах изменения всех переменных и сравнимы. В случае взаимосвязи между аргументами в правой части уравнения могут происходить странные вещи. Надежность и значимость коэффициента регрессии. Здесь обозначен коэффициент детерминации, получаемый при построении уравнения регрессии, в котором в качестве зависимой переменной взята другая переменная. Из выражения видно, что величина коэффициента тем неустойчивее, чем сильнее переменная связана с остальными переменными. Эта статистика имеет распределение Стьюдента. В выдаче пакета печатается наблюдаемая ее двусторонняя значимость - вероятность случайно при нулевом регрессионном коэффициенте получить значение статистики, большее по абсолютной величине, чем выборочное. Значимость включения переменной в регрессию. При последовательном подборе переменных предусмотрена автоматизация, основанная на значимости включения и исключения переменных.
Важнейшим этапом построения регрессионной модели (уравнения регрессии) является установление в анализе исходной информации математической функции. Сложность заключается в том, что из множества функций необходимо найти такую, которая лучше других выражает реально существующие связи между анализируемыми признаками. Выбор типов функции может опираться на теоретические знания об изучаемом явлении, опят предыдущих аналогичных исследований, или осуществляться эмпирически – перебором и оценкой функций разных типов и т.п. [10]
При изучении связи экономических показателей производства (деятельности) используют различного вида уравнения прямолинейной и криволинейной связи. Внимание к линейным связям объясняется ограниченной вариацией переменных и тем, что в большинстве случаев нелинейные формы связи для выполнения расчётов преобразуют (путём логарифмирования или замены переменных) в линейную форму. Уравнение однофакторной (парной) линейной корреляционной связи имеет вид:
ŷ = a0 + a1x ,
где ŷ - теоретические значения результативного признака, полученные по уравнению регрессии;
a0 , a1 - коэффициенты (параметры) уравнения регрессии. Задача регрессионного анализа состоит в построении модели, позволяющей по значениям независимых показателей получать оценки значений зависимой переменной. Регрессионный анализ является основным средством исследования зависимостей между социально-экономическими переменными. Эту задачу мы рассмотрим в рамках самой распространенной в статистических пакетах классической модели линейной регрессии. Специфика социологических исследований состоит в том, что очень часто необходимо изучать и предсказывать социальные события. Вторая часть данной главы будет посвящена регрессии, целью которой является построение моделей, предсказывающих вероятности событий. Величина называется ошибкой регрессии. Первые математические результаты, связанные с регрессионным анализом, сделаны в предположении, что регрессионная ошибка распределена нормально с параметрами, ошибка для различных объектов считаются независимыми. Кроме того, в данной модели мы рассматриваем переменные как неслучайные значения. Такое, на практике, получается, когда идет активный эксперимент, в котором задают значения (например, назначили зарплату работнику), а затем измеряют (оценили, какой стала производительность труда).
Поскольку a0 является средним значением у в точке х=0, экономическая интерпретация часто затруднена или вообще невозможна. За это иногда зависимую переменную называют откликом. Теория регрессионных уравнений со случайными независимыми переменными сложнее, но известно, что, при большом числе наблюдений, использование метода разработанного корректно. Для получения оценок коэффициентов регрессии минимизируется сумма квадратов ошибок регрессии. В пакете вычисляются статистики, позволяющие решить эти задачи. Существует ли линейная регрессионная зависимость? Для проверки одновременного отличия всех коэффициентов регрессии от нуля проведем анализ квадратичного разброса значений зависимой переменной относительно среднего. Его можно разложить на две суммы следующим образом. Статистика в условиях гипотезы равенства нулю регрессионных коэффициентов имеет распределение Фишера и, естественно, по этой статистике проверяют, являются ли коэффициенты одновременно нулевыми. Коэффициенты детерминации и множественной корреляции. При сравнении качества регрессии, оцененной по различным зависимым переменным, полезно исследовать доли объясненной и необъясненной дисперсии. Корень из коэффициента детерминации называется коэффициентом корреляции. Следует иметь в виду, что является смещенной оценкой. Абсолютные значения коэффициентов не позволяют сделать такой вывод.
Коэффициент парной линейной регрессии a1 имеет смысл показателя силы связи между вариацией факторного признака х и вариацией результативного признака у. Вышеприведенное уравнение показывает среднее значение изменения результативного признака у при изменении факторного признака х на одну единицу его измерения, то есть вариацию у, приходящуюся на единицу вариации х. Знак a1 указывает направление этого изменения.
Параметры уравнения a0 , a1 находят методом наименьших квадратов (метод решения систем уравнений, при котором в качестве решения принимается точка минимума суммы квадратов отклонений), то есть в основу этого метода положено требование минимальности сумм квадратов отклонений эмпирических данных yi от выравненных ŷ :
S(yi – ŷ)2 = S(yi – a0 – a1xi)2 ® min [9]
Для нахождения минимума данной функции приравняем к нулю ее частные производные и получим систему двух линейных уравнений, которая называется системой нормальных уравнений:
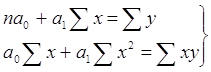
.
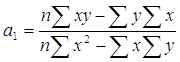 |
Решим эту систему в общем виде:
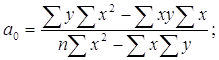
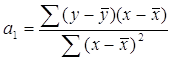 | 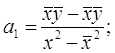 | ||||
Параметры уравнения парной линейной регрессии иногда удобно исчислять по следующим формулам, дающим тот же результат:
Определив значения a0 , a1 и подставив их в уравнение связи ŷ = a0 + a1x , находим значения ŷ , зависящие только от заданного значения х.
Рассмотрим построение однофакторного уравнения регрессии зависимости работающих активов у от капитала х (см. таблица 1). Рассмотрим, что представляет собой эта значимость. Обозначим коэффициент детерминации, полученный при исключении из правой части уравнения переменной. При этом мы получим уменьшение объясненной дисперсии, на величину. Для оценки значимости включения переменной используется статистика, имеющая распределение Фишера при нулевом теоретическом приросте. Вообще, если из уравнения регрессии исключаются переменных, статистикой значимости исключения будет. Пошаговая процедура построения модели. Основным критерием отбора аргументов должно быть качественное представление о факторах, влияющих на зависимую переменную, которую мы пытаемся смоделировать. Очень хорошо реализован процесс построения регрессионной модели: на машину переложена значительная доля трудностей в решении этой задачи. Возможно построение последовательное построение модели добавлением и удалением блоков переменных. Но мы рассмотрим только работу с отдельными переменными. По умолчанию программа включает все заданные переменные.
Здесь представлены показатели 32 банков: размер капитала и работающих активов. Передо мной стоит задача определить, есть ли зависимость между этими двумя признаками и, если она существует, определить форму этой зависимости, то есть уравнение регрессии.
За факторный признак я взяла размер капитала банка, а за результативный признак – работающие активы. [11]
Сопоставление данных параллельных рядов признаков х и у показывает, что с убыванием признака х (капитал), в большинстве случаев убывает и признак у (работающие активы). Задача регрессионного анализа состоит в построении модели, позволяющей по значениям независимых показателей получать оценки значений зависимой переменной. Регрессионный анализ является основным средством исследования зависимостей между социально-экономическими переменными. Эту задачу мы рассмотрим в рамках самой распространенной в статистических пакетах классической модели линейной регрессии. Специфика социологических исследований состоит в том, что очень часто необходимо изучать и предсказывать социальные события. Вторая часть данной главы будет посвящена регрессии, целью которой является построение моделей, предсказывающих вероятности событий. Величина называется ошибкой регрессии. Первые математические результаты, связанные с регрессионным анализом, сделаны в предположении, что регрессионная ошибка распределена нормально с параметрами, ошибка для различных объектов считаются независимыми. Кроме того, в данной модели мы рассматриваем переменные как неслучайные значения. Такое, на практике, получается, когда идет активный эксперимент, в котором задают значения (например, назначили зарплату работнику), а затем измеряют (оценили, какой стала производительность труда).
Следовательно, можно предположить, что между х и у существует прямая зависимость, пусть неполная, но выраженная достаточно ясно.
Для уточнения формы связи между рассматриваемыми признаками я использовала графический метод. Я нанес на график точки, соответствующие значениям х и у, и получила корреляционное поле (см. график 1). Метод включения и исключения переменных состоит в следующем. Из множества факторов, рассматриваемых исследователем как возможные аргументы регрессионного уравнения, отбирается один, который более всего связан корреляционной зависимостью. Далее проводится та же процедура при двух выбранных переменных, при трех и т.д. Процедура повторяется до тех пор, пока в уравнение не будут включены все аргументы, выделенные исследователем, удовлетворяющие критериям значимости включения. Замечание: во избежание зацикливания процесса включения исключения значимость включения устанавливается меньше значимости исключения. Переменные, порождаемые регрессионным уравнением. Сохранение переменных, порождаемых регрессией, производится подкомандой. Благодаря полученным оценкам коэффициентов уравнения регрессии могут быть оценены прогнозные значения зависимой переменной, причем они могут быть вычислены и там, где значения определены, и там где они не определены.
Анализируя поле корреляции, можно предположить, что возрастание признака у идет пропорционально признаку х. В основе этой зависимости лежит прямолинейная связь, которая может быть выражена простым линейным уравнением регрессии:
ŷ = a0 + a1x,
где ŷ - теоретические расчётные значения результативного признака (работающие активы), полученные по уравнению регрессии;
a0 , a1 - коэффициенты (параметры) уравнения регрессии;
х – капитал исследуемых банков.
Пользуясь вышеуказанными формулами для вычисления параметров линейного уравнения регрессии и расчётными значениями из таблицы 1, получаем:
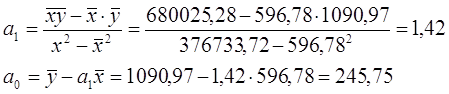
Следовательно, регрессионная модель зависимости работающих активов от капитала банков может быть записана в виде конкретного простого уравнения регрессии:
![]() .[4]
.[4]
Это уравнение характеризует зависимость работающих активов от капитала банка. Расчётные значения ŷ , найденные по этому уравнению, приведены в таблице 1. Правильность расчёта параметров уравнения регрессии может быть проверена сравниванием сумм ∑у = ∑ŷ . В моем случае эти суммы равны. Однако при небольшой взаимосвязи между переменными, если стандартизовать переменные и рассчитать уравнение регрессии для стандартизованных переменных, то оценки коэффициентов регрессии позволят по их абсолютной величине судить о том, какой аргумент в большей степени влияет на функцию. Стандартизация переменных. Бета коэффициенты. Коэффициенты в последнем уравнении получены при одинаковых масштабах изменения всех переменных и сравнимы. В случае взаимосвязи между аргументами в правой части уравнения могут происходить странные вещи. Надежность и значимость коэффициента регрессии. Здесь обозначен коэффициент детерминации, получаемый при построении уравнения регрессии, в котором в качестве зависимой переменной взята другая переменная. Из выражения видно, что величина коэффициента тем неустойчивее, чем сильнее переменная связана с остальными переменными. Эта статистика имеет распределение Стьюдента. В выдаче пакета печатается наблюдаемая ее двусторонняя значимость - вероятность случайно при нулевом регрессионном коэффициенте получить значение статистики, большее по абсолютной величине, чем выборочное. Значимость включения переменной в регрессию. При последовательном подборе переменных предусмотрена автоматизация, основанная на значимости включения и исключения переменных.
Но для того, чтобы применить мою формулу, надо рассчитать, насколько она приближенна к реальности, то есть проверить ее адекватность.
Похожие работы
... модели меньше ошибка, но в первой лучше показатели качества регрессионного уравнения, более того, вторая модель неадекватна, т.е. не соответствует исходным данным и оценкам, полученным при помощи регрессионного анализа и регрессионная модель отражает анализируемые данные не точно. Следовательно, более точной является первая модель. Таким образом, модель зависимости уровня рентабельности от числа ...
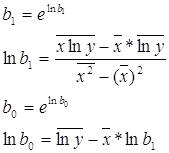
... теперь на основе выше рассчитанного доверительный интервал: 3.Сравнительный анализ расчетов, произведенных с помощью формул Excel и с использованием «Пакета анализа» Если сравнивать между собой результаты, полученные при расчетах линейной и степенной регрессионной модели, то можно выделить следующее: 1. Значение b1 в линейной регрессионной модели < b1 в степенной регрессионной ...
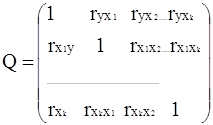
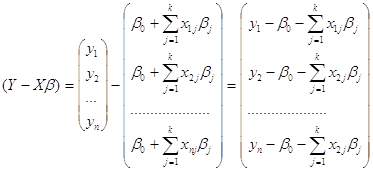
... 9472;───────┴─────────┘ Реализация алгоритма многомерного регрессионного анализа начинается с расчета важнейших статистических характеристик исходной информации и матрицы выборочных парных коэффициентов корреляции. Рассмотрим более подробно вариационные характеристики переменной у: ...
Использование корреляционно-регрессионного анализа для обработки экономических статистических данных
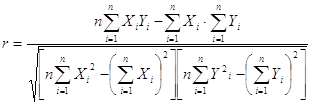
... быстро выполняемой счетной операцией. Данная работа посвящена изучению возможности обработки статистических данных биржевых ставок методами корреляционного и регрессионного анализа с использованием пакета прикладных программ Microsoft Excel. Роль корреляцонно-регрессионного анализа в обработке экономических данных Корреляционный анализ и регрессионный анализ являются смежными разделами ...
0 комментариев