Законодательно-нормативная база, используемая при составлении отчета о финнсовых результатах
Краткая экономическая характеристика ГУСП "Башхлебоптицепром"
Учет финансовых результатов в ГУСП "Башхлебоптицепром"
Анализ деятельности ГУСП “Башхлебоптицепрома»
Показатель – это степень финансовой устойивости
Х (149000/17467-135009)=767 х 1,002= -768,5 тыс.руб
Основные положения корреляционного и регрессионного анализа
Экономико – математическое моделирование прибыли ГУСП «Башхлебоптицепрома»
Разработка мероприятий по улучшению финансовых результатов
Экономическая эффетивность прелагаемых мероприятий
Навигация
Основные положения корреляционного и регрессионного анализа
Анализ финансовых результатов на примере магазина
145543
знака
22
таблицы
1
изображение
3.1 Основные положения корреляционного и регрессионного анализа
Одним из инструментов экономического анализа в настоящее время, является экономико-математического моделирование.
Экономико-математическое моделирование представляет собой метод исследования экономико-математических моделей, с помощью экономико-математических методов.
Экономико-математическая модель - это математическое описание экономического процесса или объекта.
Экономико-математические методы – это комплекс экономических и математических дисциплин, таких, как:
экономико-статистические методы;
эконометрика;
исследование операций;
экономическая кибернетика.
Предметом экономико-математического моделирования является изучение реальных процессов социально-экономического развития, их обобщение и представление в виде конкретных объективно обусловленных оценок.
Основной целью экономики является обеспечение общества предметами потребления. Экономика состоит из элементов – хозяйственных единиц: предприятия, фирмы, банки и так далее. Экономика является подсистемой системы более высокого уровня – природы и общества.
Задачами экономико-математического моделирования являются:
- анализ экономических объектов и процессов;
- экономическое прогнозирование, предвидение развития экономических процессов;
- выработка данных необходимых для принятия управленческих решений.
Любое экономическое исследование всегда предполагает объединение теории (экономической модели) и практики (статистических данных). Теоретические модели используются для описания и объяснения наблюдаемых процессов, а статистические данные собираются с целью эмпирического построения и обоснования модели.
Математические модели, используемые в экономике, подразделяются на классы по ряду признаков, относящихся к особенностям моделируемого объекта, цели моделирования и используемого инструментария: модели макро- и микроэкономические, теоретические и прикладные, оптимизационные и равновесные, статистические и динамические.
Макроэкономические модели описывают экономику как единое целое, связывая между собой укрупненные материальные и финансовые показатели: ВНП, потребление, инвестиции, занятость и т.д. Микроэкономические модели описывают взаимодействие структурных и функциональных составляющих экономики, либо поведение отдельной такой составляющей в рыночной среде. Теоретические модели позволяют изучать общие свойства экономики и ее характерных элементов дедукцией выводов из формальных предпосылок. Прикладные модели дают возможность оценить параметры функционирования конкретного экономического объекта и сформулировать рекомендации для принятия практических решений. Равновесные модели описывают такие состояния экономики, когда результирующая всех сил, стремящихся вывести ее из данного состояния, равна нулю. В моделях статистических описывается состояние экономического объекта в конкретный момент или период времени; динамические модели включают взаимосвязи переменных во времени.
В экономической деятельности достаточно часто требуется не только получить прогнозные оценки исследуемого показателя, но и количественно охарактеризовать степень влияния на него других факторов, а также возможные последствия их изменений в будущем. Для решения этой задачи предназначен аппарат корреляционного и регрессионного анализа.
Результат опыта можно охарактеризовать качественно и количественно. Любая качественная характеристика результата опыта называется событием; любая количественная характеристика результата опыта называется случайной величиной. Случайная величина – это такая величина, которая в результате опыта может принимать различные значения, причем до опыта не возможно предсказать, какое именно значение она примет.
Понятие зависимости (независимости) случайных величин является одним из важнейших понятий в теории вероятностей. Так как наличие или отсутствие зависимости между случайными величинами оказывает существенное влияние на метод исследования. Степень тесноты изменяется в широких пределах: от полной независимости случайных величин до очень сильной, близкой по существу к функциональной зависимости.
Связь между зависимой переменной Y(i) и n независимыми факторами можно охарактеризовать функцией регрессии Y(i) = f (X1, X2, ......, Xm), которая показывает, каким будет в среднем значение переменной Y, если переменные Х примут конкретное значение. Это обстоятельство позволяет применять модель регрессии не только для анализа, но и для прогнозирования.
Множественная корреляция и регрессия определяют форму связи переменных, выявляют тесноту их связи и устанавливают влияние отдельных факторов.
Основными этапами построения регрессионной модели являются:
- построение системы показателей (факторов). Сбор и предварительный анализ исходных данных.
- выбор вида модели и численная оценка ее параметров.
- проверка качества модели
- оценка влияния отдельных факторов на основе модели
- прогнозирование на основе модели регрессии.
Рассмотрим содержание этих этапов и их реализацию.
Построение системы показателей (факторов).
Информационной базой регрессионного анализа являются многомерные временные ряды, каждый из которых отражает динамику одной переменной и должен удовлетворять требованиям статистического аппарата исследования.
Для построения системы показателей используется корреляционный анализ. Основная задача которого, состоит в выявлении связи между случайными переменными путем точечной и интервальной оценки парных (частных) коэффициентов корреляции и детерминации.
Выбор факторов, влияющих на исследуемый показатель, производится прежде всего исходя из содержательного экономического анализа. Для получения надежных оценок в модель не следует включать слишком много факторов. Их число не должно превышать одной трети объема имеющихся данных. Для определения наиболее существенных факторов могут быть использованы коэффициенты линейной и множественной корреляции.
При проведении корреляционного анализа вся совокупность данных рассматривается как множество переменных (факторов), каждая из которых содержит n-наблюдений; хik – i- ое наблюдение k-ой переменной.
Связь между случайными величинами X и Y в генеральной совокупности, имеющими совместное нормальное распределение, можно описать коэффициентами корреляции:
r = М ((X – mx) (Y – my)) / sx sy , или r = Кxy / sx sy , ( 17 )
где r - коэффициент корреляции (или парный коэффициент корреляции) генеральной совокупности.
Оценкой коэффициента корреляции r является выборочный парный коэффициент корреляции:
N _ _
r = å (xi – x ) (yi – y) / nSxSy, ( 18 )
i = 1
где Sx.Sy – оценки дисперсии;
x , y– наилучшие оценки математического ожидания.
Парный коэффициент корреляции является показателем тесноты связи лишь в случае линейной зависимости между переменными и обладает следующими основными свойствами:
![]()
![]() Свойство 1. Коэффициент корреляции принимает значение в интервале (-1,+1), или rxy < 1. Значение коэффициентов парной корреляции лежит в интервале от -1 до +1. Его положительное значение свидетельствует о прямой связи, отрицательное - об обратной, то есть когда растет одна переменная, другая уменьшается. Чем ближе его значение к 1 , тем теснее связь.
Свойство 1. Коэффициент корреляции принимает значение в интервале (-1,+1), или rxy < 1. Значение коэффициентов парной корреляции лежит в интервале от -1 до +1. Его положительное значение свидетельствует о прямой связи, отрицательное - об обратной, то есть когда растет одна переменная, другая уменьшается. Чем ближе его значение к 1 , тем теснее связь.
Коэффициент множественной корреляции, который принимает значение от 0 до 1, более универсальный: чем ближе его значение к 1, тем в большей степени учтены факторы, влияющие на зависимую переменную, тем более точной может быть модель.
Свойство 2. Коэффициент корреляции не зависит от выбора начала отсчета и единицы измерения, то есть
р (a1X + b a2 Y + b) = r xy, ( 19 )
где a1, a2 , b - постоянные величины, причем a1 > 0 , a2 > 0.
Случайные величины X,Y можно уменьшать (увеличивать) в a раз, а также вычитать или прибавлять к значениям X и Y одно и тоже число b - это не приведет к изменению коэффициента корреляции r.
Свойство 3. При r = +-1 корреляционная связь представляется линейной функциональной зависимостью. При этом линии регрессии y по x и x по y совпадают.
Свойство 4. При r = 0 линейная корреляционная связь отсутствует и параллельны осям координат.
Рассмотренные показатели во многих случаях не дают однозначного ответа на вопрос о наборе факторов. Поэтому в практической работе с использованием ПЭВМ чаще осуществляется отбор факторов непосредственно в ходе построения модели методом пошаговой регрессии. Суть метода состоит в последовательном включении факторов. На первом шаге строится однофакторная модель с фактором , имеющим максимальный коэффициент парной корреляции с результативным признаком. Для каждой переменной регрессии , за исключением тех, которые уже включены в модель , рассчитывается величина С(j) , равная относительному уменьшению суммы квадратов зависимой переменной при включении фактора в модель. Эта величина интерпретируется как доля оставшейся дисперсии независимой переменной, которую объясняет переменная j. Пусть на очередном шаге k номер переменной, имеющей максимальное значение, соответствует j. Если Сk меньше заранее заданной константы, характеризующей уровень отбора, то построение модели прекращается. В противном случае k-я переменная вводится в модель.
После того, как с помощью корреляционного анализа выявлены статистические значимые связи между переменными и оценена степень их тесноты, переходят к математическому описанию
Регрессионной моделью системы взаимосвязанных признаков является такое уравнение регрессии, которое включает основные факторы, влияющие на вариацию результативного признака, обладает высоким (не ниже 0,5) коэффициентом детерминации и коэффициентом регрессии, интерпретируемыми в соответствии с теоретическим знанием о природе связей в изучаемой системе.
Основной задачей линейного регрессионного анализа является установление формы связи между переменными, а так же выбор наиболее информативных аргументов Xj; оценивание неизвестных значений параметров aj уравнения связи и анализ его точности.
В регрессионном анализе вид уравнения выбирается исходя из физической сущности изучаемого явления и результатов наблюдений. Простейший случай регрессионного анализа для линейной зависимости между зависимой переменной Y и независимой переменной Х выражается следующей зависимостью:
Y = a0 + a1X + e , ( 20 )
где a0 – постоянная величина (или свободный член уравнения).
a1 – коэффициент регрессии, определяющий наклон линии, вдоль которой рассеяны данные наблюдений. Это показатель, характеризующий процентное изменение переменой Y, при изменении значения X на единицу. Если a1 > 0 –переменные X и Y положительно коррелированны, если a2 < 0 – отрицательно коррелированны;
e - независимая ((М (ei ej )= 0, при i ¹ j ) нормально распределенная случайная величина – остаток (помеха) с нулевым математическим ожиданием (me= 0) и постоянной дисперсией ( De= s2 ). Она отражает тот факт, что изменение Y будет недостаточно описываться изменением X – присутствуют другие факторы, неучтенные в данной модели.
Параметры модели оцениваются по методу наименьших квадратов, который дает наилучшие (эффективные) линейные несмещенные оценки.
Если записать выражение для определения коэффициентов регрессии в матричной форме, то становится очевидным, что решение задачи возможно лишь тогда, когда столбцы и строки матрицы исходных данных линейно независимы. Для экономических показателей это условие выполняется не всегда. Линейная или близкая к ней связь между факторами называется коллиниарностью и приводит к линейной зависимости нормальных уравнений, что делает вычисление параметров либо невозможным, либо затрудняет содержательную интерпретацию параметров модели. Чтобы избавиться от коллиниарности, в модель включают лишь один из линейно связанных между собой факторов, причем тот, который в большей степени связан с зависимой переменной.
Проверка качества модели
Качество модели оценивается стандартным для математических моделей образом: по адекватности и точности. Расчетные значения получаются путем подстановки в модель фактических значений всех включенных факторов.
Кроме рассмотренных выше характеристик, целесообразно использовать корреляционное отношение (индекс корреляции), а также характеристики существенности модели в целом и ее коэффициентов.
![]()
![]() В качестве характеристики тесноты связи применяется индекс корреляции (Iyx )переменных Y по X.
В качестве характеристики тесноты связи применяется индекс корреляции (Iyx )переменных Y по X.
![]() Iyx =
1- (se2 / sy2) , ( 21 )
Iyx =
1- (se2 / sy2) , ( 21 )
где se2 – это дисперсия параметра Х относительно функции регрессии, то есть остаточная дисперсия, которая характеризует влияние на Y прочих неучтенных факторов в модели;
sy2 – полная дисперсия, она измеряет влияние параметра X и Y.
Из этого следует, что 0 £ Iyx £ 1. При этом Iyx = 0 означает полное отсутствие корреляционной связи между зависимой переменной Y и объясняющей переменной Х. В то же время максимальное значение индекса корреляции (Iyx = 1) соответствует наличию чисто функциональной связи между переменными X и Y и, следовательно, возможность детерминированного восстановления значений зависимой переменной Y по соответствующим значениям объясняющей переменной X.
Данный коэффициент является универсальным, так как он отражает тесноту связи и точность модели, а также может использоваться при любой форме связи переменных. При построении однофакторной модели и их линейной зависимости он равен коэффициенту линейной корреляции.
Коэффициент множественной корреляции (индекс корреляции), возведенный в квадрат, называется коэффициентом детерминации. Он показывает долю вариации результативного признака, находящегося под воздействием изучаемых факторов, то есть определяет, какая доля вариации признака Y учтена в модели и обусловлена влиянием на него факторов.
В качестве меры точности применяют несмещенную оценку дисперсии остаточной компоненты , которая определяется по формуле:
n _
S = S2 / å (xi – x) , ( 22 )
i=1
где S2 – дисперсия зависимой переменной Y.
n _ n
S2 = å (yi – yi)2 / n-2 = å ei2 / n-2 ( 23 )
i=1 i=1
Квадратный корень из этой величины (S) называется стандартной ошибкой оценки:
![]()
![]() n _
n _
![]() S а1= S2 / å (xi – x) , ( 24 )
S а1= S2 / å (xi – x) , ( 24 )
i=1
Коэффициент а1 есть мера наклона линии регрессии. Очевидно, чем больше разброс значений Y вокруг линии регрессии, тем больше в среднем ошибка в определении ее наклона. Кроме того, чем больше число наблюдений n, тем больше сумма å (xi – x)2 и тем, самым меньше стандартная ошибка оценки а1 .
Проверка значимости модели регрессии осуществляется по F-критерию (критерий Фишера), расчетное значение которого определяется по формуле:
Fp = {Q1 * (n - m)} / {Q2 * (m-1)}, ( 25 )
где m – число объясняющих (независимых переменных);
n – число наблюдений;
Q1 - сумма квадратов, объясняемая регрессией, то есть сумма квадратов отклонений обусловленных влиянием признака Х;
Q2 – остаточная сумма квадратов, характеризующая влияние неучтенных факторов.
По заданному уровню значимости l и числу степеней свободы k1 =m-1 и k2 = n-m по таблице F-распределения находится значение Fтабл и сравнивается с расчетным Fp :
если Fp > Fтабл, то нулевая гипотеза Н0 отвергается и уравнение регрессии (модель) считается значимым;
если Fp < Fтабл, то нет основания отвергать нулевую гипотезу Н0.
Значимость коэффициентов регрессии проверяется с помощью t-критерия, значение которого рассчитывается по формуле:
t = r / Sr = r n-2 / 1 – r 2
где r – коэффициента уравнения регрессии;
Sr - среднеквадратическое отклонение r.
При заданном уровне значимости l и числе степеней свободы k= n – m – 1 определяется табличное значение t – критерия и сравнивается с расчетным tp : - если tp > tpасч коэффициент регрессии является значимым. В противном случае фактор, соответствующий этому коэффициенту, следует исключить из модели (при этом ее качество не ухудшится).
Оценка влияния отдельных факторов на основе модели.
Коэффициенты регрессии являются именованными числами, выраженными в разных единицах измерения. Поэтому трудно, а иногда невозможно сопоставить факторы Х по степени их влияния на зависимую переменную Y. Для устранения этого недостатка в практике экономического анализа используются следующие коэффициенты:
коэффициент эластичности Э;
бета – коэффициент, b;
дельта – коэффициент, ∆. Коэффициент эластичности имеет вид: Эi = bi * x i / y ( 27 )
где bi – коэффициент модели при i– факторе; х i – среднее значение i – го фактора;
у – среднее значение зависимой переменной.
Коэффициент эластичности i – фактора Х i говорит о том, что при отклонении его величины от среднего значения хi на 1%, и при фиксированных на постоянном уровне значениях других факторов, входящих в уравнение, объясняемая переменная Y отклониться от своего среднего значения y на э i процентов. Иначе, - изменение значения фактора Х i на 1% от его средней величины х i, приводит к изменению значения объясняемой переменной на э i процентов от ее средней величины.
Бета – коэффициент имеет вид: b i = b i * S i / Sy , ( 28 )
где b i - коэффициент модели при i- м факторе;
S i – оценка среднеквадратического отклонения i – го фактора;
Sy - оценка среднеквадратического отклонения зависимой переменной Y.
Бета-коэффициент при факторе X i определяет меру влияния его вариации на вариацию зависимой переменной Y при фиксированной на одном уровне вариации остальных независимых факторов, входящих в уравнение регрессии.
Указанные коэффициенты позволяют проранжировать факторы по степени влияния факторов на зависимую переменную .
Дельта-коэффициент имеет вид:
∆i = ri bi / R2 , ( 29 )
где bi – бета-коэффициент i – го фактора Хi ;
ri – коэффициент парной корреляции i – го фактора Хi и зависимой переменной Y;
R2 – коэффициент множественной детерминации.
Дельта-коэффициент позволяет оценить долю вклада каждой независимой переменной Хi в суммарное влияние всех факторов.
При корректно проводимом анализе значения ∆ - коэффициентов положительны, то есть все коэффициенты регрессии имеют тот же знак, что и соответствующие парные коэффициенты корреляции. Но в случаях сильной коррелированности факторов некоторые дельта-коэффициенты могут быть отрицательными вследствие того, что соответствующий коэффициент регрессии имеет знак, противоположный знаку парного коэффициента корреляции.
Прогнозирование на основе модели регрессии.
Регрессионные модели могут быть использованы для прогнозирования возможных ожидаемых значений переменной. При это перенос закономерности связи, измеренной в исследуемой совокупности в статике на динамику, не является корректным и требует проверки условий допустимости такого переноса (экстраполяции).
Ограничением прогнозирование на основании регрессионной модели служит условие стабильности или малой изменчивости других факторов и условий изучаемого процесса, не связанных с ними.
Прогнозируемое значение переменной Y получается при подстановке в уравнение регрессии: ŷ n+k = a0 + a1 xn+1
ожидаемой величины фактора Х. Данный прогноз называется точечным. Возникает ограничение при выборе ожидаемой величины Х: нельзя подставлять значения независимой переменной xn+k , значительно отличающейся от входящих в исследуемою выборку, по которой вычислено уравнение регрессии.
Вероятность реализации точечного прогноза практически равна нулю. Поэтому рассчитывается средняя ошибка прогноза или доверительный интервал с достаточно большой надежностью.
Средняя ошибка линии регрессии в генеральной совокупности при значении фактора xn+k вычисляется для линии регрессии по формуле:
![]()
![]() _ n _
_ n _
![]() m Ŷk = Stтабл 1 / n + (xn+k – x ) 2 / å (xi - x ) 2 , ( 31 )
m Ŷk = Stтабл 1 / n + (xn+k – x ) 2 / å (xi - x ) 2 , ( 31 )
i =1
где tтабл - табличное значение t – статистики с уровнем значимости l и степенью свободы (n - 2);
S – стандартная ошибка зависимой переменной.
Границы доверительного интервала вычисляются, соответственно, как:
нижняя граница - UH(k) = ŷ n + k – m y k ;
верхняя граница – UB(k) = ŷ n + k + m ŷ k.
Средняя ошибка прогноза для индивидуального значения зависимой переменой Y от линии регрессии вычисляется по формуле:
![]()
![]() __
n _
__
n _
![]() m ŷ (xk) = Stтабл 1 +1 / n +
(xn+k – x ) 2 / å (xi - x ) 2 (32 )
m ŷ (xk) = Stтабл 1 +1 / n +
(xn+k – x ) 2 / å (xi - x ) 2 (32 )
i =1
Критерием прогнозных качеств оцененной регрессионной модели может служить относительная ошибка прогноза:
__
V = S / y , ( 33 )
где S - стандартная ошибка зависимой переменной;
y - среднее значение фактических данных зависимой переменной.
Если величина V мала и отсутствует автокорреляция остатков (то есть систематичность отклонений зависимой переменной от линии регрессии), то прогнозные качества модели высоки. Автокорреляция остатков проверяется с помощью критерия Дарбина – Уотсона, рассчитываемая по формуле:
n n
d p = å(ei - e i-1)2 / å ei2 , ( 34 )
i =1 i =1
и сравнивается с табличными значениями d1 и d2, определенными по таблице с уровнем значимости l и числом степеней свободы k = n: при dр > d2, то корреляция отсутствует.
Если построенная регрессионная модель адекватна и прогнозные оценки факторов достаточно надежны, то с выбранной пользователем вероятностью можно утверждать, что при сохранении сложившихся закономерностей развития прогнозируемая величина попадет в интервал, образованный нижней и верхней границами.
Похожие работы
... продукции для столицы Беларуси. На предприятии внедрены передовые технологии и высокопроизводительное оборудование ведущих отечественных и зарубежных фирм, которые позволяют добиваться высоких производственных показателей. 2. ОРГАНИЗАЦИЯ УЧЕТА И КОНТРОЛЯ РЕАЛИЗАЦИИ ГОТОВОЙ ПРОДУКЦИИ 2.1. Документальное оформление операций по реализации готовой продукции Первичный учет представляет собой ...
... прибыли от реализации продукции и снижение себестоимости товарной продукции. На основе изученного теоретического материала проведем анализ финансовых результатов деятельности ООО «Евролот Запад». 2. АНАЛИЗ ФИНАНСОВЫХ РЕЗУЛЬТАТОВ ДЕЯТЕЛЬНОСТИ ООО «ЕВРОЛОТ-ЗАПАД» 2.1 Организационно-правовая и экономическая характеристика предприятия Предприятие ООО «Евролот Запад» создано по решению ...
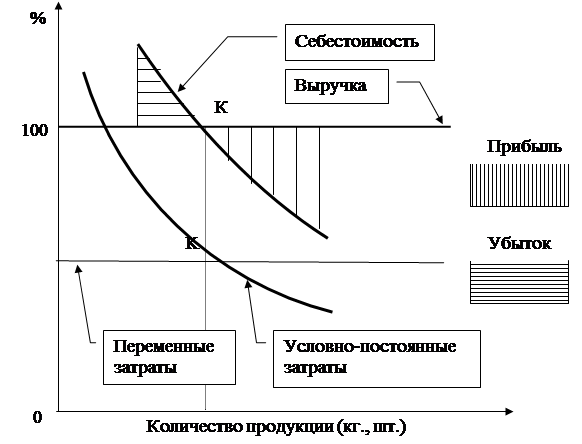
... лиц – уменьшилась с 18,6 до 18,3 %. Также незначительно изменилась доля сбора на уборку и благоустройство города с 12,4 до 12,2% соответственно. По проведенному анализу можно сделать вывод, что доля налогов, влияющих на прибыль и относимых на финансовый результат сократилась в 2000г. по сравнению с 1999г. 3. МЕРОПРИЯТИЯ ПО СОВЕРШЕНСТВОВАНИЮ УПРАВЛЕНИЯ ПРИБЫЛЬЮ ПРЕДПРИЯТИЯ ОАО МОЛЗАВОД « ...
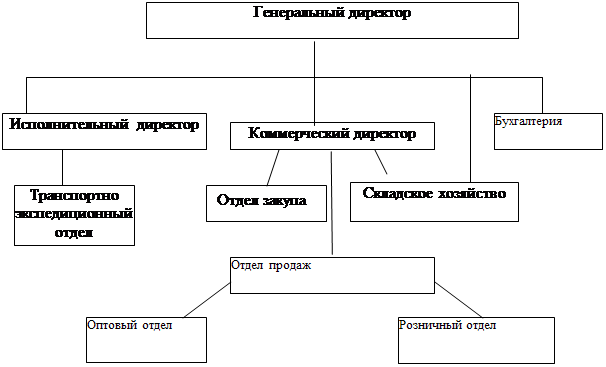

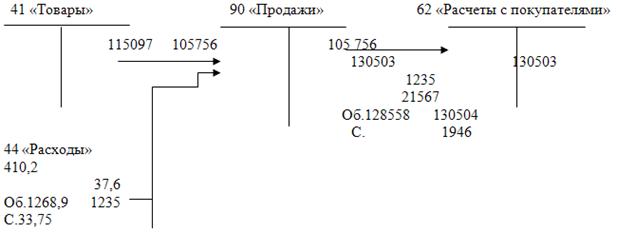
... заключение о достаточно эффективной организации бухгалтерского учета в ООО "Интел - плюс", отвечающее требованиям достоверности, полноты, адекватности. 2 АНАЛИЗ ФИНАНСОВОГО РЕЗУЛЬТАТА В ООО "ИНТЕЛ-ПЛЮС" 2.1 Организация учета финансового результата в ООО "Интел - плюс" Правила формирования в бухгалтерском учете ООО "Интел - плюс" информации о доходах определяются в соответствии с Положением ...
0 комментариев