Генерация исходных данных
Группировка статистических данных
Графическое изображение рядов распределения
Доверительные интервалы
Другие точечные оценки интервального ряда (мода, медиана, коэффициент вариации, коэффициент асимметрии, эксцесс)
Оценка однородности выборки
Определение оценок параметров распределений
Проверка нормальности эмпирического распределения на основе критериев согласия Пирсона
Навигация
Генерация исходных данных
Комплексная статистическая обработка экспериментальных данных
42056
знаков
53
таблицы
8
изображений
1. Генерация исходных данных
В данной курсовой работе вместо статистического наблюдения используются случайные величины, сгенерированные по следующим формулам:
1) непрерывная случайная величина X, определяемая по формуле 1.1;
![]() (1.1)
(1.1)
2) непрерывная случайная величина У, определяемая по формуле 1.2.
![]() (1.2)
(1.2)
где ![]() ,
, ![]() - значения случайной величины X и У в различных опытах;
- значения случайной величины X и У в различных опытах;
![]() - случайное число, равномерно распределенное на отрезке [0, 1], возвращаемое при обращении к стандартной функции на выбранном языке программирования к датчику случайных чисел; Для генерации исходных данных были использованы следующие методы:
- случайное число, равномерно распределенное на отрезке [0, 1], возвращаемое при обращении к стандартной функции на выбранном языке программирования к датчику случайных чисел; Для генерации исходных данных были использованы следующие методы:
1) Для случайной величины ![]() в окне Variable в поле Long Name была введена формула 1.3:
в окне Variable в поле Long Name была введена формула 1.3:
![]() (1.3)
(1.3)
2) Для случайной величины ![]() был создан программный имитатор в модуле STATISTICA BASIC. Реализация алгоритма генерации данных в модуле STATISTICA BASIC приведена в приложении А.
был создан программный имитатор в модуле STATISTICA BASIC. Реализация алгоритма генерации данных в модуле STATISTICA BASIC приведена в приложении А.
В результате были получены выборки, объемом 100, 200…1000 значений для каждой из случайных величин.
2. Первичная обработка результатов наблюдения
2.1 Построение вариационного ряда
Вариационный ряд - упорядоченные по возрастанию значения признака.
Построение вариационного ряда в пакете STATISTICA производилось следующим образом:
в модуле Basic Statistics and Tables: Analysis → Frequency tables → кнопка Variables для выбора переменной → отметили All distinct values → ОК.
Размах варьирования ![]() – абсолютная величина разности между максимальным
– абсолютная величина разности между максимальным ![]() и минимальным
и минимальным ![]() значениями (вариантами) изучаемого признака:
значениями (вариантами) изучаемого признака:
![]() (2.1)
(2.1)
Построение размаха варьирования в пакете STATISTICA производилось следующим образом:
в модуле Basic Statistics and Tables: Analysis → Descriptive statistics → Variables (выбрать переменную) → нажали Box & whisker plot for all variables → выбрали Median / Quart. / Range → ОК.
Значения размаха варьирования для заданных выборок в таблице 2.1.
Таблица 2.1 – Размах варьирования для заданных выборок
|
|
| |||||
| Выборка |
|
|
|
|
|
|
| 100 | 25,201 | 6,993 | 18,209 | 28,805 | 2,429 | 26,376 |
| 500 | 25,110 | 6,984 | 18,126 | 33,695 | 0,196 | 33,499 |
| 1000 | 25,237 | 6,711 | 18,466 | 33,962 | -1,574 | 35,536 |
Случайная величина ![]() имеет меньший размах, чем случайная величина
имеет меньший размах, чем случайная величина ![]() .
.
Похожие работы
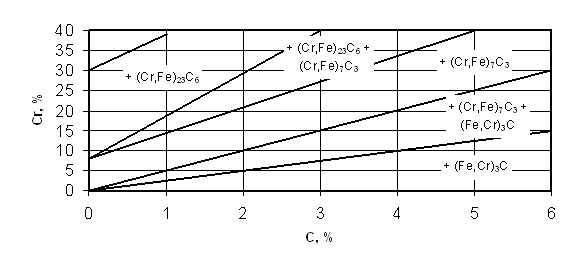
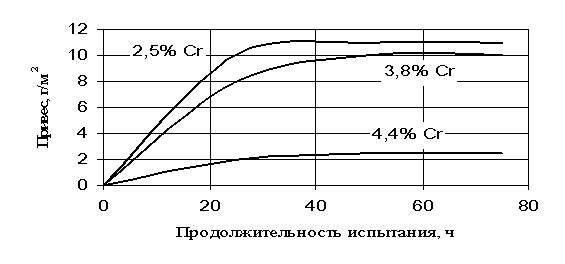
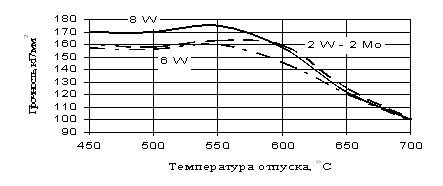
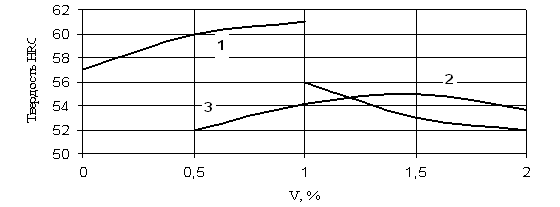
... отпуска может быть на 10–20оС ниже, а его продолжительность на 20–25% меньше, чем первого отпуска. Охлаждение после отпуска проводится на воздухе. 1.1.5 Влияние термической обработки на свойства штамповых сталей Служебные свойства штампового инструмента и его стойкость в значительной степени определяются соответствующим назначением марки стали, ее термообработкой и условиями эксплуатации ...
... о начавшихся в них процессах деградации, которые в дальнейшем приведут к условным отказам. В этом случае выбросы являются закономерными, обусловлены физическими процессами и их нельзя исключать из дальнейшего рассмотрения при статистической обработке результатов испытаний. Поэтому для принятия того или иного решения проводят тщательный комплексный анализ возможных причин указанных отклонений. ...
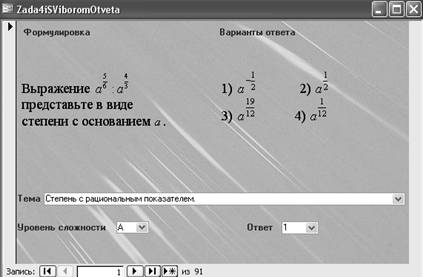

... в процессе обучения, необходима разработка совершенно новых подходов к работе с таким видом информационных ресурсов как базы данных. Глава 2.Технология использования баз данных математических задач в процессе подготовки учащихся к ЕГЭ по математике 2.1 Реализация модели В соответствии с теорией поэтапного формирования умственных действий учащихся, подготовку к сдаче единого ...
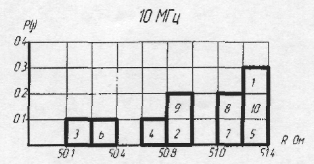
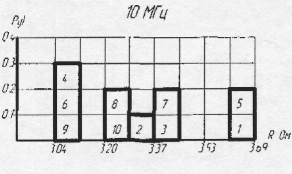
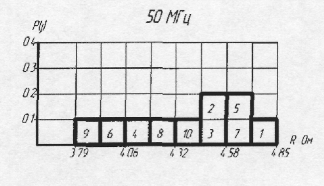
... плана ФЭ. Большое разнообразие моделей РК приводит к необходимости использования разнообразных способов и технических средств для измерения их параметров. Как правило, статические и динамические параметры РК измеряют на разных технологических установках. Методы построения средств измерения для идентификации моделей РК могут быть сведены к следующим принципам, учитывающим особенности подключения ...
0 комментариев