Навигация
Проверка адекватности регрессионной модели
83374
знака
2
таблицы
16
изображений
2. Проверка адекватности регрессионной модели.
Для практического использования моделей регрессии большое значение имеет их адекватность, т.е. соответствие фактическим статистическим данным.
Корреляционный и регрессионный анализ обычно (особенно в условиях так называемого малого и среднего бизнеса) проводится для ограниченной по объёму совокупности. Поэтому показатели регрессии и корреляции – параметры уравнения регрессии, коэффициенты корреляции и детерминации могут быть искажены действием случайных факторов. Чтобы проверить, насколько эти показатели характерны для всей генеральной совокупности, не являются ли они результатом стечения случайных обстоятельств, необходимо проверить адекватность построенных статистических моделей.
При численности объектов анализа до 30 единиц возникает необходимость проверки значимости (существенности) каждого коэффициента регрессии. При этом выясняют насколько вычисленные параметры характерны для отображения комплекса условий: не являются ли полученные значения параметров результатами действия случайных причин. Задача регрессионного анализа состоит в построении модели, позволяющей по значениям независимых показателей получать оценки значений зависимой переменной. Регрессионный анализ является основным средством исследования зависимостей между социально-экономическими переменными. Эту задачу мы рассмотрим в рамках самой распространенной в статистических пакетах классической модели линейной регрессии. Специфика социологических исследований состоит в том, что очень часто необходимо изучать и предсказывать социальные события. Вторая часть данной главы будет посвящена регрессии, целью которой является построение моделей, предсказывающих вероятности событий. Величина называется ошибкой регрессии. Первые математические результаты, связанные с регрессионным анализом, сделаны в предположении, что регрессионная ошибка распределена нормально с параметрами, ошибка для различных объектов считаются независимыми. Кроме того, в данной модели мы рассматриваем переменные как неслучайные значения. Такое, на практике, получается, когда идет активный эксперимент, в котором задают значения (например, назначили зарплату работнику), а затем измеряют (оценили, какой стала производительность труда).
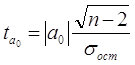 |
Значимость коэффициентов простой линейной регрессии (применительно к совокупностям, у которых n<30) осуществляют с помощью t-критерия Стьюдента. При этом вычисляют расчетные (фактические) значения t-критерия
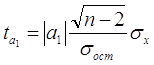 |
для параметра a0 :
для параметра a1 :
где n - объём выборки;
- среднее квадратическое отклонение результативного признака от выравненных значений ŷ ;
![]() или
или 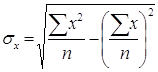
- среднее квадратическое отклонение факторного признака x от общей средней ![]() . [8]
. [8]
Вычисленные по вышеприведенным формулам значения сравнивают с критическими t , которые определяют по таблице Стьюдента с учетом принятого уровня значимости α и числом степеней свободы вариации ![]() . В социально-экономических исследованиях уровень значимости α обычно принимают равным 0,05. Параметр признаётся значимым (существенным) при условии, если tрасч> tтабл . В таком случае практически невероятно, что найденные значения параметров обусловлены только случайными совпадениями. За это иногда зависимую переменную называют откликом. Теория регрессионных уравнений со случайными независимыми переменными сложнее, но известно, что, при большом числе наблюдений, использование метода разработанного корректно. Для получения оценок коэффициентов регрессии минимизируется сумма квадратов ошибок регрессии. В пакете вычисляются статистики, позволяющие решить эти задачи. Существует ли линейная регрессионная зависимость? Для проверки одновременного отличия всех коэффициентов регрессии от нуля проведем анализ квадратичного разброса значений зависимой переменной относительно среднего. Его можно разложить на две суммы следующим образом. Статистика
в условиях гипотезы равенства нулю регрессионных коэффициентов имеет распределение Фишера и, естественно, по этой статистике проверяют, являются ли коэффициенты одновременно нулевыми. Коэффициенты детерминации и множественной корреляции. При сравнении качества регрессии, оцененной по различным зависимым переменным, полезно исследовать доли объясненной и необъясненной дисперсии. Корень из коэффициента детерминации называется коэффициентом корреляции. Следует иметь в виду, что является смещенной оценкой. Абсолютные значения коэффициентов не позволяют сделать такой вывод.
. В социально-экономических исследованиях уровень значимости α обычно принимают равным 0,05. Параметр признаётся значимым (существенным) при условии, если tрасч> tтабл . В таком случае практически невероятно, что найденные значения параметров обусловлены только случайными совпадениями. За это иногда зависимую переменную называют откликом. Теория регрессионных уравнений со случайными независимыми переменными сложнее, но известно, что, при большом числе наблюдений, использование метода разработанного корректно. Для получения оценок коэффициентов регрессии минимизируется сумма квадратов ошибок регрессии. В пакете вычисляются статистики, позволяющие решить эти задачи. Существует ли линейная регрессионная зависимость? Для проверки одновременного отличия всех коэффициентов регрессии от нуля проведем анализ квадратичного разброса значений зависимой переменной относительно среднего. Его можно разложить на две суммы следующим образом. Статистика
в условиях гипотезы равенства нулю регрессионных коэффициентов имеет распределение Фишера и, естественно, по этой статистике проверяют, являются ли коэффициенты одновременно нулевыми. Коэффициенты детерминации и множественной корреляции. При сравнении качества регрессии, оцененной по различным зависимым переменным, полезно исследовать доли объясненной и необъясненной дисперсии. Корень из коэффициента детерминации называется коэффициентом корреляции. Следует иметь в виду, что является смещенной оценкой. Абсолютные значения коэффициентов не позволяют сделать такой вывод.
 |
Теперь я рассчитаю t-критерий Стьюдента для моей модели регрессии.
- это средние квадратические отклонения.
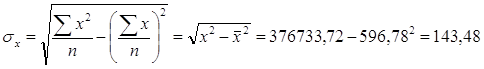
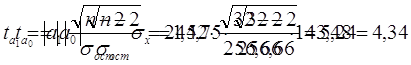 |
Расчетные значения t-критерия Стьюдента:
По таблице распределения Стьюдента я нахожу критическое значение t-критерия для ν= 32-2 = 30 . Вероятность α я принимаю 0,05. tтабл равно 2,042. Так как, оба значения ta0 и ta1 больше tтабл , то оба параметра а0 и а1 признаются значимыми и отклоняется гипотеза о том, что каждый из этих параметров в действительности равен 0 , и лишь в силу случайных обстоятельств оказался равным проверяемой величине.
Проверка адекватности регрессионной модели может быть дополнена корреляционным анализом. Для этого необходимо определить тесноту корреляционной связи между переменными х и у. Теснота корреляционной связи, как и любой другой, может быть измерена эмпирическим корреляционным отношением ηэ , когда δ2 (межгрупповая дисперсия) характеризует отклонения групповых средних результативного признака от общей средней:![]() .
.
Говоря о корреляционном отношении как о показателе измерения тесноты зависимости, следует отличать от эмпирического корреляционного отношения – теоретическое. Рассмотрим, что представляет собой эта значимость. Обозначим коэффициент детерминации, полученный при исключении из правой части уравнения переменной. При этом мы получим уменьшение объясненной дисперсии, на величину. Для оценки значимости включения переменной используется статистика, имеющая распределение Фишера при нулевом теоретическом приросте. Вообще, если из уравнения регрессии исключаются переменных, статистикой значимости исключения будет. Пошаговая процедура построения модели. Основным критерием отбора аргументов должно быть качественное представление о факторах, влияющих на зависимую переменную, которую мы пытаемся смоделировать. Очень хорошо реализован процесс построения регрессионной модели: на машину переложена значительная доля трудностей в решении этой задачи. Возможно построение последовательное построение модели добавлением и удалением блоков переменных. Но мы рассмотрим только работу с отдельными переменными. По умолчанию программа включает все заданные переменные.
Теоретическое корреляционное отношение η представляет собой относительную величину, получающуюся в результате сравнения среднего квадратического отклонения выравненных значений результативного признака δ, то есть рассчитанных по уравнению регрессии, со средним квадратическим отношением эмпирических (фактических) значений результативности признака σ:
![]() ,
,
где 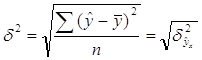 ;
; 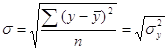 .
.
Тогда  . [2]
. [2]
Изменение значения η объясняется влиянием факторного признака. Метод включения и исключения переменных состоит в следующем. Из множества факторов, рассматриваемых исследователем как возможные аргументы регрессионного уравнения, отбирается один, который более всего связан корреляционной зависимостью. Далее проводится та же процедура при двух выбранных переменных, при трех и т.д. Процедура повторяется до тех пор, пока в уравнение не будут включены все аргументы, выделенные исследователем, удовлетворяющие критериям значимости включения. Замечание: во избежание зацикливания процесса включения исключения значимость включения устанавливается меньше значимости исключения. Переменные, порождаемые регрессионным уравнением. Сохранение переменных, порождаемых регрессией, производится подкомандой. Благодаря полученным оценкам коэффициентов уравнения регрессии могут быть оценены прогнозные значения зависимой переменной, причем они могут быть вычислены и там, где значения определены, и там где они не определены.
В основе расчёта корреляционного отношения лежит правило сложения дисперсий, то есть ![]() , где
, где ![]() - отражает вариацию у за счёт всех остальных факторов, кроме х , то есть являются остаточной дисперсией:
- отражает вариацию у за счёт всех остальных факторов, кроме х , то есть являются остаточной дисперсией:
![]()
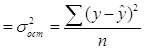 .
.
Тогда формула теоретического корреляционного отношения примет вид:
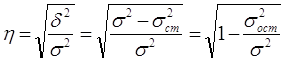 ,
,
или
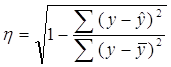 .
.
Подкоренное выражение корреляционного выражения представляет собой коэффициент детерминации (мера определенности, причинности).
Коэффициент детерминации показывает долю вариации результативного признака под влиянием вариации признака-фактора. Задача регрессионного анализа состоит в построении модели, позволяющей по значениям независимых показателей получать оценки значений зависимой переменной. Регрессионный анализ является основным средством исследования зависимостей между социально-экономическими переменными. Эту задачу мы рассмотрим в рамках самой распространенной в статистических пакетах классической модели линейной регрессии. Специфика социологических исследований состоит в том, что очень часто необходимо изучать и предсказывать социальные события. Вторая часть данной главы будет посвящена регрессии, целью которой является построение моделей, предсказывающих вероятности событий. Величина называется ошибкой регрессии. Первые математические результаты, связанные с регрессионным анализом, сделаны в предположении, что регрессионная ошибка распределена нормально с параметрами, ошибка для различных объектов считаются независимыми. Кроме того, в данной модели мы рассматриваем переменные как неслучайные значения. Такое, на практике, получается, когда идет активный эксперимент, в котором задают значения (например, назначили зарплату работнику), а затем измеряют (оценили, какой стала производительность труда).
Теоретическое корреляционное выражение применяется для измерения тесноты связи при линейной и криволинейной зависимостях между результативным и факторным признаком.
Как видно из вышеприведенных формул корреляционное отношение может находиться от 0 до 1. Чем ближе корреляционное отношение к 1, тем связь между признаками теснее.
Теоретическое корреляционное отношение применительно к моему анализу я рассчитаю двумя способами:

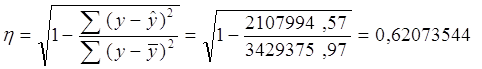 [5]
[5]
Полученное значение теоретического корреляционного отношения свидетельствует о возможном наличии среднестатистической связи между рассматриваемыми признаками. Коэффициент детерминации равен 0,62. Отсюда я заключаю, что 62% общей вариации работающих активов изучаемых банков обусловлено вариацией фактора – капитала банков (а 38% общей вариации нельзя объяснить изменением размера капитала).
Кроме того, при линейной форме уравнения применяется другой показатель тесноты связи – линейный коэффициент корреляции:
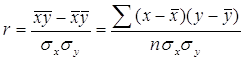 ,
,
где n – число наблюдений.
Для практических вычислений при малом числе наблюдений (n≤20÷30) линейный коэффициент корреляции удобнее исчислять по следующей формуле:
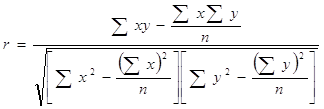 .
.
Значение линейного коэффициента корреляции важно для исследования социально-экономических явлений и процессов, распределение которых близко к нормальному. Он принимает значения в интервале: -1≤ r ≤ 1.
Отрицательные значения указывают на обратную связь, положительные – на прямую. При r = 0 линейная связь отсутствует. Чем ближе коэффициент корреляции по абсолютной величине к единице, тем теснее связь между признаками. И, наконец, при r = ±1 – связь функциональная. Задача регрессионного анализа состоит в построении модели, позволяющей по значениям независимых показателей получать оценки значений зависимой переменной. Регрессионный анализ является основным средством исследования зависимостей между социально-экономическими переменными. Эту задачу мы рассмотрим в рамках самой распространенной в статистических пакетах классической модели линейной регрессии. Специфика социологических исследований состоит в том, что очень часто необходимо изучать и предсказывать социальные события. Вторая часть данной главы будет посвящена регрессии, целью которой является построение моделей, предсказывающих вероятности событий. Величина называется ошибкой регрессии. Первые математические результаты, связанные с регрессионным анализом, сделаны в предположении, что регрессионная ошибка распределена нормально с параметрами, ошибка для различных объектов считаются независимыми. Кроме того, в данной модели мы рассматриваем переменные как неслучайные значения. Такое, на практике, получается, когда идет активный эксперимент, в котором задают значения (например, назначили зарплату работнику), а затем измеряют (оценили, какой стала производительность труда).
Используя данные таблицы 1 я рассчитала линейный коэффициент корреляции r. Но чтобы использовать формулу для линейного коэффициента корреляции рассчитаем дисперсию результативного признака σy:
![]()
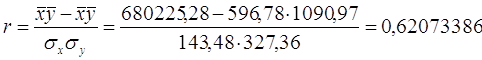
Квадрат линейного коэффициента корреляции r2 называется линейным коэффициентом детерминации. Из определения коэффициента детерминации очевидно, что его числовое значение всегда заключено в пределах от 0 до 1, то есть 0 ≤ r2 ≤ 1. Степень тесноты связи полностью соответствует теоретическому корреляционному отношению, которое является более универсальным показателем тесноты связи по сравнению с линейным коэффициентом корреляции. Однако при небольшой взаимосвязи между переменными, если стандартизовать переменные и рассчитать уравнение регрессии для стандартизованных переменных, то оценки коэффициентов регрессии позволят по их абсолютной величине судить о том, какой аргумент в большей степени влияет на функцию. Стандартизация переменных. Бета коэффициенты. Коэффициенты в последнем уравнении получены при одинаковых масштабах изменения всех переменных и сравнимы. В случае взаимосвязи между аргументами в правой части уравнения могут происходить странные вещи. Надежность и значимость коэффициента регрессии. Здесь обозначен коэффициент детерминации, получаемый при построении уравнения регрессии, в котором в качестве зависимой переменной взята другая переменная. Из выражения видно, что величина коэффициента тем неустойчивее, чем сильнее переменная связана с остальными переменными. Эта статистика имеет распределение Стьюдента. В выдаче пакета печатается наблюдаемая ее двусторонняя значимость - вероятность случайно при нулевом регрессионном коэффициенте получить значение статистики, большее по абсолютной величине, чем выборочное. Значимость включения переменной в регрессию. При последовательном подборе переменных предусмотрена автоматизация, основанная на значимости включения и исключения переменных.
Факт совпадений и несовпадений значений теоретического корреляционного отношения η и линейного коэффициента корреляции r используется для оценки формы связи. [4]
Выше отмечалось, что посредством теоретического корреляционного отношения измеряется теснота связи любой формы, а с помощью линейного коэффициента корреляции – только прямолинейной. Следовательно, значения η и r совпадают только при наличии прямолинейной связи. Несовпадение этих величин свидетельствует, что связь между изучаемыми признаками не прямолинейная, а криволинейная. Установлено, что если разность квадратов η и r не превышает 0,1 , то гипотезу о прямолинейной форме связи можно считать подтвержденной. В моем случае наблюдается примерное совпадение линейного коэффициента детерминации и теоретического корреляционного отношения, что дает мне основание считать связь между капиталом банков и их работающими активами прямолинейной.
При линейной однофакторной связи t-критерий можно рассчитать по формуле:
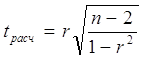 ,
,
где (n - 2) – число степеней свободы при заданном уровне значимости α и объеме выборки n. Задача регрессионного анализа состоит в построении модели, позволяющей по значениям независимых показателей получать оценки значений зависимой переменной. Регрессионный анализ является основным средством исследования зависимостей между социально-экономическими переменными. Эту задачу мы рассмотрим в рамках самой распространенной в статистических пакетах классической модели линейной регрессии. Специфика социологических исследований состоит в том, что очень часто необходимо изучать и предсказывать социальные события. Вторая часть данной главы будет посвящена регрессии, целью которой является построение моделей, предсказывающих вероятности событий. Величина называется ошибкой регрессии. Первые математические результаты, связанные с регрессионным анализом, сделаны в предположении, что регрессионная ошибка распределена нормально с параметрами, ошибка для различных объектов считаются независимыми. Кроме того, в данной модели мы рассматриваем переменные как неслучайные значения. Такое, на практике, получается, когда идет активный эксперимент, в котором задают значения (например, назначили зарплату работнику), а затем измеряют (оценили, какой стала производительность труда).
Так, для коэффициента корреляции между капиталом и работающими активами получается:
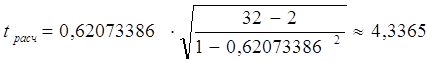
Если сравнить полученное tрасч с критическим значением из таблицы Стьюдента, где ν=30, а α=0,01 (tтабл=2,750), то полученное значение t-критерия будет больше табличного, что свидетельствует о значимости коэффициента корреляции и существенной связи между капиталом и работающими активами.
Таким образом, построенная регрессионная модель ŷ=245,75+1,42x в целом адекватна, и выводы полученные по результатам малой выборки можно с достаточной вероятностью распространить на всю гипотетическую генеральную совокупность. За это иногда зависимую переменную называют откликом. Теория регрессионных уравнений со случайными независимыми переменными сложнее, но известно, что, при большом числе наблюдений, использование метода разработанного корректно. Для получения оценок коэффициентов регрессии минимизируется сумма квадратов ошибок регрессии. В пакете вычисляются статистики, позволяющие решить эти задачи. Существует ли линейная регрессионная зависимость? Для проверки одновременного отличия всех коэффициентов регрессии от нуля проведем анализ квадратичного разброса значений зависимой переменной относительно среднего. Его можно разложить на две суммы следующим образом. Статистика в условиях гипотезы равенства нулю регрессионных коэффициентов имеет распределение Фишера и, естественно, по этой статистике проверяют, являются ли коэффициенты одновременно нулевыми. Коэффициенты детерминации и множественной корреляции. При сравнении качества регрессии, оцененной по различным зависимым переменным, полезно исследовать доли объясненной и необъясненной дисперсии. Корень из коэффициента детерминации называется коэффициентом корреляции. Следует иметь в виду, что является смещенной оценкой. Абсолютные значения коэффициентов не позволяют сделать такой вывод.
Похожие работы
... модели меньше ошибка, но в первой лучше показатели качества регрессионного уравнения, более того, вторая модель неадекватна, т.е. не соответствует исходным данным и оценкам, полученным при помощи регрессионного анализа и регрессионная модель отражает анализируемые данные не точно. Следовательно, более точной является первая модель. Таким образом, модель зависимости уровня рентабельности от числа ...
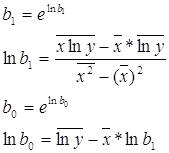
... теперь на основе выше рассчитанного доверительный интервал: 3.Сравнительный анализ расчетов, произведенных с помощью формул Excel и с использованием «Пакета анализа» Если сравнивать между собой результаты, полученные при расчетах линейной и степенной регрессионной модели, то можно выделить следующее: 1. Значение b1 в линейной регрессионной модели < b1 в степенной регрессионной ...
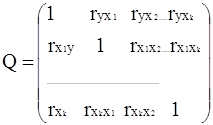
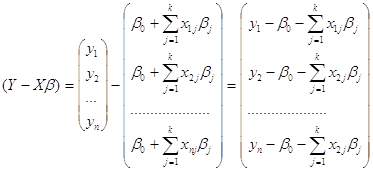
... 9472;───────┴─────────┘ Реализация алгоритма многомерного регрессионного анализа начинается с расчета важнейших статистических характеристик исходной информации и матрицы выборочных парных коэффициентов корреляции. Рассмотрим более подробно вариационные характеристики переменной у: ...
Использование корреляционно-регрессионного анализа для обработки экономических статистических данных
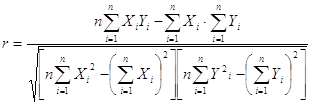
... быстро выполняемой счетной операцией. Данная работа посвящена изучению возможности обработки статистических данных биржевых ставок методами корреляционного и регрессионного анализа с использованием пакета прикладных программ Microsoft Excel. Роль корреляцонно-регрессионного анализа в обработке экономических данных Корреляционный анализ и регрессионный анализ являются смежными разделами ...
0 комментариев