Непозиционные и позиционные системы счисления
Докажем существование представления любого натурального числа в виде
Системы счисления с другими основаниями, их происхождение и применение
Умножение и деление
Перевод чисел из одной системы счисления в другую
ИСПОЛЬЗОВАНИЕ СИСТЕМ СЧИСЛЕНИЯ В КОМПЬЮТЕРНОЙ ТЕХНИКЕ И ИНФОРМАЦИОННЫХ ТЕХНОЛОГИЯХ
Способы построения двоичных кодов
Навигация
Способы построения двоичных кодов
Системы счисления и основы двоичных кодировок
54749
знаков
16
таблиц
10
изображений
2.3 Способы построения двоичных кодов
Начиная с конца 60-х годов, компьютеры все больше использовать для обработки текстовой информации и в настоящее время большая часть компьютеров в мире занято именно обработкой текстовой информации.
Традиционно для кодирования одного символа используется количество информации равное 1 байту, то есть 8 бит. Если рассматривать символы как возможные события, то получаем, что количество различных символов, которые можно закодировать, будет равно 256. Такое количество символов вполне достаточно для представления текстовой информации, включая прописные и строчные буквы русского и латинского алфавитов, а так же цифры, знаки препинания и математических операций, графические символы и так далее.
Но способов построения таких кодов очень много, рассмотрим некоторые из них:
Алфавитное неравномерное двоичное кодирование
При алфавитном способе двоичного кодирования символы некоторого первичного алфавита (например, русского) кодируются комбинациями символов двоичного алфавита (т.е. 0 и 1), причем, длина кодов и, соответственно, длительность передачи отдельного кода, могут различаться. Оптимизировать кодирование можно за счет суммарной длительности сообщения.
Суммарная длительность сообщения будет меньше, если применить следующий подход: чем буква первичного алфавита, встречается чаще, то присваиваем ей более короткой по длине код. Следовательно, коды букв, вероятность появления которых в сообщении выше, следует строить из возможно меньшего числа элементарных сигналов.
Возможны различные варианты двоичного кодирования, однако, не все они будут пригодны для практического использования - важно, чтобы закодированное сообщение могло быть однозначно декодировано, т.е. чтобы в последовательности 0 и 1, которая представляет собой многобуквенное кодированное сообщение, всегда можно было бы различить обозначения отдельных букв.
Рассмотрим пример построения двоичного кода для символов русского алфавита:
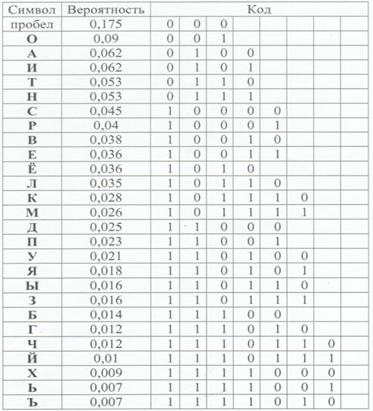
Неравномерный код с разделителями
Для того что бы было проще декодировать сообщения был придуман код с разделителями.
Проще всего достичь однозначного декодирования, если коды будут разграничены разделителем - некоторой постоянной комбинацией двоичных знаков. Условимся, что разделителем отдельных кодов букв будет последовательность 00 (признак конца знака), а разделителем слов - 000 (признак конца слова - пробел). Довольно очевидными оказываются следующие правила построения кодов:
— код признака конца знака может быть включен в код буквы, поскольку не существует отдельно (т.е. кода всех букв будут заканчиваться 00);
— коды букв не должны содержать двух и более нулей подряд в
середине (иначе они будут восприниматься как конец знака);
— код буквы (кроме пробела) всегда должен начинаться с 1;
— разделителю слов (000) всегда предшествует признак конца знака;
при этом реализуется последовательность 00000 (т.е. если в конце кода встречается комбинация ...000 или ...0000, они не воспринимаются как разделитель слов); следовательно, коды букв могут оканчиваться на 0 или 00 (до признака конца знака).
Длительность передачи каждого отдельного кода 4 очевидно, может быть найдена: ti = ki • τ, где ki - количество элементарных сигналов (бит) в коде символа L.
Алфавитное неравномерное двоичное кодирование. Префиксный код
Рассмотрев один из вариантов двоичного неравномерного кодирования, попробуем найти ответы на следующие вопросы: возможно ли такое кодирование без использования разделителя знаков? Существует ли наиболее оптимальный способ неравномерного двоичного кодирования?
Суть первой проблемы состоит в нахождении такого варианта кодирования сообщения, при котором последующее выделение из него каждого отдельного знака (т.е. декодирование) оказывается однозначным без специальных указателей разделения знаков. Наиболее простыми и употребимыми кодами такого типа являются так называемые префиксные коды, которые удовлетворяют следующему условию (условию Фано):
ииииииииииии
Неравномерный код может быть однозначно декодирован, если никакой из кодов не совпадает с началом какого-либо иного более длинного кода.
Например, если имеется код ПО, то уже не могут использоваться коды 1, 11, 1101, 110101 и пр. Если условие Фано выполняется, то при прочтении (расшифровке) закодированного сообщения путем сопоставления со списком кодов всегда можно точно указать, где заканчивается один код и начинается другой.
Пример: Пусть имеется следующая таблица префиксных кодов:
| а | л | м | р | у | ы |
| 10 | 010 | 00 | 11 | 0110 | 0111 |
Требуется декодировать сообщение: 00100010000111010101110000110. Декодирование производится циклическим повторением следующих действий:
1. отрезать от текущего сообщения крайний левый символ, присоединить к рабочему кодовому слову;
2. сравнить рабочее кодовое слово с кодовой таблицей; если совпадения нет, перейти к (1);
3. декодировать рабочее кодовое слово, очистить его;
4. проверить, имеются ли еще знаки в сообщении; если «да», перейти к (1).
Применение данного алгоритма дает:
| Шаг | Рабочее слово | Текущее сообщение | Распознанный знак | Декодированное сообщение |
| 0 | пусто | 00100010000111010101110000110 | - | - |
| 1 | 0 | 0100010000111010101110000110 | нет | - |
| 2 | 00 | 100010000111010101110000110 | м | М |
| 3 | 1 | 00010000111010101110000110 | нет | М |
| 4 | 10 | 0010000111010101110000110 | а | МА |
| 5 | 0 | 010000111010101110000110 | нет | МА |
| 6 | 00 | 10000111010101110000110 | м | Мам |
| • • • |
Доведя процедуру до конца, получим сообщение: «мама мыла раму».
Код Хаффмана
Способ оптимального префиксного двоичного кодирования был предложен Д.Хаффманом. Построение кодов Хаффмана мы рассмотрим на следующем примере: пусть имеется первичный алфавит А, состоящий из шести знаков a1…а6 с вероятностями появления в сообщении, соответственно, 0,3; 0,2; 0,2; 0,15; 0,1; 0,05. Создадим новый вспомогательный алфавит Аb объединив два знака с наименьшими вероятностями (а5 и а6) и заменив их одним знаком (например, а(1)); вероятность нового знака будет равна сумме вероятностей тех, что в него вошли, т.е. 0,15; остальные знаки исходного алфавита включим в новый без изменений; общее число знаков в новом алфавите, очевидно, будет на 1 меньше, чем в исходном. Аналогичным образом продолжим создавать новые алфавиты, пока в последнем не останется два знака; ясно, что число таких
шагов будет равно N - 2, где N - число знаков исходного алфавита (в нашем случае N = 6, следовательно, необходимо построить 4 вспомогательных алфавита). В промежуточных алфавитах каждый раз будем переупорядочивать знаки по убыванию вероятностей. Всю процедуру построения представим в виде таблицы:
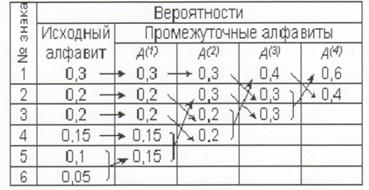
Теперь в обратном направлении поведем процедуру кодирования. Двум знакам последнего алфавита присвоим коды 0 и 1 (которому какой - роли не играет; условимся, что верхний знак будет иметь код 0, а нижний - 1). В нашем примере знак а1(4) алфавита А(4), имеющий вероятность 0,6 , получит код 0, а а2(4) с вероятностью 0,4 - код 1. В алфавите A(3) знак а1(3) с вероятностью 0,4 сохранит свой код (1); коды знаков a2(3) и a3(3), объединенных знаком a1(4) с вероятностью 0,6 , будут уже двузначным: их первой цифрой станет код связанного с ними знака (т.е. 0), а вторая цифра -как условились - у верхнего 0, у нижнего - 1; таким образом, а2(3) будет иметь код 00, a a3(3) - код 01. Полностью процедура кодирования
представлена в следующей таблице:
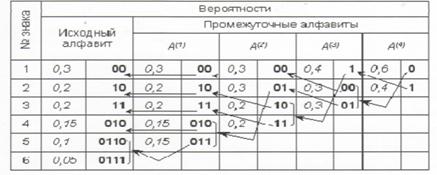
Из самой процедуры построения кодов легко видеть, что они удовлетворяют условию Фано и, следовательно, не требуют разделителя. Средняя длина кода при этом оказывается: К(2) = 0,3-2+0,2-2+0,2-2+0,15-3+0,1-4+0,05-4 = 2,45
Для сравнения можно найти I1{A)-она оказывается равной 2,409. что соответствует избыточности кода Q = 0,0169, т.е. менее 2%.
Код Хаффмана важен в теоретическом отношении, поскольку он является самым экономичным из всех возможных, т.е. ни для какого метода алфавитного кодирования длина кода не может оказаться меньше, чем код Хаффмана. Можно заключить, что существует метод построения оптимального неравномерного алфавитного кода. Метод Хаффмана и его модификация - метод адаптивного кодирования (динамическое кодирование Хаффмана) - нашли применение в программах-архиваторах, программах резервного копирования файлов и дисков, в системах сжатия информации в модемах и факсах.
Равномерное алфавитное двоичное кодирование. Байтовый код
В этом случае двоичный код первичного алфавита строится цепочками равной длины, т.е. со всеми знаками связано одинаковое количество информации равное 10. Передавать признак конца знака не требуется, поэтому для определения длины кодовой цепочки можно воспользоваться формулой: К(2) > log2N. Приемное устройство просто отсчитывает оговоренное заранее количество элементарных сигналов и интерпретирует цепочку (устанавливает, какому знаку она соответствует). Правда, при этом недопустимы сбои, например, пропуск (непрочтение) одного элементарного сигнала приведет к сдвигу всей кодовой последовательности и неправильной ее интерпретации; решается проблема путем синхронизации передачи или иными способами. С другой стороны, применение равномерного кода оказывается одним из средств контроля правильности передачи, поскольку факт поступления лишнего элементарного сигнала или, наоборот, поступление неполного кода сразу интерпретируется как ошибка.
Пример:
| Символ | Код |
| А | 00000001 |
| Б | 00000010 |
| В | 00000011 |
| Г | 00000100 |
| Д | 00000101 |
| Е | 00000110 |
| Ё | 00000111 |
| Ж | 00001000 |
ЗАКЛЮЧЕНИЕ
В кокой системе счисления лучше записывать числа - это вопрос удобства и традиций. С технической точки зрения, в ЭВМ удобно использовать двоичную систему, так как в ней для записи числа используется всего две цифры 0 и 1, которыми можно представить двумя легко различимыми состояниями «нет сигнала» и «есть сигнал».
Изучая источники по теме «Системы счисления» мы получили возможность провести исторический анализ, исследовать различные формы записи чисел, систематизировать материал и выявить различные спектры применения.
Различные системы счисления окружают нас повсюду. Сами того не замечая мы ежедневно пользуемся не только десятичной системой счисления, а так же двенадцатеричной, когда хотим узнать время или покупаем в магазине пуговицы.
Сейчас системы счисления очень распространены в электронно-вычислительной технике, многие коды и шифры созданы на их основе.
В ходе проведения исследования:
— исследовали историю и развитие систем счисления,
— исследовали практический материал
— рассмотрели область применения и выявили актуальность темы.
Нами решены задачи:
— арифметические действия в различных системах счисления,
— перевод из одной системы счисления в другую.
СПИСОК ЛИТЕРАТУРЫ
1. Алгебра и теория чисел: Учеб. пособие для студентов-заочников II курса физ.-мат. фак. пед. ин-тов (Н.А.Казачёк и др.) / Под ред. Н.Я. Виленкина - 2-е изд. М.: Просвещение, 1984. - 192 с.
2. Бендукидзе А.Д. О системах счисления // Квант - 1975 - №8 - с 59-61.
3.Берман Г.Н. Число и наука о нем. Общедоступные очерки по арифметики натуральных чисел. Изд. 3-е. М.: Физматгиз, 1960. - 164с.
4. Вайман А.А. Шумеро-вавилонская математика. III - I тысячелетия до н.э. М.: Изд. вост. лит., 1961. - 278с.
5. Выгодский М.Я. Арифметика и алгебра в древнем мире. Изд. 2-е, испр. идоп. М.: Наука, 1967. - 367 с.
6. Глейзер Г.И. История арифметике в школе: IV - VI кл. Пособие для учителей. - М.: Просвещение, 1981. - 239 с.
7. Гутер Р.С. Вычислительные машины и системы счисления // Квант-1971 -№2.
8. Депман И.Я. История арифметики, пособие для учителей. М.: Учпедгиз, 1959.-423с.
9. Депман И.Я., Виленкин Н.Я. За страницами учебника математики: Пособие для учащихся 5-6 кл. сред. шк. М.: Просвещение, 1989. -287с.
10. Детская энциклопедия: [В 10-ти т.] Для среднего и старшего возраста. Гл.ред. Маркушевич А.И. Т.2. - Мир небесных тел; Числа и фигуры. -М.: Педагогика, 1972. - 480 с.
11. И. Дышинский Е.А. Игротека математического кружка. М.: Просвещение, 1972. - 144 с.
Похожие работы

... также невысока и обычно составляет около 100 кбайт/с. НКМЛ могут использовать локальные интерфейсы SCSI. Лекция 3. Программное обеспечение ПЭВМ 3.1 Общая характеристика и состав программного обеспечения 3.1.1 Состав и назначение программного обеспечения Процесс взаимодействия человека с компьютером организуется устройством управления в соответствии с той программой, которую пользователь ...
... . В случае выбора пункта «выход», необходимо реализовать завершение работы программы и передачу управления операционной системе DOS. 1.3. Требования техническим и программным средствам Программа выполнена на языке ассемблера 8086 процессора, соответственно ей необходим IBM PC – совместимый компьютер с процессором не ниже 8086, также программа может выполняться на компьютерах с ...

... в широкую практику разработки программ объектно-ориентированного программирования, впитавшего в себя идеи структурного и модульного программирования, структурное программирование стало фактом истории информатики. Билет № 9 Текстовый редактор, назначение и основные функции. Для работы с текстами на компьютере используются программные средства, называемые текстовыми редакторами или текстовыми ...
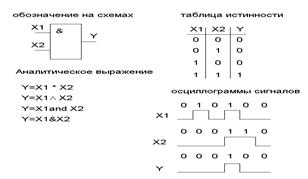
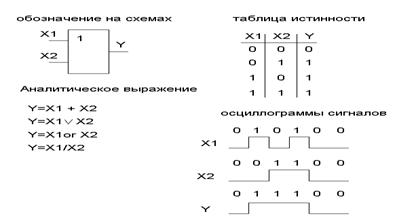
... можно изобразить отдельно. Формирователь выхода «Равенство кодов» Формирователь выхода «Больше» Формирователь выхода «Меньше». Арифметические устройства Другой класс приборов, используемых в дискретной технике предназначен для выполнения арифметических действий с двоичными числами: сложения, вычитания, умножения, деления. К арифметическим устройствам относятся также схемы, ...
0 комментариев